机器学习概述
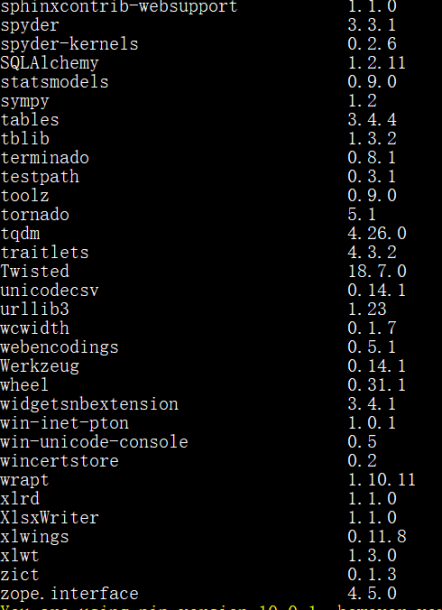
1、Python环境及pip list截图

2、学习笔记
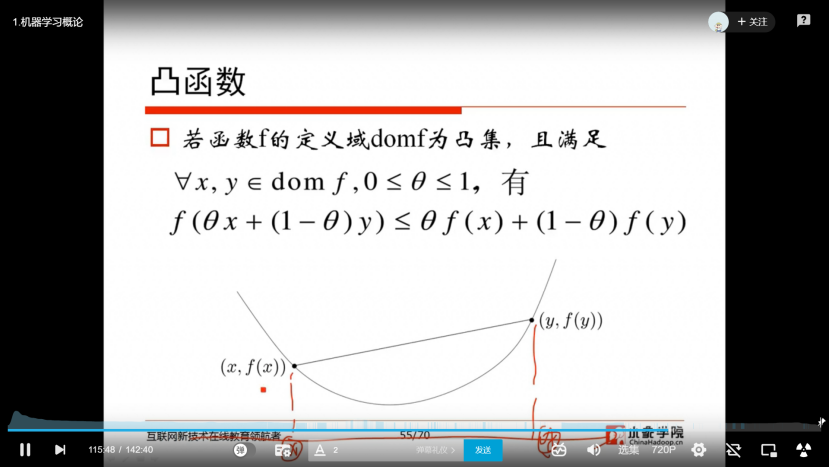
2.1 机器学习概论

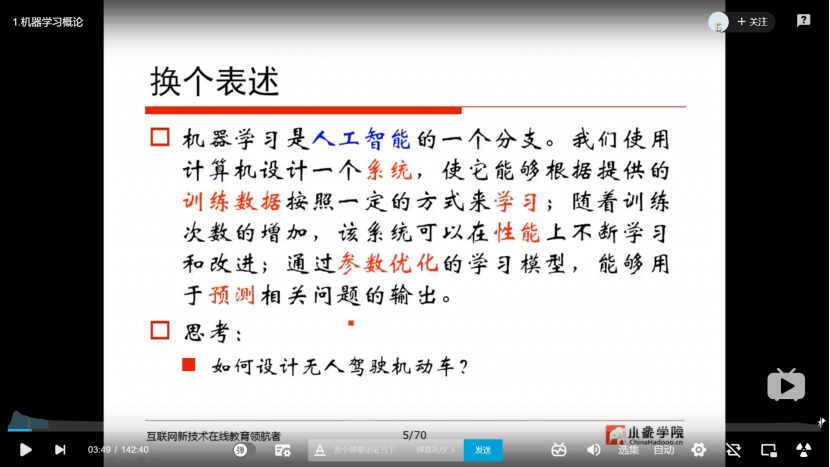
建模——预测
机器学习的一般流程:数据收集——数据请理——特征工程——数据建模
机器学习的方法:线性回归、EM算法、GMM与图像、图像的卷积、去均值ICA分离、带噪声的信号分离、SVM:高斯核函数的影响RBF、Crawler爬取数据、HMM分词:MLE、LDA
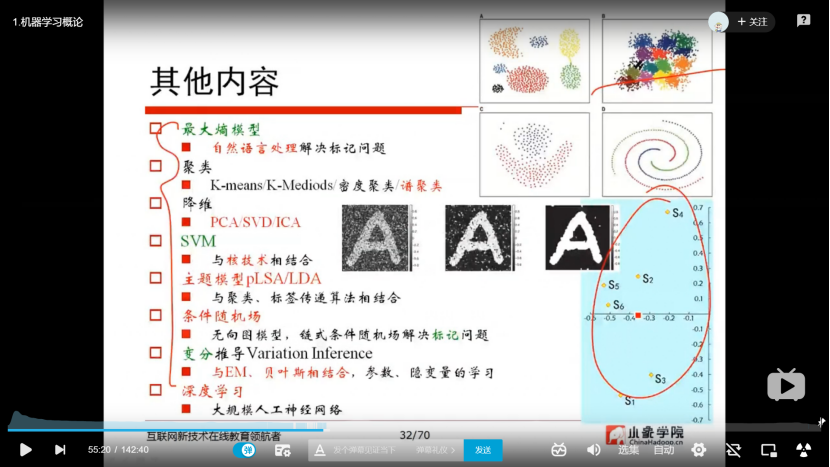




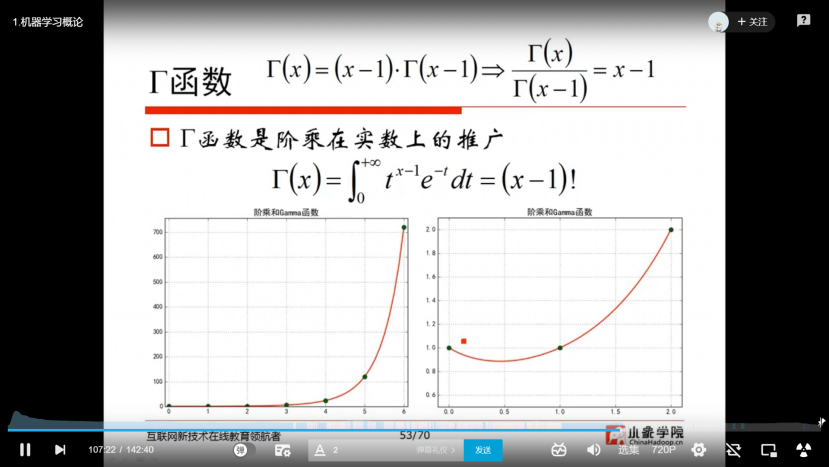

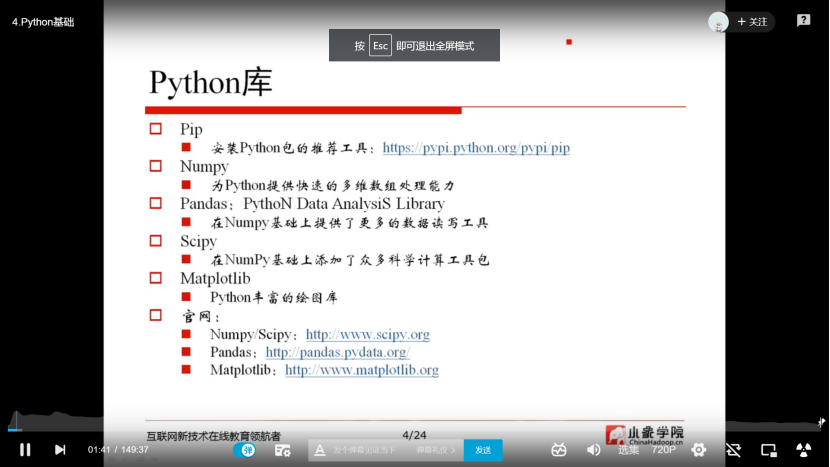
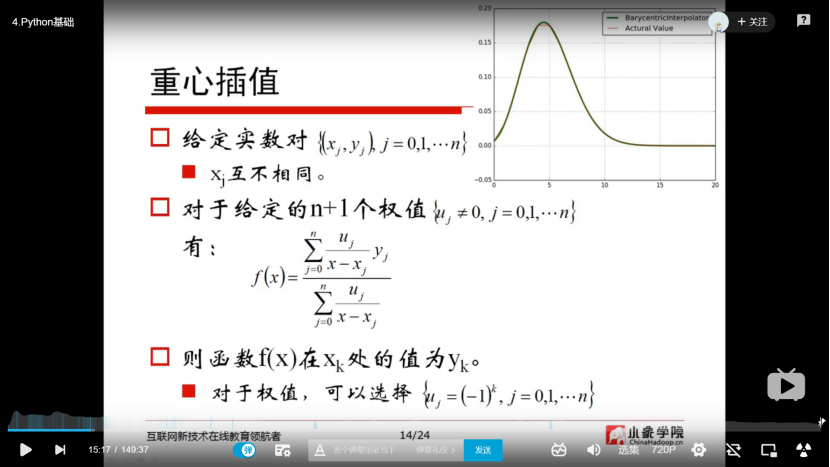
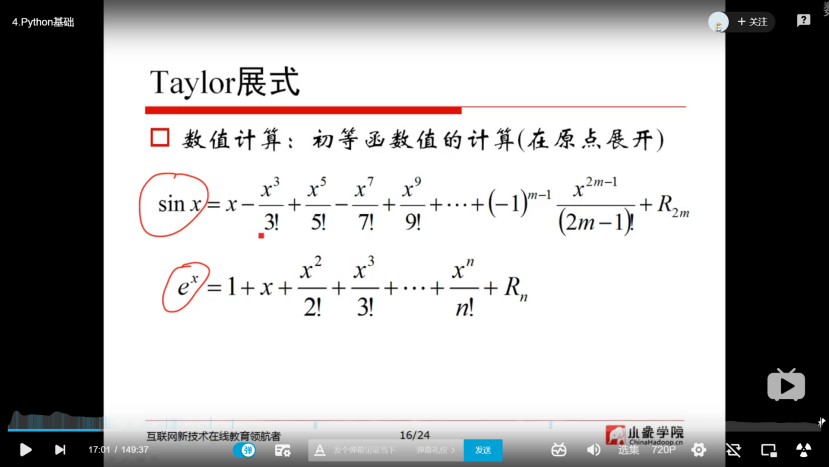
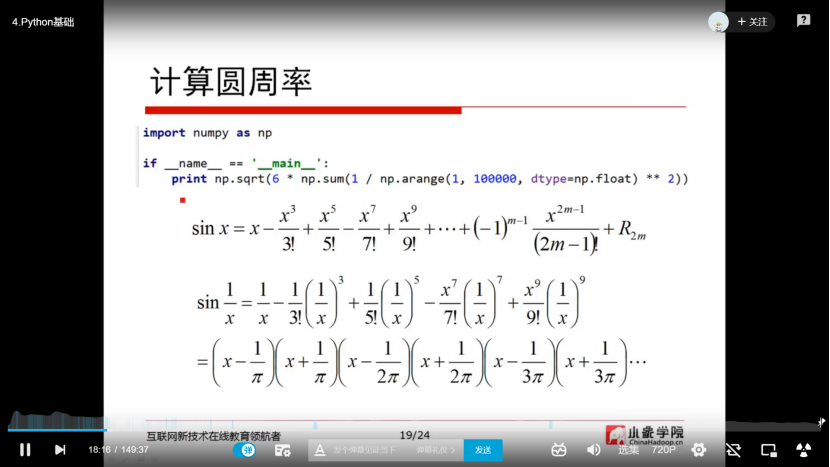
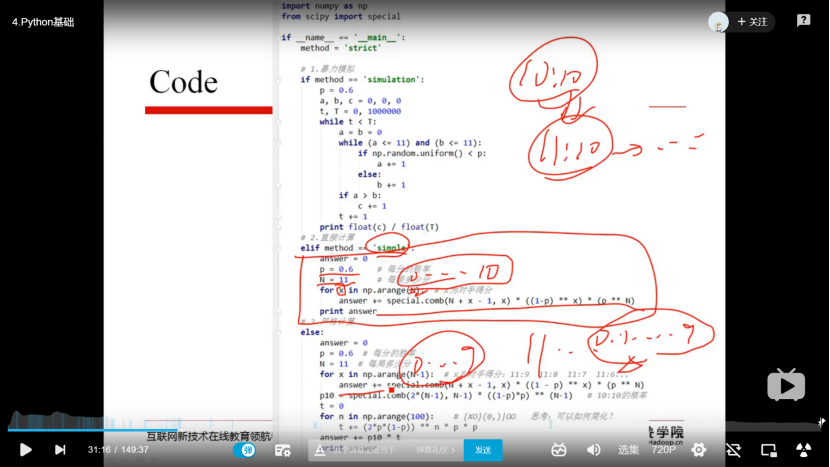
