Chen R. T. Q., Rubanova Y., Bettencourt J. and Duvenaud D. Neural ordinary differential equations. In Advances in Neural Information Processing Systems (NIPS), 2018.
概
本文提出了一种新的网络架构, 从 ODE 出发, 将神经网络的中间状态视作 ODE 中的某个状态, 而我们所需要做的只是拟合整个过程的 '动力' 部分, 即梯度.
符号说明
-
ODE:
dh(t)dt=f(h(t),t),(1)
给定初始值 h(0), 也可以写成如下的积分形式:
h(t)=h(0)+∫t0f(h(τ),τ)dτ.(2)
-
对于 f(x):Rd→Rd′, 定义
∇xf=⎡⎢
⎢
⎢
⎢
⎢
⎢
⎢
⎢⎣∂f1∂x1∂f2∂x1⋯∂fd′∂x1∂f1∂x2∂f2∂x2⋯∂fd′∂x2⋮⋮⋱⋮∂f1∂xd∂f2∂xd⋯∂fd′∂xd⎤⎥
⎥
⎥
⎥
⎥
⎥
⎥
⎥⎦∈Rd×d′.
基本框架
-
设想我们给定一输入 z(t0), 我们希望拟合'动力' f(z(t),t;θ) 来推动其状态
z(t0)→z(T;θ)=z(t0)+∫Tt0f(z(τ),τ;θ)dτ.(3)
-
然后我们利用最终状态 z(T) 来进行一些下游任务. 我们训练 θ, 我们可以利用损失函数:
L(z(T;θ))(4)
进行训练.
-
通常 z(t0)→z(T) 不是傻乎乎积分得到的, 而是通过一些数值近似方法, 比如: Euler 方法:
h(t+s)=h(t)+sf(h(t),t),(5)
其中 s 是每一步迭代的步长.
-
非常有意思的是, 当我们去 s=1 的时候:
h(t)=h(t)+f(h(t),t),(6)
这实际上就是鼎鼎大名的残差连接. 当然对于 ResNet 而言, 它的'动力模块' f(h(t);θt) 对于每一个 block 都是不同的. 而 NODE 的思想是我们只拟合一个这样的'动力模块'.
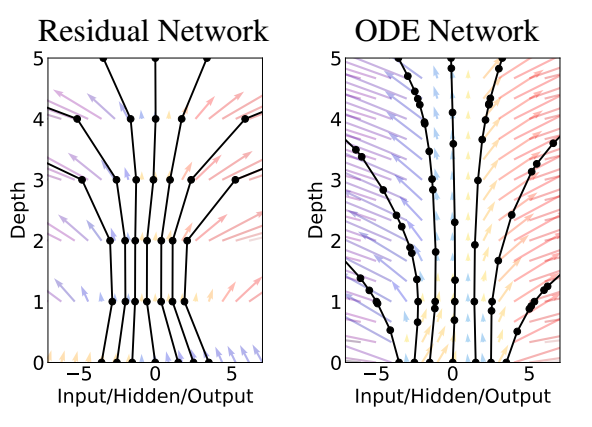
- 那么 NODE 的优势体现在哪儿呢 ? 就是对于 (3) 的近似上, 我们不单单可以采用简单的 Euler 方法 (s=1), 步长可以更加精细, 甚至可以学习, 此外也可以用一下更复杂的数值近似方法, 比如 Runge-Kutta.
