EMA
源
Exponential moving average (EMA) 是一个非常有用的trick, 起到加速训练的作用. 近来发现, 该技巧还可以用于提高网络鲁棒性(约1% ~ 2%). EMA的流程很简单, 是我们用于训练的网络, 则在每次迭代结束后进行:
其中是网络的参数, 的网络初始化是一致的, 另外的网络参数的更新仅仅通过上式.
一般情况下, 对抗训练用来生成对抗样本, 即
来获得, 而我想的能不能
背后的直觉是, 相较于更为平稳, 则由其产生的对抗样本的分布更加稳定, 则拟合起来会不会更加容易?
我在一个8层的网络上进行测试, 结果不如人意:
设置
| model | cifar |
|---|---|
| dataset | CIFAR-10 |
| attack | PGD |
| epsilon | 8/255 |
| stepsize | 2/255 |
| steps | 10 |
| loss | cross entropy |
| optimizer | sgd |
| momentum | 0.9 |
| beta1 | 0.9 |
| beta2 | 0.999 |
| weight_decay | 2e-4 |
| leaning_rate | 0.1 |
| learning_policy | AT |
| epochs | 200 |
| batch_size | 128 |
| transform | default |
| seed | 1 |
| alpha | 0.999 |
结果
| Accuracy | Robustness | |
