Pearl Causal Hierarchy (PCH)
概
这部分内容主要介绍 PCH 中的三个阶段 \(\mathcal{L}_i, i=1,2,3\). 并介绍在什么情况下, 我们可以通过 \(\mathcal{L}_1\) 推测 \(\mathcal{L}_2\), 即利用观测数据进行因果推断.
符号说明
- \(X\), 随机变量;
- \(\text{Val}(X)\), 值域;
- \(x \in \text{Val}(X)\), 某个取值;
- \(\mathbf{X}\), 一组随机变量;
- \(P(Y_x) := P(Y|do(X = x))\);
- path (\(X, Y\)): \(X\) 到 \(Y\) 的路径 (不限方向, 比如 \(X \leftarrow U \rightarrow Y\) 也是 ok 的);
- collider: \(Z\) 为 \(X, Y\) 的 collider \(X \rightarrow Z \leftarrow Y\), 仅仅此模型而言:
Structural Causal Models and the Causal Hierarchy
Structural Causal Model (SCM)
SCM \(\mathcal{M}\) 由四元组 $\langle \mathbf{U}, \mathbf{V}, \mathcal{F}, P(\mathbf{U})\rangle $ 所定义, 其中
-
\(\mathbf{U}\) 为外部的 (exogenous) 背景 (backgroud) 元素, 通常是不感兴趣的或者难以观测的变量构成;
-
\(\mathbf{V} = \{V_1, V_2, \cdots, V_n\}\) 则是内部的 (endogenous) 由其它结点 (父节点) 所决定的变量;
-
关系 \(\mathcal{F} = \{f_1, f_2, \cdots, f_n\}\) 将 \(\mathbf{U}_i \bigcup \mathbf{Pa}_i\) 映射为结点 \(V_i\), 这里 \(\mathbf{U}_i\) 是与 \(V_i\) 关联的外部结点, 而 \(\mathbf{Pa}_i \subset \mathbf{V}\) 则是 \(V_i\) 的父节点, 即
- \(P(\mathbf{U})\) 是外部节点 \(\mathbf{U}\) 的分布.
注: 这里假设 SCM 是 recursive, acyclic 的, 即若 \(f_i \prec f_j\) (这里 \(\prec\) 代表'时序'), 则 \(f_i\) 的输入不包含 \(V_j\).
注: 给定 \(\mathbf{U}\), 则 \(\mathbf{V}\) 也就知道了, 故整个系统由 \(\mathbf{U}\) 和 \(\mathcal{F}\) 决定.
Causal Hierarchy
Pearl 将人认知的三个过程: seeing, doing, imagining 抽象为 association, intervention, and counterfactual 三个阶段 (分别记为 \(\mathcal{L}_1, \mathcal{L}_2, \mathcal{L}_3\))
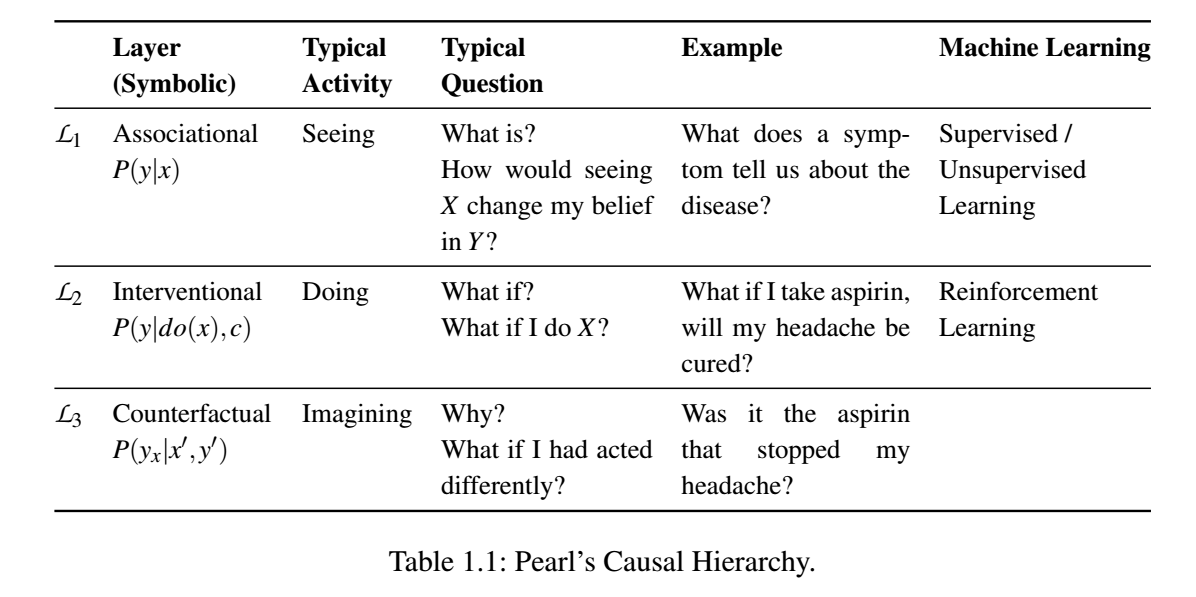
Layer1-Seeing
对于任意的 SCM \(\mathcal{M}\), 可以通过下式
估计出任意 \(\mathbf{Y} \subset \mathbf{V}\) 的联合分布. 其中 \(\mathbf{Y(u)}\) 给定 \(\mathbf{U} = \mathbf{u}\) 后 \(\mathbf{Y}\) 的值.
