Exploring Memorization in Adversarial Training
概
大家知道, 即使是随机的标签 (是随机赋予的), 普通的网络也能够很好地拟合(训练精度几乎达到100%). 本文发现, 即使是对抗训练, 网络也能够很好地拟合.
作者认为, 这是导致过拟合的元凶, 利用 temporal ensembling (TE) 可以缓解这一点.
主要内容
PGD-AT:
TRADES:
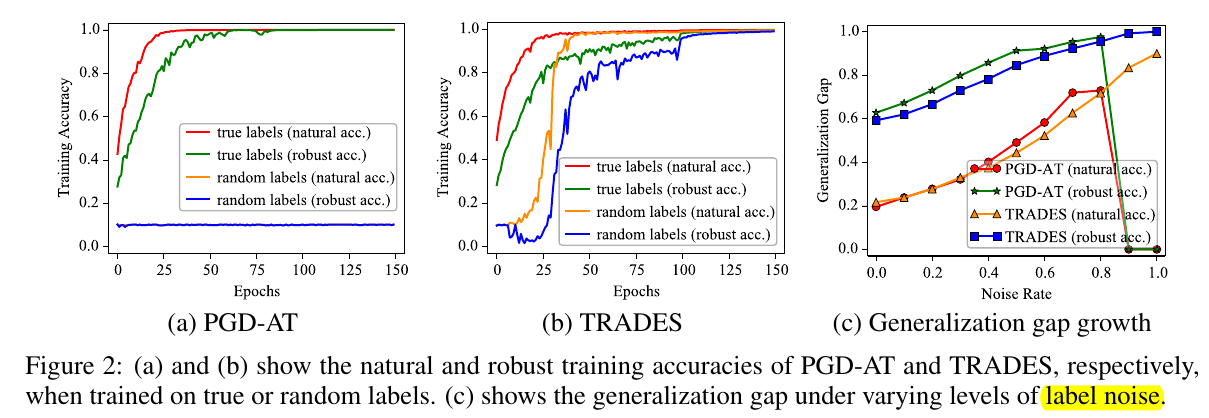
通过比较(a), (b)可以发现, 当通过随机标签进行训练的时候, TRADES的训练精度几乎可以达到100%, 这说明网络的拟合能力是完全足够的. 另一方面, PGD-AT不行的原因是, 其损失函数仅包含对抗损失, 训练被杀死了.
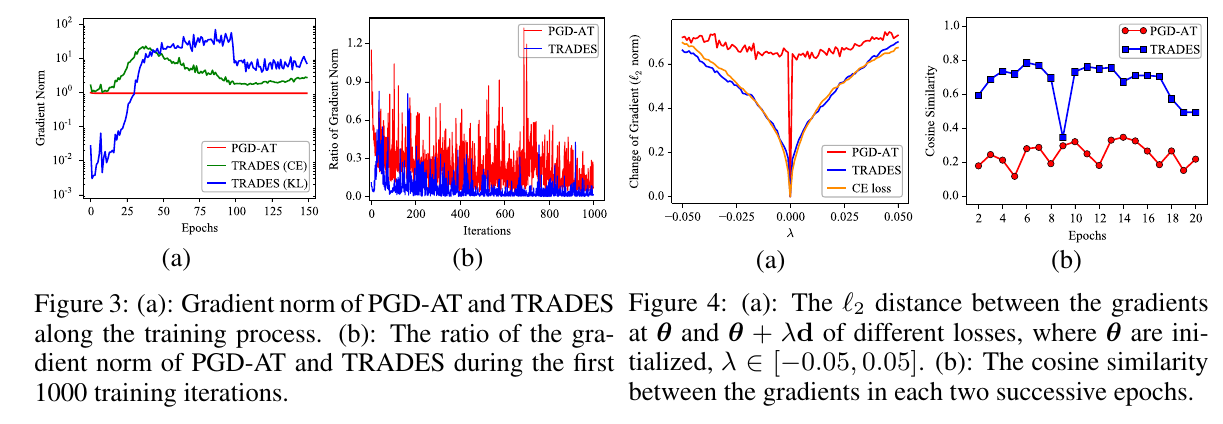
作者发现, 该主要原因是PGD-AT利用随即标签训练前后的参数扰动变化过大, 可以理解为当前点的梯度几乎是没有任何参考意义的, 这导致训练被杀死.
相比之下, TRADES因为还有普通样本的交叉熵损失, 所以比较稳定.
过拟合
既然神经网络有如此的强大的拟合能力, 这在一定程度上解释了对抗训练为什么会这么容易出现过拟合. 设想, 因为我们对抗训练的时候, 一直采用的标签训练, 但是对于因为, 当比较大的时候, 用标签似乎就有点过于强硬了. 所以作者采用了 temporal ensembling来缓解:
其中
累积了过去的网络对这个样本的预测. 这意味着, 我们希望过去的预测和现在的能够尽可能保持一致性.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2019-04-12 一些矩阵范数的subgradients