Proximal Algorithms
这一节介绍了一些利用proximal的算法.
Proximal minimization
这个相当的简单, 之前也提过,就是一个依赖不动点的迭代方法:
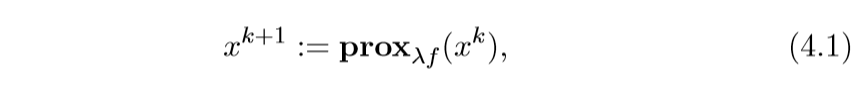
有些时候λ不是固定的:
xk+1:=proxλkf(xk),∞∑k=1λk=∞
import numpy as np
import matplotlib.pyplot as plt
以f(x,y)=x2+50y为例
f = lambda x: x[0] ** 2 + 50 * x[1] ** 2
x = np.linspace(-40, 40, 1000)
y = np.linspace(-20, 20, 500)
X, Y = np.meshgrid(x, y)
fig, ax = plt.subplots()
ax.contour(X, Y, f([X, Y]), colors="black")
plt.show()

求解proximal可得:
x=v12λ+1y=v2100λ+1
def prox(v1, v2, lam):
x = v1 / (2 * lam + 1)
y = v2 / (100 * lam + 1)
return x, y
times = 50
x = 30
y = 15
lam = 0.1
process = [(x, y)]
for i in range(times):
x, y = prox(x, y, 0.1)
process.append((x, y))
process = np.array(process)
x = np.linspace(-40, 40, 1000)
y = np.linspace(-20, 20, 500)
X, Y = np.meshgrid(x, y)
fig, ax = plt.subplots()
ax.contour(X, Y, f([X, Y]), colors="black")
ax.scatter(process[:, 0], process[:, 1])
ax.plot(process[:, 0], process[:, 1])
plt.show()

解释
除了之前已经提到过的一些解释:
Gradient flow
考虑下面的微分方程:
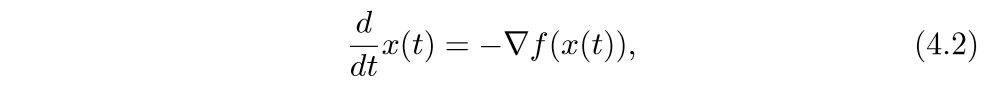
t→∞时f(x(t))→p∗,其中p∗是最小值.
我们来看其离散的情形:
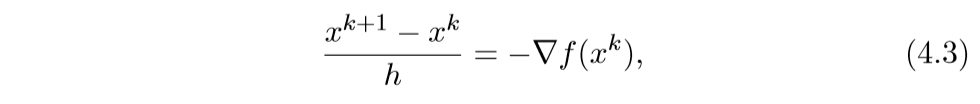
于是就有:
xk+1:=xk−h∇f(xk)
还有一种后退的形式:
xk+1−xkh=−∇f(xk+1)
此时,为了找到xk+1, 我们需要求解一个方程:
xk+1+h∇f(xk+1)=xk⇒xk+1=(I+h∇f)−1xk=proxhf(xk)
还有一种特殊的解释,这里不提了.
f(x)+g(x)
考虑下面的问题:
minimizef(x)+g(x)
其中f是可微的.
我们可以通过下列proximal gradient method来求解:
xk+1:=proxλkg(xk−λk∇f(xk))
可以证明(虽然我不会),当∇f Lipschitz连续,常数为L,那么,如果λk=λ∈(0,1/L],这个方法会以O(1/k)的速度收敛.
还有一些直线搜素算法:

一般取β=1/2,ˆfλ是f的一个上界,在后面的解释中在具体探讨.
解释1 最大最小算法
最大最小算法, 最小化函数φ:Rn→R:
xk+1:=argminxˆφ(x,xk)
其中ˆφ(⋅,xk)是φ的凸上界:ˆφ(x,xk)≥φ(x), ˆφ(x,x)=φ(x).
我们可以这么构造一个上界:
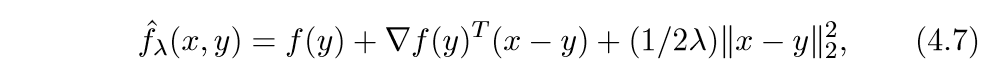
上面的式子很像泰勒二阶展开,首先这个函数符合第二个条件,下面我们证明,当λ∈(0,1/L],那么它也符合第一个条件.
ˆfλ(x)−f(x)=f(y)−f(x)+∇f(y)T(x−y)+...=(∇f(y)−∇f(z))(x−y)+...
其中z=x+θ(y−x),θ∈[0,1], 又Lipschitz连续,所以:
∥∇f(y)−∇f(z)∥≤L∥y−z∥≤L∥y−x∥
考虑f(x+tΔx)关于t的二阶泰勒展式:
f(x+tΔx)=f(x)+∇f(x)TΔxt+12ΔxT∇2f(x)Δxt2+o(t2)
令t=1:
f(x+Δx)=f(x)+∇f(x)TΔx+12ΔxT∇2f(x)Δx+...
∥∇f(x)−∇f(x+tΔx)∥t≤L∥Δx∥
由当t→0时,左边为∥∇2f(x)Δx∥, 所以∇2f(x)的最大特征值必小于L, 所以:
f(x+Δx)≤f(x)+∇f(x)TΔx+L2∥Δx∥22+...
完蛋,好像只能证明在局部成立,能证明在全局成立吗?
xk+1:=argminxˆfλ(x,xk)
再令:
qλ(x,y)=ˆfλ(x,y)+g(x)
那么:
xk+1:=argminxqλ(x,xk)=proxλg(xk−λ∇f(xk))
上面的等式,可以利用第二节中的性质推出.
不动点解释
最小化f(x)+g(x)的点x∗应当满足:
0∈∇f(x∗)+∂g(x∗)
更一般地:

