Interval Bound Propagation (IBP)
概
一种可验证的提高网络鲁棒性的方法.
主要内容
IBP
假设第k层表示为:
\[z_k = h_k(z_{k-1}) = \sigma_k (W_k z_{k-1} + b_k), \: k=1,2,\cdots, K.
\]
一般的分类网络, 要求:
\[e_y^Tz_K \ge e_j z_K, \: \forall j \not= y,
\]
其中\(e_j\)只有第\(j\)个元素为1, 其余均为0.
相应的, 如果考虑鲁棒性, 则需要
\[\forall z_0 \in \mathcal{X}(x_0):= \{x| \|x-x_0\|_{\infty} < \epsilon \},
\]
\[[z_K]_y = e_y^Tz_K \ge e_j^T z_K = [z_K]_j, \: \forall j \not= y,
\]
成立.
现在, 假设已知
\[\underline{z}_{k-1} \le z_{k-1} \le \overline{z}_{k-1},
\]
并令
\[\mu_{k-1} = \frac{\overline{z}_{k-1} + \underline{z}_{k-1}}{2} \\
r_{k-1} = \frac{\overline{z}_{k-1} - \underline{z}_{k-1}}{2} \\
\mu_k = W_k \mu_{k-1} + b \\
r_k = |W_k|r_{k-1} \\
\]
则
\[\mu_k - r_k \le W_k z_{k-1} + b \le \mu_k + r_k,
\]
其中\(|\cdot|\)是element-wise的绝对值.
注:
\[\max_{x \in [\underline{x}, \overline{x}]} \quad a \cdot x
\Rightarrow x =
\left \{
\begin{array}{ll}
\overline{x}, & a \ge 0 \\
\underline{x}, & a < 0
\end{array}
\right .
\Rightarrow
a \cdot x = \frac{a(\overline{x}+\underline{x})}{2} + \frac{|a|(\overline{x}-\underline{x})}{2}.
\]
倘若激活函数\(\sigma\)是单调的, 进而有
\[\underline{z}_k = \sigma_k(\mu_k - r_k), \: \overline{z}_k = \sigma_k (\mu_k + r_k) \\
\underline{z}_k \le z_k \le \overline{z}_k.
\]
以此类推, 我们可以获得:
\[\underline{z}_K \le z_K \le \overline{z}_K.
\]
可知:
\[[z_K]_j - [z_K]_y \le [\overline{z}_K]_j - [\underline{z}_K]_y,
\]
显然, 如果下式
\[[\overline{z}_K]_j - [\underline{z}_K]_y \le 0, \: \forall j\not= y
\]
成立, 则该模型对于\(x_0\)在\(\epsilon\)下就是鲁棒的.
故定义
\[[z_{*}]_j =
\left \{
\begin{array}{ll}
[\overline{z}_K]_j, & j \not = y \\
[\underline{z}_K]_j, & \text{otherwise} \\
\end{array}
\right.
\]
并通过下列损失:
\[\mathcal{L} = \kappa \cdot \ell (z_K, y) + (1 - \kappa) \cdot \ell(z_*, y),
\]
其中\(\ell\)是softmax交叉熵损失.
注:
\[\max_{\|x - x_0\|_{\infty}<\epsilon} \ell (z_K(x), y) \le \ell(z_*, y).
\]
这是因为
\[\begin{array}{ll}
\ell(z_K(x), y)
&= -\log \frac{\exp (z_y)}{\sum_j \exp(z_j)} \\
&= -\log \frac{1}{\sum_j \exp(z_j-z_y)} \\
&\le -\log \frac{1}{\sum_{j\not= y} \exp(\overline{z}_j-\underline{z}_y) + 1} \\
&\le -\log \frac{\exp(\underline{z}_y)}{\sum_{j\not =y} \exp(\overline{z}_j) + \exp(\underline{z}_y)} \\
&= \ell(z_*, y).
\end{array}
\]
故我们优化的是一个上界.
CROWN
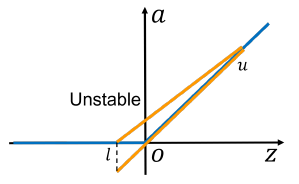
注: 此图来自[Lyu Z. et al. Towards Evaluating and Training Verifiably Robust Neural Networks].
CROWN的区别, 实际上就是其对激活函数的一个relaxation, 比如
\[\underline{x} \le x \le \overline{x} \Rightarrow \\
ax\le \mathrm{ReLU}(x) \le \frac{\overline{x}}{\overline{x} - \underline{x}} \cdot x
-\frac{\overline{x}\underline{x}}{\overline{x} - \underline{x}}.
\]
其中\(a \in [0, 1]\).
这个界可视化就是上面的图.
注: 作者说是要back propagation, 但是感觉forward也可以...
CROWN-IBP
上面二者的结合, 假设由上面二者分别推导出两个界, 并得到
\[z_*, z_*',
\]
相应的损失函数为
\[\mathcal{L} = \kappa \cdot \ell (z_K, y) + (1 - \kappa) \cdot \ell(\beta \cdot z_* + (1 - \beta) \cdot z_*', y).
\]
这么做的原因是, 作者认为IBP在最开始的时候估计的界是非常loose的, 所以一开始的训练是很不稳定的, 故采取了这么一个折中的方案.
训练的技巧
- \(\kappa\) 从\(\kappa_{start}\)线性下降到\(\kappa_{end}\), 即训练开始先着重于clean的部分;
- \(\beta\) 同样从\(0\)增大至\(1\)(ramp-up).
- \(\epsilon\)则是从0慢慢增大(ramp-up), 且如果我们测试关系的是\(8/255\), 训练的时候实际增大到\(8.8/255\), 即\(1.1\epsilon\), 原因是发现IBP的方法对于\(\epsilon\)比较小的情况的效果不是特别好和稳定;
写在最后
首先, 这些理论的保证并没有太好的效果, 和经验的方法依旧差距甚远, 个人觉得有趣的地方在于, 网络在不接触对抗训练的基础上依然能够获得鲁棒性.
另外, IBP的估计的界虽然远不及一些别的方法包括CROWN, 但是其表现出来的效果却好上很多, 这是非常有意思的一点.
虽然这一点在深度学习里头似乎也是比较常见的现象.

