Peng S., Sugiyama K. and Mine T. Less is more: reweighting important spectral graph features for recommendation. In International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2022.
概
图 embedding 学习的权重讨论, 高频和低频信息的重要性.
符号说明
-
U, user;
-
I, item;
-
|U|=M,|I|=N;
-
R∈{0,1}M×N, 交互矩阵;
-
E∈R(M+N)×d, embeddings;
-
邻接矩阵:
A=[0RRT0]∈{0,1}(M+N)×(M+N);
-
D,Dii=∑jAij,Dij=0 if j≠i;
-
~A=A+I,~D=D+I;
-
^A=~D−12~A~D−12;
-
Nu={i:rui=1}∪{u};
动机
-
现在的图网络用于推荐, 大抵每一次将邻居的点进行一个聚合得到第 (k+1) 层的特征:
h(k+1)u=σ(∑i∈Nu1√du+1√di+1h(k)iW(k));
-
用矩阵的形式表示即为
H(k+1)=σ(^AH(k)W(k+1));
-
最后通过
ou=pooling(h(0)u,…,hu(K))
来得到最后的特征;
-
并借此进行预测
^rui=oTuoi.
作者定义
∥s−^As∥
为信号 s 经过'聚合' 后的变化, 显然如果变化大, 说明整个图整体很不光滑. 倘若 s=vt 为一特征向量, 此时有
∥vt−^Avt∥=1−λt,
分解
^A=∑tλtvtvTt,
可知, λt 大的特征 vt 反而越光滑.
注: ^A 的特征值在 (−1,1] 内.
作者令
^A′=∑tM(λt)vtvTt,
其中 M(λ)∈{0,λ}. 作者将 (−1,1] 分成数份, 仅用其一所构成的矩阵 ^A′ 在普通的 GCN 和 LightGCN 上进行训练, 得到如下结果:
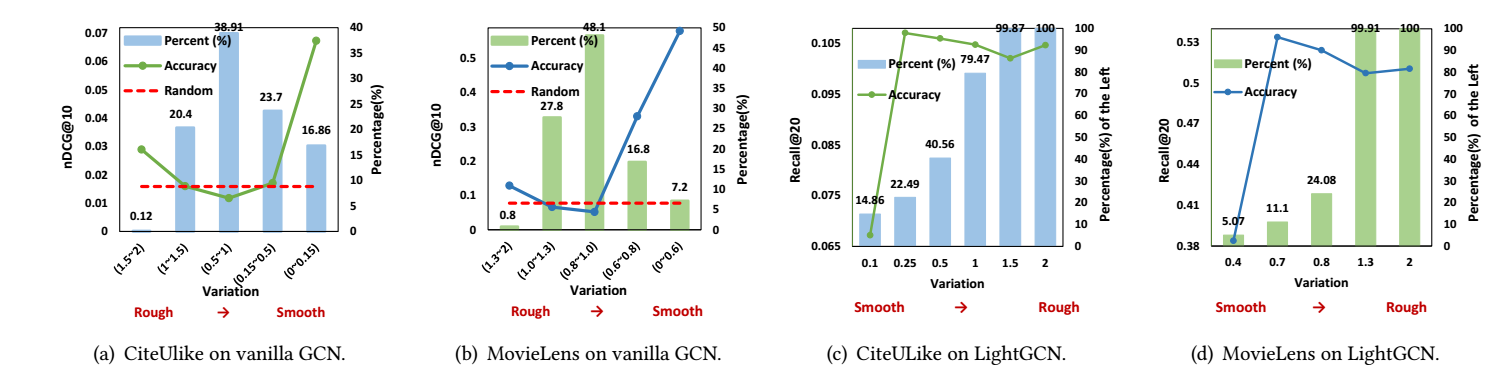
从中可以得到如下结论:
- 大部分 λt 其中在 [0.5,1.5];
- 少部分的对应粗糙 (rough) [0,0.15] 的特征和对应光滑 [1.5,2] 的特征对于预测准确率是最为重要的!
以 LightGCN 为例, 其可以表述为
O=K∑k=0αkH(k)=K∑k=0^AkK+1E=(∑t(K∑k=0λktK+1)vtvTt)E,
可见, LightGCN 仅是将 λt 用 ∑Kk=0λktK+1 替代, 倘若我们对不同的 t 画出其比例, 如下图可知, 随着 K 加深, LightGCN 实际上就是一种更倾向于 smooth 特征的做法罢了, 而根据先前的分析, (b) 可能更为合适.
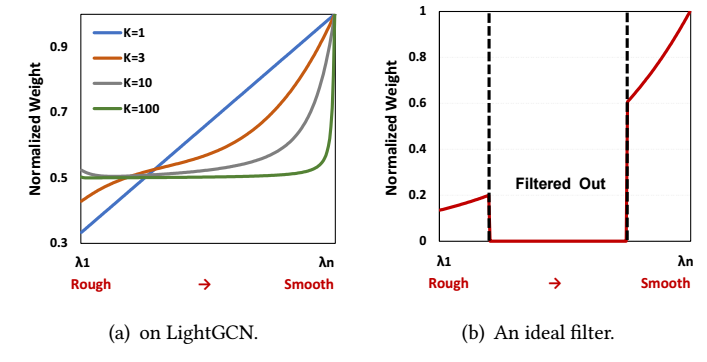
本文方法
-
定义user/item 的 hypergraphs:
AU=D−12uRD−1iRTD−12u∈RM×M,AI=D−12iRD−1uRTD−12i∈RN×N.
虽然看似复杂, 实际上就是一种'二阶'邻接矩阵罢了;
-
为这两个邻接矩阵, 分别进行矩阵分解:
AU=(P⊙π)PT,AI=(Q⊙σ)QT,
其中 P, π 分别为 AU 的特征向量和特征值, Q,σ 之于 AI 也是类似的;
-
假设我们希望保留的是一些最 smooth 特征和最 rough 特征, 不妨记
[P(s),π(s)],[P(r),π(r)]
为所对应的特征和特征值 (Q 也类似分解);
-
于是我们可以通过
H(s)U=([P(s)⊙γ(U,π(s))]P(s)T)EU,H(s)I=([Q(s)⊙γ(I,σ(s))]Q(s)T)EU,H(r)U=([P(r)⊙γ(U,π(r))]P(r)T)EU,H(r)I=([Q(r)⊙γ(I,σ(r))]Q(r)T)EU,
其中 γ(⋅) 会对 λ 加以调整;
-
如此一来, 我们就关于user 和 item 分别得到了高频和低频的特征信息, 借此可以得到
OU=pooling(H(s)U,H(r)U),OI=pooling(H(s)I,H(r)I),
借此预测即可.
微调的方法
在讲作者设计 γ 的思路前, 先通过泰勒展开得
[P⊙γ(π)]PT≈Pdiag(K∑k=0αkπk)PT=K∑kαk¯AkU,
倘若 γ 的 k 阶导数一直不为 0, 则通过此方法可以相当于利用了非常高阶的信息 ¯AkU !
注: 严格来说, 一般的向量函数 γ 是不具备上面的泰勒展开的, 不过作者所设计的 γ 又满足此性质, 故也无法说它是错的.
所以作者希望设计这么一个 γ, 作者首先给出的结论就是
γ=eβπ,
注意, 这里的 eβπ=[eβπ1,…,eβπm]. 由此一来, 相当于 (按照 LightGCN 的方式推导)
H(k+1)=¯AUH(k)OU=limK→∞K∑k=0βkk!H(k).
当然, 本文不需要重复无限次 layers 聚合, 只需:
H(s)U=([P(s)⊙γ(U,π(s))]P(s)T)EU,H(r)U=([P(r)⊙γ(U,π(r))]P(r)T)EU,OU=pooling(H(s)U,H(r)U),
即可.
此外, 考虑到不同的用户 u 下降的速度应当不同, 作者认为越不活跃的用户越需要 smooth (即高阶的邻居信息, 故 αk 应当大), 故作者最后得设计结果为
γ(u,π)=e(β−log(du))π.
注: 对于 i 自然也是类似的设计.
其它细节
- 为了提高泛化性, 作者在训练的时候会随机 (按照概率 p∈[0,1]) 移除部分点, 相当于 dropout 了;
- 关于 BPR 损失作者提出了一个自适应的版本;
- 关于 over-smoothing 的分析可以看一看.
代码
[official]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2021-07-28 Color Models (RGB, CMY, HSI)