神经网络一丢丢
@
终究有一天,还是得接触这个让人捉摸不透的东西。我总感觉他太过神秘,所以对他没有什么好感。无奈,他如此实用,不得不拜访一下。我不管什么CNN和RNN,这些花里胡哨的东西,我感觉就像边角料。
参考《Pattern Recongition》
源
神经网络,就其类别来讲是非线性判别,而非线性判别,主要是因为激活函数。输入层得到输入,经过线性函数(超平面)的分隔,输入的特征被映射为其他一些特征,如果激活函数是简单的0-1函数(虽然没法反向求导了)。就是那样本映射到超体(是这么形容吗?)的顶点上,再经过一层,网络,对上述点进行分隔,幸许就能把样本成功分类了。当然,这些都是简单的情况,而且,俩层神经网络的能力似乎并不够。

神经网络框架
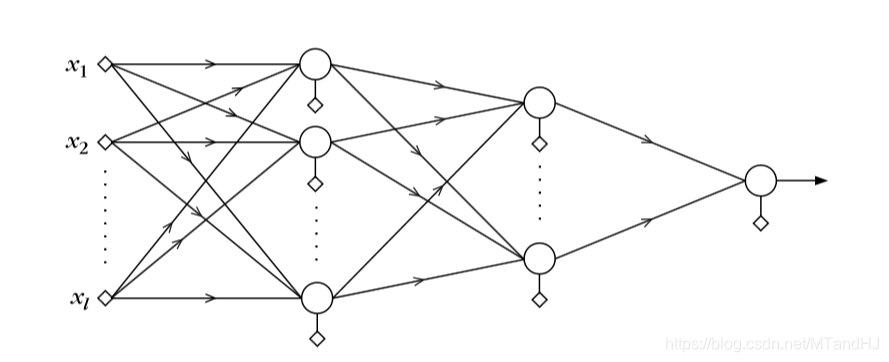
这是一个三层神经网络。
Backpropagation 反向传播
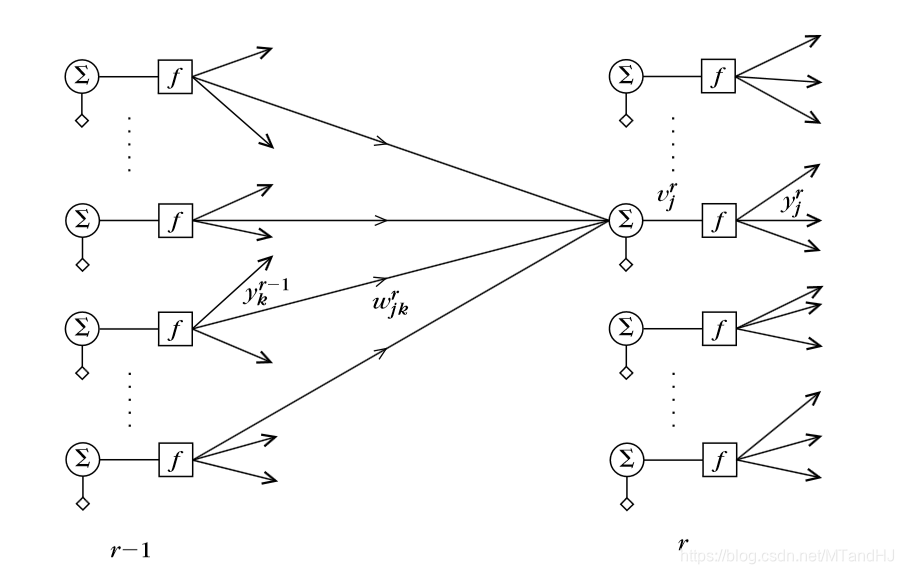
我不知道有没有别的什么神经网络不用这个算法的,我还没有太深入了解,但我感觉,神经网络最核心的东西就是反向传播,还有框架本身。
下面,过一遍这个梯度的计算。
符号说明
\(假定有L层神经元,输入层有k_0=l个结点(神经元),在第r层有k_r个结点,r=1,2,\ldots,L.\)
\(有N个训练样本,(x(i),y(i)),i=1,2,\ldots,N\)
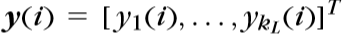
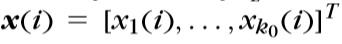
\(w_j^r表示第r层第j个结点\)
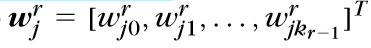
权重更新,按照普通的梯度下降为:
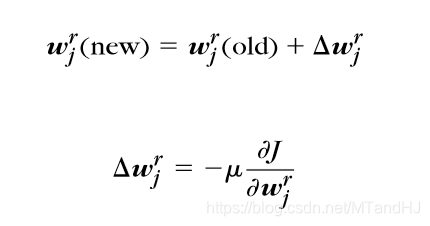
\(f(\cdot)为激活函数\)
损失函数(这里以最小平方误差为例)
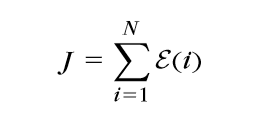
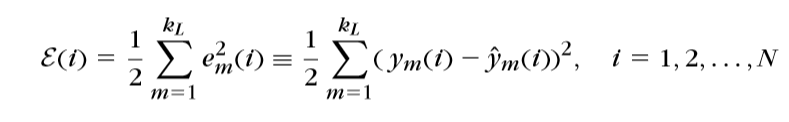
梯度计算 \(\Delta w_j^r=-\mu\mathop{\sum}\limits_{i=1}^{N}\delta_j^r(i)y^{r-1}(i)\)
\(首先,y_k^{r-1}(i),是第r-1层第k个结点的输出(激活后),相应的v_k^{r-1}为没有激活的输出。\)
