Xu H., Liu X., Wang W., Jain A. K. Tang J., Ding W., Wu Z. and Liu Z. Towards the memorization effect of neural networks in adversarial training. In International Conference on Learning Representations (ICLR), 2022.
概
作者将样本分为 typical 和 atypical (可以理解为较少的和其它类别相近的困难样本) 两类. 神经网络对于前者能够利用语义特征来区别, 而对于后者往往需要利用记忆. 对于标准训练来说, 记忆 atypical 的样本并不会降低网络的泛化能力. 对于对抗训练来说, 为了记忆 atypical 样本, 容易造成自然精度的下滑, 所以作者提出BAT来更细致地对待这些 atypcial 样本.
主要内容
typcial 和 atypical 样本
首先定义利用算法A和数据集D在样本xi处的'memorization value':
mem(A,D,xi)=Pr.F←A(D)(F(xi)=yi)−Pr.F←A(D∖xi)(F(xi)=yi).(1)
如果该值很大, 说明网络必须记忆这个样本, 否则难以正确识别出它 (也就是说这个样本的特征其实是脱离整个数据集的分布的).
上面的是对于训练集中的样本而言的, 对于测试集合的样本 (x′j,y′j) 和训练集中的样本 (xi,yi) 有:
infl(A,D,xi,x′j)=Pr.F←A(D)(F(x′j)=y′j)−Pr.F←A(D∖xi)(F(x′j)=y′j).(2)
给定阈值 t, 我们定义 atpcial 训练样本和测试样本:
Datyp:={xi∈D|mem(xi)>t},D′atyp:={x′j∈D′|infl(xi,x′j)>t,∀xi∈Datyp}.
atypical 较差的泛化性
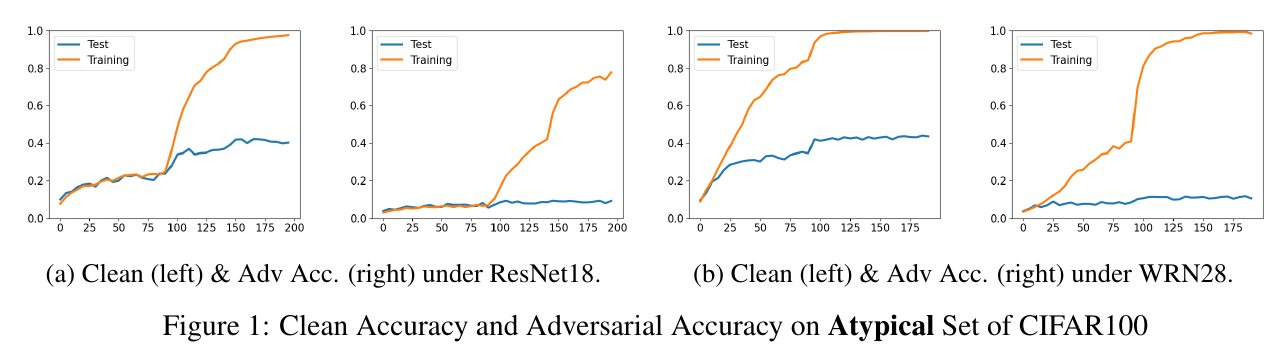
作者选择了 t=0.15, 然后在整个数据集上进行训练, 可以发现:
- 无论是自然精度还是鲁棒性, 其Training的结果都很好, 这意味这ResNet18WRN28都有足够的表示能力;
- 随着训练精度的上升, 在 D′atyp上的自然精度能够上升, 但是鲁棒性几乎没有变换, 说明记忆 atpyical 样本对于增强鲁棒性是无效的.
typcial 和 atypical 样本在鲁棒性上的冲突
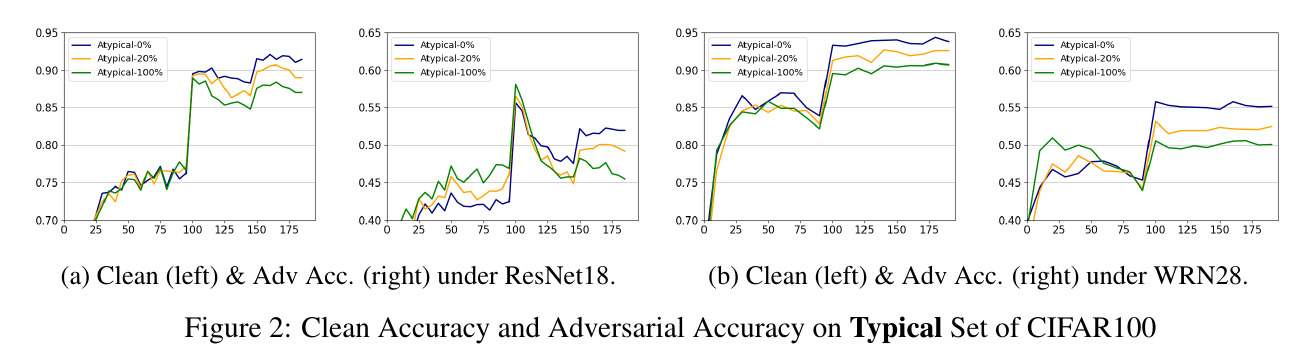
这里, 作者以 typical 样本为基础, 逐步添加 atypical 样本, 可以发现让网络去记忆这些 atypical 反而会造成对 typical 数据有效性. 作者认为, 这些 atypical 由于本身数目比较少, 然后又和别的类别比较接近, 区分难度大的特点, 导致网络想要去记忆这些样本反而会学习到更差的特征.

Benign Adversarial Training (BAT)
作者通过重加权和 Discrimination Loss 来解决这一问题.
cost-sensitive reweighting strategy
{exp(−α⋅q(xadvi))if mem(xi)>t and argmaxkFk(xadvi)≠y1otherwise.
其中
q(xadvi)=maxk≠yFk(xadvi).
然后分类损失是:
argminF1∑iwi∑i[wi⋅L(F(xadvi),yi)].
discrimination loss
LDL(F)=E(xi,yi)(xj,yj),{(xb,yb)}Bb=1[−logehT(xadvi)h(xadvj)/τ∑Bb=1ehT(xadvi)h(xadvk)/τ],
其中
yi=yj,yb≠yi,b=1,2,⋯,B,mem(xi),mem(xj),mem(xb)<t.
即该损失希望 typcial 样本的特征 h(xi) (倒数第二层) 同类之间相互靠近, 不同类之间相互远离.
最后的损失是:
argminF1∑iwi∑i[wi⋅L(F(xadvi),yi)]+β⋅LDL(F).
实验设置:
- α=1|2,β=0.2;
- 160 epochs, momentum=0.9, weight decay = 5e-4;
- lr=0.1, [80, 120] x 0.1
- CIFAR: 8/255; TinyImageNet: 4/255



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2021-04-03 Direct and Indirect Effects