Jae Hyun Lim, Jong Chul Ye, Geometric GAN.
概
很有趣, GAN的训练过程可以分成
- 寻找一个超平面区分real和fake;
- 训练判别器, 使得real和fake分得更开;
- 训练生成器, 使得real趋向错分一侧.
主要内容
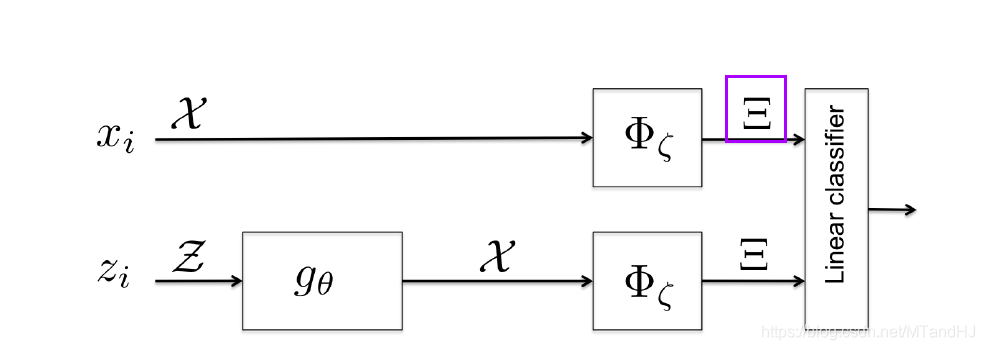
McGAN
本文启发自McGAN, 在此基础上, 有了下文.
结合SVM
设想, GAN的判别器D(x)=S(⟨w,Φζ(x)⟩), 其中S是一个激活函数, 常见如sigmoid, 先假设其为identity(即D(x)=⟨w,Φζ(x)⟩).
McGAN 是借助⟨w,Φζ(x)⟩来构建IPM, 并通过此来训练GAN. 但是,注意到, 若将Φζ(x)视作从x中提取出来的特征, 则⟨w,Φζ(x)⟩便是利用线性分类器进行分类,那么很自然地可以将SVM引入其中(训练判别器的过程.
minw,b12∥w∥2+C∑i(ξi+ξ′i)subjectto⟨w,Φζ(xi)⟩+b≥1−ξii=1,…,n⟨w,Φζ(gθ(zi))⟩+b≤ξ′i−1i=1,…,nξi,ξ′i≥0,i=1,…,n.
类似于
minw,bRθ(w,b;ζ),(13)
其中
Rθ(w,b;ζ)=12Cn∥w∥2+1n∑ni=1max(0,1−⟨w,Φζ(xi)⟩−b)+1n∑ni=1max(0,1+⟨w,Φζ(gθ(zi))⟩+b).(14)
进一步地, 用以训练ζ:
minw,b,ζRθ(w,b;ζ).(15)
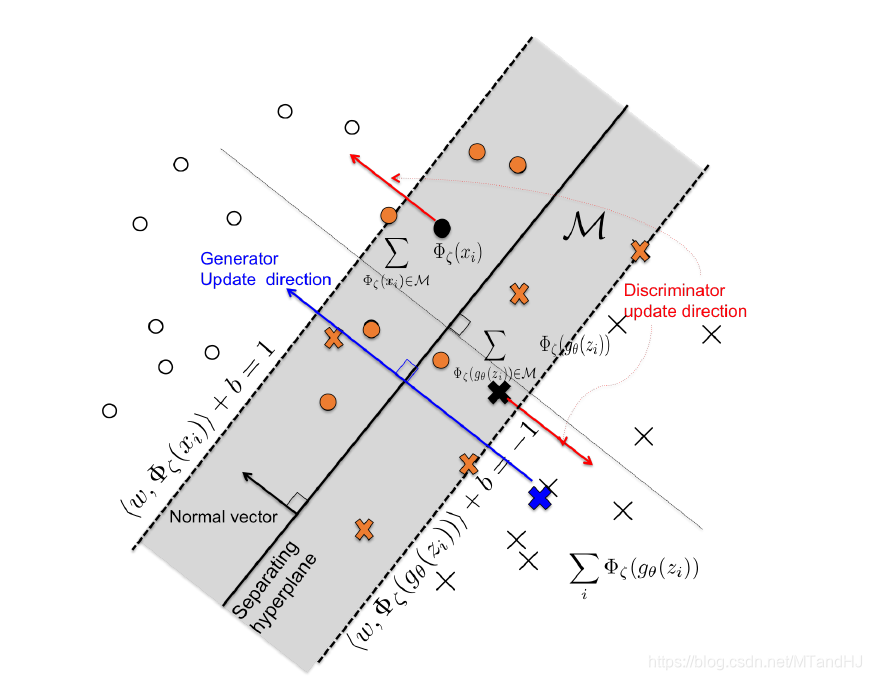
SVM关于w有如下最优解
wSVM:=n∑i=1αiΦζ(xi)−n∑i=1βiΦζ(gθ(zi)),
其中αi,βi只有对支持向量非零.
定义
M={ϕ∈Ξ||⟨wSVM,ϕ⟩+b|≤1}
为margin上及其内部区域的点.
于是
Rθ(w,b;ζ)=1n∑ni=1⟨wSVM,siΦζ(gθ(zi))−tiΦζ(xi)⟩+constant,(18)
其中
ti={1,Φζ(xi)∈M0,otherwise,si={1,Φζ(gθ(zi))∈M0,otherwise.(19)
训练ζ
于是ζ由此来训练
ζ←ζ+η1nn∑i=1⟨wSVM,ti∇ζΦζ(xi)−si∇ζΦζ(gθ(zi))⟩.
训练gθ
就是固定w,b,ζ训练θ.
所以
minθLw,b,ζ(θ),
其中
Lw,b,ζ(θ)=−1nn∑i=1D(gθ(zi)),
的
θ←θ+η1nn∑i=1⟨wSVM,si∇θΦζ(gθ(zi))⟩.
理论分析
n→∞的时候
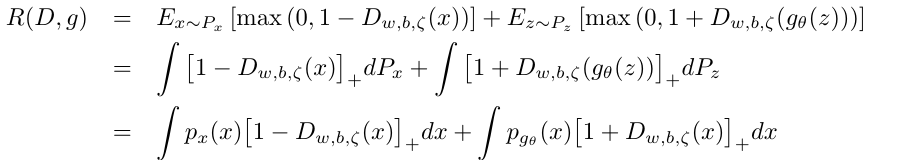
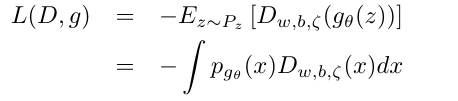
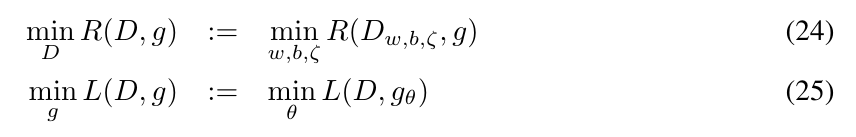
定理1: 假设(D∗,g∗)是(24), (25)交替最小化解, 则pg∗(x)=px(x)几乎处处成立, 此时R(D∗,G∗)=2.
注: 假体最小化是指在固定g∗下, R(D∗,g∗)最小,在固定D∗下L(D∗,g∗)最小.
证明



注:文中附录分析了各种GAN的超平面分割解释, 挺有意思的.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix