Localized Graph Collaborative Filtering
概
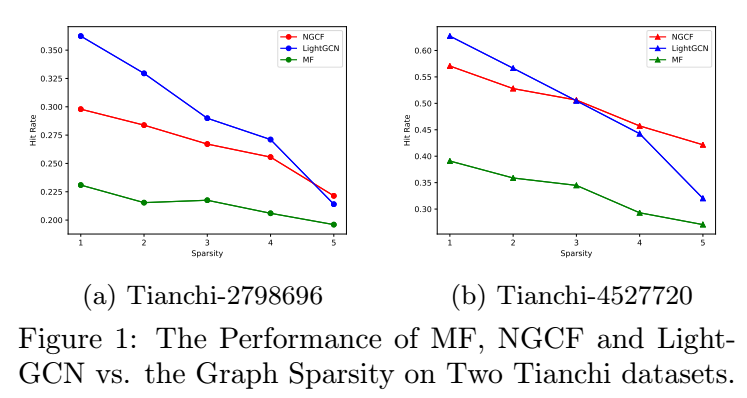
现在的推荐系统, 倾向于为每个 user, item 构建 embeddings. 但是和 NLP 中的问题不同, 推荐的数据往往是非常稀疏的, 所以这么做势必为带来一些训练上的一些问题. 这篇文章是这方面的一个尝试, 虽然感觉不是很成熟, 但是很有意义.
符号说明
- \(G = (\mathbf{U}, \mathbf{I}, \mathbf{E})\), 图 (user, item, edge);
- \(\mathbf{U} = \{u_1, u_2, \ldots, u_n\}\);
- \(\mathbf{I} = \{i_1, i_2, \ldots, i_m\}\);
- \(\mathbf{E} = \{e_0, e_1, \ldots, e_l\}\);
- \(s_{jk} = f(u_, i_k|\mathbf{E})\), 预测的分数;
本文方法
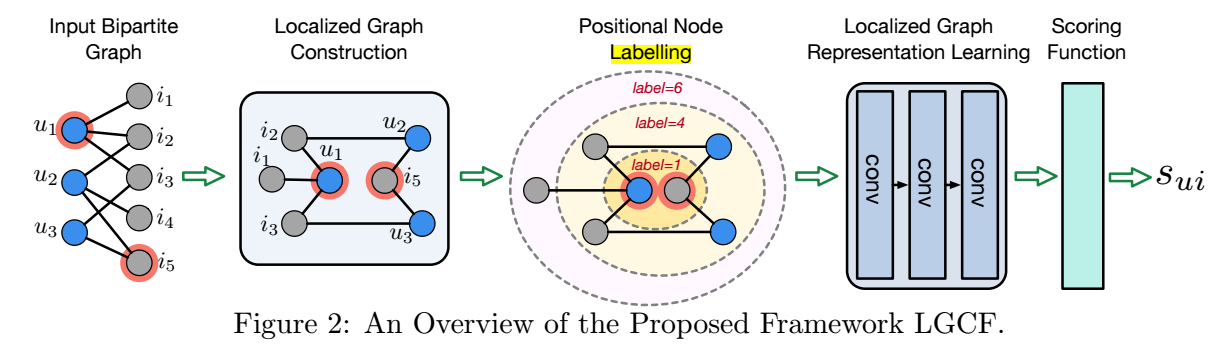
- 本文研究的问题: 在仅知道结点和他们之间的边的关系的条件下预测 \(u_j, i_k\) 的 score \(s_{jk}\);
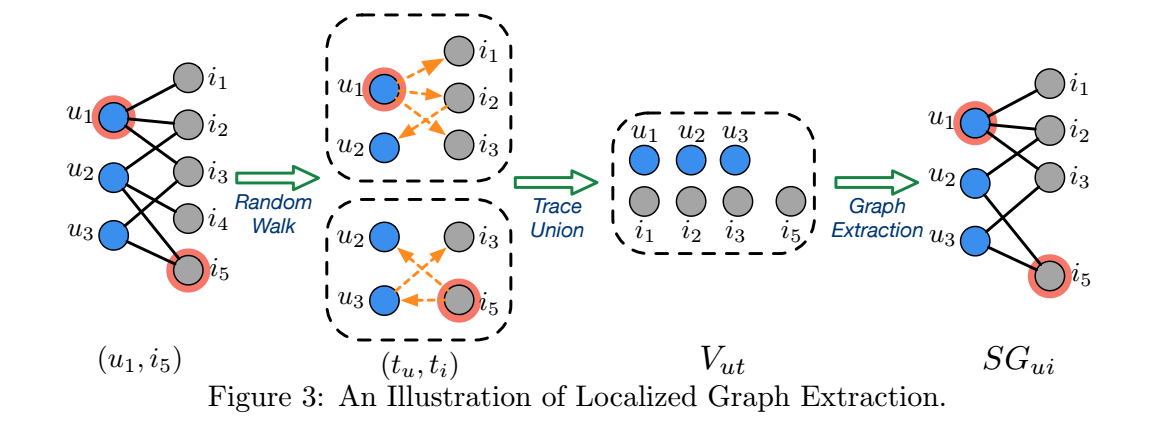
- 如上图所示, 假设我们想要预测 \(s_{ui}\), 则首先通过 random walk 来构建局部的子图:
- 分别从 \(u\) 和 \(i\) 出发, 通过 random walk with restart 各自得到一串序列 \(V_u, V_i\);
- \(V_{ui} = V_u \cup V_i\), 包含了所有经过的点, 在上图例子中, 仅 \(i_4\) 没有包括;
- 将 \(V_{ui}\) 和他们两两之间的边的关系保留, 构成一个新的子图;
-
将由 \((u, i)\) 出发所构建的子图的邻接矩阵即为 \(\mathbf{A}_{ui}\), 我们希望用这个子图来进行特征的提取:
\[\tag{3.2} \mathbf{X}_{l+1} = \sigma(\mathbf{\tilde{D}^{-1/2}} \tilde{\mathbf{A}}_{ui} \mathbf{\tilde{D}^{-1/2}} \mathbf{X}_l \mathbf{W}), \]并通过 sum pooling
\[\mathbf{x}_{ui} = \text{sum}(\mathbf{X}_L) \]得到最后的特征. 作者希望该特征能够反映 \((u, i)\) 间的一个关系, 并用如下方式进行预测
\[s_{ui} = \sigma(\mathbf{x}_{ui}^T \mathbf{w}). \] -
现在的问题是, 我们并不具备每个结点的信息 (信号) \(\mathbf{X}_0\), 为此, 作者打算人为地给结点赋予属性, 同时作者希望这个属性能够满足如下性质:
- 起始结点 \(u, i\) 的属性为 \(1\);
- 直观上, 若结点 \(v\) 距离 \(u(i)\) 比较接近, 那么它的值也应当离 \(u(i)\) 接近, 这里两个结点 \(u, v\) 的距离 \(d(u, v)\) 定义为二者的最短路径长度, 比如上图中 \(d(i_2, u_1) = 1, d(i_2, u_3) = 3\);
- 假如两个结点 \(x, y\) 到两个起始结点 \(u, i\) 的距离和是一样的, 即:\[d(x, u) + d(x, i) = d(y, u) + d(y, i), \]但是\[\min(d(x, u), d(x, i)) < \min(d(y, u), d(y, i)) \]则应当 \(x\) 的值要小于 \(y\);
-
作者于是采用如下的属性的定义方法:
\[f(v) = \left \{ \begin{array}{ll} 1 & v = u \text{ or } i \\ 1 + \min (d(v, u), d(v, i)) + [(d(v, u) + d(v, i)) / 2]^2 & \text{else}. \end{array} \right . \]
注: 最上面那张图中 labeling 应是指距离而不是文中所述的 label.
注: (3.2) 中的 \(W\) 我想应该是 \(W_l\), 因为 \(X_0 \in \mathbb{R}^{|V_{ui}|}\), 是一维向量, 所以 \(W_0\) 只能是标量 (若 \(W_0 = W_l\)). 如果每层采用不同的 \(W\), 就可以令 \(W_0 \in \mathbb{R}^{1 \times d_1}, W_l \in \mathbb{R}^{d_l \times d_{l+1}}\) 了.
注: 本文还讨论了和 LightGCN 的结合, 并没有特别的新意.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号