实际上, 现在大抵的机器学习就是为了估计数据的一个联合分布. 比如:
- 图像生成: \(\mathbf{V} = \mathbf{Z} \bigcup \mathbf{X}\), 其中 \(\mathbf{X}\) 为图像, \(\mathbf{Z}\) 为一些属性, 然后只要估计出
就可以采样图片了;
- 分类任务: \(\mathbf{V} = \mathbf{X} \bigcup \mathbf{Y}\), 其中 \(\mathbf{X}\) 为图片, \(\mathbf{Y}\) 为标签, 则一般的分类模型实际上就是建模
总的来说, 这些任务依旧停留在数据分布估计之上.
Layer2-Doing
我们常常做出假设并验证. 若我们希望考察如果设定 \(\mathbf{X} = \mathbf{x}\) 下其它结点的情况, 此时相当于构建了一个新的 SCM:
其中
此时, 我们可以通过下式估计
其中 \(\mathbf{Y_x(u)}\) 表示在 \(\mathcal{F}_{\mathbf{x}}\) 和 \(\mathbf{U = u}\) 下的结果.
Layer3–Imagining
吾日三省吾身. 人是非常擅长从反省中进步的, 比如考完试后, 总会想如果某个题再看仔细点会如何如何. 在这过程中, 我们将真实的世界所发生的事情和虚构的世界发生的事情联系了起来, 而且虚构的世界往往给予现实之上的. 这实际上是面对:
的估计问题. 即在观测到现实中 \(X=x, Y=y\) 的事实后, 思考在 \(do(X=x')\) 的条件下的结果.
一般来说 (看下面的例子), 我们只需要构建出 \(Y_x, Y_{x'} \cdots\) 的联合分布, 上式也是水到渠成的事情. 而对于 任意的 \(\mathbf{Y}, \mathbf{Z}, \cdots, \mathbf{X}, \mathbf{W} \subset \mathbf{V}\), \(\mathbf{Y_x, \cdots, Z_w}\) 的联合分布为
注: \(\mathbf{Y}_x, \cdots, \mathbf{Z_w}\) 实际上是不同虚构世界中的元素, 故 (L3) 构建了这样的一个联系;
注: (L3) 其实很好理解, 把 \(\mathbf{U}\) 看成最底下的水源, 上面是借此生长的花花草草, 无论多复杂, 只要寻到了底下的 atom, 一切就迎刃而解了.
注: 在实际中, 我们需要通过 \(\mathcal{M}_x, \mathcal{M}_w\) 分别求解 \(\{\mathbf{u|Y_x(u) = y_x}\} \cdots\), 然后取交集.
例子
假设存在如下的一个模型:
一个病人患了某种病, 有可能表现出一些症状, 如头疼 (\(Z = 1\)), 也有可能没有症状 (\(Z = 0\)), 根据症状和其它因素, 医生会选择是否开药 (\(X \in \{1, 0\}\)). 病人最后是否能够康复受其是否自身的抵抗力 $U_r \in {0, 1} $, 是否开药 \(X\) 以及未知因素 \(U_y\) 影响. 具体来说, \(X, Y, Z\) 的值可通过下式推导出:
仅从上式我们可以得出结论: 对那些有免疫力的人 (\(U_r = 1\)) 开药 (\(X = 1\)) 是有利的 (\(Y=1\)), 对没有免疫力的人开药反而是有害的.
接下来, 我们考察在
的条件下, 三种层次所得出来的结论.
- Seeing: 根据 (L1) 可以算出来:
所以从条件概率的角度来讲, 该药物对于治疗该疾病是有利的;
- Doing: 保持 \(f_z, f_y\) 不变, 令 \(f_x: X \leftarrow 1\) 可得:
类似地, 令 \(f_x: X \leftarrow 0\) 可得:
所以其得出的结论是该药物对于治疗该疾病是无效的.
- 接下来, 通过 imagining 可以进一步回答这个问题. 通过 (L3) 可得
再通过 (L1) 可得:
通过贝叶斯公式可得:
即无法自愈的个体即使给药了也通常无法康复. 类似地,
能够自愈的个体, 给药后反而无法康复. 故通过 Layer3 我们最终得到了我们所希望的结论.
Expressivity of Pearl Causal Hierarchy (PCH)
通过上面的分析我们可知, 只要知道 SCM \(\mathcal{M}\), 那么各层 \(\mathcal{L}_i, i=1,2,3\) 的信息也就容易求得了. 而且显然, 这三者所包含的信息量是
的 (因为低层的均可以看成是高层的一个特例).
但是这个顺序是直观上的, 并不严谨. 思考一个有趣的例子, 我们知道, 整数, 有理数, 实数也是类似的一种从低到高的关系(从包含数的角度上讲), 但是它们的基数却是 整数=有理数<实数. 虽然整数真包含在有理数中, 但是我们可以找到一个一一映射, 换言之, 二者的表达能力是一致的.
那么现在的问题是, 虽然 \(\mathcal{L}_1, \mathcal{L}_2, \mathcal{L}_3\) 有上面的关系, 会不会和整数, 有理数一样实际上所包含的信息量是一致的呢? 倘若是的话, 那么我们就没有研究高层的必要了. 再通俗点讲, 倘若通过 \(\mathcal{L}_1\) 能够推出 \(\mathcal{L}_2\) 甚至 \(\mathcal{L}_3\), 那么意味着普通的数据就能帮助我们进行因果推断了. 答案自然是否定的.
等价类定义
\(\sim_i\): 假设 \(\Omega\) 为一包含感兴趣的 SCM 的集合, 对于任意的 \(\mathcal{M}, \mathcal{M}' \in \Omega\), 我们称二者是 \(\mathcal{L}_i\) 等价的, 即 \(\mathcal{M} \sim_i \mathcal{M}'\), 若二者在 \(\mathcal{L}_i\) 上是一致的.
注: 文中用的是逻辑语言来度量一致性, 从我的角度来看, 比如 \(\mathcal{L}_1\) 上一致, 就是联合分布 \(P(\mathbf{V})\) 是相同的, 而 \(\mathcal{L}_2\) 上一致, 就是 \(P(\mathbf{Y_x}) \: \forall \mathbf{Y \subset V}, \mathbf{X=x}\) 是相同的.
Collapse
Collapse relative to \(\mathcal{M}^*\):, 对于 SCM \(\mathcal{M}^* \in \Omega\), 称其 \(\mathcal{L}_j\) 塌缩为 \(\mathcal{L}_i, i < j\), 若
一旦 \(\mathcal{L}_j\) 塌缩为 \(\mathcal{L}_i\), 比如 \(\mathcal{L}_2\) 塌缩为 \(\mathcal{L}_1\), 这就意味着, 所有能够导出 \(\mathcal{L}_1\) 的 SCM \(\mathcal{M}\) 均导出相同的 \(\mathcal{L}_2\). 此时想要通过 \(\mathcal{L}_1\) 获得 \(\mathcal{L}_2\), 我们可以:
- 构建任意满足 \(\mathcal{L}_1\) 的 \(\mathcal{M}\);
- 通过 \(\mathcal{M}\) 得到 \(\mathcal{L}_2\).
这就相当于, \(\mathcal{L}_1\) 包含了构建 \(\mathcal{L}_2\) 所需的全部信息, 此时我们只需要研究 \(\mathcal{L}_1\), 即简单的观测数据即可了.
Causal Hierarchy Theorem (CHT)
Causal Hierarchy Theorem (CHT): 对于 SCMs \(\Omega\), 其中会发生塌缩的子集的 Lebesgue 测度为 0.
注: Lebesgue 测度的定义, 首先需要对 SCMs 进行一个编码, 使其称为落在一个 \([0, 1]^K\) 中的一个凸集 (等有时间看了该作者另外一篇文章的证明就知道了).
CHT 说明了, 会发生塌缩的 SCM 几乎是不存在的. 这也就说明了研究 \(\mathcal{L}_2\) 以及 \(\mathcal{L}_3\) 的必要性.
Corollary 1: 想要回答 \(\mathcal{L}_i\) 所构建的问题, 需要知道 \(\mathcal{L}_i\) 或者更高层次的 \(\mathcal{L}_j, j > i\) 的信息.
例子
我们仍以上一节的例子为例 (记为 \(\mathcal{M}^*\)). 我们令 (记为 \(\mathcal{M}\))
其余的映射保持不变. 此时, \(X, Y\) 之间并不存在直接的因果关系, 即
即 \(\mathcal{L}_2\) 层面, 两个 SCMs 是不等价的. 但是可以计算得到, \(\mathcal{L}_1\) 层面二者是等价的. 这就说明了, 在这个这个例子中, 仅通过观测数据是无法进行 \(do\) 操作的.
还可以构造出 \(\mathcal{L}_1, \mathcal{L}_2\) 等价的 \(\mathcal{M}'\) 但是 \(\mathcal{L}_3\) 不等价 (详情见文中 Example 9).
基于数据的因果推断
诚然, 倘如我们能够知道 SCM \(\mathcal{M}\) 本身, 那么无论是 \(\mathcal{L}_i, i=1,2,3\) 的问题就都迎刃而解了. 但是在实际中, 我们通常只有可怜的观测数据可以用, 即
是可知(估计)的. 而我们又从上一节的 CHT 知道, 仅通过 \(\mathcal{L}_1\) 的信息想要推断出 \(\mathcal{L}_2, \mathcal{L}_3\) 几乎是不可能的. 于是现在的问题是, 通过添加怎么样的额外信息, 能够帮助我们进行 \(\mathcal{L}_2\) 甚至是 \(\mathcal{L}_3\) 层面的推断呢?
[不可行] Layer1 的约束
我们先来看看一种常用的但是实际上不可行的 \(\mathcal{L}_1\)-约束: 条件独立 (conditoinal independence). 直接以例子进行佐证.
考虑 \(\mathbf{V} = \{X, Z, Y\}, \mathbf{U} = \{U_x, U_y, U_z\}\), 而 \(\mathcal{M}^1, \mathcal{M}^2\) 分别由
其中 \(\oplus\) 代表 \(xor\) 且
容易证明, \(\mathcal{M}^1\), \(\mathcal{M}^2\) 导出相同的 \(\mathcal{L}_1\), 即
同时, 都满足条件独立性:
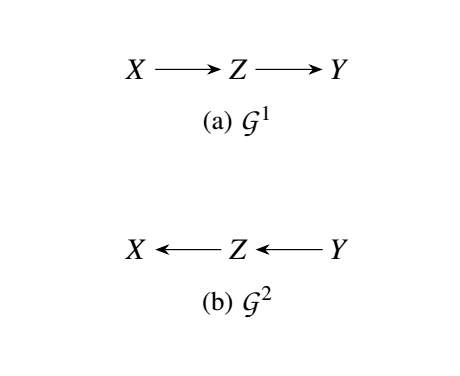
但是, 它们的 \(\mathcal{L}_2\) 层面的性质, 比如
就不一致了.
