Wang C., Yu Y., Ma W., Zhang M., Chen C., Liu Y. and Ma S. Towards representation alignment and uniformity in collaborative filtering. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining (SIGKDD), 2022.
概
作者分析了特征 alignment 和 uniformity 的重要性, 并针对 BPR 进行了改进.
符号说明
- U, user;
- I, item;
- R={(u,i):u interacted with i};
- f(u),f(i)∈Rd, user u 和 item i 所对应的特征;
- s(u,i), u, i 间的 score, 比如用 f(u)Tf(i) 度量;
- BPR:
LBPR=1|R|∑(u,i)∈R−log[sigmoid(s(u,i)−s(u,i−))](1)
其中 i− 从 u×I∖R 中随机采样;
将 (1) 进行解剖, 可以得到
−log[sigmoid(s(u,i)−s(u,i−))]=−loges(u,i)es(u,i)+es(u,i−)=−s(u,i)+log(es(u,i)+es(u,i−))→−E(u,i)∼pposs(u,i)+logE(u,i)∼pdata(es(u,i)),
若令
s(u,i):=−∥f(u)−f(i)∥2,
则上式大约等价于
lalign=E(u,i)∼ppos∥f(u)−f(i)∥2,(2)
luniform=logE(u,i)∼pdatae−2∥f(u)−f(i)∥2,(3)
其中 ppos,pdata 分别表示 positive pair 间的分布, 和一般 pair 的分布.
虽然 BPR 损失的设计的确是兼顾了 alignment 和 uniformity, 使得 positive pair 之间互相靠近, 而 negative pair 间互相远离, 但是在实际情况中, 并非如此理想, 如下图所示:
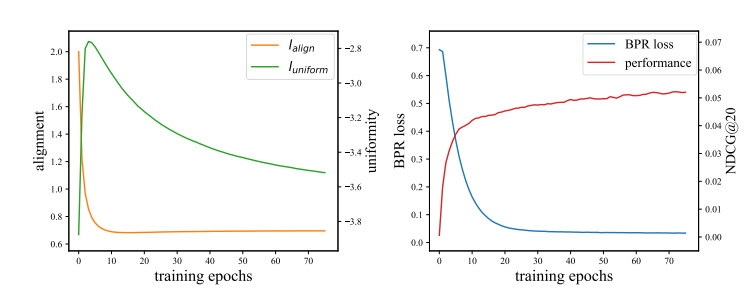
利用最普通的 MF 方法和 BPR 损失, 从上左图可以看见, lalign 会迅速下降, 即整体的 alignment 会迅速满足, 而代价是 uniformity 先增加再渐渐降低.
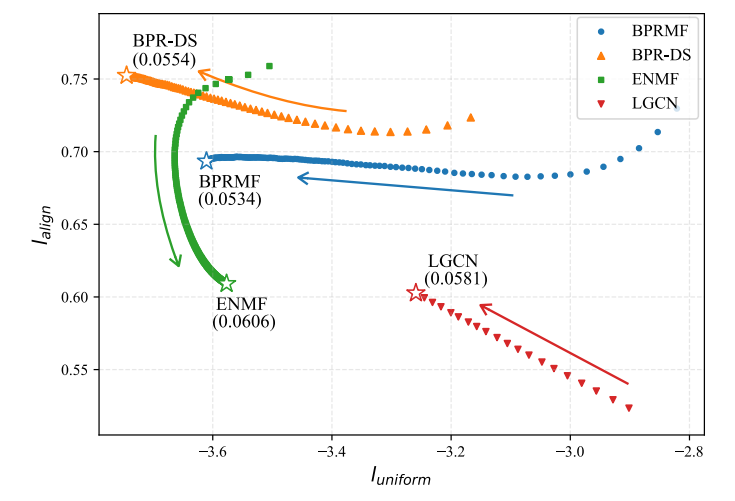
作者进一步在 BPRMF, BPR-DS, LGCN, ENMF 上进行实验, 发现兼顾 alignment 和 uniformity 的方法往往具有更好的表现. 此外, 普通的 BPR 本身是很难保证特别好的 alignment.
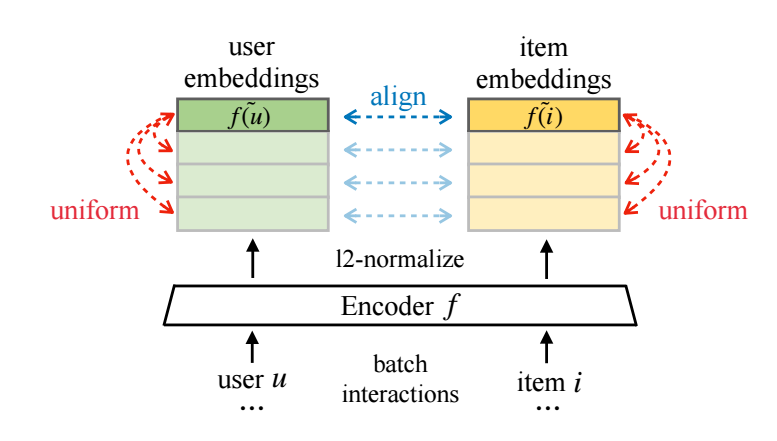
本文方法
-
对于 (u,i) 通过映射 f(⋅) 得到他们的特征表示:
f(u),f(i).
特别地, 作者直接采取 f(⋅) 为一 embedding table 加之 l2 normalization. 即假设 eu 为 u 的 embedding, 取
f(u)=eu∥eu∥,
虽然可以用更复杂的 encoder 来代替, 但是作者发现复杂的 encoder 所带来的提升并没有太多;
-
利用如下损失训练:
lalign=E(u,i)∼ppos∥f(u)−f(i)∥2,luniform=logE(u,u′)∼pusere−2∥f(u)−f(u′)∥2/2+logE(i,i′)∼piteme−2∥f(i)−f(i′)∥2/2,LDirectAU=lalign+γluniform.
大致如下图所示:
其他
作者还理论证明了 BPR 对于 Alignment 和 Uniformity 的倾向 (感觉并无意义), 感兴趣的不妨回看原文.
代码
[official]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix