Hern\'an M. and Robins J. Causal Inference: What If.
Neal B. Introduction to Causal Inference.
这里对常用的causal effect的估计方法做一个总结, 需要注意的是, 在参数模型的情况下θL 表示θTL当二者为向量的时候.
为了方便, 我们常常使用∑, 这并非要求该项必须是离散的, 除了A大部分可以等价于∫.
默认情况下, (条件)可交换性(exchangeability), 一致性(consistency) 以及 正性(positivity) 都是满足的, 特别的情况为注明.
其中, time-varying的条件可交换性定义为:
(Yg,L––gk+1)⨿Ak|¯Ak−1=g(¯Ak−2,¯Lk−1),¯Lk,k=0,⋯,K.
如果是静态的, g换成¯a.
Censoring 是数据缺失的情况, 对其的处理可以理解为对多个treatments的情况的处理.
Standardization
非参数情况
E[Ya]=E[Ya|A=a]=E[Y|A=a].
E[Ya]=ELEYa[Ya|L]=ELEY[Y|A=a,L].(S)
具体地, 为
∑lE[Y|A=a,L=l]Pr[L=l],(S+)
所以该式必须满足正性, 即
Pr[A=a|L=l]>0,ifPr[L=l]>0,
否则E[Y|A=a,L=l]无定义.
Censoring
E[Ya,c=0]=ELE[Y|A=a,C=0,L].
参数模型
标准化处理的参数模型, 就是估计
^E[Y|A=a,L=l],
比如:
^E[Y|A,L]=θ0+θ1A+θ2L+θ3AL.
接下来用(S, S+)的公式就可以了(一般是直接用S, 根据大数定律弄的).
Time-varying
静态
∑¯lKE[Y|¯AK=¯aK,¯LK=¯lK]∏Kk=0f(lk|¯ak−1,¯lk−1)=∑¯lKE[Y|¯AK−1=¯aK−1,¯LK=¯lK]∏Kk=0f(lk|¯ak−1,¯lk−1)=∑¯lKE[Y,¯AK−1=¯aK−1,¯LK=¯lK]∏K−1k=0f(lk|¯ak−1,¯lk−1)⋅f(¯ak−1,¯lk−1)=∑¯lKE[Y|¯AK−1=¯aK−1,¯LK=¯lK−1]∏K−1k=0f(lk|¯ak−1,¯lk−1)=⋯=E[Y¯a].
至于动态的, 书上给出了一个公式, 但是我感觉不是很对, 这里推导一下试试:
E[Yg]=E¯a∼gEY[Y¯a]=∑¯a∼g∑¯lE[Y¯a|¯A=¯a,L=¯l]⋅f(¯A,¯L),
其中
Pr(¯A,¯L)=K∏k=0f(Lk|¯Ak−1,¯Lk−1)⋅K∏k=0fint(Ak|¯Ak−1,¯Lk).
这里, fint表示每一步g的根据前面历史选择Ak的概率.
IP weighting
无参数
E[I(A=a)Yf(A|L)]=EL{EY[Ya|L]⋅EA[I(A=a)f(A|L)|L]=1}=E[Ya].
倘若A为连续变量, f为对应的条件密度函数, 则(非零的部分是零测集)
E[I(A=a)Yf(A|L)]≡0.
当正性不成立的时候, 即存在l, Pr[L=l]>0, 但是f(A=0|L=l)=0, 此时
E[I(A=a)Yf(A|L)]=EL∈Q(a){E[Ya|L=l]⋅EA[I(A=a)f(A|L)|L]}=EL∈Q(a){E[Ya|L=l]}=E[Ya|L∈Q(a)]Pr[L∈Q(a)].
Censoring
E[Ya,c=0]=E[I(A=a,C=0)Yaf(A|L)f(C|A,L)].
参数模型
定义
WA=f(A|L),
需要说明的是
E[Ya]=E[I(A=a)WAY]E[I(A=a)WA].(IP)
注: 实际上分母为1.
特别的, 可以定义
SWA=f(A)/f(A|L),
E[Ya]=E[I(A=a)SWAY]E[I(A=a)SWA].(IP+)
注: 此时分母为f(A). 在估计中, (IP+)更为稳定.
显然, 在参数模型中, 我们常常需要建模:
^f(A|L),
并得到
ˆWAorˆSWA.
