Transparent Classification with Multilayer Logical Perceptrons and Random Binarization
概
和这儿类似的rule-based的网络, 主要探讨如何训练它.
主要内容
作者提出一种从零开始训练的rule-based网络, 其由如下的CAS (Concept Rule Sets) 模块构成:
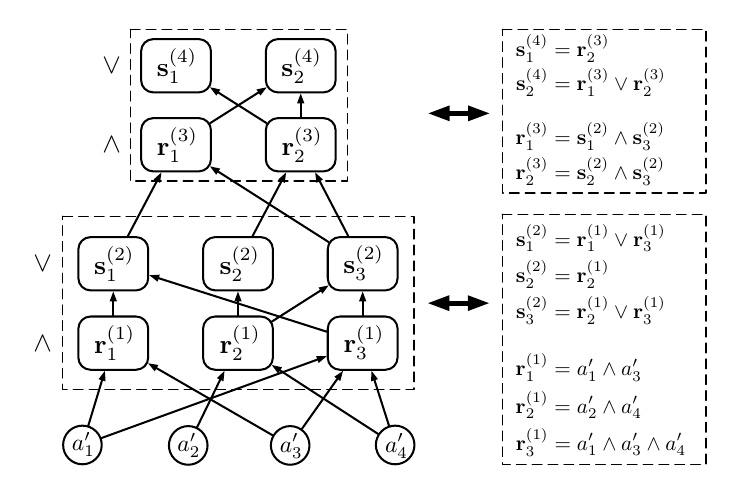
相较于 这儿 除了基本模块不同外, 作者额外引入了 Random Binarlization (RB) 机制. 即在训练其连续化版本 \(\hat{W}\) 时:
- 通过一定概率生成掩码矩阵 \(M\);
- 对于\(M_{i,j} = 1\)的权重\(\hat{W}_{i,j}\)进行二元化:
\[\tilde{W}_{i,j} = \mathbb{I}(\hat{W}_{i, j} > \mathcal{T}),
\]
其余元素保持不变;
3. 训练时仅训练马偕 \(M_{i,j} = 0\)的元素, 即固定那些被二元化的权重;
4. 训练一定次数后, 将这些被二元化的权重恢复如初, 回到第二步, 重复训练.
相当于每次训练一部分, 另一部分试图去适应二元化的部分, 这样可能在之后二元后后会容易些.
输入
对于连续的输入, 首先要通过离散, 作者采用的是:
Dougherty, J.; Kohavi, R.; and Sahami, M. 1995. Supervised and unsupervised discretization of continuous features. In MLP. Elsevier. 194–202.
的工作.
简化
最后获得的网络可能存在冗余的结点: 不存在路径经过的结点 (dead node) 和 重复的结点 (规则重复), 简化这些结点可以降低模型的复杂度.

