Krichene W. and Rendle S. On sampled metrics for item recommendation. KDD, 2020.
概
作者对推荐系统中 sampled-based ranking 的评估进行了批判.
符号说明
- x∈D, instance (user, query ...);
- I, item set, |I|=n;
- A, 推荐算法;
- y={y1,y2,…,yl}⊂I, instance x 所感兴趣的 items;
- R(A,x), 给定 instance x 和推荐算法 A, 返回 A 对 x 所感兴趣的 y 排序结果. 比如, x 对 y1,y2 感兴趣, 若 R(A,x)={3,5} 则表示 A 认为 y1,y2 在所有的 items 中的排名为 3 和 5 (排名从 1 开始, 越靠前说明算法认为这个 item 越适合 x).
- 注意: 在没有起义的情况下, 我们省略 A,x, 仅用 R 表示 R(A,x).
- M(R) 表示衡量排序结果 R 的一个指标.
- [n]={1,2,…,n}.
Metrics
-
给定 Metric M, 其在整个数据上的指标通常采用如下的方式测量:
1|D|∑x∈DM(R(A,x)).
-
接下来, 我们介绍推荐系统中一些常见的 M.
-
AUC:
AUC(R;n)=1|R|∑r∈R∑r′∈[n]∖Rδ(r<r′)n−|R|,
如果 |R|=1, 则有
AUC(R;n)=n−rn−1.
-
Precision:
Prec(R;k)=∑r∈Rδ(r≤k)k.
如果 |R|=1,
Prec(R;k)=δ(r≤k)k.
-
Recall:
Recall(R;k)=∑r∈Rδ(r≤k)|R|.
如果 |R|=1,
Recall(R;k)=δ(r≤k)1.
-
Average Precision:
AP(R;k)=1min(|R|,k)k∑i=1δ(i∈R)Prec(R;i).
如果 |R|=1,
AP(R;k)=δ(r≤k)r.
-
Normalized discounted cumulative gain:
NDCG(R;k)=1∑min(|R|,k)i=11log2(i+1)k∑i=1δ(i∈R)log2(i+1).
如果 |R|=1,
NDCG(R;k)=δ(r≤k)log2(r+1).
Sampled-based ranking
-
上面的指标都是 full-ranking, 即排序是在整个 item 集合 I 之上的.
-
但是, 如果 |I|=n 很大, 那么每次排序可能都需要很长的时间. 所以, 一种常用的 sampled-based ranking 是对于每个正样本 y, 采样 m 个负样本 i1,i2,…,im∉y.
-
然后 y 在 {y,i1,i2,…,im} 中的排名用于后续的评估.
例子
-
让我们看一个例子:

-
上图展示了三个不同的推荐系统 A,B,C 给五个实例的预测排名, 然后后面是精确的评估. 从其上的表现也可以发现:
- AUC 是一个很 mean 的指标, 它要求推荐系统一视同仁;
- AP, NDCG 比较在意排名靠前的结果.
- Recall@10 对排名 10 之前的一视同仁, 但是之后的就会有极大的惩罚.
-
实际上, 这些指标对于不同的 r 的评估结果如下 (|R|=1).
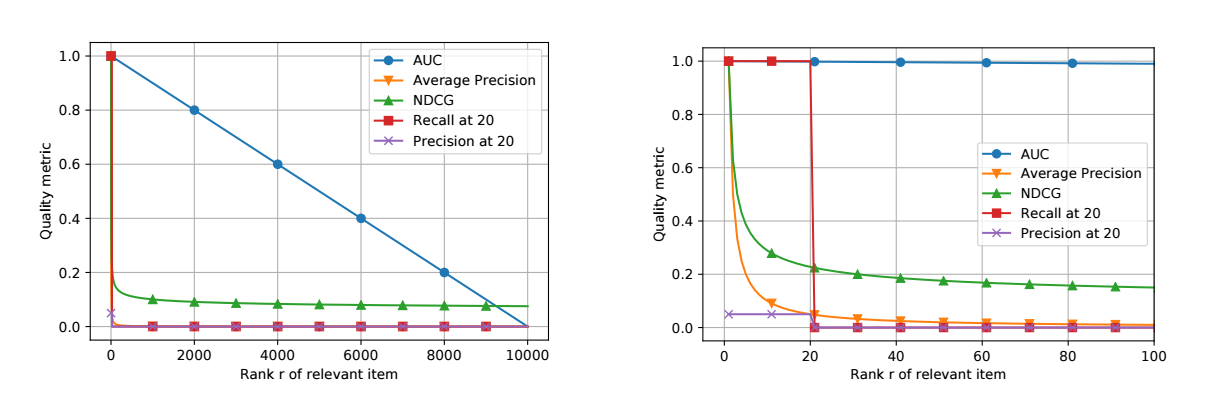
- 那, 如果我们按照 sampled-based ranking 评估会是怎么样的一个结果呢?