这说明, 即使加了合理的条件约束, 依然无法保证 \(\mathcal{L}_2\) 是正确的.
Layer2 约束 - Markovian Causal Bayesian Networks
Causal Diagram (Markovian Models): 考虑一个 Markovian SCM \(\mathcal{M} = \langle \mathbf{U}, \mathbf{V}, \mathbf{F}, P(U) \rangle\). 则其 casual diagram \(\mathcal{G}\) 通过如下方式定义:
- 所有的内部结点 \(\mathbf{V}\) 为顶点;
- 添加有向边 \(V_j \rightarrow V_i\), 一旦 \(V_j\) 为 \(f_i\) 的是一个直接的参数, 即
CBN - Markovian
Causal Bayesian Network (CBN - Markovian): 令 \(\mathbf{P}_*\) 为所有 interventional distributions \(P(\mathbf{V}|do(\mathbf{x})), \mathbf{X} \subset \mathbf{V}, \mathbf{x} \in \text{Val} (\mathbf{X})\). 则有向无环图 \(\mathcal{G}\) 称为 \(\mathbf{P}_*\) 的 Causal Bayesian Network, 如果对于所有的 \(\mathbf{X \subset V}\) 有下列性质成立:
- [Markovian] \(P(\mathbf{V}|do(\mathbf{x}))\) 满足马尔可夫性质, 即
即给定其父节点 \(\mathbf{pa}_i\), \(V_i\) 与其非后代结点独立.
- [Missing-link] 对于任意的 \(V_i \in \mathbf{V}, V_i \not \in \mathbf{X}\), 则
在固定(doing)父节点之后, \(do(X)\) 就不起作用了.
- [Parent do/see] 对于任意的 \(V_i \in \mathbf{V}, V_i \not \in \mathbf{X}\):
注: 条件 2, 3 等价于 [Modularity]:
proof:
[Missing-link] + [Parent do/see] \(\Rightarrow\) [Modularity]:
[Parent do/see] \(\Leftarrow\) [Modularity]:
[Missing-link] \(\Leftarrow\) [Modularity]:
[Markovian] CBN + Layer1 -> Layer2
倘若我们所关注的 SCM \(\mathcal{M}\) 是满足 Markovian 的, 即
则其所导出的 casual diagram \(\mathcal{G}\) 是一个 CBN, 此时我们可以根据 \(\mathcal{L}_1\) 的性质来推导 \(\mathcal{L}_2\):
于是, 我们只需求出
这一 \(\mathcal{L}_1\) 层的信息即可进行 \(\mathcal{L}_2\) 层的推断了.
Corollary 2 (Back-door Criterion (Markovian)): 在 Markovian 模型中, 对于操作 \(\mathbf{X}\) 以及导致的输出 \(\mathbf{Y}\), 若 \(\mathbf{Z}\) 阻隔了 \(\mathbf{X} \rightarrow \mathbf{Y}\) 的路径, 则
注: 切记, 要求 \(\mathcal{M}\) 是满足 Markovian 的.
个人更加推荐的 causal diagram 表示方法: SWIG
相较于 Pearl 所提出的这种因果图, 我更喜欢 Robins and Richardson (2013) (也可以参考: Causal Inference: What If, p93) 的 Single-world intervention graphs (SWIGs).
如下图所示, 基于 SCM, \(do(X = x)\) 的 SWIG \(\mathcal{G}_{x}\) 可以按照如下方式定义:
- 将所有的 \(\mathbf{U}, \mathbf{V}\) 作为顶点;
- 添加 \(Z_j \rightarrow Z_i\), 一旦 \(f_i\) 中的参数包含 \(Z_j\);
- 将 \(X\) 替换为 \(X|x\), 其中 \(X|x\) 显式表示 \(X, x\) 无关;
- 将原先由 \(X\) 出发的边 \(\rightarrow\) 删除, 并添加相应的由 \(x \rightarrow\) 出发的边;
- \(X\) 的后代 (存在 directed path) 用加上下标 \(x\) 以表示 \(\cdot|do(X=x)\).
可以发现, 因为我们把未观测的变量 \(\mathbf{U}\) 也放入了其中, 所以 \(\mathcal{G}_x\) 实际上是满足 Markov 性质的, 是一个 markovian casual diagram. 此外:
- 如果 \(X \prec Y\),
即操作后代对于前者没有影响.
- [Consistency]
Layer2 约束 - Semi-Markovian Causal Bayes Networks
上一节的约束只适用于满足 Markovian 性质的 SCM, 那么怎么样的 \(\mathcal{M}\) 才会满足这样的性质呢: 那些不存在未观测变量 \(\mathbf{U}\) 或者不存在同一个 \(U\) 同时影响 \(X, Y \in \mathbf{V}\) 才会满足这个性质. 但是实际上, 这个是很难实现的, 一件事情的发展总会受到各种各样的无法观测因素的干扰.
