BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
目录
概
数据的长短尾效应是当前比较棘手的问题, 本文提出用分支网络来应对这一问题, 并取得了不错的结果.
主要内容
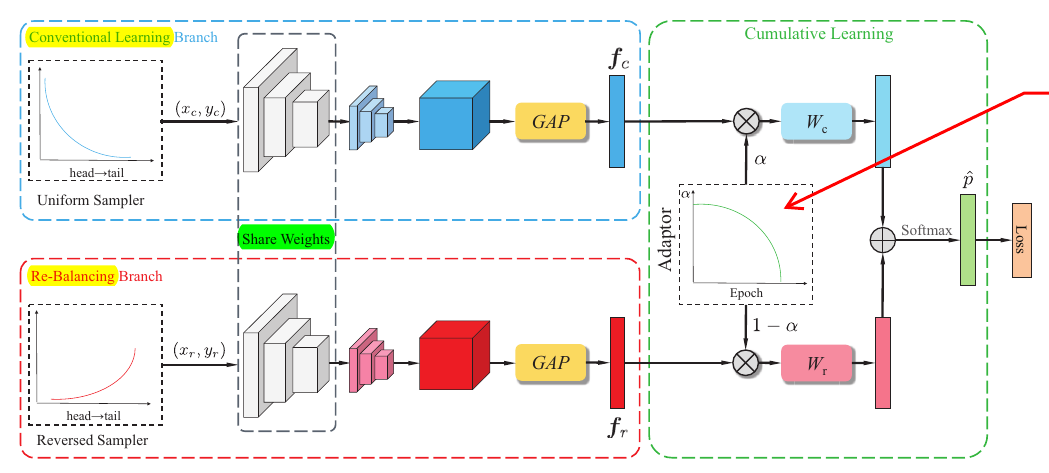
这篇文章的创新点是用两个分支来适应数据的不平衡.
如图所示, 上面的分支用于标准的训练, 而下面的分支则采用适合不平衡数据的训练方式: 即一般的训练是均匀的采样分布, 而非标准训练采用的是一个非均匀的依赖于样本分布的.
通过均匀采样得到\((x_c, y_c)\), 通过非均匀采样得到\((x_r, y_r)\), 分别喂入上下分支得到特征表示\(f_c\)和\(f_r\).
注意到, 上下两个分支是共享部分参数的, 作者实际选择的是残差网络, 设定为除了最后一个residual block外均是共享的.
根据\(f_c\)和\(f_r\)进一步得到
\[z = \alpha W^T_c f_c + (1-\alpha) W_r^T f_r,
\]
即\([z_1, z_2,\cdots, z_C]^T\).
得到相应的概率向量
\[\hat{p}_i = \frac{e^{z_i}}{\sum_{i=1}^{C}e^{z_j}}.
\]
最后通过下列损失函数进行训练
\[\mathcal{L} = \alpha E(\hat{p}, y_c) + (1-\alpha)E(\hat{p}, y_r).
\]
实际上, \(\alpha\)就是一个调整标准训练和处理不平衡数据的权重.
采样方式
对于非均匀分布, 作者采取了如下方式构造采样分布, 假设每个类的样本数目为\(N_i, i=1,2,\ldots,C\). 则采样比例为
\[P_i = \frac{w_i}{\sum_{j=1}^C w_j},
\]
其中\(w_i=\frac{1}{N_i}\).
权重\(\alpha\)
作者采用的是这样的一种方案
\[\alpha = 1 - (\frac{T}{T_{max}})^2,
\]
其中\(T\)为当前的epoch, \(T_{max}\)为总的训练epochs.
在实际测试中, 作者也尝试了一些别的方案, 不过别的方案不如此方案理想.
直观上的解释就是, 训练过程会有普通的训练渐渐偏向re-balance的训练.
Inference phase
在推断过程中, 设定\(\alpha=0.5\).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号