LTD: Low Temperature Distillation for Robust Adversarial Training
概
本文利用distillation来提高网络鲁棒性.
主要内容
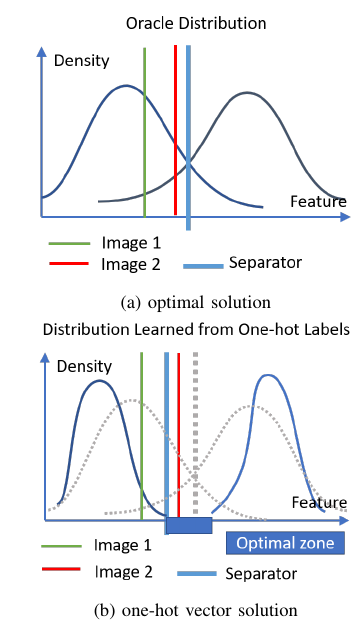
如上图所示, 作者认为, 如果我们用one-hot的标签进行训练, 结果会导致图(b)中的情形, 于是两个分布中间的空袭部分均可以作为分类边界, 从而导致存在大量的对抗样本的存在. 解决的方案要么更加密集的采样(即增加样本), 或者使用soft-label即本文的策略.
本文的目标即:
\[\mathcal{L}_{LTD} = \mathcal{L}_{ce}(p^s(x; T=1), p^t(x;T=\tau)) + \beta \mathrm{KL}(p^s(x;T=1)\|p^s(x';T=1)),
\]
其中\(p^s\)表示学生网络得到的概率向量, 而\(p^t\)是在普通数据上训练好的教师网络得到的概率向量(且注意其temperature不为1, 根据作者的消融实验, \(T=5\)对于WRN是一个不错的选择).
可以发现, 上述目标与普通的TRADES仅仅差别与第一项改用了soft-label.
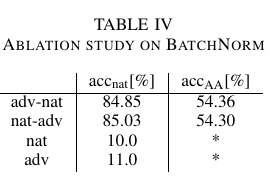
作者还额外讨论了BN的作用, 如果单独使用干净或者对抗样本进行更新, 网络几乎是不收敛的. 而先更新干净或者对抗样本对最后的结果影响不大. 这个还挺有意思的, 我也做过类似的东西, 会不会是被kill了?
问?
不晓得作者有没有试过AT的distillation, 因为感觉没有特别的创新点, 难不成AT上不起作用?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号