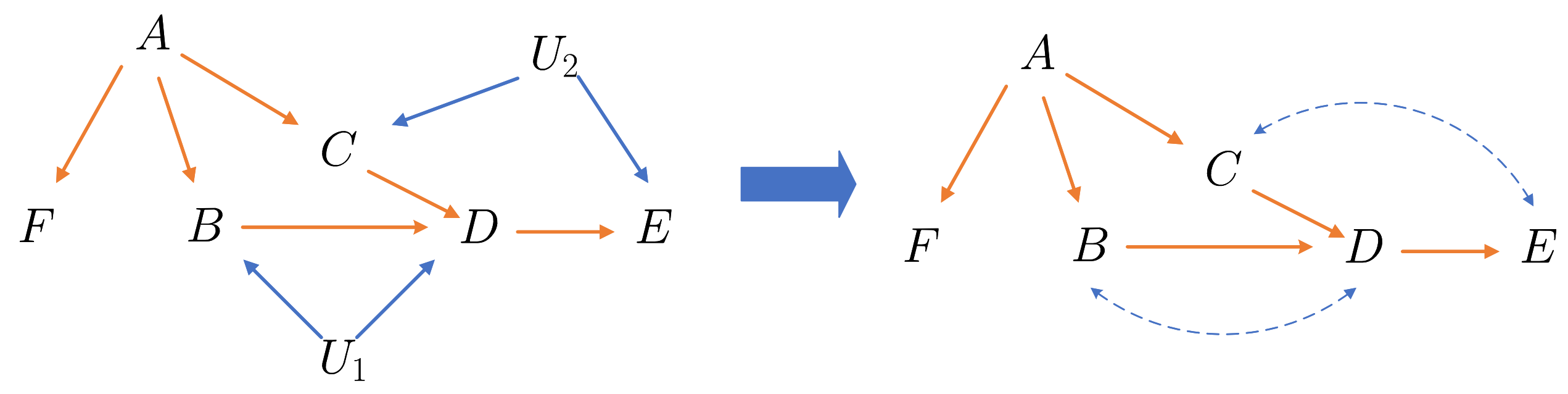
如上图所示, 如果按照 Markovian causal diagram 的定义方式,
另外一些 CBN 所需要满足的条件也都是不符合的.
注: 如果能够把所有的 \(\mathbf{U}\) 考虑进去, 整体还是满足 Markovian 性质的, 即
但是 \(\mathbf{U}\) 实际中是未观测的.
Causal Diagram (Semi-Markovian Models): 给定一个普通的 SCM \(\mathcal{M} = \langle \mathbf{U}, \mathbf{V}, \mathcal{F}, P(\mathbf{U}) \rangle\). 则其 causal diagram \(\mathcal{G}\) 按照如下方式定义:
- 将所有的内部结点 \(\mathbf{V}\) 作为 \(\mathcal{G}\) 的顶点;
- 添加有向边 \(V_j \rightarrow V_i\), 一旦 \(V_j\) 为 \(f_i\) 的是一个直接的参数, 即
- 添加双向虚边 \(V_j \dashleftarrow \dashrightarrow V_i\), 一旦 \(f_i, f_j\) 共享参数 \(U \in \mathbf{U}\), 即
如上图所示, 右端就是左端的一个 causal diagram 表示.
既然这种类型的 causal diagram, 即使给定 \(V_i\) 的父节点 \(\mathbf{Pa}_i\), 也没有
成立, 其中 \(\mathbf{NDesc}_i\) 表示 \(V_i\) 的非后代 (non-descendants) 结点. 而这一性质 Markovian 性质对于利用 \(\mathcal{L}_1\) 推导 \(\mathcal{L}_2\) 的信息是至关重要的. 现在的问题是, 我们希望引入'更严格'的条件独立.
Confounded Component: 令 \(\{\mathbf{C}_1, \mathbf{C}_2, \ldots, \mathbf{C}_k\}\) 为 \(\mathbf{V}\) 的一个分割 (\(\bigcap \mathbf{C}_i = \empty, \bigcap \mathbf{C}_i = \mathbf{V}\)). \(\mathbf{C}_i\) 称为 \(\mathcal{G}\) 的一个 confounded component, 当对于任意的 \(V_i, V_j \in \mathbf{C}_i\) 之间存在一路径完全由双向虚边 (即 \(\dashleftarrow \dashrightarrow\)) 构成, 且 不存在 confounded component \(\mathbf{C}' \subset \mathbf{V}, \mathbf{C}' \not= \mathbf{C}_i\) 且 \(\mathbf{C}_i \subset \mathbf{C}\), 即 \(\mathbf{C}_i\) 是最大的了 (maximal).
比如, 上图中:
接下来我们观察上例:
注意到, 此时路径 \(A \rightarrow C \leftarrow U \rightarrow E\) 由于 \(|C\) 而被打通;
所以, 想要 \(E\) 和其非后代结点独立, 需要给定其 父节点 + confounded component + confounded component 的父节点, 即 \(\mathbf{Pa}_E^+\). 其中 \(\mathbf{Pa}_i^+\) 定义为
这里 \(\prec\) 表示时序, \(\{V: V \preceq V_i\}\) 即表示非后代结点包括 \(V_i\).
\(\mathbf{Pa}_i^+\) 的制作过程实际上就是首先收集非后代节点中和 \(V_i\) 属于统一 confounded component 的其它点, 然后再合并它们 + 它们的父节点 + \(V_i\) 的父节点.
于是我们有如下的类似 Markovian 的定义:
Semi-Markov: 分布 \(P\) 称其关于 \(\mathcal{G}\) (semi-markovian casual diagram) 为 semi-markov 的, 若
假设经过 \(do(\mathbf{X} = \mathbf{x})\) 后的 causal diagram 为 \(\mathcal{G}_{\overline{\mathbf{X}}}\), 则其满足 semi-markov 若
其中 \(\mathbf{Pa}_i^{\mathbf{x}+}\) 表示根据 \(\mathcal{G}_{\overline{\mathbf{X}}}\) 构建的 \(\mathbf{Pa}_i^+\).