\(而w_{jk}^r是连接r-1层第k个结点和r层第j个结点的权重。\)
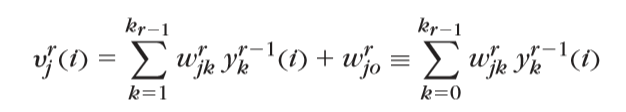
\(简便的写法就是v_j^r(i)=w_j^{t\mathrm{T}}y^{r-1}(i)\)
\(其中y_0^{r-1}(i)\equiv+1\)
\(那么损失函数关于w_j^r的导数(梯度)就是:\)
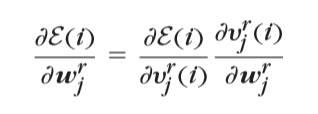
\(又\)

\(记\)
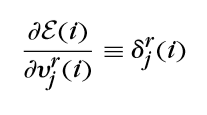
\(则:\)
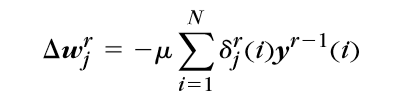
计算 \(\delta_j^r(i)\)
\(r=L\)
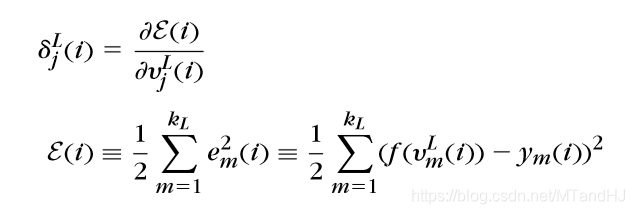
\(所以\)
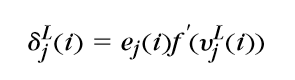
\(r < L\)
\(因为v_j^{r-1}(i)是第r层所有结点的输入,所以:\)
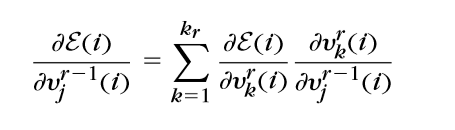
\(也就是\)
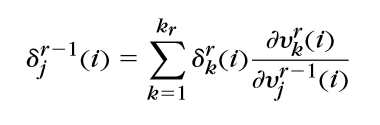
\(令\delta^{r}=[\delta_1^r,\delta_2^r,\ldots,\delta_{k_r}^r]^{\mathrm{T}},那么\)
\(\delta^{r-1}=M^r\delta^r其中M_{jk}^r=\frac{\partial v_k^r}{\partial v_j^{r-1}}又\)
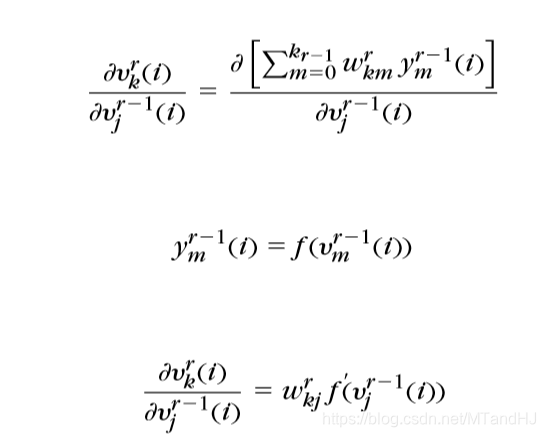
\(所以M_{jk}^r(i)=w_{kj}^r f^{'}(v_j^{r-1}(i))\)
\(所以,总的来说\)
\(\delta^r=M^{r+1}M^{r+2}\ldots M^{L}\delta^L\)
\(这意味着,对于第r层,我们只要记录w^r(old)和M^r就足够迭代更新了,而且计算M^r的工作可以在前向传递的时候完成,也可以在反向传播的时候再计算。\)
\(我想,这也是Pytorch等框架计算梯度的原理,当然这只是猜测,因为我还没有实际上去看。\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号