各层的特征的差异性
motivation
不同层之间的特征分布有什么关系?
settings
STD
| Attribute | Value |
|---|---|
| batch_size | 128 |
| beta1 | 0.9 |
| beta2 | 0.999 |
| dataset | cifar10 |
| description | STD=STD-sgd-0.1=128=default |
| epochs | 164 |
| learning_policy | [82, 123] x 0.1 |
| loss | cross_entropy |
| lr | 0.1 |
| model | resnet32 |
| momentum | 0.9 |
| optimizer | sgd |
| progress | False |
| resume | False |
| seed | 1 |
| stats_log | True |
| transform | default |
| weight_decay | 0.0002 |
AT
| Attribute | Value |
|---|---|
| attack | pgd-linf |
| batch_size | 128 |
| beta1 | 0.9 |
| beta2 | 0.999 |
| dataset | cifar10 |
| description | AT=AT-sgd-0.1=pgd-linf-0.0314-0.25-10=128=default |
| epochs | 100 |
| epsilon | 0.03137254901960784 |
| learning_policy | [50, 75] x 0.1 |
| loss | cross_entropy |
| lr | 0.1 |
| model | resnet32 |
| momentum | 0.9 |
| optimizer | sgd |
| progress | False |
| resume | False |
| seed | 1 |
| stats_log | True |
| steps | 10 |
| stepsize | 0.25 |
| transform | default |
| weight_decay | 0.0005 |
results
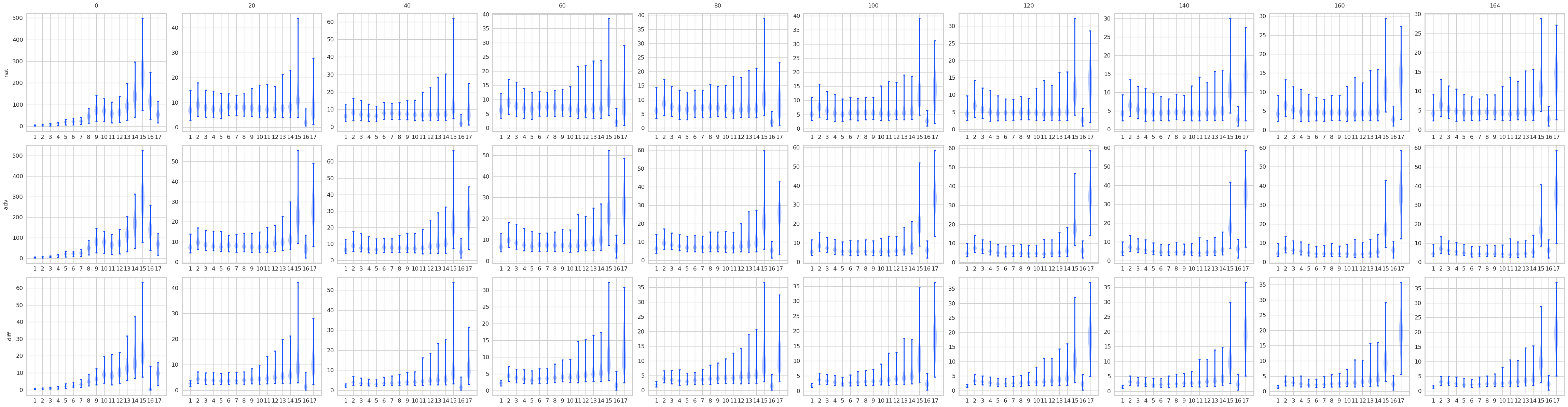
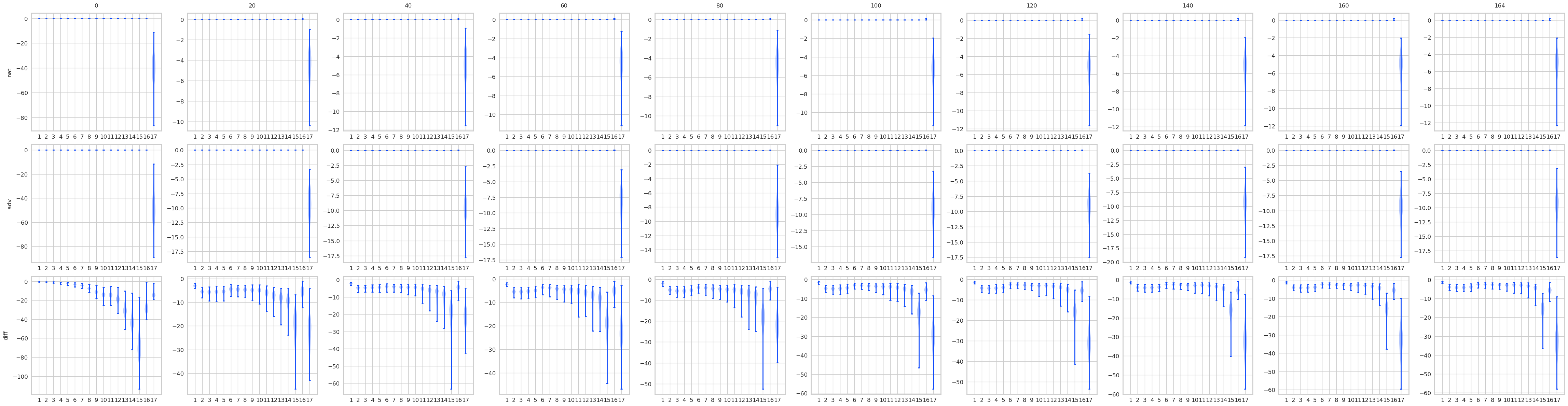
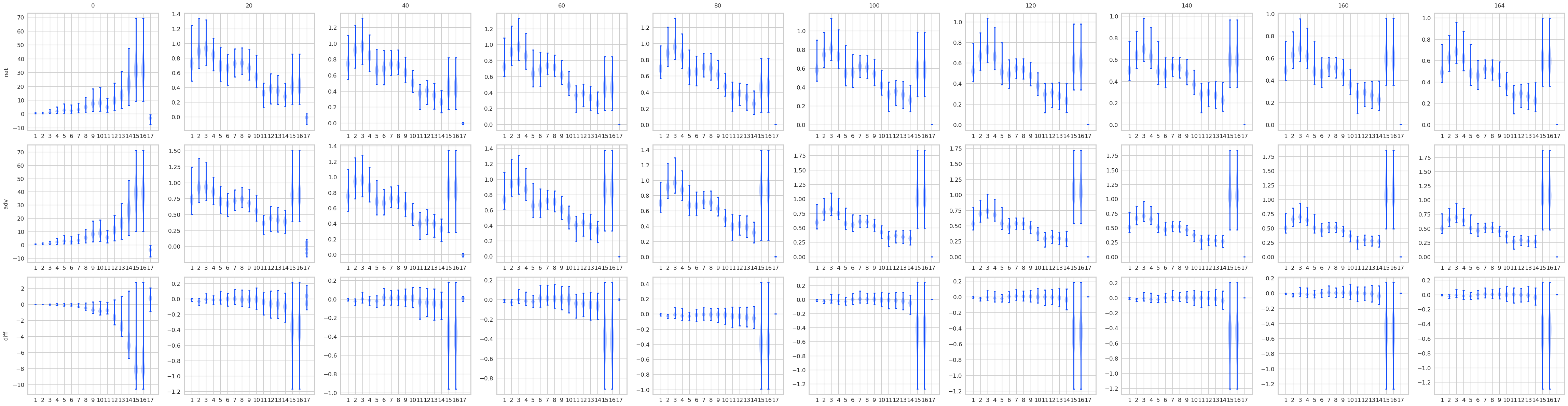
