Inductive Matrix Completion Based on Graph Neural Networks
概
本文介绍了一种 Inductive 的矩阵补的方式, 作者主要用在推荐上.
注: 现在的图网络大体分为 transductive: 即要求测试的结点也在训练集中; inductive: 不要求测试的结点也在训练集中. 在推荐的场景中, 后者可以看成是解决冷启动问题的尝试.
符号说明
- , 二部图, 包含 user , item , 二者之间的边 .
- , rating matrix, 其中 表示 ratings 的种类, 比如 MovieLens 中有 .
IGMC
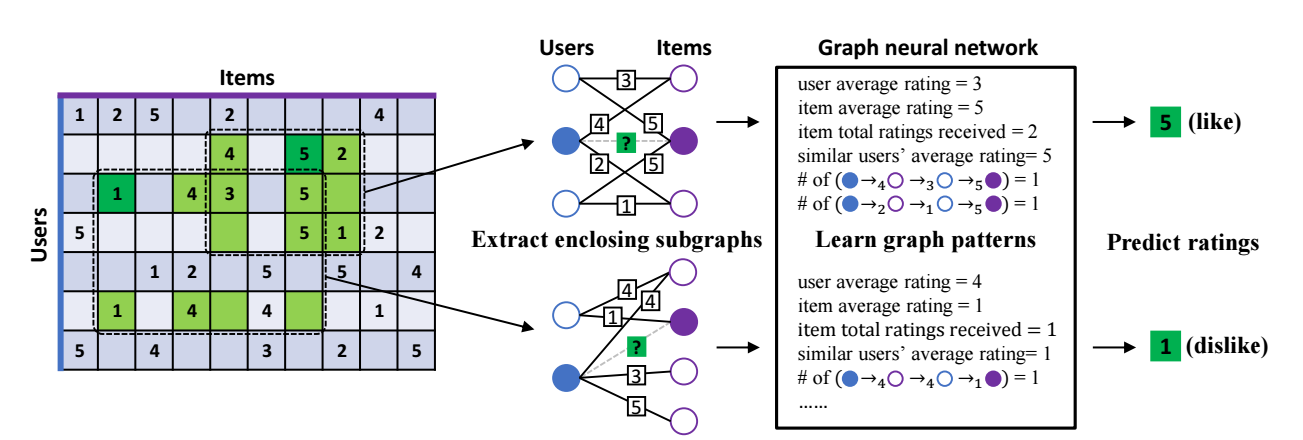
- IGMC 的主要流程是:
- 抽取基于 的 1-hop enclosing subgraph;
- -hop 结点编号;
- 喂入 graph-level 的 GNN 中进行编码;
- 利用分类器进行分类 (like/dislike).
Enclosing subgraph
- IMGC 的 link prediciton 是居于图的拓扑结构的, 也因此能够避免 ID 以及其它信息的需求.
- 作者采用如下算法抽取围绕 的 h-hop enclosing subgraph (本文采用 ):

Node labeling
-
在喂入 graph-level 的 GNN 之前, 我们需要为采样出来的结点进行排序, 使得后续的 GNN 能够区分:
- user, item;
- 结点离目标结点 之间的相对距离.
-
为此, 作者采取如下方式排序:
- 令 的 label 为 0, 的 label 为 1;
- 假设结点 为 user 且为 -hop, 则其 label 为 ;
- 假设结点 为 item 且为 -hop, 则其 label 为 .
Graph-level GNN
-
接下来作者采用 R-GCN (relational graph convolutonal operator) 来提取特征, 其中的 message passing layer 为 (各层之间通过 Tanh 激活函数连接):
注意, 我们对不同的 采用不同的权重矩阵 .
-
最后, 将各层的特征凭借起来得到新的特征表示:
然后
-
最后, 通过下列分类器获得预测概率:
Optimization
-
利用如下的 MSE 损失进行优化:
-
但是, 作者提出, R-GCN 为每个 设置不同的权重矩阵 . 但是直观上来说, 往往表示喜欢, 往往表示不喜欢, 这种独立的做法不利于这种关系的学习. 故作者额外添加了如下的约束:
-
最后的损失为:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2021-03-15 Handing Incomplete Heterogeneous Data using VAEs