|---|---|---|
| EMA* | 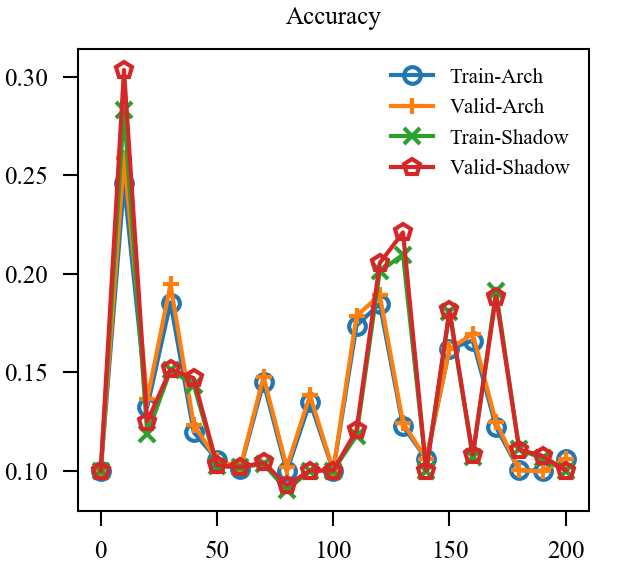 |
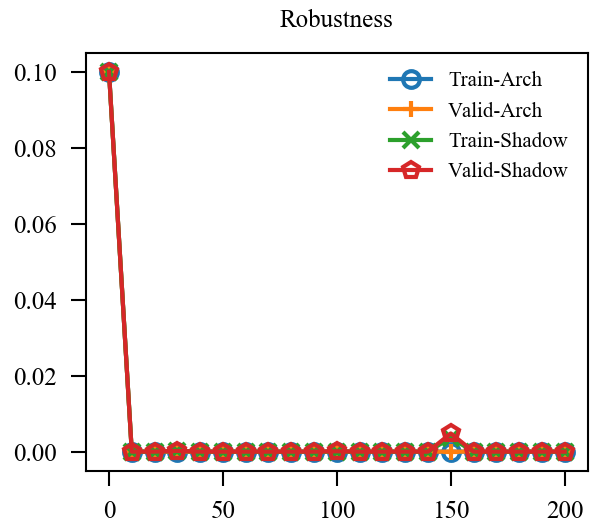 |
| EMA | 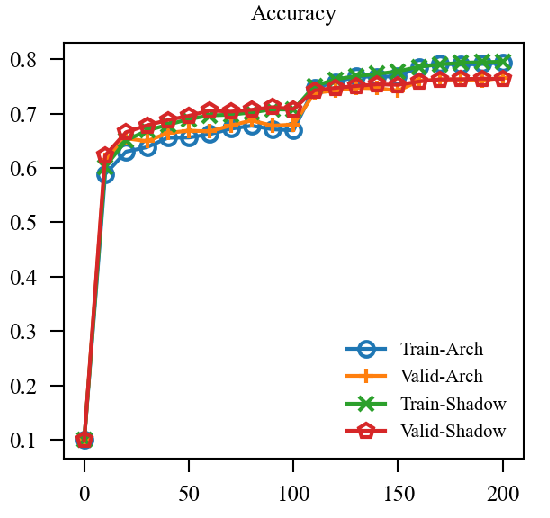 |
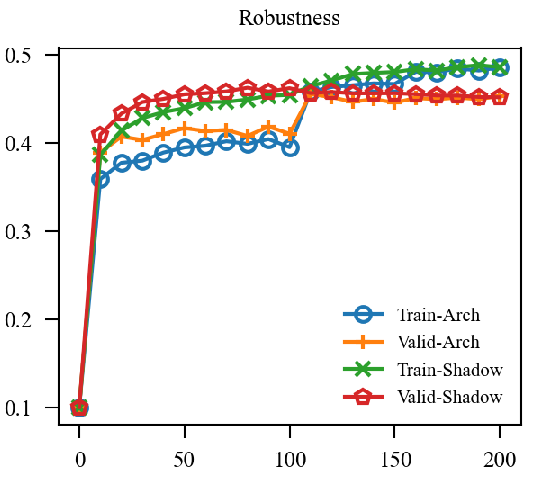 |
| EMA + GroupNorm | 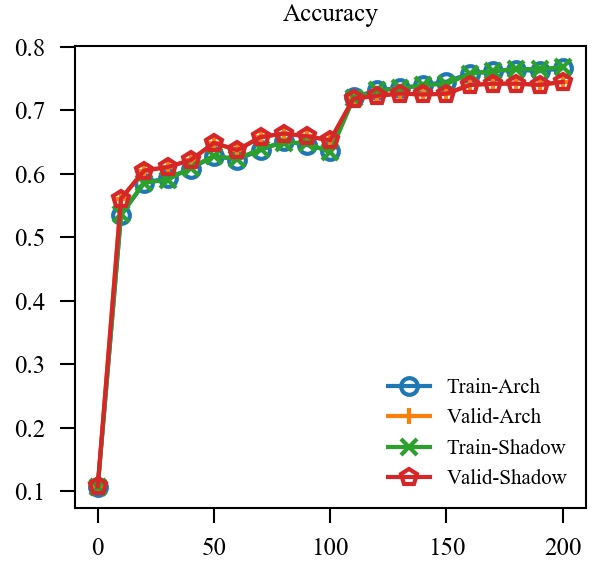 |
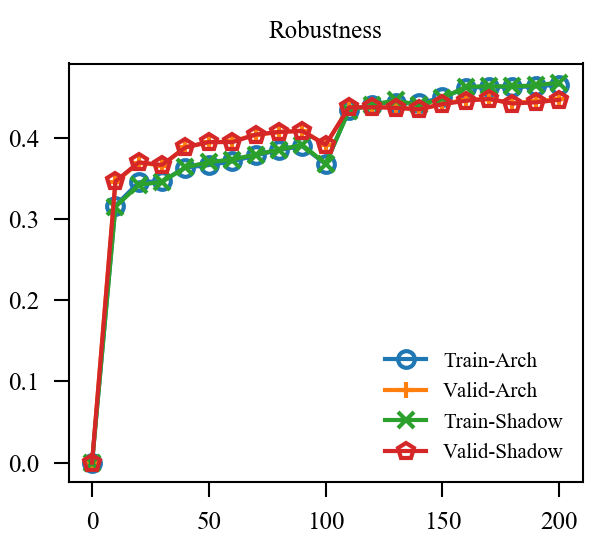 |
上图中, EMA是原本的逻辑, 可见其的确能加速训练(Shadow表示), 虽然最后的结果是降了点, 这主要是参数没调好, 毕竟对抗训练很容易过拟合. 但是我们的直接却完全不起作用, 这让我非常困惑, 因为, 我料想的最差的结果, 也应当是鲁棒性不怎样, 不能精度和鲁棒性都很差, 因为虽然是通过生成的对抗样本, 这些对抗样本依旧是满足 的,所以应该是没问题的.
于是我又尝试让由慢慢增加到, 但是结果依然不容乐观. 我料想是batch normalization的问题, 于是换了group normlization:
虽然结果似乎表明我们的直觉完全是错误的, 但是还是体会到了 normalization 的重要性, BN很难应对不同分布.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix