Deep & Cross Network for Ad Click Predictions
概
Wide & Deep 模型虽然强大, 但是其 wide 部分仍需要复杂的交叉特征的特征工程, 本文主要提了一个 Cross 模块去自动提取.
主要内容
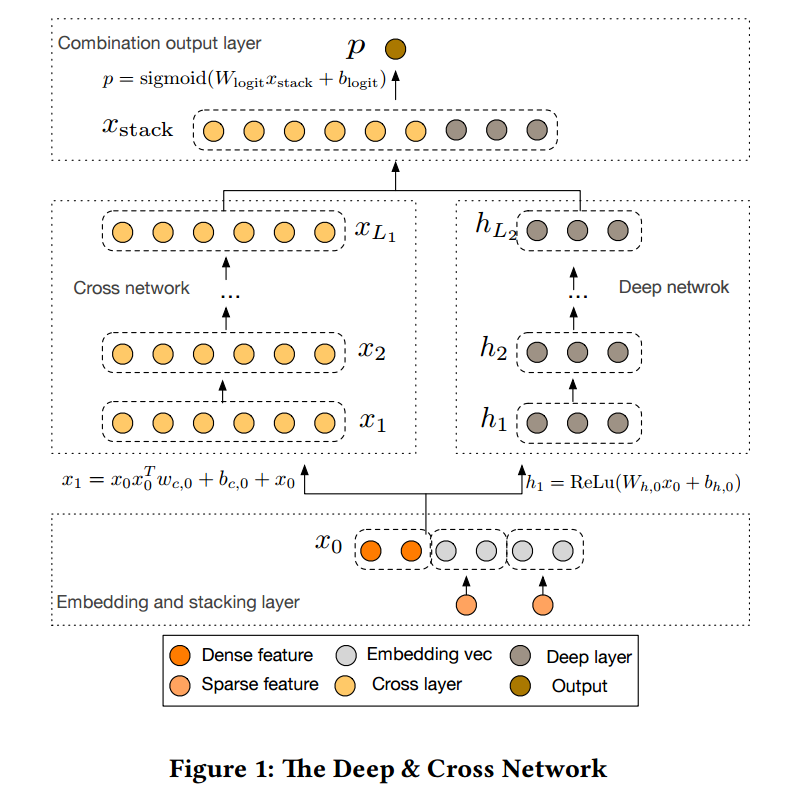
Embedding and Stacking Layer
如图所示, DCN 首先需要将稀疏特征通过 embedding layer 转换为稠密向量
\[\bm{x}_{\text{embed}, i} = W_{\text{embed}, i} \bm{x}_i,
\]
然后通过拼接得到
\[\bm{x}_0 = [\bm{x}_{\text{embed}, 1}^T, \cdots, \bm{x}_{\text{embed}, k}^T, \bm{x}_{\text{dense}}^T]^T
\]
Cross Network
特征交叉对于推荐系统是非常重要的, 比如 FM 就是主要利用了2阶的交叉
\[x_i x_j.
\]
Cross Network 的作用就是自动的提取高阶交叉特征, 其每一层的形式如下
\[\bm{x}_{l + 1} = f(\bm{x}_l, \bm{w}_l, \bm{b}_l) + \bm{x}_l = \underbrace{\bm{x}_0 \bm{x}_l^T \bm{w}_l + \bm{b}_l}_{cross} + \underbrace{\bm{x}_l}_{residual},
\]
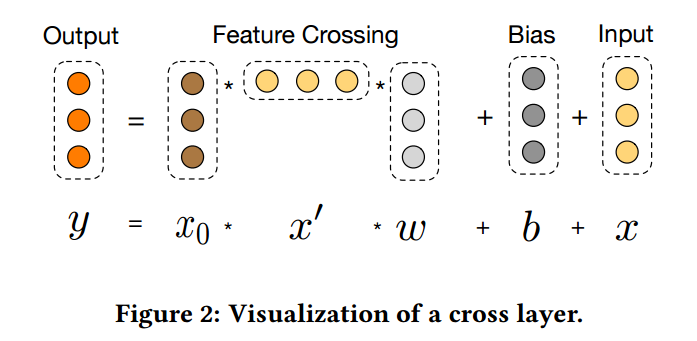
假设共有 \(L\) 层 (从 0 开始计数), 则最后\(\bm{x}_{L}\)囊括了所有
\[x_1^{\alpha_1}x_2^{\alpha_2}\cdots x_d^{\alpha_d}, \: 0 \le |\bm{\alpha}| \le L + 1,
\]
其中 \(|\bm{\alpha}| = \sum_{i=1}^d \alpha_i\). 这个可以由归纳法得到, 不妨设对于 \(l\) 均成立, 则 (省略偏置和residual连接)
\[\bm{x}_{l + 1} = \bm{x}_0 \bm{x}_l^T \bm{w}_l = \bm{x}_0 [\bm{x}_l^T \bm{w}_l] = \sum_i x_i [\bm{x}_l^T \bm{w}_l],
\]
既然 \(\bm{x}_l^T \bm{w}_l\) \(l + 1\) 阶, \(\bm{x}_{l+1}\) 自然 \(l + 2\)阶.
此外, 和一般的交叉模型不同的是, 由于每个交叉特征的权重不是独立的, 使得模型既减少了计算开销, 又避免了随之而来的严重的过拟合.
Deep Network
很普通的MLP:
\[\bm{h}_{l+1} = f(W_l \bm{h}_l + \bm{b}_l).
\]
Combination Layer
最后, 通过 combination layer 进行预测
\[p = \sigma([\bm{x}_{L_1}^T, \bm{h}_{L_2}^T]\bm{w}_{\text{logits}}).
\]
损失为
\[loss = -\frac{1}{N} \sum_{i=1}^N y_i \log p_i + (1 - y_i) \log (1 - p_i) + \lambda \sum_l \|\bm{w}_l\|_2^2.
\]
代码
注: 看了 PyTorch 的代码, 发现 Cross 部分居然真的没用上激活函数.