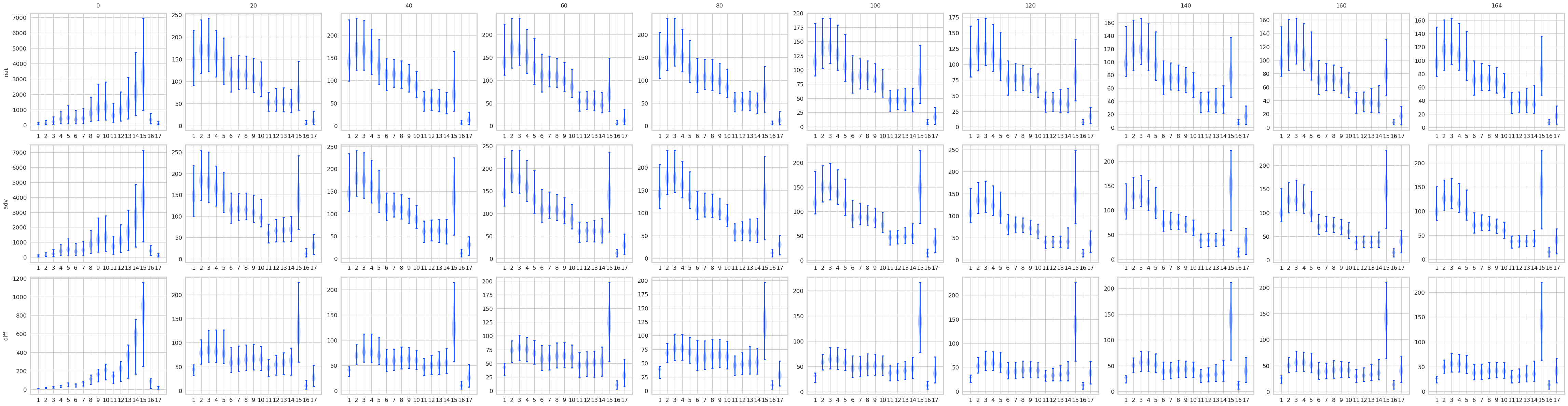
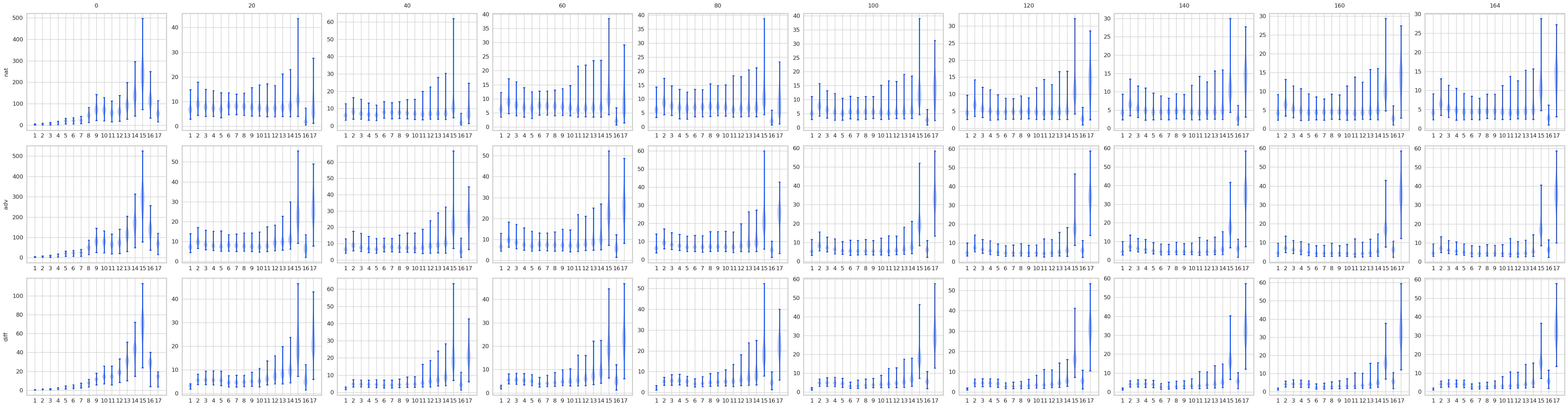
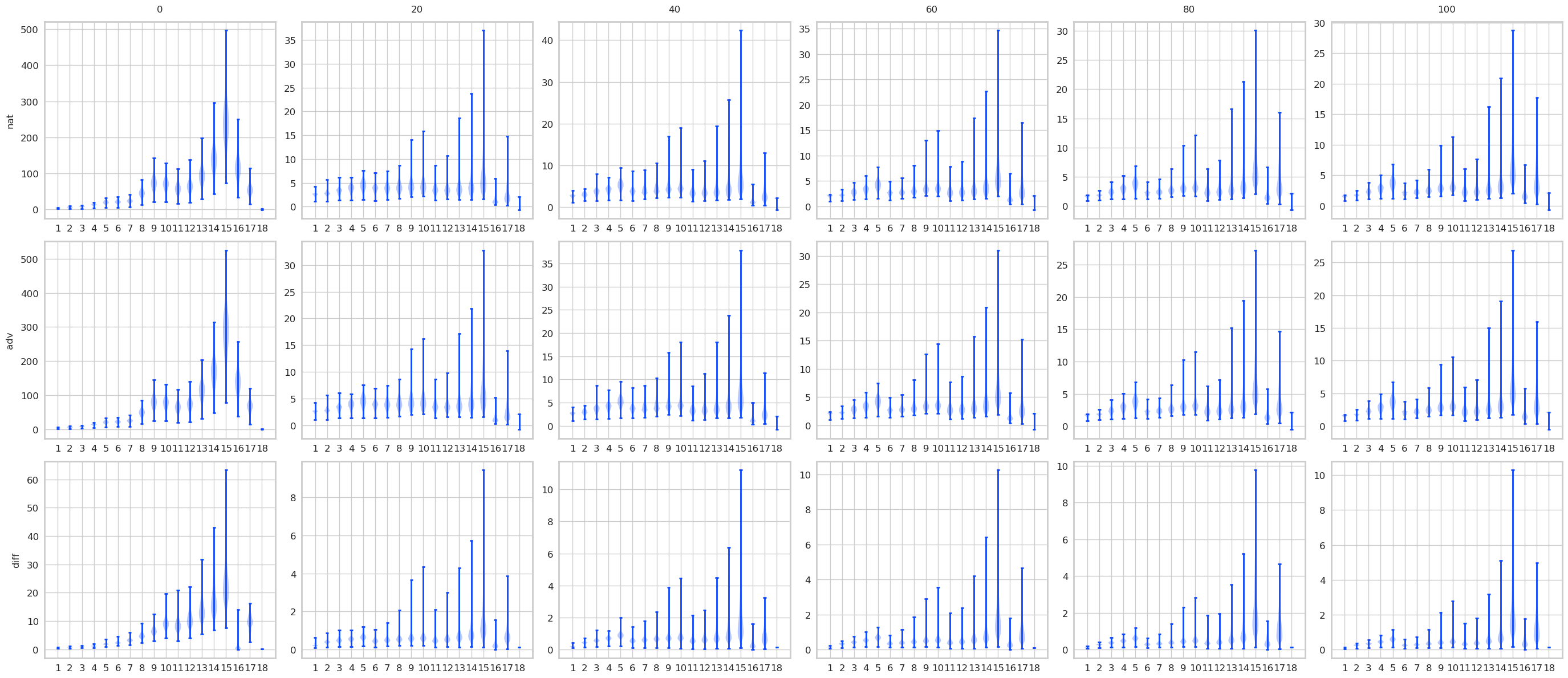
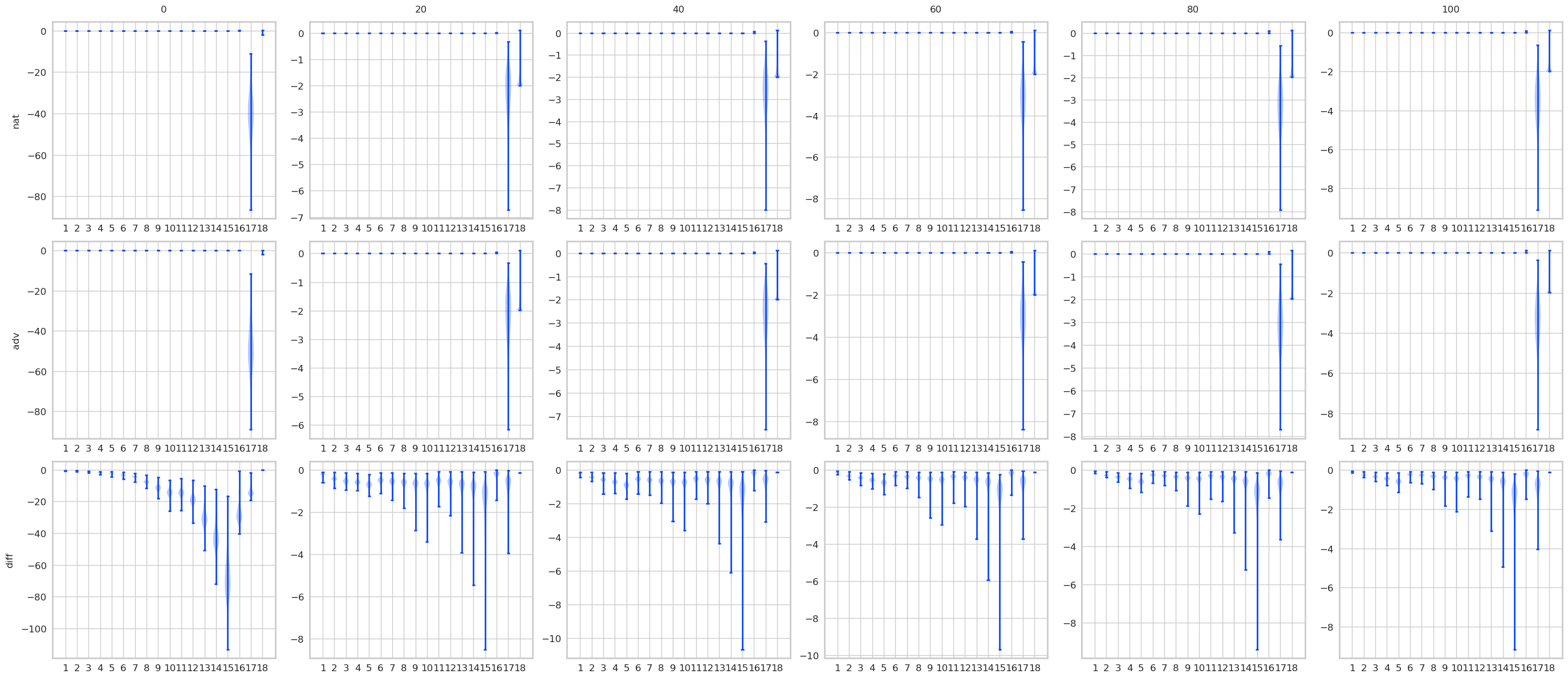
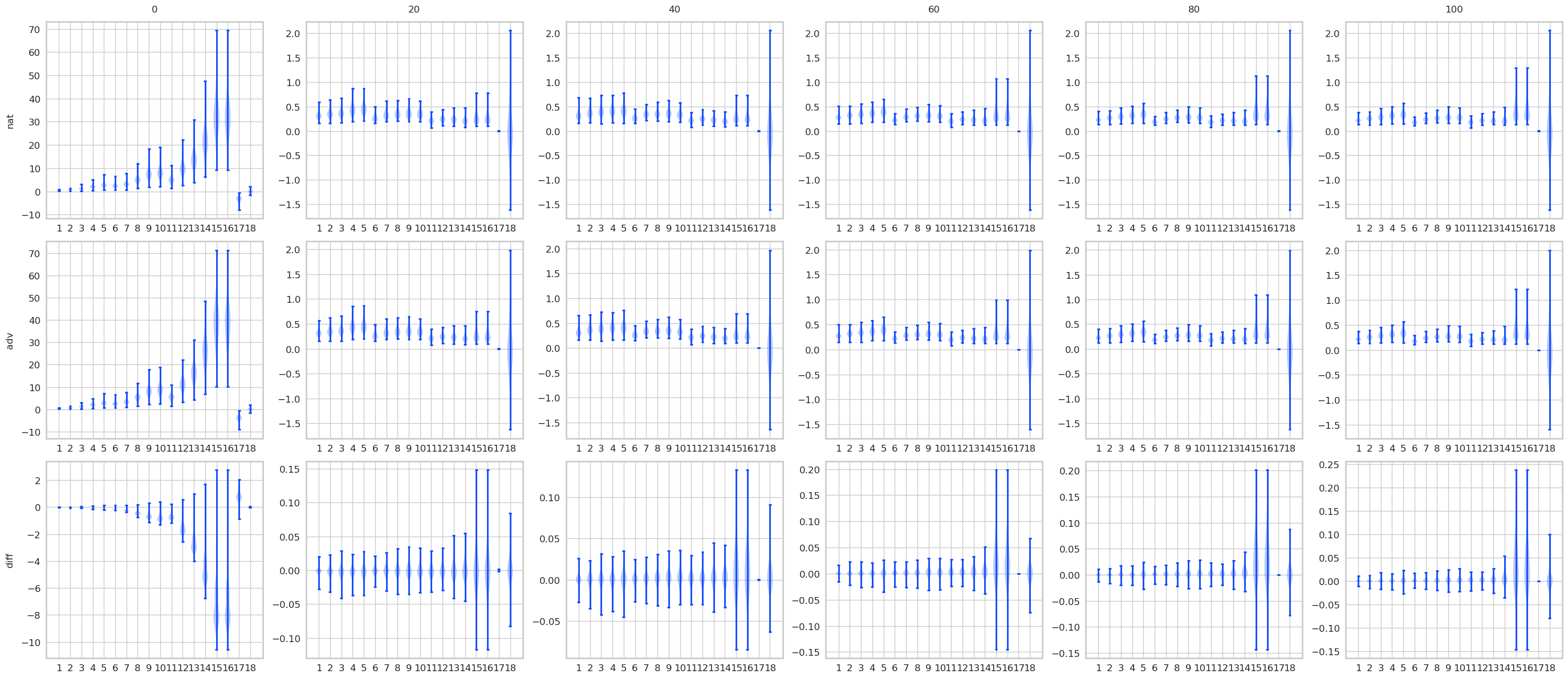