注: \(\mathcal{G}_{\overline{\mathbf{X}}}\) 是将 \(\mathcal{G}\) 中指向 \(\mathbf{X}\) 的边移除后的图.
为什么 \(do(\mathbf{X})\) 只需要移除指向 \(\mathbf{X}\) 即可?
因为此时 \(\mathbf{X} = \mathbf{x}\) 的概率为 \(1\), 以其余的变量无关.
为什么要这么构造 \(\mathbf{pa}^+\) ? 需要注意的是, \(\mathbf{Pa}^+\) 实际是一个充分的条件. 注意到:
- \(V_i\) 自身的父节点是必须的;
- \(\mathbf{C}(V_i)\) 也是必须的;
- \(V \in \mathbf{C}(V_i)\) 的父节点不一定是必须的, 因为可能不存在结点 \(V_j\) 指向 \(V_i\), 此时 \(|V\) 就不会造成额外的通路了.
例子
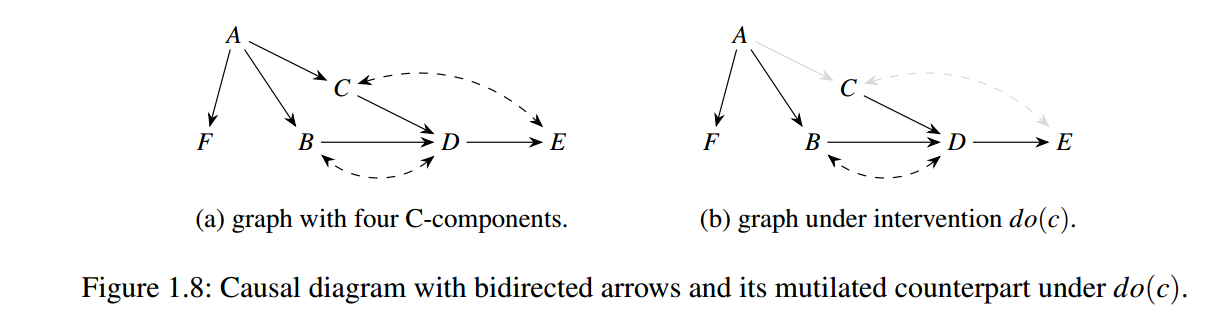
对于上图, 有
根据 semi-markov 性质:
故有
右图为 \(do(C=c)\) 后 \(\mathcal{G}_{\overline{C}}\) 的表示, 就是将指向 \(C\) 的边去掉. 此时有
注: \(\mathcal{G}_{\overline{\mathbf{X}}}\) 中的确有:
但是这不意味着:
CBN - Semi-Markovian
与 CBN Markovian 类似, 我们给出 CBN - Semi-Markovian 的定义, 并说明这种模型约束下, 我们可以连接一般的 \(\mathcal{L}_1\) 和 \(\mathcal{L}_2\).
Causal Bayesian Network (CBN - Semi-Markovian): 令 \(\mathbf{P}_*\) 为所有 interventional distributions \(P(\mathbf{V}|do(\mathbf{x})), \mathbf{X} \subset \mathbf{V}, \mathbf{x} \in \text{Val} (\mathbf{X})\). 则有向图 \(\mathcal{G}\) 称为 \(\mathbf{P}_*\) 的 Causal Bayesian Network, 如果对于所有的 \(\mathbf{X \subset V}\) 有下列性质成立:
- [Semi-Markovian] \(P(\mathbf{V}|do(\mathbf{x}))\) 关于 \(\mathcal{G}_{\overline{X}}\) 是 semi-Markov 的;
- [Missing directed-link] 对于任意的 \(V_i \in \mathbf{V} \setminus \mathbf{X}, W \subseteq \mathbf{V} \setminus (\mathbf{Pa}_i^{\mathbf{x}+} \cup \mathbf{X} \cup \{V_i\}\):
即给定 \(\mathbf{pa}_i^{\mathbf{x}^+}\), 再设定非后代结点 \(\mathbf{W}\) 是无意义的;
- [Missing bidirected-link] 对于任意的 \(V_i \in \mathbf{V} \setminus \mathbf{X}\), 假设 \(\mathbf{Pa}_i^{\mathbf{x}+}\) 可以分割成 confounded (\(\mathbf{Pa}_i^{c} \in \mathbf{C}(V_i)\)) 和 unconfounded ($ \mathbf{Pa}_i^u \not \in \mathbf{C}(V_i)$) 父节点, 则
注: 个人感觉 \(\mathbf{X}, \mathbf{W}\) 没必要区分的如此细致, 这里只是为了避免一些不必要的说明.
以上面的例子来说:
[Missing directed-link]:
第二个不是应该直接用 \(f\) 来思考?
[Missing bidirected-link]:
可以证明的是, 一般的 SCM \(\mathcal{M}\) 所导出的 causal diagram \(\mathcal{G}\) 都是 semi-Markovian CBN.
