Counterfactual VQA: A Cause-Effect Look at Language Bias
概
利用因果分析消除VQA(Visual Question Answering (VQA))中的language bias.
主要内容
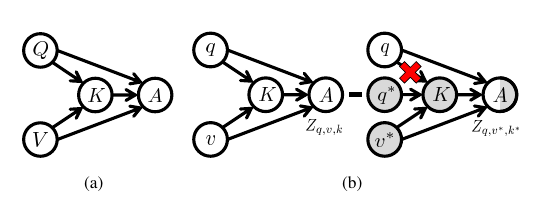
如上图所示,
\(Q\): question;
\(V\): image;
\(K\): multi-modal knowledge;
\(A\): answer.
影响最后决策\(A\)有三种:
- \(Q \rightarrow A\), 直接受question影响, 比如模型对于所有的问图中的香蕉是什么颜色的问题均回答"黄色", 显然是不考虑图片的影响(因为可能是绿色), 这种实际上就是language bias;
- \(V \rightarrow A\), 直接受图片影响;
- \(V, Q \rightarrow K \rightarrow A\), 这里有一个mediator K, 即部分影响兼顾了\(Q, V\).
理想的VQA模型应该舍弃1中的影响, 在因果分析里头, 这部分direct effect被称之为natural direct effect (pure direct effect实际上):
余下的是TIE (total indirect effect):
作者的思路是在inference的时候找到一个\(a\), 最大化TIE.
需要说明的是:
这条件成立的原因单纯是因为作者的假设中并没有confounder, 实际上个人认为应当加一个\(V \rightarrow A\)的 arrow, 虽然这个并不影响上面的结论.
然后作者计算TIE也并不是针对\(A\), 而是\(A\)的score, \(Z=Z(Q=q, V=v, K=k)\).
实现
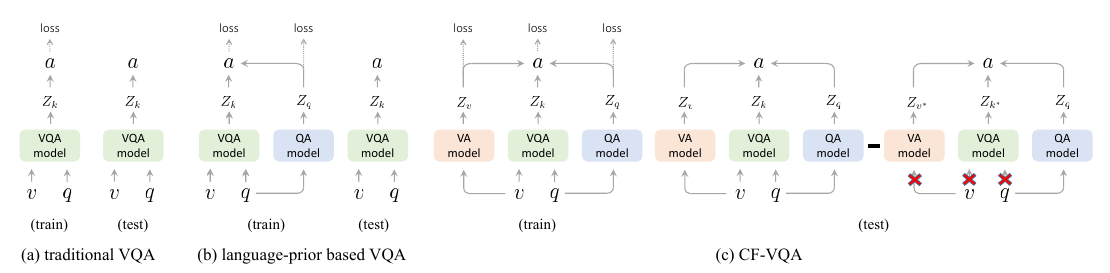
不同以往, 这一次可以显示地设置\(v^*, k^*\)了:
特别的, 在\(q^*, v^*, k^*\)的情况下, 作者采取了如下的策略:
这里\(c\)为可学习的变量.
注: 作者在代码中给出, \(c\)为一scalar, 也就是说实际上是:
作者也在文中指出, 这是为了一个Uniform的假设.
注: 看起来, 似乎应该对不同的\(Z_*\)指定不同的\(c\), 但是实际上, 是不影响的. 这一点是因为在下面HM和SUM的处理方式中, 无论是\(c_1\cdot c_2\cdot c_3\)
还是\(c_1 + c_2 + c_3\)都等价于\(c\) (这里要感谢作者的答复).
有了上面的准备, 下面是\(h\)的构造, 因为我们需要把不同的特征融合起来, 作者给出了两种方案:
- Harmonic (HM):
- SUM:
在训练的时候, 用的是如下的损失:
以及, 为了训练\(c\)(且仅用于训练c),
其中\(p(a|q,v,k)=softmax(Z_{q,v, k})\).
虽然感觉可以直接通过最大化TIE来训练c比较合理, 但是正如作者在附录中给出的解释一下, 这种情况明显会导致\(c \rightarrow 0\)并导致\(Z_{q, v^*, k^*}\rightarrow -\infty\).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号