Liang D., Krishnan R. G., Hoffman M. D. and Jebara T. Variational autoencoders for collaborative filtering. In International Conference on World Wide Web (WWW), 2018.
概
一种基于 VAE 的协同过滤方法.
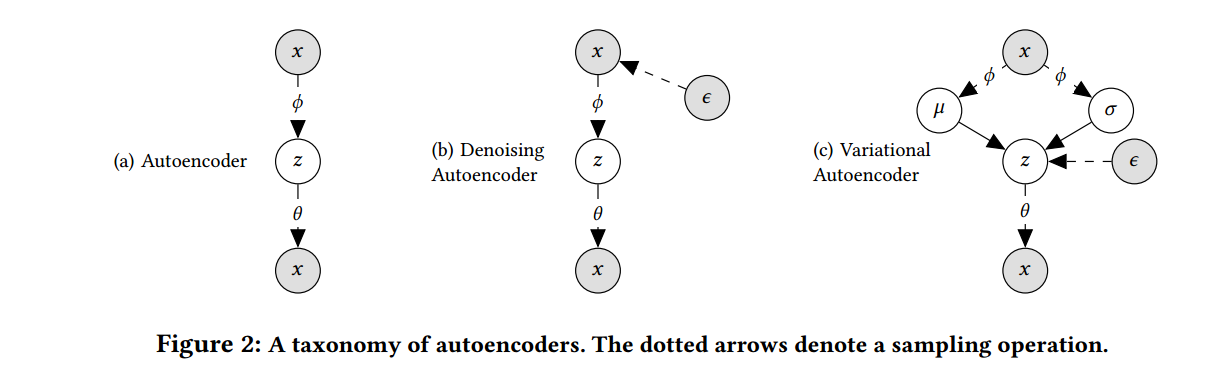
整体框架
-
xu∈RI, 用户 u 所对应的一个历史点击情况;
-
经过编码器 gϕ 得到:
[μϕ(xu),σϕ(xu)]∈R2K,
其中 K 代表隐变量的维度;
-
基于二者构建后验分布:
qϕ(zu|xu):=N(μϕ(xu),diag(σ2ϕ(xu))),
并通过重参数化进行采样
zu=μϕ(xu)+ϵ⊙σϕ(xu),ϵ∼N(0;IK);
-
通过解码器 fθ 得到概率向量
[π(zu)]i:=[exp(fθ(zu))]i∑j[exp(fθ(zu))]j,i=1,2,⋯,I;
假设 ^xu|zu 服从多项式分布:
p(^xu|zu):=Mult(Nu,π(zu)),
其中 Nu=∑i[^xu]i 表示推荐的次数.
-
最大化 ELBO 进行训练:
Lβ(xu;θ,ϕ)=Eqϕ(zu|xu)[logpθ(^xu=xu|zu)]−β⋅KL(qϕ(zu|xu)∥p(zu)),
其中 β=1 表示原始的 ELBO, 这里显式添加 β 用于后面方便调节, 作者采用了 β 从 0 逐渐升至 0.2 的方式调节. 此外 p(zu) 表示先验分布, 通常为普通的标准正态分布.
-
实际推断的时候, 只需计算 fθ(zu), 然后找到 top-k 作为推荐即可 (即概率越大越应该被推荐).
注:
logpθ(xu|zu)=∑i[xu]ilog[π(zu)]i.
细节
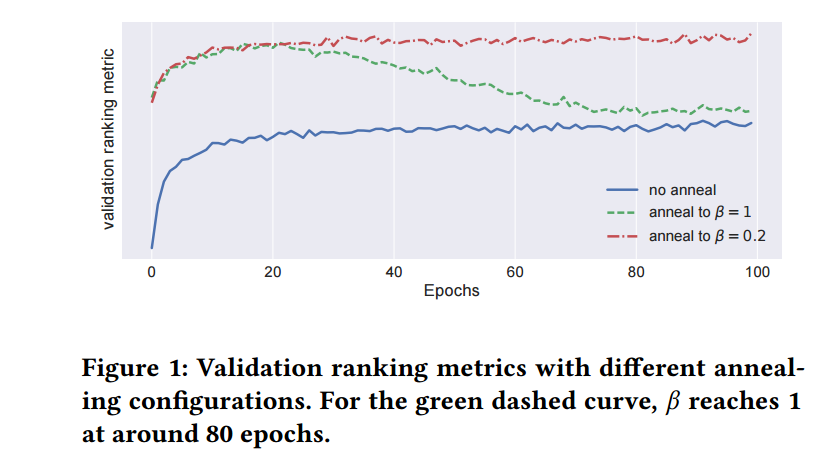
如图, 恒定 β=1 或者 β 从零逐步上升到 1 最后的结果都不是太好, 逐步升到 β=0.2 是结果最好的.
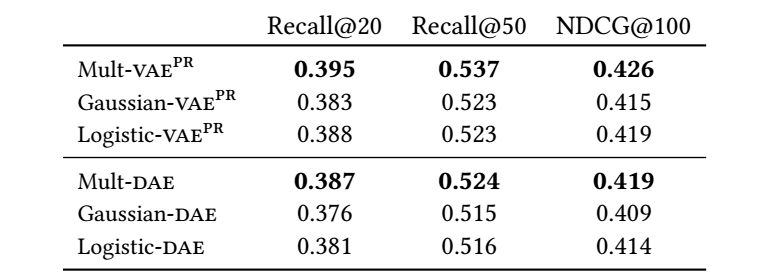
作者也试了不同的 p(^xu|zu) 的构建, 比较下来是多项式分布最优.
代码
[official]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix