Proximal Algorithms 7 Examples and Applications
本节介绍一些例子.
LASSO
考虑如下问题:
其中\(x \in \mathbb{R}^n, A \in \mathbb{R}^{m\times n }\).
proximal gradient method
proximal gradient method 是:
令\(f(x)=(1/2)\|Ax-b\|_2^2, g(x)=\gamma \|x\|_1\), 则
其中\(S_{\gamma}(x)\)是soft-thresholding.
ADMM
很自然的方法,不提了.
矩阵分解
一般的矩阵分解问题如下:
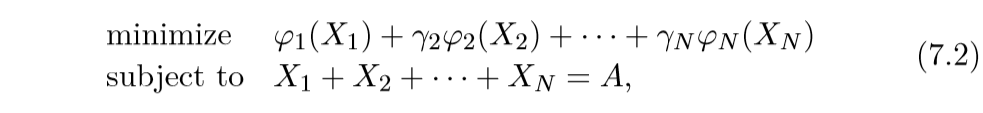
其中\(X_1, \ldots, X_N \in \mathbb{R}^{m\times n}\)为变量,而\(A \in \mathbb{R}^{m\times n }\)为数据矩阵.
不同的惩罚项\(\varphi\)会带来不同的效果.
- \(\varphi(X)=\|X\|_F^2\), 这时,矩阵元素往往都比较接近且小
- \(\varphi(X)=\|X\|_1\), 这会导致稀疏化
- \(\varphi(X) = \sum_j \|x_j\|_2\), 其中\(x_j\)是\(X\)的第\(j\)列, 这会导致列稀疏?
其他的看文章吧.
ADMM算法
令
其中\(X = (X_1, \ldots, X_N)\), 并且:
根据之前的分析,容易知道:
其中\(\bar{X}\)是\(X_1, \ldots, X_N\)的各元素的平均.
最后算法总结为:
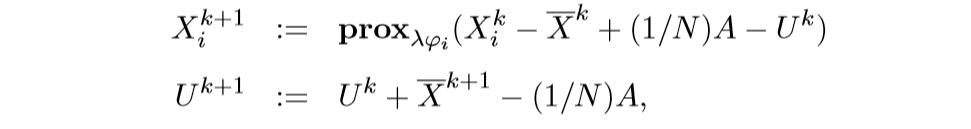
多时期股票交易
其问题是:
其中\(x_t, t=1,\ldots, T\)表示第\(t\)个时期所保持的股份,期权,而\(f_t\)则表示对应的风险,\(g_t\)表示第\(t\)个时期交易所需要耗费的资源.
考虑如下分割:
其中\(X=[x_1, \ldots, x_T]\in\mathbb{R}^{n \times T}\).
随机最优
为如下问题:
其中\(\pi \in \mathbb{R}_+^K\)是一个概率分布,满足\(1^T\pi=1\).
利用第5节的知识,将此问题化为:
再利用ADMM就可以了.
Robust and risk-averse optimization
鲁棒最优,特别的, 最小化最大风险:
更一般的:
其中\(\varphi\)为非降凸函数.
method
将上面的问题转化为:
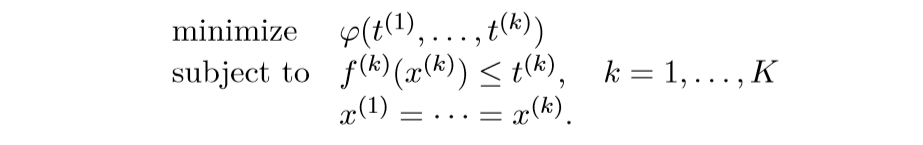
将
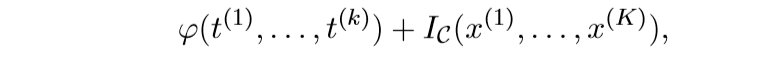
视作\(f\)
而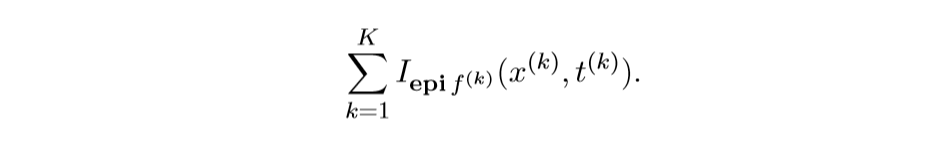
作为\(g\),再利用ADMM求解即可.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号