Towards Self-Explainable Graph Neural Network
概
SE-GNN 试图构造一个本身就有可解释能力的 GNN.
符号说明
- \(\mathcal{G = (V, E}, X)\), 图;
- \(\mathcal{V} = \{v_1, \ldots, v_N\}\), nodes;
- \(\mathcal{E} \subset \mathcal{V \times V}\), edges;
- \(X = \{\bm{x}_1, \ldots, \bm{x}_N\}\), 特征;
- \(A \in \mathbb{R}^{N \times N}\), 邻接矩阵;
- \(\mathcal{V}_L\), labeled nodes, 其中结点的标签记为 \(\bm{y}_i \in \mathcal{Y}\), 此为 one-hot 向量;
- \(\mathcal{V}_U = \mathcal{V} \setminus \mathcal{V}_L\), unlabeled nodes;
- \(\mathcal{N}^{(n)}(v_i)\), \(v_i\) 的 n-hop 邻居;
- \(\mathcal{G}_s^{(n)}(v_i) = (\{v_i\} \cup \mathcal{N}^{(n)}(v_i), \mathcal{E}_s^{(n)}(v_i))\) n-hop subgraph;
Motivation
-
以往的可解释 GNN 往往采取重新训练一个模型来解释特定的 GNN, 作者认为这种做法存在 bias, 所以作者希望能够构造一个本身具有可解释能力的 GNN;
-
作者认为, node 分类最重要的是关注 node features 以及它们的 local structures:
- 两个结点如果它们的特征相似, 那么它们的标签可能是一致的;
- 两个结点如果它们的局部的结构相似, 那么它们的标签也可能是一致的;
-
所以本文就从这两个方面出发, 介绍如何建模点和点的特征相似度以及结构特征相似度.
相似度
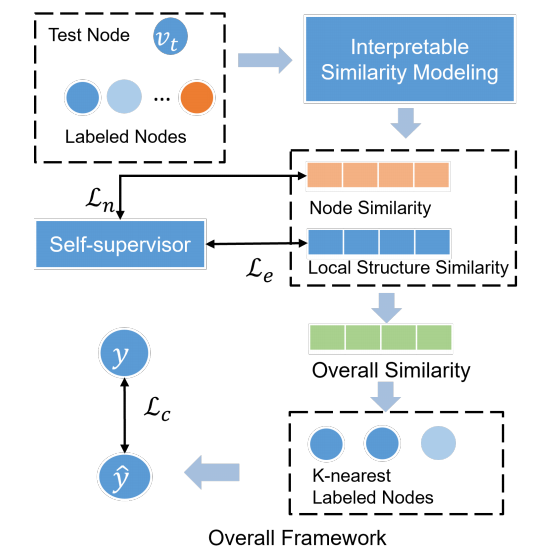
点相似度
-
以往的抓住结点间的相似度, 往往通过一个复杂的 GNN 将其转换为特征, 然后用类似 cosine 相似度来度量, 但是一旦用上了复杂的 GNN, 那么就不可避免地混淆了结构信息;
-
所以作者希望避免这一点:
\[H^m = \text{MLP}(X), \: H = \sigma(\tilde{A}H^m W) + H^m, \]即通过 MLP 紧接一个单层的 GCN.
-
于是两个结点的点相似度可以定义为:
\[s^n(v_t, v_l) = sim(\bm{h}_t, \bm{h}_l), \]其中 \(sim\) 可以用比如 cosine 相似度.
结构相似度
- 如果两个结点具有相似的 n-hop 子图的话, 那么两个结点本身也可能是相似的;
- 为了建模这一关系, 我们需要考虑两个结点的 n-hop 子图的边的匹配度:
- 首先定义 \(e = (v_i, v_j)\) 的表示:
\[\bm{e}_{ij} = f_e(\bm{h}_i, \bm{h}_j), \]其中 \(f_e\) 可以是池化或者 LSTM 等等;
2. 记两个子图 \(\mathcal{G}_s^{(n)}(v_t), \mathcal{G}_s^{(n)}(v_l)\) 的边特征集合为:\[\mathcal{R}_t = \{\bm{e}_t^1, \ldots, \bm{e}_t^M\}, \\ \mathcal{R}_l = \{\bm{e}_l^1, \ldots, \bm{e}_l^N\}; \\ \]- 为 \(\mathcal{R}_t\) 中的每一个边找到 \(\mathcal{R}_l\) 中的一个最相似的匹配:
\[e_p^i = \arg\max_{e_l^ \in \mathcal{E}_s^{(n)}(v_l)} sim(\bm{e}_t^i, \bm{e}_l^j), i=1,2, \ldots, M. \]并把这些配对记为\[\mathcal{P}^{(n)} (v_t, v_l) = \{ (e_t^i, e_p^i)\}_{i=1}^M. \]- 于是, 我们可以定义边的相似度:
\[s^e(v_t, v_l) = \frac{1}{M} \sum_{i=1}^M sim(\bm{e}_t^i, \bm{e}_p^i); \]
本文方法

-
有了点的相似度和结构的相似度, 我们可以定义两个结点的总的相似度:
\[s(v_t, v_l) = \lambda s^n(v_t, v_l) + (1 - \lambda) s^e(v_t, v_l); \] -
通过概相似度, 我们可以通过 KNN 找到 K 个最相邻的结点 \(\mathcal{K}_t = \{v_t^1, \ldots, v_t^K\}\);
-
很显然的, \(v_t\) 应该和最相似的那批点的标签保持一致 (这里假设 \(s(\cdot, \cdot)\) 越大越相似):
\[\hat{\bm{y}}_t := \sum_{i=1}^K a_{ti} \bm{y}_{t}^i, \]其中
\[a_{ti} = \frac{\exp(s(v_t, v_t^i) / \tau)}{\sum_{i=1}^K \exp(s(v_t, v_t^i)/ \tau)}; \] -
显然这个过程解释了 \(\hat{\bm{y}}_t\) 的来源;
-
此外, 我们还可以对边的重要性进行解释:
- 如果一条边很重要, 那么它应当在多个相似的子图中出现;
- 对于边 \(e_t^i\), 记 \(e_p^{ij}, j=1,2,\ldots, K\) 为 \(\mathcal{G}_s^{(n)}(v_t^j)\) 中匹配的点边, 则 \(e_t^i\) 的重要性可以衡量为:
\[p(e_t^i) = \frac{1}{K} \sum_{j=1}^K sim (\bm{e}_t^i, \bm{e}_p^{ij}). \]显然 \(p(e_t^i)\) 越大, 说明该边提供了很多的相似度, 自然是重要的边.
注: 如何 KNN 以及如何采样负样本近似等这里就不讲了.
代码
[official]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号