Session-based Recommendations with Recurrent Neural Networks
概
这篇文章将 GRU 用在了 session-based 的推荐上, 在效率上有诸多考虑 (虽然我不确定现在的主流模型是不是也用到了这些, 感觉有些复杂).
Session-based Recommendations
什么是 session-based recommendation ? 这是结合实际场景的一个问题, 在实际中, 由于隐私保护等因素, 可能导致我们无法知道当前用户是具体哪个用户, 所以我们没法利用一些额外的属性. 但是在这一次浏览行为中, 该用户往往会连续点击一些物品 (称为一个 session) \(i_1, i_2, i_3, \cdots\), 所以我们的目标是根据该 seesion 来判断出下一个用户可能点击的物品, 并给予推荐.
GRU
下图描述了 GRU 的一个流程 (摘自邱老师的 《神经网络与深度学习》):
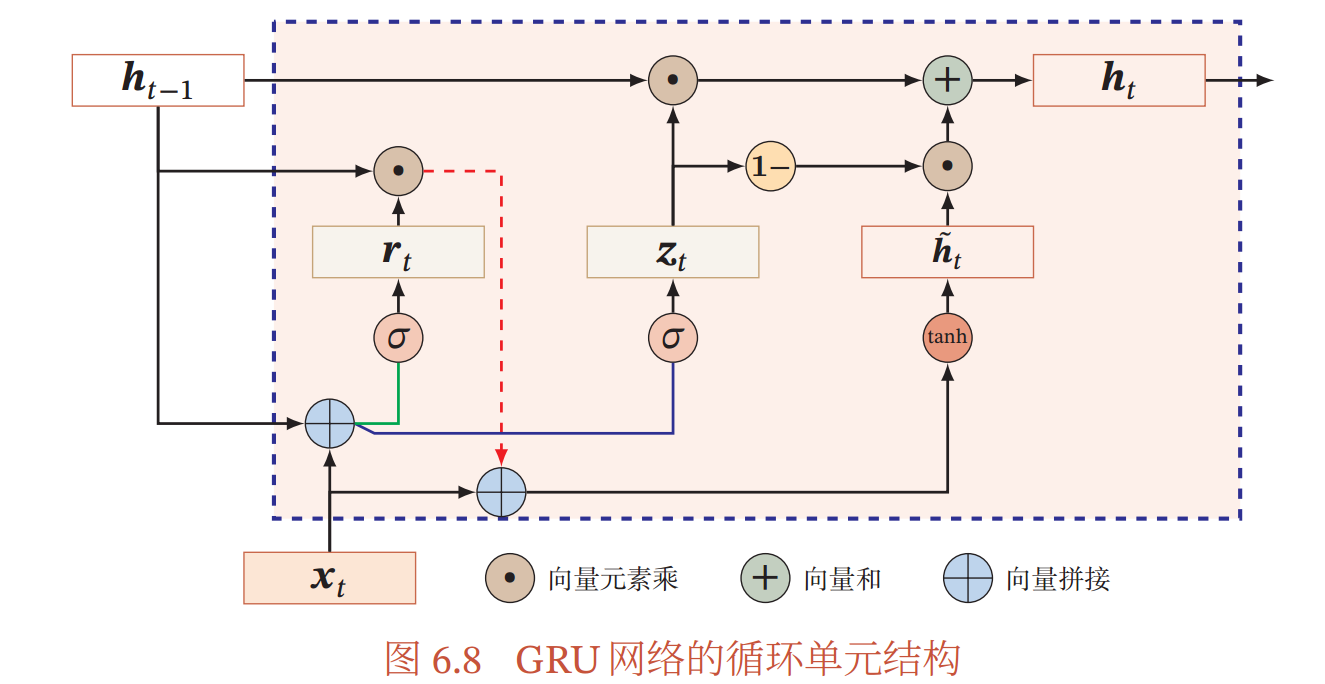
每一个循环包括如下过程:
即当前时刻的隐变量 \(\bm{h}_t\) 由上一时刻的隐变量 \(\bm{h}_{t-1}\) 和候选隐变量 \(\hat{\bm{h}}_t\) 决定. 更新门 \(\bm{z}\) 决定了更倾向于前者还是更新:
其中 \(\bm{r}_t\) 为重置门:
GRU4Rec
GRU4Rec 的形式如下:

- 给定 item 序列 \([i_1, i_2, \cdots, i_k]\);
- 通过 embedding layer (注意, GRU4Rec-pytorch 的代码中默认使用 one-hot vector) 得到 embeddings \([\bm{x}_1, \bm{x}_2, \cdots, \bm{x}_k\);
- 初始化 hidden 变量 \(\bm{h}_0 = \bm{0}\), 然后输入 GRU 网络得到最后的特征 \(\bm{h}_k\);
- 通过一个前向的线性网络得到最后的 logits \(\bm{z} \in \mathbb{R}^{|\mathcal{I}|}\), 它的每一个元素反应了 next-item 的得分, 得分越高者越应该被推荐.
