Perception Prioritized Training of Diffusion Models
概
作者认为, 在 diffusion 过程中, 还比较小的时候给予更多权重去学习更有利于整体的学习, 遂提出了一种新的加权方法.
Motivation
-
前向:
则
-
对于分布 而言, 它的信噪比为:
在概场景下, 前向的过程:
随着 的增加逐渐减小.
-
一般来说, DPM 中的 consistent term 为:
然后总的损失为:
-
但是一般来说, 实际上用的是:
这相当于把 MSE 前的系数都给去掉了. 当然, 这种损失虽然能够平衡方差, 让训练更加稳定, 但是也缺少学习的侧重性, 很难认为训练过程中所有的阶段都是同等重要的.
-
所以本文希望把 SNR 引入进来. 如下图所示 (注意, 横坐标 SNR 增加, 对应的 是减小的, 所以从生成的角度来说是从左往右的生成), 源于同一个图片, 来源于不同的图片, 随着图片的生成, 相同图片的更加近似, 而源于不同图片的两张图片会逐渐变得不同. 换言之, 在 SNR 很小的阶段, 图片需要学习更多的内容 (content), 那么自然地我们应该强调这一部分.

本文的方法
-
引入特殊的权重:
于是最后的损失就成了:
-
下图是在两种不同的 schedule 下的结果, 显然更加注重 content 部分的权重.
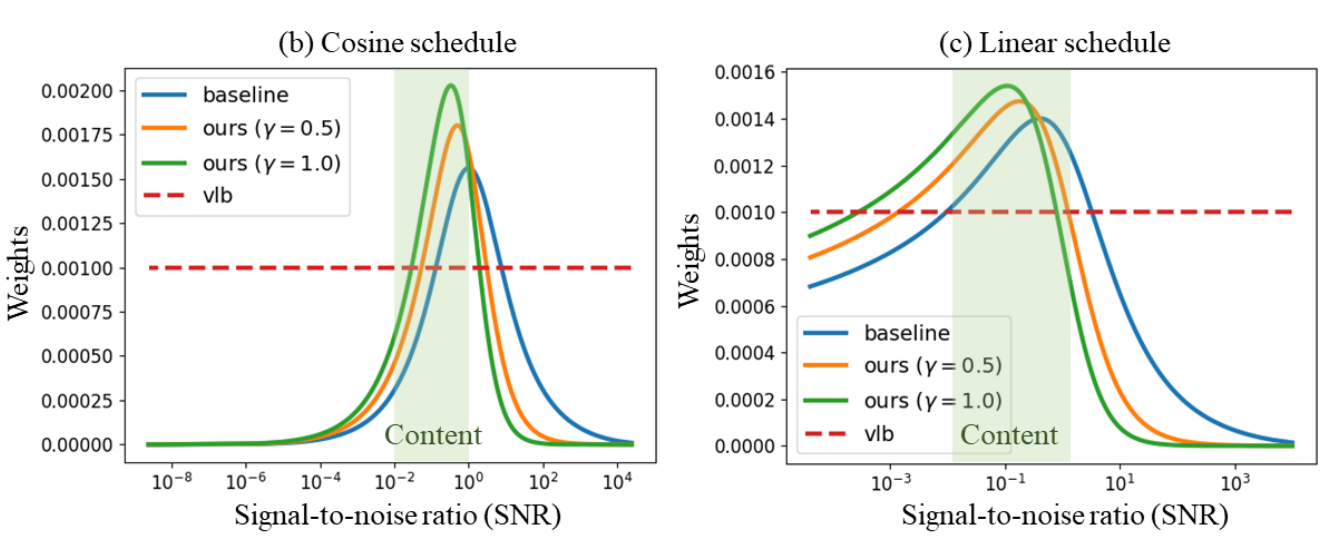
- 作者推荐是 .



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具