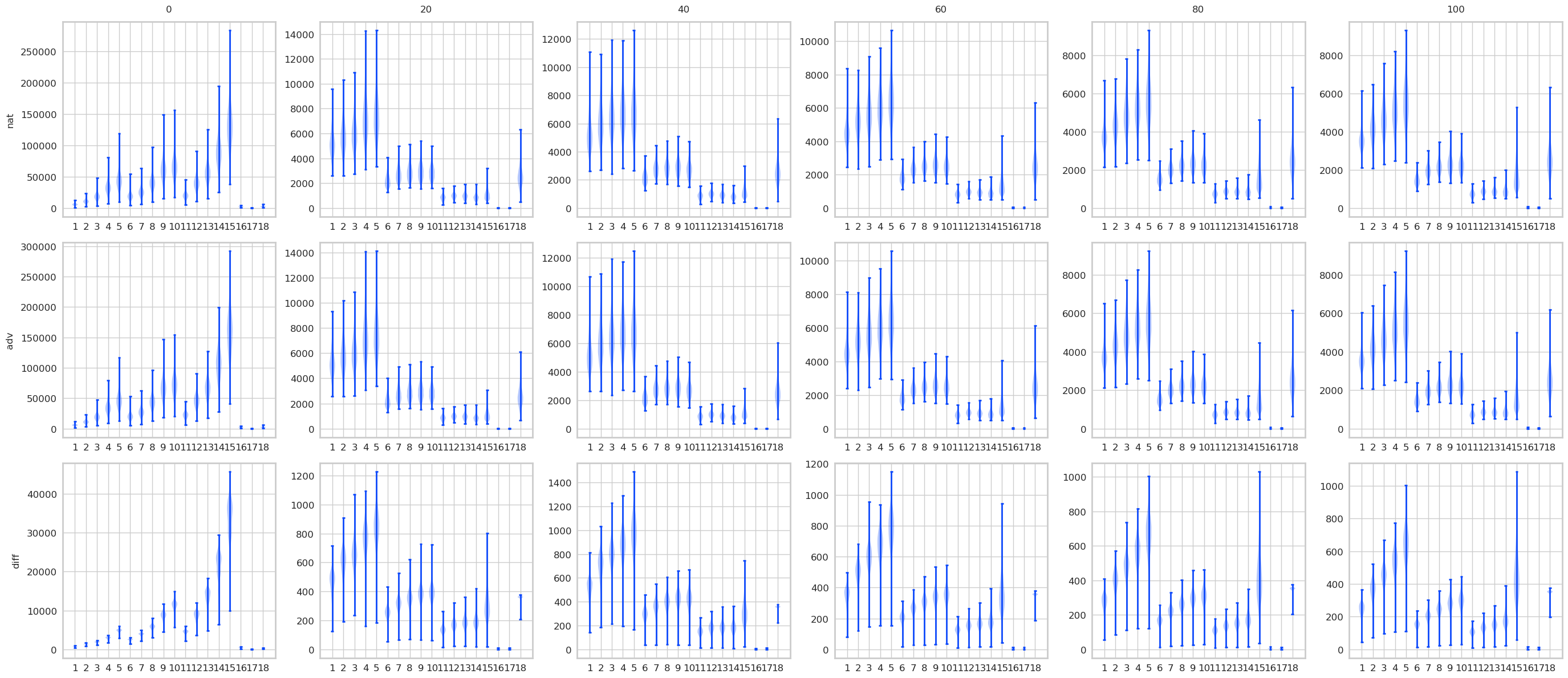
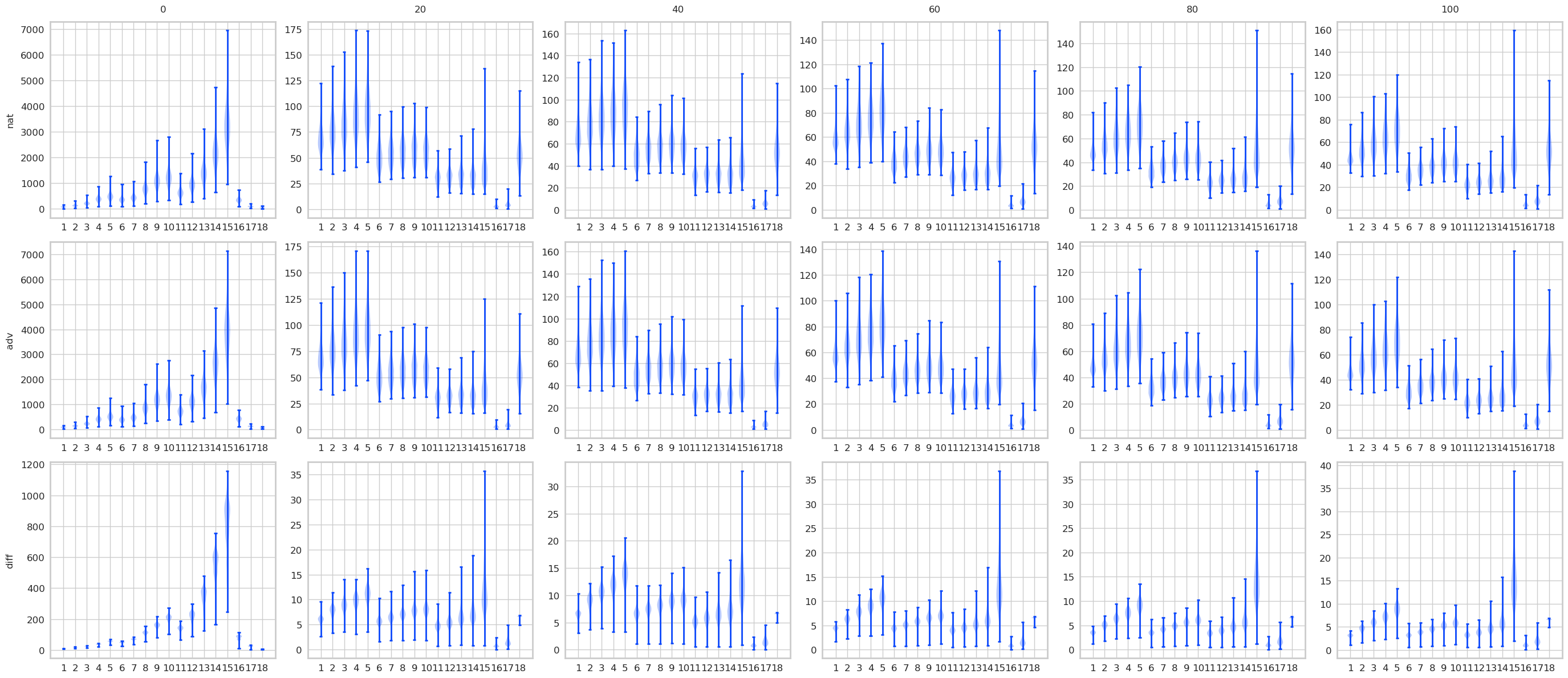
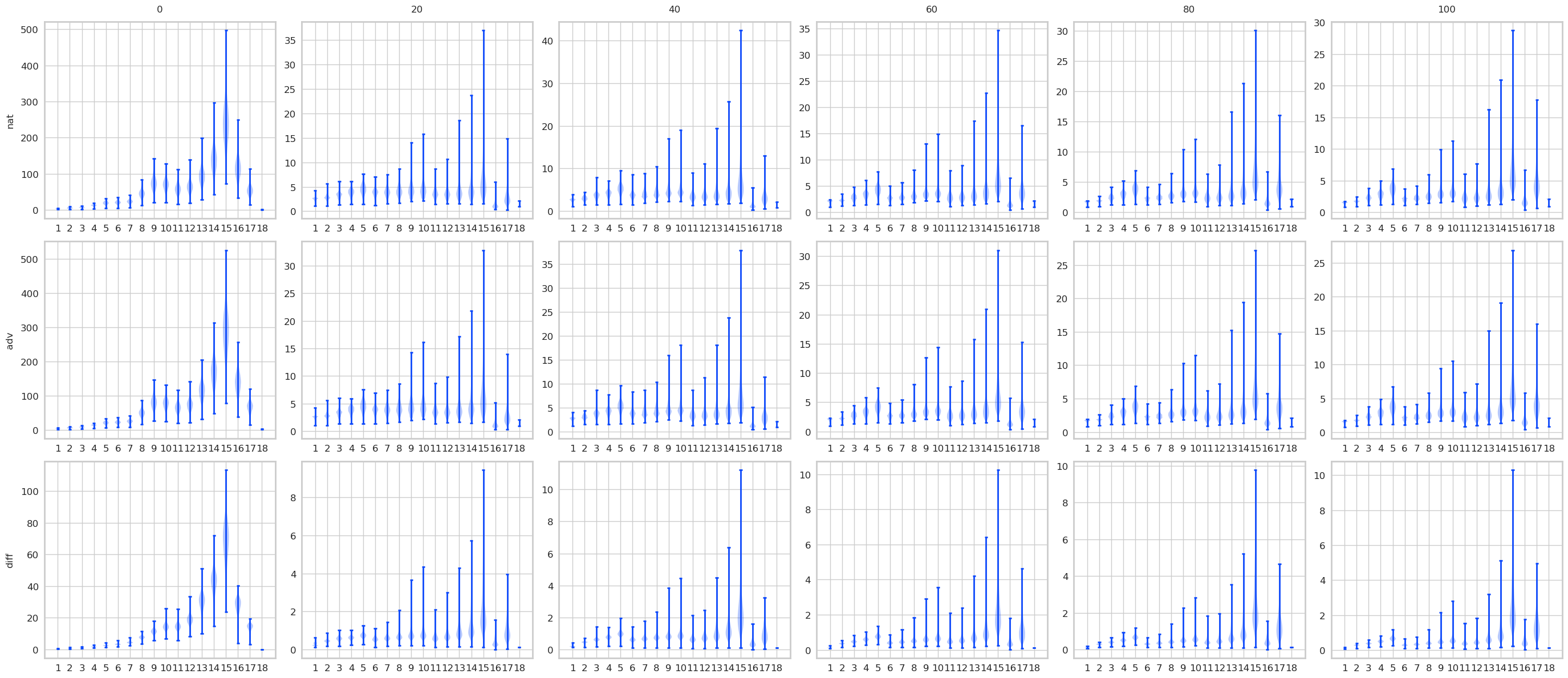
对比STD 和 AT, 有一些结果是预期的, 显然AT的最后logits是变化是很小的, 而STD的变化很大. 不过有意思的是, 其实STD的前面的层, 变化也都不大, 到了pooling前后变化一下子打了起来, 所以如果对pooling前加以限制是否能提高鲁棒性? 感觉会是跷跷板啊.
注: AT比STD多了一层, 是把输入作为第一层添加进去了.
STD
max
min
mean
norm1
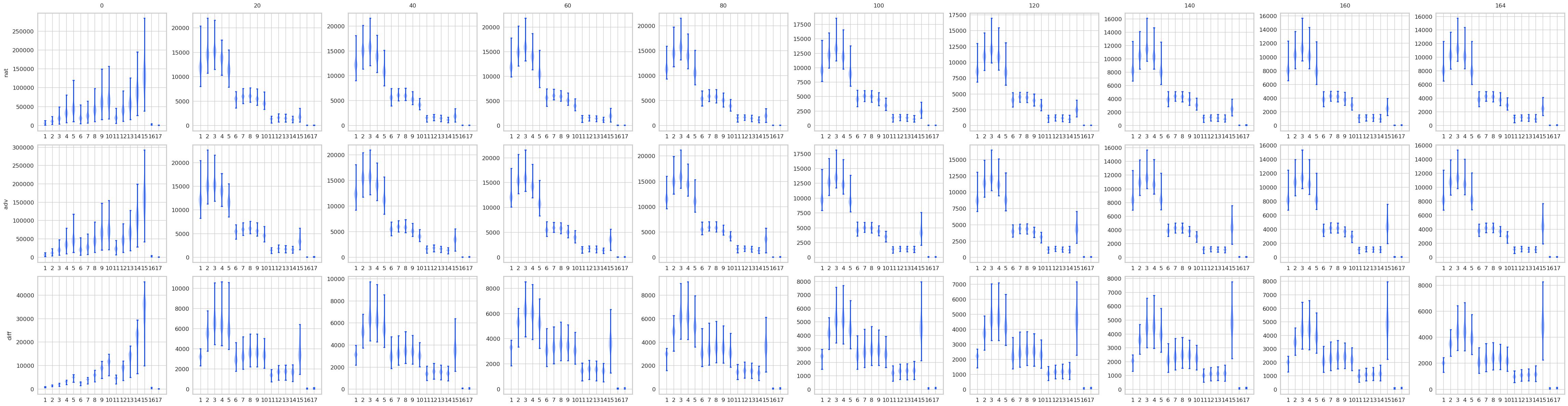
norm2
norminf
AT
max
min
mean
norm1
norm2
normlinf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号