[Semi-Markovian] CBN + Layer1 -> Layer2
现在, 给定 Semi-Markovian CBN 结合 \(\mathcal{L}_1\) 的信息, 在有些时候就可以顺利推导出 \(\mathcal{L}_2\) 的信息了, 其所需要用到的工具就是下面的 do-calculus:
Do-Calculus: 令 \(\mathcal{G}\) 为 \(\mathbf{P}_*\) 的一个 CBN, 则 \(\mathbf{P}_*\) 满足如下的规则. 即对于不交的 \(\mathbf{X, Y, Z, W} \subseteq \mathbf{V}\), 有
- Rule1:
- Rule2:
- Rule3:
其中 \(\overline{X}\) 是指移除指向 \(X\) 的边, \(\underline{Z}\) 是指移除由 \(Z\) 发出的边, \(\mathbf{Z(W)}\) 表示 \(\mathbf{Z}\) 中不为 \(\mathbf{W}\) 祖先 (non-ancestors) 的点的集合.
一个尝试性证明 (其实回看 Pearl 的论文比较好).
proof:
Rule1:
因果图 SWIG \(\mathcal{G}_{\mathbf{X}}\), 可以发现:
如果
但是
则, 在 \(\mathcal{G}_{\mathbf{X}} |\mathbf{W}\) 中存在 \(\mathbf{Z}, \mathbf{X}, \mathbf{Y}\) 的一个 (经过 \(\mathbf{X}\))的 unblocked path, 但是注意到 \(\mathcal{G}_{\mathbf{X}}\) 中 \(\mathbf{X}\) 所以向外的作用都被 \(\mathbf{x}\) 替代了, 故存在 unblocked path 的变量 \(Z \in \mathbf{Z}\) 必须为某个 \(X \in \mathbf{X}\) 的祖先, 即 \(Z \prec X\). 但是任何 \(X\) 到 \(Y\) 的通路都必须经过其祖先 \(X \leftarrow U\) 实现, 此时 \(Z \rightarrow X \leftarrow U\) 构成了 collider, 在不给定 \(|X\) 的条件下是不可能构成 unblocked path 的.
Rule2:
Rule2 实际上就是证明给定
的条件下成立
只需注意到
和
除 \(\mathbf{x}, \mathbf{z}\) 外的等价性, 再结合 Rule1 便得证了.
Rule3:
记 \(\mathbf{Z}^a, \mathbf{Z}^d\) 分别为 \(W\) 的祖先和后代, 让我们首先观察
代表了什么:
表示 \(\mathcal{G}\) 中 \(\mathbf{Z}^d\) 要么不存在到 \(\mathbf{Y}\) 的通路, 或者通路经过 \(\mathbf{X}\);
\(\mathbf{Z}^a\) 到 \(Y\) 要么没有通路, 要么经过 \(\mathbf{W}\) 或 \(\mathbf{X}\), 换言之,
故在 \(\mathcal{G}_{\mathbf{xz}}\) 中,
既然 \(\mathbf{z}^d\) 必须通过 \(\mathbf{X}\) 才能影响 \(\mathbf{Y}\), 而 \(do(\mathbf{X=x})\) 彻底阻断了这一点, 此时有
- 则
例子
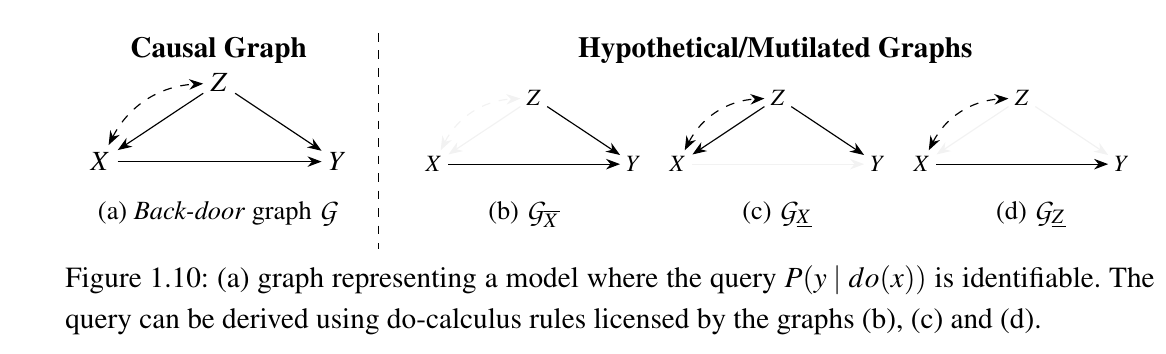
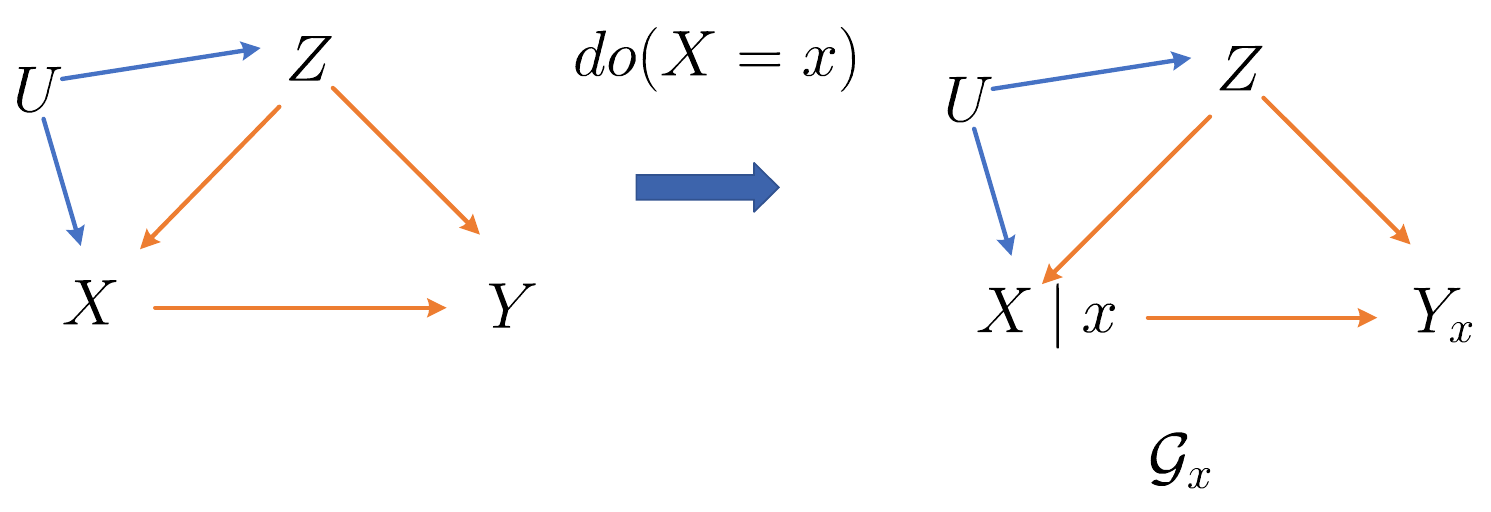
如上图所示, 我们分别用上面介绍的 rules 和 SWIG 来推导 \(P(y|do(x))\):
rules:
SWIG:
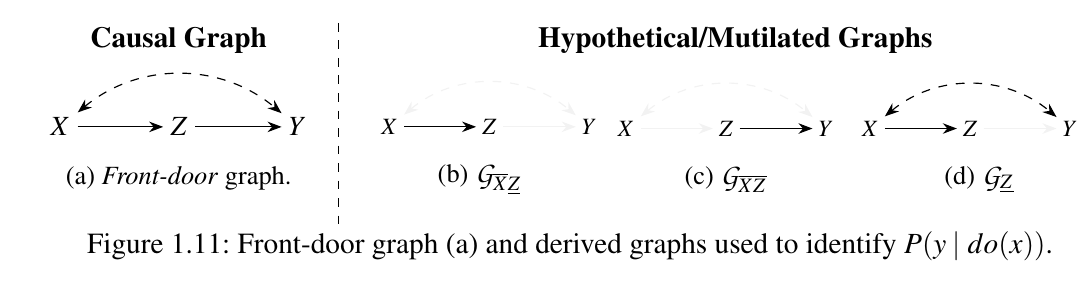
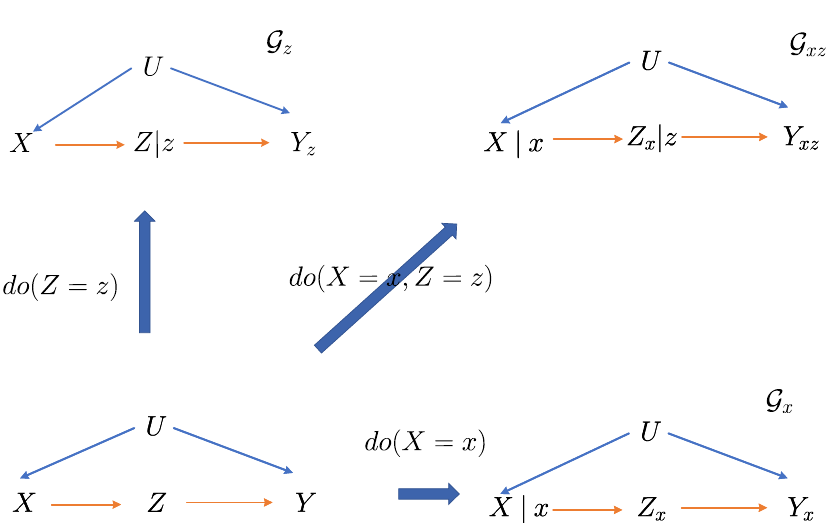
我们再来看这个例子:
Rules:
SWIG:
注: 想要用 rules 得到相同的结果, 需要额外的 backdoor 推论 (详情回见文章).
最后,
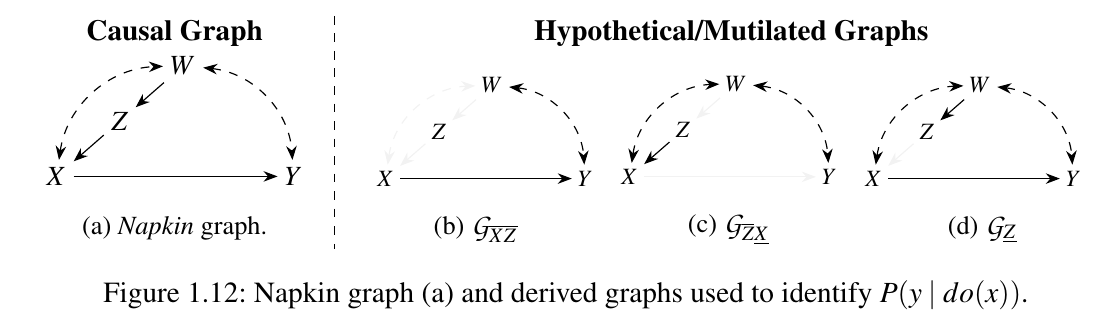
推导就省略了.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号