Zhu D., Zhang Z., Cui P. and Zhu W. Robust graph convolutional networks against adversarial attacks. In ACM International Conference on Knowledge Discovery and Data Mining (KDD), 2019.
概
RGCN 设计了一种 Gaussian-based 的模块, 利用 Variance 来设计 attention 用于提高网络的鲁棒性. 从我的理解来看, 它提高对抗鲁棒性的能力堪忧.
符号说明
- G=(V,E), 图;
- V={v1,…,vN}, nodes;
- A, 邻接矩阵;
- ~A, add self-loop;
- ~Dii=∑j~Aij;
- h(l)i, node vi 在第 l 层的特征表示;
- N(i)={v:(v,vi)∈E}∪{vi};
- ⊙, element-wise 乘法;
算法
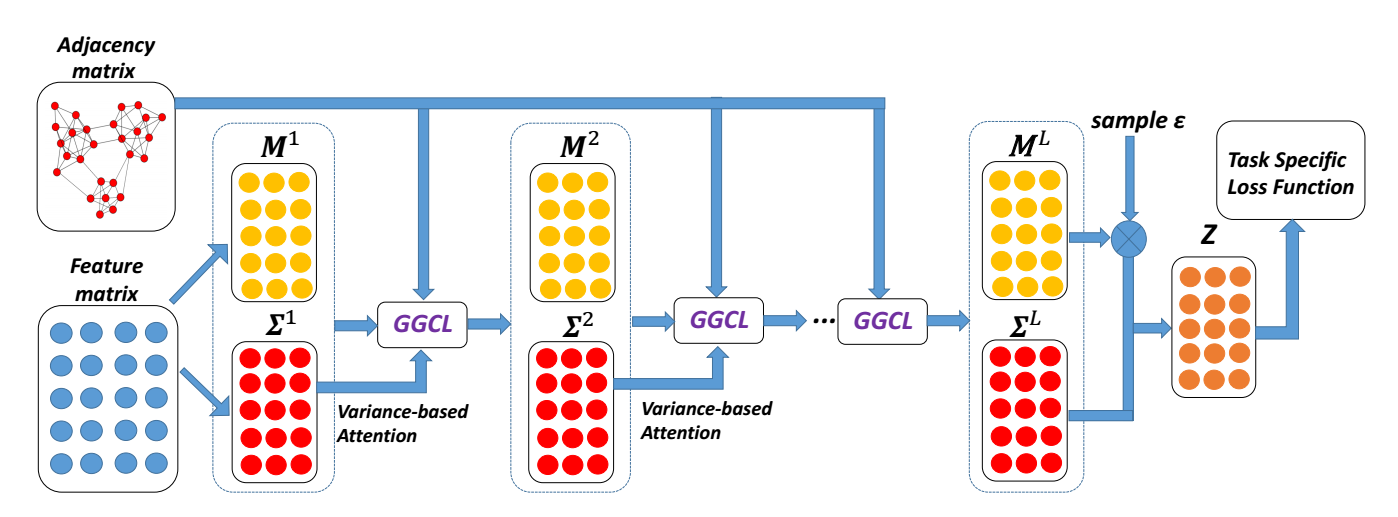
-
初始化均值和方差特征:
M(0)=[μ(0)1,μ(0)2,…,μ(0)N]T,Σ(0)=[σ(0)1,σ(0)2,…,σ(0)N]T,
假设
h(0)i∼N(μ(0)i,σ(0)i);
-
第 l 层进行如下操作:
-
首先计算 attention:
α(l)j=exp(−γσ(l−1)j),
可以看出, 方差越大对应的权重越小 (因为作者认为方差越大的越容易是噪声);
-
计算如下该层的均值和方差特征:
μ(l)i=ρ(∑j∈N(i)μ(l−1)j⊙α(l)j√~Dii~DjjW(l)μ),σ(l)i=ρ(∑j∈N(i)σ(l−1)j⊙α(l)j⊙α(l)j√~Dii~DjjW(l)σ);
此时
h(l)i∼N(μ(l)i,σ(l)i);
-
用矩阵表示为如下结果:
M(l)=ρ(~D−1/2~A~D−1/2(M(l−1)⊙A(l))W(l)μ),Σ(l)=ρ(~D−1/2~A~D−1/2(Σ(l−1)⊙A(l)⊙A(l))W(l)σ);
-
最后一层, 我们得到最后的输出:
zi=μ(L)i+ϵ⊙√σ(L)i,ϵ∼N(0,I);
-
最后通过如下损失进行训练:
L=Lcls+β1Lreg1+β2Lreg2,
其中 Lcls 就是普通的分类损失 (基于 zi), 然后
Lreg1=N∑i=1KL(N(μ(1)i,σ(1)i)∥N(0,I))
确保第一层的输出是正态分布?
Lreg2=∥W(0)μ∥22+∥W(0)σ∥22
为普通的对第一层的 L2 正则.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2021-10-07 Implicit Neural Representations with Periodic Activation Functions
2020-10-07 What is being transferred in transfer learning?
2019-10-07 pandas tutorial
2019-10-07 pandas tutorial 2