连续的反向传播
-
为了能够训练 θ, 前提是我们能够计算出梯度
∇θL.(7)
-
为了便于推导, 我们假想 θ,t 也随着整个过程变化, 只是
∇tθ(t)=0,dt(t)dt=1.(8)
-
此时我们可以定义
a(t):=∇z(t)L,aθ(t):=∇θ(t)L,at(t):=dLdt(t).(9)
-
再定义增广的向量:
zaug:=⎡⎢⎣z(t)θ(t)t(t)⎤⎥⎦,faug(zaug)=⎡⎢⎣f(zaug)01⎤⎥⎦,aaug=⎡⎢⎣aaθat⎤⎥⎦.(10)
-
于是我们可以将 (3) 改写为
zaug(t)=zaug(t0)+∫tt0faug(zaug(τ))dτ.(11)
-
另一种有助于求梯度的形式:
zaug(t+ϵ)=zaug(t)+∫t+ϵtfaug(zaug(τ))dτ.(12)
-
可知 (链式法则):
aaug(t)=∇zaug(t)L=∇zaug(t)zaug(t+ϵ)∇zaug(t+ϵ)L=∇zaug(t)zaug(t+ϵ)aaug(t+ϵ)(13)
-
此外, 注意到 (12) 的一阶泰勒近似为:
zaug(t+ϵ)=zaug(t)+faug(zaug(t))ϵ+O(ϵ2)⇒∇zaug(t)zaug(t+ϵ)=I+ϵ∇zaug(t)faug+O(ϵ2),(14)
其中
∇zaug(t)faug(zaug(t))=⎡⎢
⎢⎣∇zf00∇θf00dfdt00⎤⎥
⎥⎦.(15)
注: 这里和下面的 ∇θf(z,θ) 都是指关于 θ 变元求梯度 (此时不能再通过 ∇θz 再求导下去), 否则加上就乱套了, 也就是说, 我们在这里简单地认为 z 和 θ 无关.
-
故
daaug(t)dt=limϵ→0aaug(t+ϵ)−aaug(t)ϵ=limϵ→0aaug(t+ϵ)−∇zaug(t)zaug(t+ϵ)aaug(t+ϵ)ϵ=limϵ→0aaug(t+ϵ)−(I+ϵ∇zaug(t)faug+O(ϵ2))aaug(t+ϵ)ϵ←(14)=limϵ→0−{ϵ∇zaug(t)faug+O(ϵ2)}aaug(t+ϵ)ϵ=limϵ→0−{∇zaug(t)faug+O(ϵ)}aaug(t+ϵ)=−∇zaug(t)faug(zaug)aaug(t).(16)
-
具体地 (根据 (15)):
da(t)dt=−[∇zf]a,daθ(t)dt=−[∇θf]a,dat(t)dt=−dfdta.(17)
-
于是乎:
∇z(t)L=a(t)=a(T)−∫tT[∇zf(z(τ),τ;θ)]a(τ)dτ,∇θ(t)L=aθ(t)=aθ(T)−∫tT[∇θf(z(τ),τ;θ)]a(τ)dτ,∇t(t)L=at(t)=at(T)−∫tT[∇tf(z(τ),τ;θ)]a(τ)dτ.(18)
其中
a(T)=∇z(T)L,at(T)=∇z(T)L∇Tz(T)=[∇z(T)L]f(z(T),T;θ).(19)
至于 aθ(T) 作者说可以设它为 0, 个人感觉是因为:
aθ(T)=∇θTL=∇z(T)L∇θTz(T)=∇z(T)L{∇θT∫Tt0f(z(τ),τ;θ(τ))dτ},(20)
由于在积分中 θT 只有一瞬, 故可以认为 aθ(T)=0. 不晓得这么理解正确与否.
-
让我们再通过离散化来仔细分析一下, 假设定性 [t0,T] 为 [0,K], 并用一般的 Euler 方法进行前向的扩散 (且步长为 1), 则
z(t+1)=z(t)+f(z(t),t;θ),t=0,1,⋯,K−1.
-
倘若我们对 (18) 也采用 Euler 的方式近似:
aθ(t)=aθ(t+1)+∇θf(z(t+1),t+1;θ)∇z(t+1)L.≈aθ(t+1)+∇θf(z(t),t;θ)∇z(t+1)L.
故
aθ(0)≈T−1∑t=0∇θf(z(t),t;θ)∇z(t+1)L.
这完全和我们直接利用反向传播公式得到的结果是一致的.
-
当然, 也可以用一般的 ODE Solver 来更加复杂地近似求解梯度, 正如作者给出的算法 (符号和这里定义的略有不同):

注: 我看了一篇契合 NODE 的应用于推荐系统的文章, 发现他仅仅是在前向的过程中用到了 ODE Solver, 后向就是用的普通的传播, 如果仅仅这样效果就很好了的话, 那这个潜力还是相当大的. 因为很重要的一点是时间 t 实际上都是可以训练的, 这意味着我们的模块间的远近都可以自动学习.
注: 在各个场景下的应用也是非常精彩的.
代码
[torchdiffeq]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix