使用es作为日志系统的优化
增加索引刷新时间
创建表时指定排序字段
关闭评分计算
避免过多的shards及人工分片
经过多次测试,在机器数及配置不是特别好的情况下,过多的shard和日期分片会导致速度反而变慢,在500g数据的测试环境下,单索引反而是效果最好的,考虑到扩展性,目前打算使用月-appName进行分片
- 示例
PUT test2
{
"settings": {
"index": {
"sort.field": [
"dtTime",
"seq"
],
"sort.order": [
"desc",
"desc"
]
},
"number_of_shards": 10,
"number_of_replicas": 0,
"refresh_interval": "30s"
},
"mappings": {
"dynamic_templates": [
{
"test_float": {
"match_mapping_type": "string",
"mapping": {
"norms": "false"
}
}
}
],
"properties": {
"appName": {
"type": "keyword"
},
"env": {
"type": "keyword"
},
"appNameWithEnv": {
"type": "keyword"
},
"logLevel": {
"type": "keyword"
},
"serverName": {
"type": "keyword"
},
"traceId": {
"type": "keyword"
},
"dtTime": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
},
"seq": {
"type": "long"
}
}
}
}
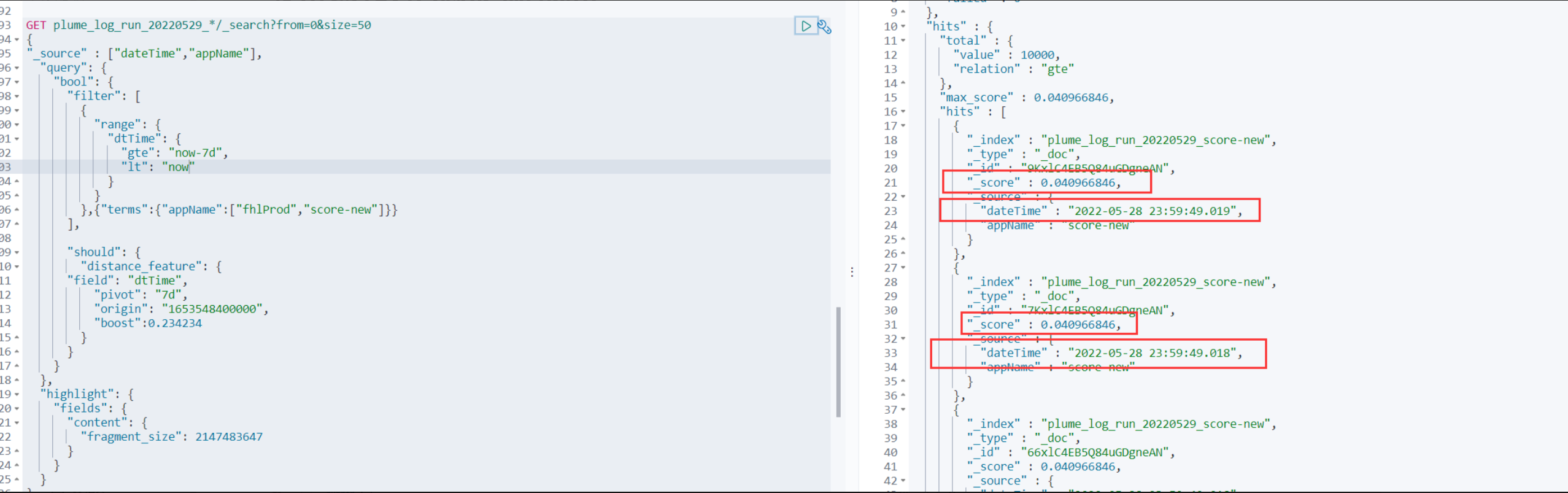
查询排序除了使用最原始的sort之外,还可以使用distance_feature依靠评分进行排序,但是实测在毫秒数接近的时候会导致评分一致,导致顺序异常,鉴于此,就不考虑这种优化了
试了下如果distance_feature和sort一起用,似乎没发生什么改变,理论上来说sort应该是优先级最高的,懒得研究了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号