Session-parallel mini-batches
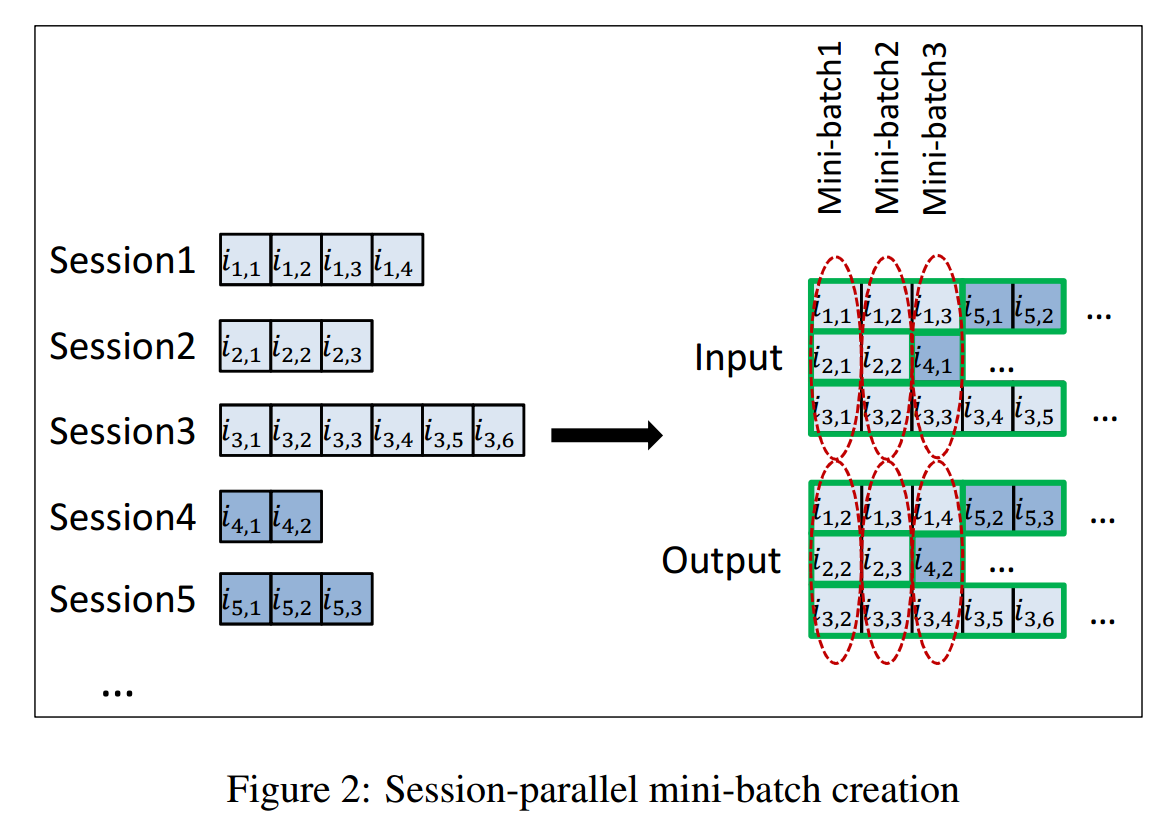
我们要知道, 在实际中的数据中, 每个 session 的长度是不一样的, 所以为了效率, 作者提出了一种 session-parallel mini-batches 的机制, 说实话如果不是看代码, 我大概是理解不了的. 不妨就以图中的 batch_size=3 为例吧:
-
首先, 前三个 sessions 被选中, 第一次的输入为:
\[\left [ \begin{array}{l} i_{1, 1} \\ i_{2, 1} \\ i_{3, 1} \\ \end{array} \right ], \]用来预测
\[\left [ \begin{array}{l} i_{1, 2} \\ i_{2, 2} \\ i_{3, 2} \\ \end{array} \right ]; \] -
然后下一次,
\[\left [ \begin{array}{l} i_{1, 2} \\ i_{2, 2} \\ i_{3, 2} \\ \end{array} \right ]; \]用来预测
\[\left [ \begin{array}{l} i_{1, 3} \\ i_{2, 3} \\ i_{3, 3} \\ \end{array} \right ]; \] -
此时, session 2 到头了, 没法继续下去了, 所以把 session 2 替换成 session 4:
\[\left [ \begin{array}{l} i_{1, 3} \\ i_{4, 1} \\ i_{3, 3} \\ \end{array} \right ]; \]用来预测
\[\left [ \begin{array}{l} i_{1, 4} \\ i_{4, 2} \\ i_{3, 4} \\ \end{array} \right ]. \] -
以此类推.
需要特别说明的是, 正因为如此, 每次需要 reset hiddens, 还要保留一个 mask, 这是 GRU4Rec-pytorch 代码中所做的, 还怪麻烦的.
文中提的 TOP1 损失这里不提了.
Evaluation: 对于测试中的序列 \([i_1, i_2, \cdots, i_k]\), 需要利用 \(i_1\) 预测 \(i_2\), 利用 \(i_2\) 预测 \(i_3\) ..., 不知道现在主流的是不是也是这样.

