SVD-GCN: A Simplified Graph Convolution Paradigm for Recommendation
概
又是一篇通过 k-largest 特征向量来缓解 over-smoothing 的 (和 Less is More 一个作者).
符号说明
-
\(\mathcal{U}\), users;
-
\(\mathcal{I}\), items;
-
\(R \in \{0, 1\}^{\mathcal{|U| \times |I|}}\), 交互矩阵;
-
\(R^+ = \{r_{ui} = 1| u \in \mathcal{U}, i \in \mathcal{I}\}\);
-
邻接矩阵:
\[A = \left [ \begin{array}{ll} 0 & R \\ R^T & 0 \end{array} \right ]; \] -
\(\tilde{R} = D_l^{-1/2} R D_r^{-1/2}\), 为 \(R\) 经过行列标准化后的交互矩阵, 可以类似定义 \(\tilde{A}\).
本文方法
-
假设 embeddings 初始化为 \(E \in \mathbb{R}^{\mathcal{(|U|+|V|) \times d}}\), 则 LightGCN 可以表述为:
- \(H^{(l)} = \tilde{A}^{l} E\);
- \(O = \frac{1}{L + 1} \sum_{l=0}^L H^{(l)}\), 其中 \(H^{(0)} = E\);
-
它可以总结为
\[\tag{1} O =\Bigg \{ \sum_{l=0}^L \frac{1}{L + 1} \tilde{A}^{l} \Bigg \} E. \] -
倘若我们假设 \(\tilde{R}\) 可以分解为 (SVD):
\[\tilde{R} = P\Sigma Q^T, \]其中 \(P \in \mathbb{R}^{\mathcal{|U| \times |U|}}, Q \in \mathbb{R}^{\mathcal{|V| \times |V|}}\), 此外 \(\Sigma \in \mathbb{R}^{\mathcal{|U| \times |V|}}\) 的对角线元素为奇异值 \((\sigma_1, \sigma_2, \ldots, \sigma_{\min(\mathcal{|U|, |V|})})\);
-
因为
\[\tilde{A} = \left [ \begin{array}{cc} 0 & P\Sigma Q^T \\ Q \Sigma^T P^T & 0 \end{array} \right ] = \left [ \begin{array}{cc} P & 0\\ 0 & Q \end{array} \right ] \cdot \left [ \begin{array}{cc} 0 & \Sigma\\ \Sigma^T & 0 \end{array} \right ] \cdot \left [ \begin{array}{cc} P^T & 0\\ 0 & Q^T \end{array}. \right ] \]令
\[V = \left [ \begin{array}{cc} P & 0\\ 0 & Q \end{array} \right ], \quad \Lambda = \left [ \begin{array}{cc} 0 & \Sigma\\ \Sigma^T & 0 \end{array} \right ] \cdot \] -
由此, 我们可以进一步将其 \(O\) 分解为
\[\tag{1} O = V\Bigg \{ \sum_{l=0}^L \frac{1}{L + 1} \Lambda^{l} \Bigg \} V^T E =V\Bigg \{ \sum_{l=0}^L \frac{1}{L + 1} \Lambda^{l} \Bigg \} \left [ \begin{array}{c} P^T E_U\\ Q^T E_I \end{array}, \right ] \]又
\[\Lambda^{2l} = \left [ \begin{array}{cc} \Sigma \Sigma^T & 0\\ 0 & \Sigma^T \Sigma \end{array} \right ], \]故 (1) 可以进一步改写为
\[\begin{array}{ll} (L+1) O &= \left [ \begin{array}{cc} P \sum_{l=0,2,\ldots}(\Sigma \Sigma^T)^{l/2} & 0\\ 0 & Q \sum_{l=0,2,\ldots}(\Sigma^T \Sigma)^{l/2} \end{array} \right ] \cdot \left [ \begin{array}{c} P^T E_U\\ Q^T E_I \end{array} \right ] \\ &+ \left [ \begin{array}{cc} 0 & P \Sigma \sum_{l=1,3,\ldots}(\Sigma^T \Sigma)^{l/2} \\ Q\Sigma^T \sum_{l=1,3,\ldots}(\Sigma \Sigma^T)^{l/2} & 0 \end{array} \right ] \cdot \left [ \begin{array}{c} P^T E_U\\ Q^T E_I \end{array} \right ]. \end{array} \]故