- 可以发现, 推荐系统 A 始终取得了一个最好的结果, 这说明:
- Sampled-based ranking 可能是不保序的, 即当 full-ranking 下 C 比 A 好的时候, 在 Sampled-based ranking 下可能会得出结果 A 比 C 好.
- Sampled-based ranking 下的不同指标, 如 AP, NDCG 等, 会变得 mean, 和 AUC 有着类似的倾向.
Sampled metrics
-
假设 |R|=1, 令 ~R 表示 Sampled-based ranking 下的排名. 一个很自然的愿景是保序性:
1|D|∑x∈DM(R(A,x))>1|D|∑x∈DM(R(B,x))⇔E[1|D|∑x∈DM(~R(A,x))]>E[1|D|∑x∈DM(~R(B,x))].
-
当然, 根据上面的分析, 我们已经发现这个性质是不成立的, 这里我们进一步看看到底是为什么. 为此, 我们需要计算 (注意, 我们假设 |R|=1)
E[M(~R)]=E[M(~r)]=m+1∑i=1p(~r=i)M(i).
-
p(~r=i) 是 target y 在样本 {y,i1,…,im} 中的排名为 i 的概率. 由于 ik 是均匀采样的, 故
p(j<r)=r−1n−1=1−AUC(r;n).
-
故, ~r 实际上等价于从如下分布中采样:
~r∼B(m,r−1n−1)+1,
其中 B(m,r−1n−1 表示成功概率为 r−1n−1 的二项分布.
-
故
p(~r=i)=(mi−1)(r−1n−1)i−1(n−rn−1)m−i+1.
-
此外, 我们有
E[~r]=mr−1n−1+1
-
接下来我们讨论不同的 matric 的期望.
-
AUC:
E~r[AUC(~r;m+1)]=E~r[m+1−~rm]=m+1−E~r[~r]m=m−mr−1n−1m=n−rn−1.
故 Sampled-based ranking 下, AUC 是无偏的.
-
Precision:
E~r[Prec(~r;k)]=E~r[δ(~r≤k)1k]=∑m+1i=1p(~r=i)δ(i≤k)1k=∑ki=1p(~r=i)1k=1kF(k−1;m,r−1n−1),
这里 F(k):=P(~r≤k) 表示二项分布的分布函数.
-
Recall:
E~r[Recall(~r;k)]=E~r[δ(~r≤k)]=∑m+1i=1p(~r=i)δ(i≤k)=∑ki=1p(~r=i)=F(k−1;m,r−1n−1),
-
AP:
E~r[AP(~r;k)]=E~r[δ(~r≤k)/~r]=∑m+1i=11ip(~r=i)δ(i≤k)=∑ki=1p(~r=i)⋅1i.
当 k=m+1, 且 r>1 的时候, 我们有
E~r[AP(~r;m+1)]=E~r[1~r]=E~r−1[1~r−1]=1−(1−p(j<r))m+1p(j<r)(m+1)=1−(n−rn−1)m+1(r−1)m+1n−1=1−AUC(r;n)m+1(r−1)m+1n−1.
这里, 我们用到了二项式分布的性质, 对于二项式分布 k∼B(m;p), E[1/(k+1)] 为
E[1k+1]=1−(1−p)m+1p(m+1).
-
非常有意思的是, 可以观测到:
- 当 AUC(r;n)≈0 的时候, 即推荐模型很差的时候, AP(~r;m+1) 和 和 AP(r;m+1) 给出的结果是一致的;
- 当 AUC(r;n)≈1 的时候, 显然我们需要采样很多的负样本, 即 m 比较大的情况下, 效果才能比较一致.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2019-09-11 Deep Linear Networks with Arbitrary Loss: All Local Minima Are Global