期末作业——波士顿房价预测及中文文本分词
一、boston房价预测
1. 读取数据集
from sklearn.datasets import load_boston boston = load_boston() boston.keys() print(boston.DESCR) boston.data.shape import pandas as pd pd.DataFrame(boston.data)
运行结果:

2. 训练集与测试集划分
from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test = train_test_split(boston.data,boston.target,test_size=0.3) print(x_train.shape,y_train.shape)
运行结果:

3. 线性回归模型:建立13个变量与房价之间的预测模型,并检测模型好坏。
from sklearn.linear_model import LinearRegression#建立模型
mlr = LinearRegression()
mlr.fit(x_train,y_train)
print('系数',mlr.coef_,"\n截距",mlr.intercept_)
运行结果:

#检测模型好坏
from sklearn.metrics import regression
y_predict = mlr.predict(x_test)
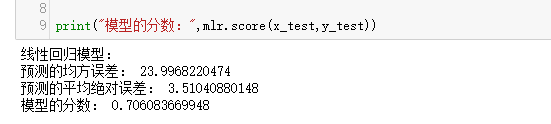
print('线性回归模型:')
print("预测的均方误差:",regression.mean_squared_error(y_test,y_predict))
print("预测的平均绝对误差:",regression.mean_absolute_error(y_test,y_predict))
print("模型的分数:",mlr.score(x_test,y_test))
运行结果:
4. 多项式回归模型:建立13个变量与房价之间的预测模型,并检测模型好坏。
from sklearn.preprocessing import PolynomialFeatures
# 多项式化
poly2 =PolynomialFeatures(degree=2)
x_poly_train = poly2.fit_transform(x_train)
x_poly_test = poly2.transform(x_test)
mlrp = LinearRegression()# 建立模型
mlrp.fit(x_poly_train, y_train)
y_predict2 = mlrp.predict(x_poly_test)# 测模型好坏
print("多项式回归模型:")
print("预测的均方误差:",regression.mean_squared_error(y_test,y_predict2))
print("预测平均绝对误差:",regression.mean_absolute_error(y_test,y_predict2))
print("模型的分数:",mlrp.score(x_poly_test,y_test))
运行结果:

结论:
通过计算可看到多项式回归模型的均方误差值、平均绝对误差值都比线性回归模型的值小,说明多项式回归模型比线性回归模型的拟合度更好。
5. 比较线性模型与非线性模型的性能,并说明原因。
线性算法有著名的逻辑回归、朴素贝叶斯、最大熵等,非线性算法有随机森林、决策树、神经网络、核机器等等。线性算法举应用训练和预测数据集的效率比较高,但最终效果对特征的依赖程度较高,需要数据在特征层面上是线性可分的。因此,使用线性算法需要在特征工程上下不少功夫,尽量对特征进行选择、变换或者组合等使得特征具有区分性。而非线性算法则可以建模复杂的分类面,从而能更好的拟合数据。
二、中文文本分类
1.获取文件,写文件
import os
import numpy as np
import sys
from datetime import datetime
import gc
path = 'E:\\E\\Pycharm\\12.6期末作业\\147'
import jieba
with open(r'E:\\stopsCN.txt',encoding='utf-8') as f: # 打开停用词文本,将无用的词读入进去
stopwords = f.read().split('\n')
2.除去噪声,如:格式转换,去掉符号,整体规范化
def processing(tokens):
tokens = "".join([char for char in tokens if char.isalpha()])# 去掉非字母汉字的字符
tokens = [token for token in jieba.cut(tokens,cut_all=True) if len(token) >=2]# 结巴分词
tokens = " ".join([token for token in tokens if token not in stopwords])# 去掉停用词
return tokens
3.遍历每个个文件夹下的每个文本文件,使用jieba分词将中文文本切割
tokenList = []
targetList = []
for root,dirs,files in os.walk(path):
for f in files:
filePath = os.path.join(root,f)
with open(filePath,encoding='gb18030',errors='ignore') as f:
content = f.read()
target = filePath.split('\\')[-2]
targetList.append(target)
tokenList.append(processing(content))
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB,MultinomialNB
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
# 划分训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(tokenList,targetList,test_size=0.3,train_size=0.7)
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(x_train)
X_test = vectorizer.transform(x_test)
from sklearn.naive_bayes import MultinomialNB
# 多项式朴素贝叶斯
mnb = MultinomialNB()
module = mnb.fit(X_train,y_train)
y_predict = module.predict(X_test)
# 对数据进行5次分割
scores=cross_val_score(mnb,X_test,y_test,cv=5)
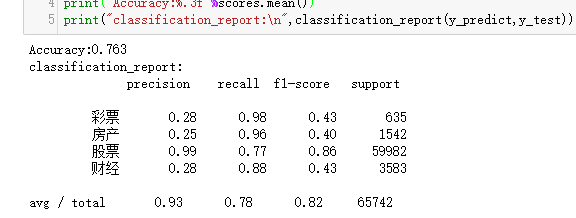
print("Accuracy:%.3f"%scores.mean())
print("classification_report:\n",classification_report(y_predict,y_test))
运行结果:
4.
targetList.append(target) print(targetList[0:10]) tokenList.append(processing(content)) tokenList[0:10]
运行结果:(很显然,结果不理想,说明前面的代码有问题,改正之后再更新)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号