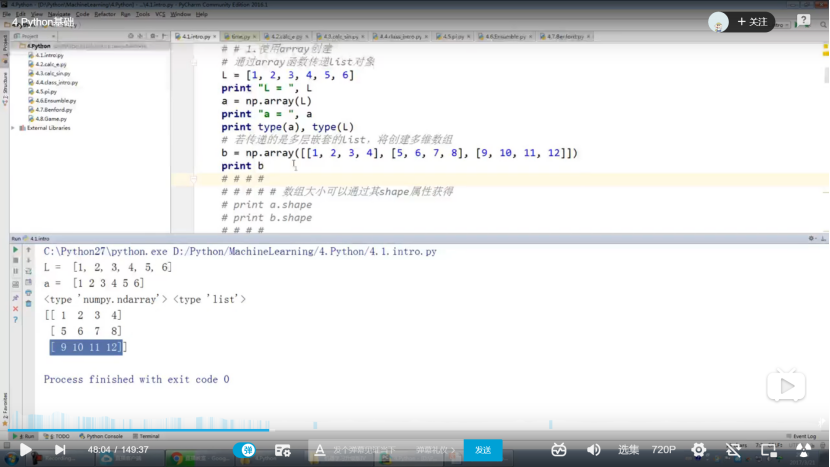
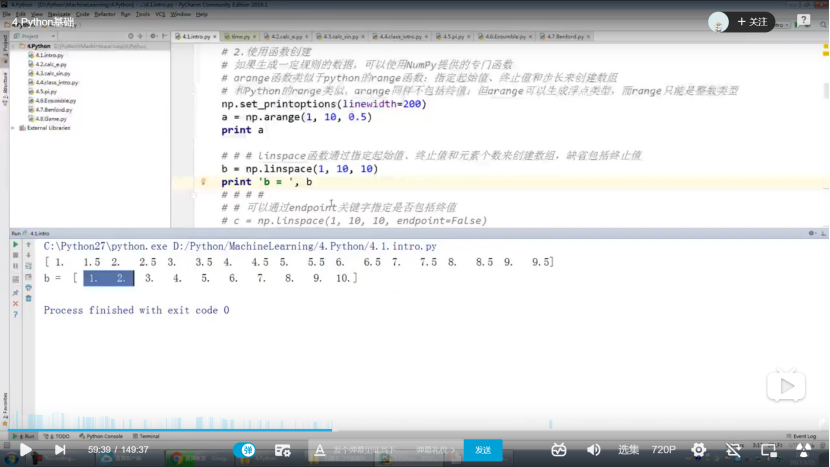
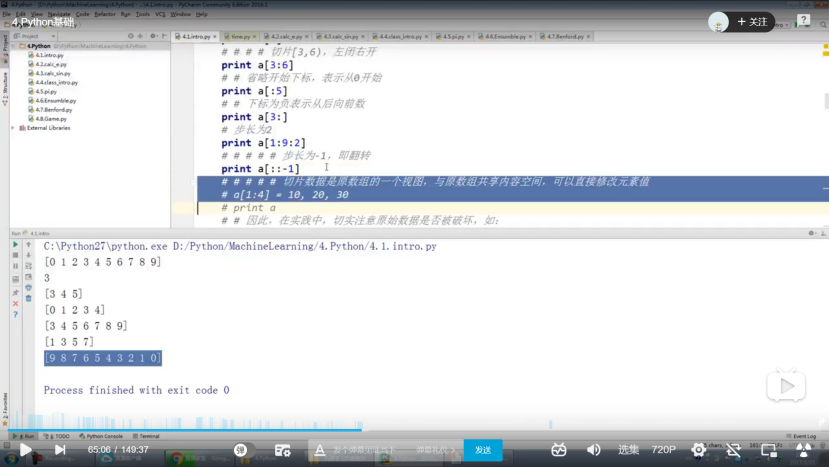
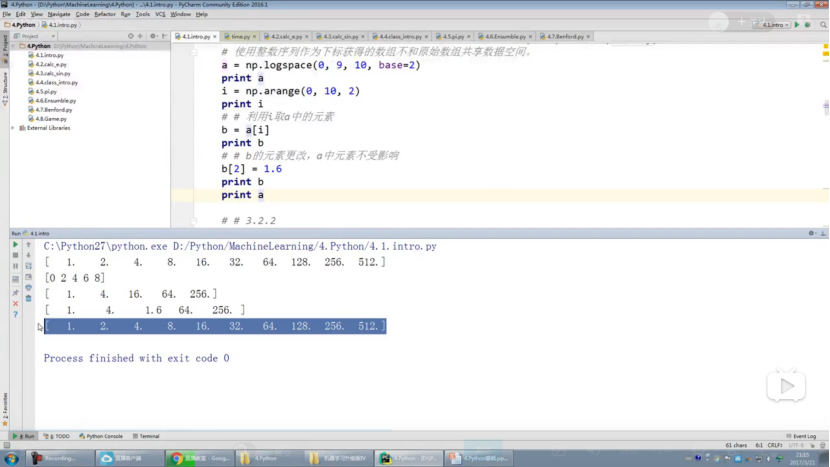
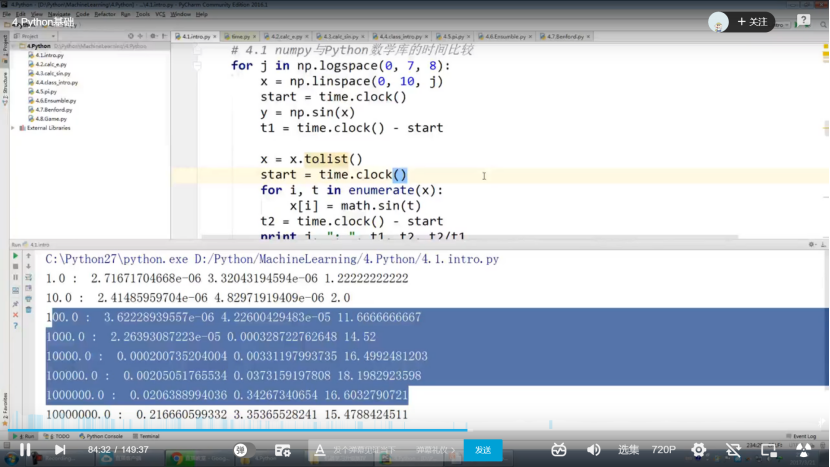
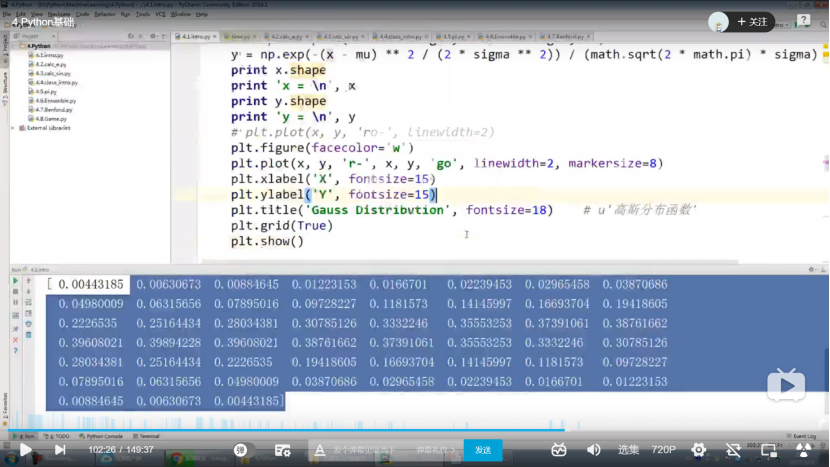
2.2 python基础

3、什么是机器学习,有哪些分类?结合案例,写出你的理解。
机器学习是人工智能的一个分支。我们使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进;过参数优化的学习模型,能够用于预测相关问题的输出。
机器学习四种类型如下:
监督学习:根据已有的数据集,知道输入和输出结果之间的关系。根据这种已知的关系,训练得到一个最优的模型。在监督学习中训练数据既有特征又有标签,通过训练,让机器可以自己找到特征和标签之间的联系,在面对只有特征没有标签的数据时,可以判断出标签。可以把机器学习理解为我们教机器如何做事情。例如分类、回归。
无监督学习:不知道数据集中数据、特征之间的关系,而是要根据聚类或一定的模型得到数据之间的关系。例如Google新闻按照内容结构的不同分成财经,娱乐,体育等不同的标签,这就是无监督学习中的聚类。
半监督学习:使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。例如生物学家可能要很多时间对某种蛋白质的结构分析或者功能鉴定,然而大量的未标记的数据可能容易得出。
强化学习:让计算机实现从一开始完全随机的进行操作,通过不断地尝试,从错误中学习,最后找到规律,学会了达到目的的方法。例如训练宠物,有惩罚和奖励,随着时间推移,宠物会做到对的事来获得奖励。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号