这便说明了一种迭代方式.
Forward-backward 迭代解释
考虑下列微分方程系统:
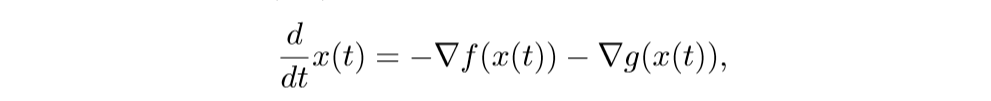
离散化后得:
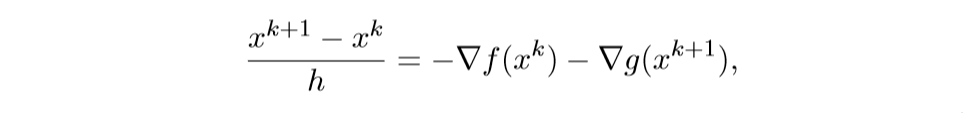
注意,等式右边xk和xk+1,这正是巧妙之处.
解此方程可得:
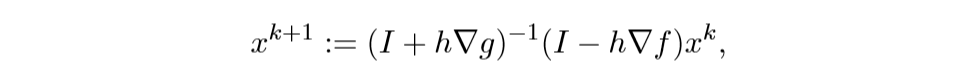
这就是之前的那个迭代方法.
加速 proximal gradient method
其迭代方式为:
yk+1:=xk+wk(xk−xk−1)xk+1:=proxλkg(yk+1−λk∇f(yk+1))
wk∈[0,1)
这个方法有点类似Momentum的感觉.
一个选择是:
wk=kk+3
也有类似的直线搜索算法:

交替方向方法 ADMM
alternating direction method of multipliers (ADMM), 怎么说呢,久闻大名,不过还没看过类似的文章.
同样是考虑这个问题:
minimizef(x)+g(x)
但是呢,这时f,g都不一定是可微的, ADMM采取的策略是:
xk+1:=proxλf(zk−uk)zk+1:=proxλg(xk+1+uk)uk+1:=uk+xk+1−zk+1
特殊的情况是, f或g是指示函数,不妨设f是闭凸集C的指示函数,而g是闭凸集D的指示函数, 即:
IC(x)=0,ifx∈C,else+∞
这个时候,更新公式变为:
xk+1:=ΠC(zk−uk)zk+1:=ΠC(xk+1+uk)uk+1:=uk+xk+1−zk+1
解释1 自动控制
可以这么理解,z为状态,而u为控制,前俩步时离散时间动态系统(不懂啊...), 第三步的目标是选择u使得x=z,所以xk+1−zk+1可以认为是一个信号误差,所以第三步就会把这些误差累计起来.
解释2 Augmented Largranians
我们可以将问题转化为:
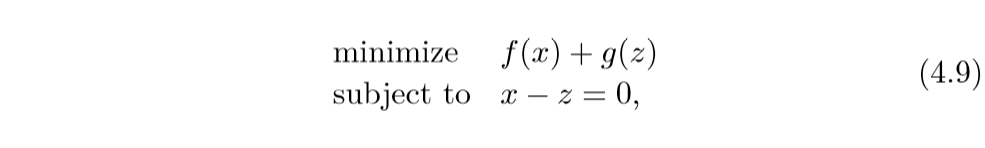
augmented Largranian:
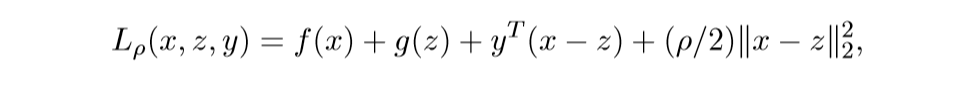
其中y为对偶变量.
在z,y已知的条件下,最小化L, 即:
xk+1:=argminxLρ(x,zk,yk)
在x,y已知的条件下,最小化L, 即:
zk+1:=argminzLρ(xk+1,z,yk)
最后一步:
yk+1:=yk+ρ(xk+1−zk+1)
如果依照对偶问题的知识,关于y应该是取最大,但是呢,关于y是一个仿射函数,所以没有最值,所以就简单地取那个?
注意到:


让uk=(1/ρ)yk, λ=1/ρ就是最开始的结果.
解释3 Flow interpretation
问题(4.9)的最优条件(KKT条件):
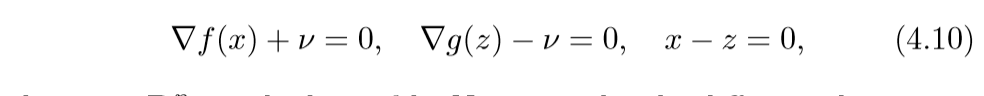
其中v是对偶变量.考虑微分方程:
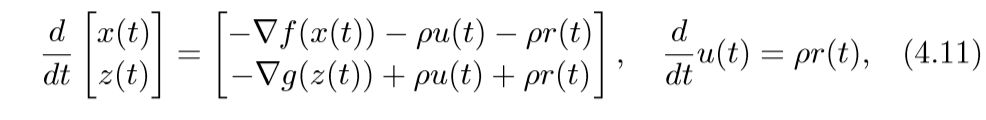
(4.11)取得稳定点的条件即为(4.10)(v=ρ)(这部分没怎么弄明白).
离散化情形为:

取h=λ,ρ=1/λ即可得ADMM.
解释4 不动点
原问题的最优条件为:
0∈∂f(x∗)+∂g(x∗)
ADMM的不动点满足:
x=proxλf(x−u),z=proxλg(x+u),u=u+x−z
从最后一个等式,我们可以知道:
x=z
, 于是
x=proxλf(x−u),x=proxλg(x+u)
等价于:
x=(I+∂f)−1(x−u),x=(I+λ∂g)−1(x+u)
等价于:
x−u∈x+λ∂f(x),x+u∈x+λ∂g(x)
俩个式子相加,说明x即为最优解.
再来说明一下,为什么可以相加,根据次梯度的定义:
λf(z)≥λf(x)+(−u)T(z−x),∀z∈domfλg(z)≥λg(x)+(+u)T(z−x),∀z∈domg
相加可得:
λf(z)+λg(z)≥2x+λf(x)+λg(x)+0
需要注意的是,我证明的时候也困扰了,
x−u∈x+λ∂f(x)
并不是指(x-u)是函数x2/2+λf(x)的次梯度, 而是x−u在λf(x)的次梯度集合加上x的集合内,也就是−u是其次梯度.
对不起!又想当然了,其实没问题, 如果
g∈∂f1(x)+h(x)
而∂f2(x)=h(x)则:
g∈∂(f1+f2)(x)
证:
已知:
f1(z)≥f1(x)+∂f1(x)T(z−x)f2(z)≥f2(x)+h(x)T(z−x)
俩式相加可得:
(f1+f2)(z)≥(f1+f2)(x)+(∂f1(x)+h(x))T(z−x)=(f1+f2)(x)+gT(z−x)
所以g∈∂(f1+f2)(x), 注意g=g(x)也是无妨的.
特别的情况 f(x)+g(Ax)
考虑下面的问题:
minimizef(x)+g(Ax)
上面的求解,也可以让˜g(x)=g(Ax),这样子就可以用普通的ADMM来求解了, 但是有更加简便的方法.
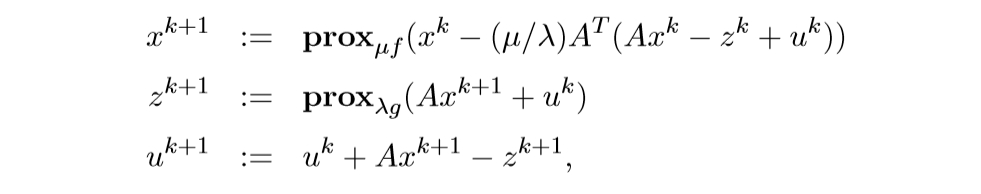
这个的来源为:

再利用和之前一样的推导,不过,我要存疑的一点是最后的替代,我觉得应该是:
ρ(ATAxk−ATzk)Tx+(1/2μ)∥x−xk∥22
否则推不出来啊.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix