Graph Convolutional Matrix Completion
概
GCN 在推荐系统中的一次尝试.
符号说明
- \(N_u\), 用户数量;
- \(N_v\), 物品数量;
- \(N = N_u + N_v\);
- \(r \in \{0, 1, \ldots, R\} = \mathcal{R}\), 用户给物品的打分, 其中 \(0\) 表示未观测;
- \(M \in \mathcal{R}^{N_u \times N_v}\), 打分矩阵;
- \(u_i \in \mathcal{U}\), user;
- \(v_j \in \mathcal{V}\), item;
- \(\mathcal{N}_{u_i, r} := \{v_j : M_{ij} = r\}\)
- \(\mathcal{N}_{u_i} = \bigcup_{r=1}^R \mathcal{N}_{u_i, r}\);
- \(\mathcal{W}:= \mathcal{U} \bigcup \mathcal{V}\), 结点;
- \(\mathcal{E} = \{(u_i, r_{ij}, v_j): r_{ij} \not = 0\}\), 边;
- \(\mathcal{G} = (\mathcal{W}, \mathcal{E}, \mathcal{R})\), 所构成的无向图.
流程
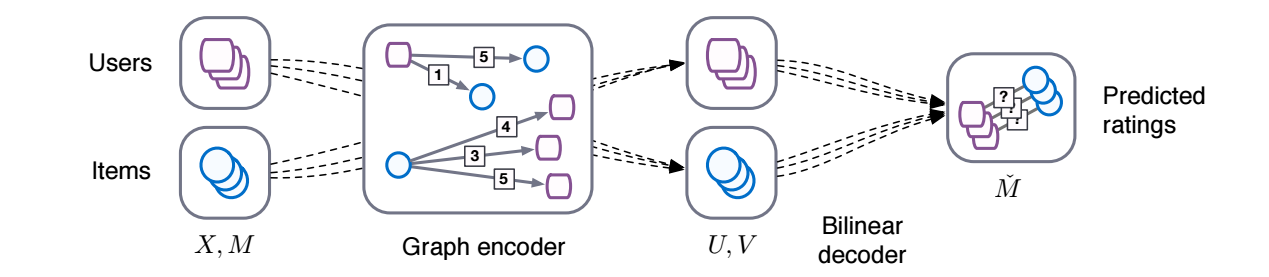
-
为每个 user, item 初始化状态 \(X \in \mathbb{R}^{N \times D}\) (embeddings), 并定义:
\[M_r \in \{0, 1\}^{N_u \times N_v}, \: r=1,2,\cdots, R \]为
\[[M_r]_{ij} = \left \{ \begin{array}{ll} 1 & \text{if } M_{ij} = r \\ 0 & \text{else}. \end{array} \right . \] -
Encoder \(f\) 将其映射为特征:
\[[U, V] = f(X, M_1, \ldots, M_R) \in \mathbb{R}^{N \times E}; \] -
Decoder \(g\) 进行预测:
\[\hat{M} = g(U, V); \] -
通过如下损失进行训练:
\[\mathcal{L} = - \sum_{i,j : M_{ij} \not = 0} \sum_{r=1}^R \mathbb{I}[M_{ij} = r] \log p(\hat{M}_{ij} = r). \]
Encoder
-
给定 \(X\), \(M_r\):
\[\mu_{j \rightarrow i,r} := \frac{1}{c_{ij}} W_r x_j, \]其中 \(c_{ij}\) 为 \(|\mathcal{N}_i|\) 或者 \(|\mathcal{N}_i||\mathcal{N}_j|\);
-
为不同的 \(u, v\) 计算各自的特征:
\[h_i = \sigma \Big[ \text{accum} (\sum_{j \in \mathcal{N}_{i, 1}} \mu_{j \rightarrow i, 1}, \ldots, \sum_{j \in \mathcal{N}_{i, 1}} \mu_{j \rightarrow i, R} ) \Big], \]其中 \(\text{accum}()\) 表示 \(\text{stack}()\) 或 \(\text{sum}()\);
-
最后得到:
\[u_i = \sigma(Wh_i). \]
Decoder
-
计算概率:
\[p(\hat{M}_{ij} = r) = \frac{e^{u_i^TQ_rv_j}}{\sum_{s=1}^R e^{u_i^T Q_s v_j}}; \] -
用期望作为预测:
\[\hat{M}_{ij} := g(u_i, v_j) = \mathbb{E}_{p(\hat{M}_{ij} = r)} [r] = \sum_{r=1}^R p(\hat{M}_{ij} = r). \]
注: 还有一些 weight sharing 和 引入其它属性信息的细节请回看原文.
代码
[official]
[PyTorch]

