Diffusion-LM Improves Controllable Text Generation
概
本文介绍了一种将 DPM 应用到可控文本生成之上, 虽然 Text 的本质是离散的, 但是作者依然采用连续的方式进行扩散 (归功于所引入的 rounding 模块).
符号说明
- , words;
- , 普通的用于生成的语言模型;
- , 基于条件 的语言生成模型 (比如, 可以是语法结构, 情感等);
流程

-
由于本文提出的条件生成模型是 classifier-guided 的, 所以就包含了两个单独的部分, 其中拟合 如上图所示.
-
其整体的思路和原始的 DPM 并灭有特别的大差别, 主要需要解决的问题是:
-
前向的时候, 如何从离散的 Text () 空间到连续空间? 作者给出的方案就是简单地用 embedding: 即首先 look_up 得到 embeddings:
然后假设
-
后向的时候, 如何从连续的 映射回离散的 Text 呢? 要知道, 几乎不可能 恰好和某个词的 embedding 一致. 作者构建了可训练的 rounding step:
其中每个 都是是通过 softmax 构建的.
-
-
在进行上述第二步的过程中, 作者遇到了些许麻烦, 虽然我没怎么看懂作者在这一刻的表述, 我感觉大概意思是在对齐方面出了些问题. 出问题的原因是 DPM 在 位置的训练不够, 所以作者直接添加了一个很强的 loss:
-
最后稍稍提一下条件生成的部分, 因为 DPM 采样只需要提供 的梯度即可, 所以可以通过 (贝叶斯公式):
-
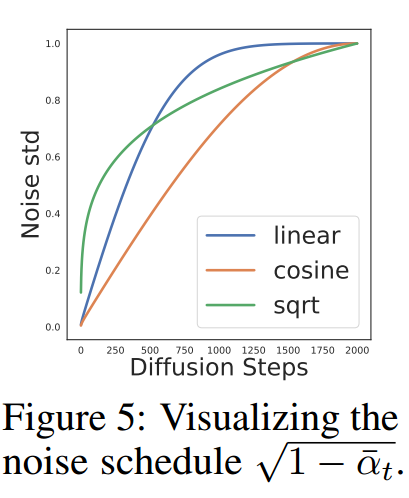
最后的最后提一个可能还挺重要的 trick, 正如之前所述, 作者认为在 接近 0 的附件拟合的不好, 所以作者希望更加强调这一部分, 所以采用的是一种新的 sqrt noise schedule:
大概如下图所示:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2021-03-02 Chapter 7 Confounding