Gong S., Li M., Feng J., Wu Z. and Kong L. DiffuSeq: Sequence to sequence text generation with diffusion models. In International Conference on Learning Representations (ICLR), 2023
概
本文提出了一种用于 Seq2Seq 的不需要 classifier 引导的扩散模型, 且是在连续空间上讨论的.
虽然方法看起来很简单, 但是感觉很容易 work 和推广.
符号说明
- z0∼q(z), a real-world data distribution;
- zT∼N(0,I), Gaussian noise;
- q(zt|zt−1)=N(zt;√1−βtzt−1,βtI),t∈[1,2,…,T];
- fθ, a diffusion model;
- wx=[wx1,…,wxm], m-length soure sequence (离散的);
- wy=[wy1,…,wyn], n-length soure sequence (离散的).
流程
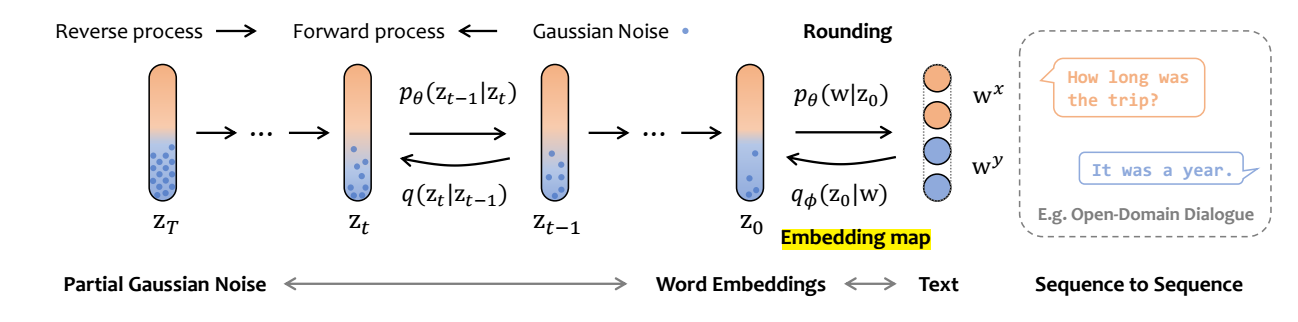
-
首先利用获取词的 embeddings:
z0=Emb(w)=[Emb(w1),Emb(w2),…],
这一步实际上是相当于构建从离散空间到连续空间的一个映射:
qϕ(z0|w)=δEmb(w)(z0).
-
因为整个流程设计两个部分: source x, target y, 不妨令
x0=Emb(wx)=[Emb(wx1),Emb(wx2),…],y0=Emb(wy)=[Emb(wy1),Emb(wy2),…].
于是
z0=x0⊕y0.
类似的之后的 zt 均可以分为 source 和 target 两部分, 即
zt=xt⊕yt.
-
前向过程: 如上图所示:
- 根据 qϕ(z0|w) 得到 z0 (这一步实际上是确定的);
- 此时我们依旧在连续空间中了, 故我们可以使用一般的高斯分布来加噪, 即:
z′t∼q(zt|zt−1)=N(zt;√1−βtzt−1,βtI).
但是特别地, 我们只对 target 部分加噪:zt=x0⊕y′t.
-
反向过程: 同样如上图所示:
-
从标准的高斯分布中采样 z′T, 并令
zT=x0⊕y′T.
-
根据如下分布进行反向传递:
z′t−1∼N(zt−1;μθ(z,t),σθ(zt,t)),zt−1=x0⊕y′t−1,t≥2.
-
最后的损失为如下:
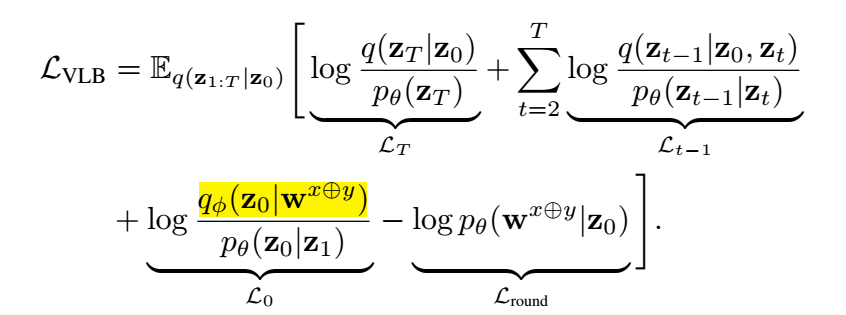
-
需要注意的是, 其中 qϕ(z0|wx⊕y) 本身是一个确定的过程, 所以是不提供导数的, 可以省略. 整体的推导其实普通的 VLB 没什么差别, Lround 也只是原来的损失一部分, 只是被作者单拎了出来. 不过也有道理, 因为但看它, 其实就是希望训练一个分类网络, 将 z0 映射回词.
-
不过作者最后用的也不是上面的损失, 而是一个简化的版本 (即把原先的系数给去掉后的结果):
LVLB=[T∑t=2∥z0−fθ(z,t)∥2+∥Emb(wx⊕y)−fθ(z1,1)∥2−logpθ(wx⊕y|z0)]⇒[T∑t=2∥y0−~fθ(z,t)∥2+∥Emb(wy)−~fθ(z1,1)∥2−logpθ(wx⊕y|z0)].
-
f,~f 就是对 zt,yt 的直接拟合, 是另一种损失的写法. 具体看 here
代码
official



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2021-03-04 Chapter 9 Measurement Bias
2021-03-04 Chapter 8 Selection Bias
2020-03-04 Towards Deep Learning Models Resistant to Adversarial Attacks
2020-03-04 EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES
2020-03-04 Practical Black-Box Attacks against Machine Learning