GNNExplainer: Generating Explanations for Graph Neural Networks
概
本文介绍了一种后处理的可解释方案: 即给定一个训练好的 GNN, 对它给予解释.
符号说明
- , 图;
- , 维的 node features;
- , GNN 将结点映射为类别 .
本文方法
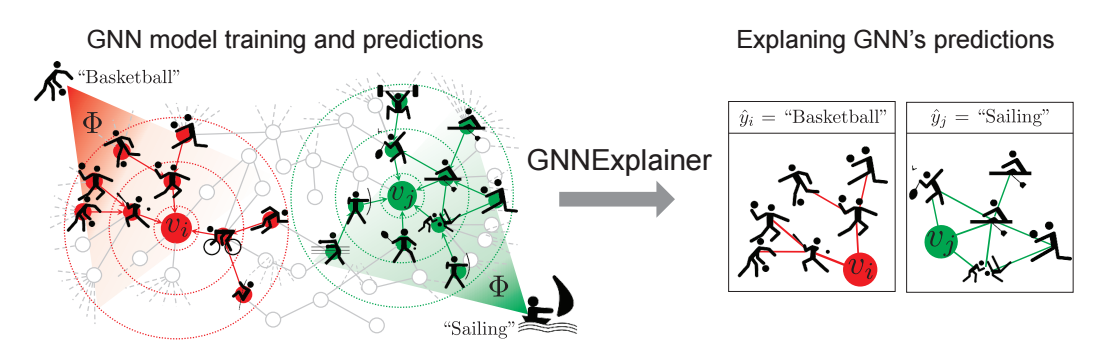
-
作者希望通过一个结点的 local subgraph 来解释某个结点的预测标签为什么是 . 如上图所示, 的朋友们都非常享受球类运动, 所以 GNN 预测他可能喜欢篮球.
-
假设完整的图为 , 作者希望为结点 找到一个子图 , 以及部分特征 来解释 ;
-
首先, 作者希望通过子图 , 具备足够的预测 的信息, 即:
因为 是不变的, 所以等价于
当然了, 如果 本身没有限制的话, 它就会倾向于 , 所以我们希望 是比较小的:
-
但是上述问题其实很难优化, 因为 本身是在一个离散的空间上, 很自然地, 作者将邻接矩阵放松到 , 且 , 即只有 原本存在的边才有可能非零. 我们可以将其理解为边存在的概率, 于是 就可以理解为采样得到的一个图, 此时 (2) 需要改写为:
其中 是由 引出的分布, .
既然信息熵是凹的, 倘若整体关于 也是凹的 (虽然实际上不现实, 但是作者的实验证明下面的优化目标用起来还可以), 则: -
实际上, 我们可以直接建模 为
其中 为 mask, 为 sigmoid 激活函数将其映射到 .
-
于是乎, 我们的目标为:
需要注意的是, 为了最后获得稀疏的结果, 需要对 进行截断处理.
-
类似地, 我们可以对特征添加 mask , 用其为 1 的部分来表示对预测重要的特征部分:
作者说这种建模方式会导致 的值趋向 但是那个特征依旧很重要的情况, 改用如下的建模方式:
其中 采样自经验分布.
注: 这一块不是很理解, 应该是借鉴自图像的可解释 [48].
代码
[official]
分类:
Robust Learning



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix