分类与监督学习,朴素贝叶斯分类算法
1.简述分类与聚类的联系与区别?
分类是按照某种标准给对象贴标签,再根据标签来区分归类。聚类是指事先没有“标签”而通过某种成团分析找出事物之间存在聚集性原因的过程。区别是分类是事先定义好类别 ,类别数不变 。分类器需要由人工标注的分类训练得到,属于有指导学习范畴。聚类则没有事先预定的类别,类别数不确定。 聚类不需要人工标注和预先训练分类器,类别在聚类过程中自动生成 。分类的目的是学会一个分类函数或分类模型,该模型能把数据库中的数据项映射到给定类别中的某一个类中。聚类是指根据“物以类聚”原理,将本身没有类别的样本聚集成不同的组,这样的一组数据对象的集合叫做簇,并且对每一个这样的簇进行描述的过程。
2.简述什么是监督学习与无监督学习
监督学习是利用已知类别的样本,调整分类器的参数,训练得到一个最优模型,使其达到所要求性能,再利用这个训练后的模型,将所有的输入映射为相应的输出,对输出进行简单的判断,从而实现分类的目的,这样,即可以对未知数据进行分类。无监督学习是实现没有有标记的、已经分类好的样本,需要我们直接对输入数据集进行建模,把相似度高的东西放在一起,对于新来的样本,计算相似度后,按照相似程度进行归类就好。两者的区别是监督学习只利用标记的样本集进行学习,而无监督学习只利用未标记的样本集。
3.朴素贝叶斯分类算法实例
利用关于心脏情患者的临床数据集,建立朴素贝叶斯分类模型。
有六个分类变量(分类因子):性别,年龄、KILLP评分、饮酒、吸烟、住院天数
目标分类变量疾病:–心梗–不稳定性心绞痛
新的实例:–(性别=‘男’,年龄<70, KILLP=‘I',饮酒=‘是’,吸烟≈‘是”,住院天数<7)
最可能是哪个疾病?
演算过程:

结果表明病人患的是心梗疾病概率比较大。
4.编程实现朴素贝叶斯分类算法
利用训练数据集,建立分类模型。
输入待分类项,输出分类结果。
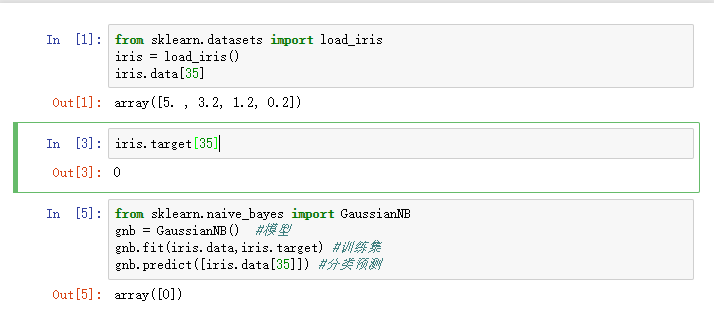
代码演示过程(以鸢尾花为例):

 浙公网安备 33010602011771号
浙公网安备 33010602011771号