MLP-Mixer: An all-MLP Architecture for Vision
概
CNN, Transformer, 现在直接用全连接层就可以了. 真的乱.
主要内容
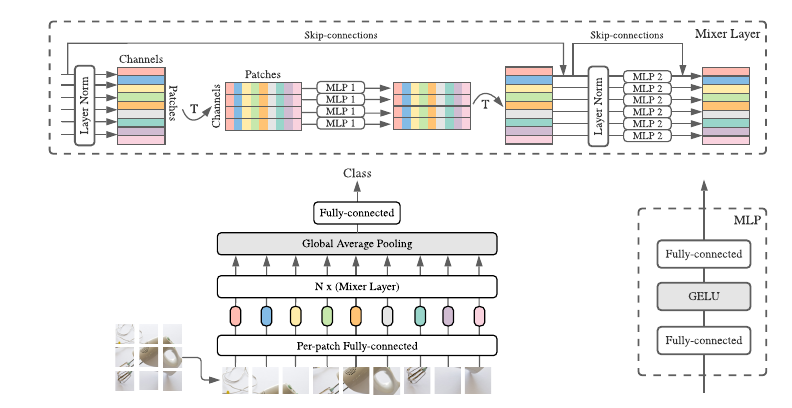
如上图所示:
-
Input: 和ViT一样, 首先将图片切割成一个个patch, 然后通过全连接层将每个patch映射为其对于的embeddings:
\[X \in \mathbb{R}^{B \times T \times D}, \]其中\(B\)是batch size, \(T\)即为patches的数目, \(D\)便是图中channels的大小.
-
将其通过Mixer Layer N次, 并经过global average pooling得到特征, 再通过全连接层得到logits.
-
输出类别.
其中, Mixer Layer的流程如下(考虑一个batch):
-
对每个channel进行处理:
\[U_{\cdot, i} = X_{\cdot, i} + W_2 \sigma (W_1 \mathrm{LayerNorm}(X)_{*, i}). \] -
此时得到\(U \in \mathbb{R}^{B \times T \times D}\), 再对每个patch进行处理:
\[Y_{j, *} = U_{j, *} + W_4 \sigma (W_3 \mathrm{LayerNorm}(U)_{j, *}). \] -
最后得到输出\(Y\).
可以发现, MLP-Mixer 实际上将channel-wise和spatial-wise的操作拆分开来了, 这样即可获得很好的效果.

