Distributionally Robust Neural Networks for Group Shifts: On the Importance of Regularization for Worst-Case Generalization
概
作者希望通过 DRO (distributionally robust optimization)
来解决分布不均衡的问题: 即训练后模型通常对于训练中占据大部分的类别比较友好, 而在 atypical 的类别中表现很差.
主要内容
数据集

上面三个数据集的设计思路是一样的, 这里介绍一下 Waterbirds.
Waterbirds 是基于 CUB 得到的, 其中的鸟类图片均带有像素级的mask, 基于此可以将鸟和背景分离开来. 作者考虑两种类别的鸟:
- Waterbirds (水鸟): albatross, auklet, cormorant, frigatebird, fulmar, gull, jaeger, kittiwake, pelican, puffin, or tern, gadwall, grebe, mallard, merganser, guillemot, or Pacific loon;
- 其余的为 landbird (陆鸟).
数据集的group是这般构造的, 95%的水(陆)鸟的背景为水(陆地), 5%的水(陆)鸟的背景为陆地(水), 显然后者在自然界在也是较为稀少的存在. 可以通过此数据集研究所得模型的偏好. 需要注意的是, 验证集和测试集的比例是均衡的 (50% vs 50%), 这能更好地验证模型对于每个group的表现. 所以, 这里自然而然有一个分布偏移的问题.
训练方法
作者比较不同训练方法下的表现:
- ERM:
其中\(\hat{P}\)为训练集上的经验分布.
- group DRO: DRO假设 (1) 中的 \(\mathcal{Q}:= \{\sum_{g=1}^m q_g \hat{P}_g: q \in \Delta_m \}\), 其中\(\Delta_m\)是一个\(m-1\)维度的单纯形, 时间上, 我们认为\(\mathcal{Q}\)中包含的分布由\(m\)个部分组合而成. 易得:
故, 实际上 \(\hat{\theta}_{\text{DRO}}\)就是使得各个group的最大化经验损失最小化.
- group adjustments DRO: 当\(\hat{P}\)和真实的分布\(P\)一致的时候, 通过 group DRO 理论上就能缓解group的偏见问题, 但是往往存在分布偏移, 所以实际上理论和实际之间存在一个泛化误差: \(\delta_g = \mathbb{E}_{(x, y) \sim P_g} [\ell(\theta; (x, y))] - \mathbb{E}_{(x, y) \sim \hat{P}_g} [\ell(\theta; (x, y))]\), 故作者引入一个估计 \(\hat{\delta}_g = C / \sqrt{n_g}\)来抵消这一误差:
其中\(C\)代表模型的拟合能力 (超参数), \(1 / \sqrt{n_g}\) 则反应了小的group相较于大的group过拟合的一个倾向程度.
- Importance Weighting: 重加权是平衡分布的一个常用手段,
通常的, 选择 \(w_g = 1 / \mathbb{E}_{g' \sim \hat{P}} [\mathbb{I}(g' = g)]\).
ERM vs group DRO
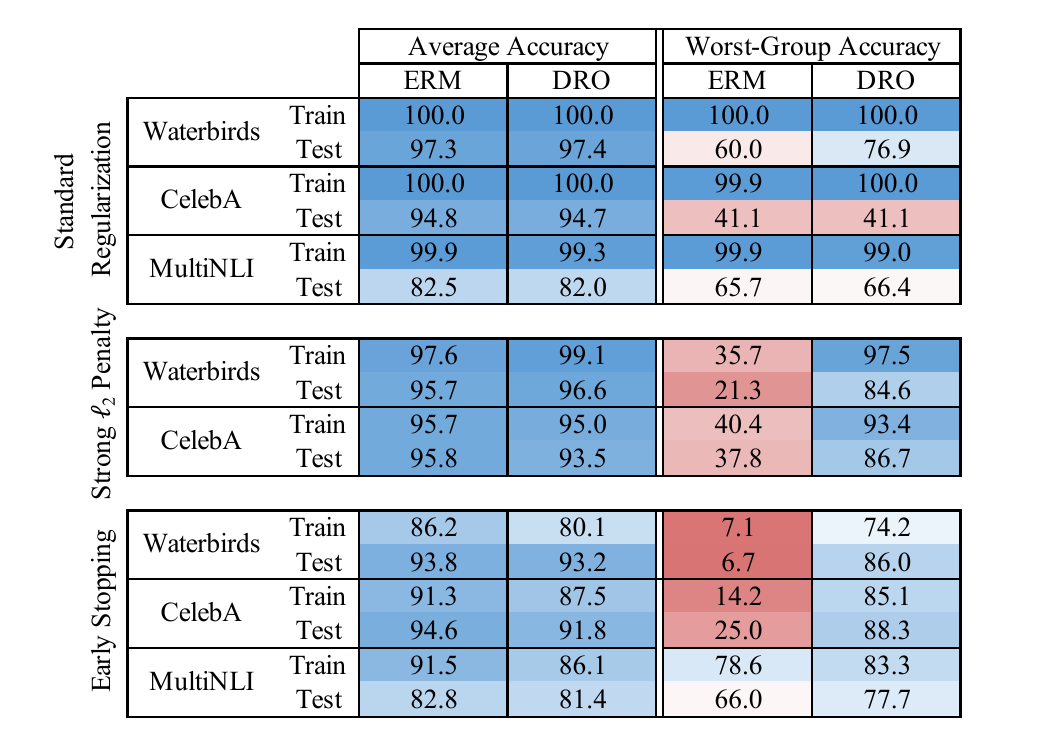
如上图所示, 可知:
- ERM 和 DRO 的 Average Accuracy 是差不多的;
- 在不添加正则化的时候 (standard), ERM 和 DRO 在最差的group上的测试正确率非常糟糕, 虽然训练精度已经相当不错了, 这表现了严重的过拟合;
- 在添加了注入 \(\ell_2\)惩罚项和早停等正则化后, DRO才能在消除group偏见上起到作用.
group DRO vs adjusted group DRO
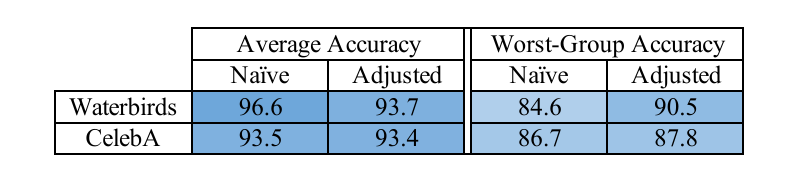
注: 仅\(\ell_2\).
由上图可知, 传统的 group DRO 由于泛化误差的存在, 任有很大进步空间, 这一点可由 (5) 来缓解.
ERM vs DRO vs Importance weighting

注: UW (upweighting)
由上图可知, 重加权也能起到平衡的作用, 但是较劣于 DRO . 此外, 作者还证明了在\(\ell\)关于\(\theta\)是凸的连续函数时, 二者是等价的, 但是一旦没有了凸性就无法保证了.
Online group DRO
虽然已经有方法提出如何解决 (3) 了, 但是这些方法大抵缺乏可扩展性和收敛性保证. 本文便提出了一种 Online 算法. 注意求解 (3) 实际上等价于
作者将 \(q_g\)视作可训练的参数, 然后交替训练其与\(\theta\).

注: 作者在实际中是使用mini-batch进行训练的:
In practice, we use minibatches and a momentum term for \(\theta\).
注: 看代码, 关于 \(q\)的更新也是 mini-batch的. 此时\(\ell\)为对应group的平均损失.
注: 我好像在 boost 之类的算法中看到过类似这种的指数上升的更新方式, 但是我并不清楚它的利和弊. 简单看来, 这个更新方式会倾向于更大的group和更难的group, 感觉和reweighting的方式还是有挺大差别的.