\[(L+1) O_{U} = P \sum_{l=0,2,\ldots}(\Sigma \Sigma^T)^{l/2}P^TE_U + P \Sigma \sum_{l=1,3,\ldots}(\Sigma^T \Sigma)^{l/2} Q^T E_I, \\ (L + 1) Q_I = Q \sum_{l=0,2,\ldots}(\Sigma^T \Sigma)^{l/2} Q^T E_I + Q\Sigma^T \sum_{l=1,3,\ldots}(\Sigma \Sigma^T)^{l/2} P^TE_U. \] -
作者将 \(P^T E_U, Q^T E_I\) 替换为可训练的参数:
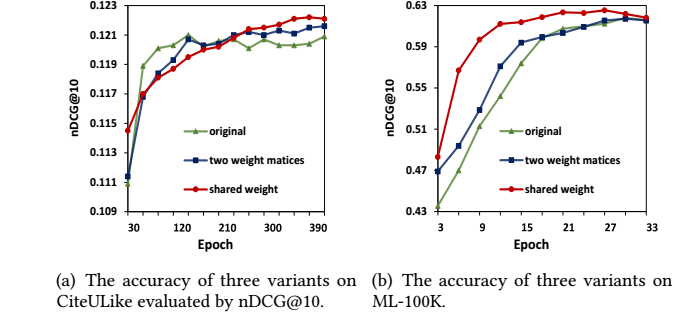
\[(L+1) O_{U} = P \sum_{l=0,2,\ldots}(\Sigma \Sigma^T)^{l/2} W_P + P \Sigma \sum_{l=1,3,\ldots}(\Sigma^T \Sigma)^{l/2} W_Q, \\ (L + 1) Q_I = Q \sum_{l=0,2,\ldots}(\Sigma^T \Sigma)^{l/2} W_Q + Q\Sigma^T \sum_{l=1,3,\ldots}(\Sigma \Sigma^T)^{l/2} W_P, \]然后进行训练, 得到了如下的一个结果, 其中
1. original 表示 LightGCN;
2. two ... 表示上述情况;
3. shared weight, \(W_P = W_Q\), 注意这里有一点点小问题, 因为作者用的是另外一种 SVD 表示法, \(P, Q\) 为保留非零特征的结果, 此时 \(W_P, W_Q\) 的大小是一致的;
在这三种情况下, 反而共享参数这一参数量最少的情况效果最好, 说明现在的 GCN 是有很大容易的 (对于推荐系统而言).
-
所以, 本文的模型可以简化为:
\[O_{U} = \frac{1}{L+1} P \sum_{l=0,2,\ldots}(\Sigma \Sigma^T)^{l/2} W \\ O_{I} = \frac{1}{L+1} Q \sum_{l=0,2,\ldots}(\Sigma^T \Sigma)^{l/2} W, \]其中 \(P \in \mathbb{R}^{\mathcal{|U| \times} K}, Q \in \mathbb{R}^{\mathcal{|V| \times} K}\), 此外 \(\Sigma \in \mathbb{R}^{K \times K}\).
-
为了效率, 我们可以仅仅挑选 K-largest 的特征;
-
为了进一步解决 over-smoothing 的现象, 作者定义
\[\dot{R} = (D_l + \alpha I)^{-1/2} R (D_r + \alpha I)^{-1/2}, \]以保证最大奇异值 \(< 1\);
-
同时, 和 Less is More 一样, 对每一层的特征重加权:
\[O_{U} = P \sum_{l=0,2,\ldots} \alpha_l (\Sigma \Sigma^T)^{l/2} W = P \text{diag}(\psi(\sigma)) W \\ O_{I} = Q \sum_{l=0,2,\ldots} \alpha_l (\Sigma^T \Sigma)^{l/2} W = Q \text{diag}(\psi (\sigma)) W, \]其中 \(\psi(\sigma) = \exp(\beta \sigma)\).
-
损失可以定义为
\[\mathcal{L}_{main} = \sum_{u \in \mathcal{U}} \sum_{(u, i^+) \in R^+, (u, i^-) \in R^-} \ln \sigma(o_u^T o_{i^+} - o_u^T o_{i^-}); \] -
除此之外, 还有 user-user, item-item 间的损失:
\[\mathcal{L}_{user} = \sum_{u \in \mathcal{U}} \sum_{(u, u^+) \in \mathcal{E}_U, (u, u^-) \not \in \mathcal{E}_U} \ln \sigma(o_u^T o_{u^+} - o_u^T o_{u^-}), \\ \mathcal{L}_{item} = \sum_{i \in \mathcal{I}} \sum_{(i, i^+) \in \mathcal{E}_I, (i, i^-) \not \in \mathcal{E}_I} \ln \sigma(o_i^T o_{i^+} - o_i^T o_{i^-}). \]这里 user-user 为正样本若存在一个 item 直接连接二者, item-item 的正样本也是类似定义的.
代码
[official]