此时再进一步假设
^E[Ya],
比如
^E[Ya]:=θ0+θ1a.
通过ˆW或者ˆSW得到E[Ya]的近似值:
∑iI(A=a)WiYi∑iI(A=a)Wi,or∑iI(A=a)SWiYi∑iI(A=a)SWi.
通过最小二乘法来估计参数θ0,θ1.
注: 一般情况下(A低维的情况), f(A)可以通过无参数估计估计, 否则也需要建模估计.
IP weighting 有一种特别好的思路, 主要到, 经过weighting之后, 相当于我们重新选择了A, 此时A和L无关, 在这个伪造的人群中, 我们有
Eps[Y|A=a]=E[Ya].
注: 证明只需要用到A⨿L.
注: 在这种可建模的情况下, 正性并不重要, 而且似乎即使A是连续变量, 上述的估计方式也是奏效的, 但是说实话我无法理解.
censoring
如果由censoring的情况出现, 只需要考虑
WAC=WA⋅WC,SWAC=SWA⋅SWC,
其中
WC=1/f(C|A,L),SWC=f(C|A)/f(C|A,L).
条件下 V
如何用IP weighting 估计
E[Ya|V],V⊂L.
只需考虑
WA=1/f(A|V,L∖V),SWA=f(A|V)/f(A,V,L∖V).
分别利用(IP, IP+)即可.
注: 此时二者分母均不为1, 故不可用最普通的IP weighting的公式.
Time-varying
此时
W¯A=K∏k=01f(Ak|¯Ak−1,¯Lk),SW¯A=K∏k=0f(Ak|¯Ak−1)f(Ak|¯Ak−1,¯Lk).
剩下的就是利用类似(IP, IP+)的公式计算.
在这种情况下, 同样有条件下V, 但是, 特别的是, V必须是baseline variables, 即
V⊂L0.
注: 没看到其用于动态策略的是说明.
G-estimation
非参数模型
非参数模型可以看成是参数模型的一种特例.
参数模型
这个方法主要是用于估计
E[Ya|L]−E[Ya′|L].
假设
^E[Ya|L]=β0+β1a+β2L+θ3aL,
则
E[Ya|L]−E[Ya=0|L]=β1a+β3aV.
假设 rank preserving 成立, 则有
Ya=Ya=0+ψ0a+ψ1aV,⇒Ya=0=Y−ψ0a−ψ1aV,
并定义H(ψ†):=Ya=0.
注意到, 条件可交换性
Ya⨿A|L
意味着
Pr[A=1|Ya=0,L]=Pr[A=1|L].
假设我们用一个逻辑斯蒂回归对其进行建模:
logitPr[A=1|Ya=0,L]=θ0+θ1Ya=0+θ2Ya=0V+θ3L.
则根据条件可交换性的性质, θ1,θ2都应该是0, 现在H(ψ†)=Ya=0, 则
logitPr[A=1|H(ψ†),L]=θ0+θ1H(ψ†)+θ2H(ψ†)V+θ3L.
给定ψ0,ψ1, 我们可以估计出一组θ0,⋯,θ3, 什么样的ψ0,ψ1是好的, 就是让估计的参数θ1,θ2接近0.
所以 G-estimation 常用网格法来估计.
不过应对高维问题的时候就比较捉襟见肘了.
在特殊的情况下, 我们可以有显示的表达式.
Time-varying
类似.
^E[Y¯ak−1,ak,0–k+1−Y¯ak+1,0–k|¯Ak−1=¯ak−1,¯Lk=¯lk]=akγk(¯ak−1¯lk;β).
Y¯Ak−1,Ak,0–k+1=Y¯Ak+1,0–k+Akγk(¯Ak−1,¯lk;β).
Hk(ψ†)=Y−K∑j=kAjγj(¯Aj−1,¯Lj,ψ†).
通过下式来估计:
logitPr[Ak=1|Hk(ψ†),¯Lk,¯Ak−1]=α0+α1Hk(ψ†)+α2Wk.
Propensity Scores
该方法仅能应用于二元情形, 即A∈{0,1}.
当L是一个高维向量的时候, 一般的无参数模型就派不上用场了, 尽管我们可以通过参数模型来建模, 但是带来的结果是估计结果的方差会比较大.
我们记π(L)=Pr[A|L], 并证明:
Ya⨿A|L⇒Ya⨿A|π(L).
