Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features
概
推荐系统非常依赖特征工程, 这篇文章提出的Deep Crossing则对此没有过多的要求.
主要内容
特征
本文主要研究的是广告推荐的问题(即预测点击率), 不过此框架推广到其它推荐领域应该也不是难事.
| 特征 | 含义 | 类型 |
|---|---|---|
| Query | 用户在搜索框中的输入的搜索词 | 文本 |
| KeyWord | 广告主为广告添加的描述其产品的关键词 | 文本 |
| Title | 广告标题 | 文本 |
| Landing page | 点击广告后的落地页面 | - |
| Match type | 搜索词匹配类型: exact, phrase, broad, contextual | 类别 |
| Campaign | 广告主创建的广告投放计划, 包括预算, 定向条件等 | - |
| Impression | 广告曝光例子, 记录了在实际曝光场景中的相关信息 | - |
| Click | 广告点击例子, 记录了广告在实际点击场景中的相关信息 | - |
| Click through rate | 广告的历史点击率 | 数值? |
| Click prediction | 另一个CTR模型预估的点击率 | 数值? |
文本: 可以转换成 a tri-letter gram (不了解);
类别: one-hot 向量, 比如 Match type: [1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1];
像 Campaign 这类, 可能有上百万的案例, 其包括:
- CampaignID: 类别;
- CampaignCount: 数字, 描述了 campaign 的统计属性, 比如点击率
两个属性. 如果仅仅依照 ID 转换成 one-hot 向量, 那么显然过于庞大和稀疏了, 所以本文的做法是将二者融合, 构建一个10001维的向量\((\bm{x} \in [0, 1]^{10001}, y \in \mathbb{R})\), 其中\(\bm{x}\)是one-hot向量, \(y\)表示CampaignCount这个数值属性. 倘若\(x_i, i \not = 10001\), 这表示其CapaginCount在所有的Campagin中排第\(i\)为, 若\(x_{10001} = 1\), 则表示其排名大于10000.
模型
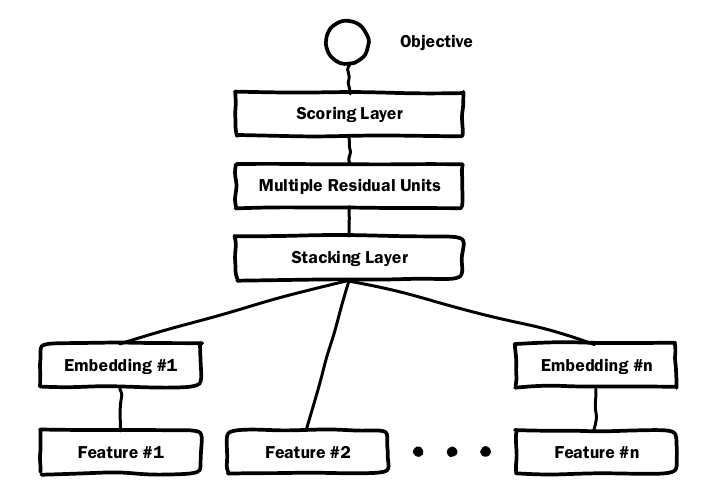
- Embedding 层: 将类别型的特征转换成维度更小的embedding, 假设输入为\(X_j^I \in [0, 1]^{n_j}\), 则
\[X_j^O = \max(\bm{0}, W_j X_j^I + \bm{b}_j) \in \mathbb{R}^{m_j}.
\]
- Stacking Layer: 将前一层的embedding和输入直接得到的数字型向量连接:
\[X^O = [X_0^O, X_1^O, \cdots, X_K^O].
\]
- Multiple Residual Units: 带残差结构的全连接层, 用于提炼特征:
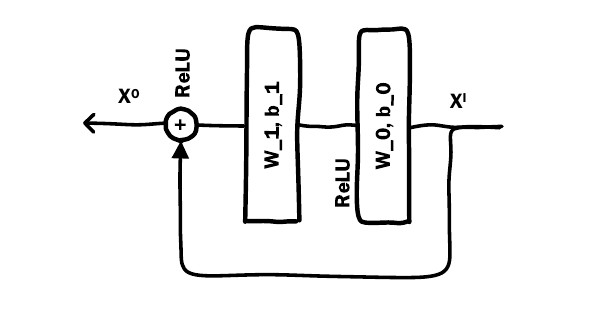
-
Scoring Layer: 逻辑斯蒂回归模型得到预测的点击率 \(p\).
-
利用BCE损失进行训练:
\[\mathcal{L} = -\frac{1}{N} \sum_{i=1}^N (y_i \log p_i + (1 - y_i) \log (1 - p_i)).
\]
注: 看别人写得代码, 数值型的变量 \(x \in \mathbb{R}\), 也有用\(x \cdot \bm{w}\)来得到embedding的, 也不是直接到stacking layer的.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号