不妨假设π(L)=s⇔L∈{li}, 则
Pr[Ya|π(L)=s]=Pr[Ya|L∈{li}]=∑iPr[Ya,L=li]∑iPr[L=li]=∑iPr[Y|A=a,L=li]Pr[L=li]∑iPr[L=li]=Pr[A=a|L=l]⋅∑iPr[Y|A=a,L=li]Pr[L=li]Pr[A=a|L=l]∑iPr[L=li]=∑iPr[Y|A=a,L=li]Pr[A=a,L=li]∑iPr[A=a,L=li]=∑iPr[Y,A=a,L=li]∑iPr[A=a,L=li]=Pr[Y,A=a,π(L)=s]Pr[A=a,π(L)]=Pr[Y|A=a,π(L)=s].
注意: π(li)=π(lj)=π(l)=s.
可见, 上述推导仅在A为二元变量是成立, 否则
Pr[A=1|l]=Pr[A=1|l′]⇏Pr[A=a′|l]=Pr[A=a′|l′].
也就无法保证上面的推导证明对于所有的A=a成立.
此时, 我们可以扩展causal graph为:
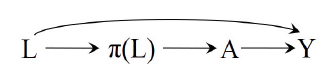
故, 我们可以通过π(L)来block以保证条件可交换性.
剩下的工作就是利用前面的方法了.
Instrumental Variables
instrumental variables 满足:
- Z 对 T 有 causal effect;
- Z 到 Y 的 causal effect 均通过 T, 即 T 是 Z 到 Y 所有 direct path 上的mediator;
- Z 和 Y 之间不存在backdoor path.
Binary Linear Setting
CAG图如上图所示.
Y:=δT+αU.
E[Y|Z=1]−E[Y|Z=0]=E[δT+αU|Z=1]−E[δT+αU|Z=0]=δE[[T|Z=1]−[T|Z=0]]+αE[[U|Z=1]−[U|Z=0]]=δE[[T|Z=1]−[T|Z=0]]
故
δ=E[Y|Z=1]−E[Y|Z=0]E[T|Z=1]−E[T|Z=0].
注: 在此CAG图中, U⨿Z.
Continuous Linear Setting
依旧是如上的CAG图.
Cov(Y,Z)=E[YZ]−E[Y]E[Z]=δ(E[TZ]−E[T]E[Z])+α(E[UZ]−E[U]E[Z])=δCov(T,Z)+αCov(U,Z)=δCov(T,Z)
故
δ=Cov(Y,Z)Cov(T,Z).
注: 依然用到了U⨿Z.
Nonparametric Identification
仅考虑单个的二元变量T∈{0,1}, 有如下几种情况:
- Compliers: Tz=1=1,Tz=0=0.
- Always-takers: Tz=1=1,Tz=0=1.
- Never-takers: Tz=1=0,Tz=0=0.
- Defiers: Tz=1=0,Tz=0=1.
当我们所考虑的群体中仅包括前三种类型的时候, 显然有:
Tz=1i≥Tz=0i.
这是我们需要的单调性假设.
此时:
E[Yt=1−Yt=0|Tz=1=1,Tz=0=0]=E[Y|Z=1]−E[Y|Z=0]E[T|Z=1]−E[T|Z=0].
即, 在compliers (遵照医嘱的) 的人群中, 可以计算出其causal effect.
证明在[2]的p93.
Difference in Difference
difference in difference 同样是处理存在unobservable变量时的一种有效的处理方法.
我们可以把Ya拆成俩个阶段:
- t=0, 此时决定A, 但是并没有落实A;
- t=1, 实行A.
凭借下面的假设:
1.
∀t,A=a⇒Yt=Yat.
- A=1, A=0两个群体若都不施加治疗, 则结果一致:
E[Y01−Y00|A=1]=E[Y01−Y00|A=0],
- 治疗前的状态一致:
E[Y10−Y00|A=1]=0.
注: 上面的第二条假设可能不容易满足.
则:
E[Y11−Y01|A=1]=(E[Y1|A=1]−E[Y0|A=1])−(E[Y1|A=0]−E[Y0|A=0]).
Doubly Robust Estimator
未完待续
Instrumental variable estimation
未完待续
Stratification
未完待续
Matching
未完待续



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix