



爬虫_腾讯招聘(xpath)
和昨天一样的工作量,时间只用了一半,但还是效率有点低了,因为要把两个网页结合起来,所以在列表操作上用了好多时间
1 import requests 2 from lxml import etree 3 4 headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'} 5 6 def get_html(url): 7 response = requests.get(url, headers=headers) 8 response.encoding = response.apparent_encoding 9 html = response.text 10 return html 11 12 13 def parse_html(html): 14 informations = [] 15 urls = [] 16 html_element = etree.HTML(html) 17 kinds = html_element.xpath('(//tr[@class="even"]|//tr[@class="odd"])/td[2]/text()') 18 ''' 19 kinds: 20 ['技术类', '设计类', '技术类', '技术类', '技术类', '技术类', '技术类', '技术类', '技术类', '产品/项目类'] 21 ''' 22 nums = html_element.xpath('(//tr[@class="even"]|//tr[@class="odd"])//td[3]/text()') 23 ''' 24 nums: 25 ['2', '1', '2', '1', '2', '2', '1', '2', '1', '1'] 26 ''' 27 addresses = html_element.xpath('(//tr[@class="even"]|//tr[@class="odd"])//td[4]/text()') 28 ''' 29 addresses: 30 ['深圳', '深圳', '深圳', '深圳', '深圳', '深圳', '深圳', '深圳', '深圳', '深圳'] 31 ''' 32 times = html_element.xpath('(//tr[@class="even"]|//tr[@class="odd"])//td[5]/text()') 33 ''' 34 times: 35 ['2018-08-04', '2018-08-04', '2018-08-04', '2018-08-04', '2018-08-04', '2018-08-04', '2018-08-04', '2018-08-04', '2018-08-04', '2018-08-04'] 36 ''' 37 names = html_element.xpath('(//tr[@class="even"]|//tr[@class="odd"])//a/text()') 38 39 40 41 42 43 detail_url = html_element.xpath('(//tr[@class="even"]|//tr[@class="odd"])//a/@href') 44 for str_url in detail_url: 45 46 url = 'https://hr.tencent.com/' + str(str_url) 47 urls.append(url) 48 49 ''' 50 urls : 51 ['https://hr.tencent.com/position_detail.php?id=42917&keywords=python&tid=0&lid=0', 52 'https://hr.tencent.com/position_detail.php?id=42908&keywords=python&tid=0&lid=0', 53 ...... 54 'https://hr.tencent.com/position_detail.php?id=42832&keywords=python&tid=0&lid=0', 55 'https://hr.tencent.com/position_detail.php?id=42628&keywords=python&tid=0&lid=0'] 56 ''' 57 for index, name in enumerate(names): 58 information = {} 59 information['name'] = name 60 information['url'] = urls[index] 61 information['kind'] = kinds[index] 62 information['nums_of_need'] = nums[index] 63 information['address'] = addresses[index] 64 informations.append(information) 65 # print(informations) 66 # print(urls) 67 return urls, informations 68 69 70 71 def parse_detail_page(url): 72 #one detail page 73 html = get_html(url) 74 return html 75 76 77 78 def get_all_page(page_nums): 79 for i in range(0, page_nums): 80 url = 'https://hr.tencent.com/position.php?lid=&tid=&keywords=python&start={0}#a'.format(i*10) 81 html = get_html(url) 82 urls, informations = parse_html(html) 83 # print(informations) 84 works = [] 85 for i, url in enumerate(urls): 86 87 html_detail = parse_detail_page(url) 88 html_element = etree.HTML(html_detail) 89 work_intro = html_element.xpath('//td[@class="l2"]//text()') 90 for index, text in enumerate(work_intro): 91 if text.startswith('工作职责:'): 92 text = text.replace('工作职责:', '') 93 works_detail = {} 94 intros = [] 95 for x in range(index+1, len(work_intro)): 96 intro = work_intro[x].strip() 97 if work_intro[x].startswith('工作要求:'): 98 break 99 intros.append(intro) 100 while '' in intros: 101 intros.remove('') 102 works_detail['1_____工作职责:'] = intros 103 works.append(works_detail) 104 # print(intros) 105 ''' 106 ['负责NLP与深度学习相关技术的研究与实现;', 107 '负责建设基础的语义分析工具和平台;', 108 '负责搜索系统、知识图谱系统、问答与对话系统的设计与搭建;', 109 '结合实际业务需求与数据,研发高效、稳健、完备的NLP解决方案。'] 110 ''' 111 112 if text.startswith('工作要求:'): 113 text = text.replace('工作要求:', '') 114 works_detail = {} 115 requests = [] 116 for x in range(index+1, len(work_intro)): 117 intro = work_intro[x].strip() 118 if work_intro[x].startswith('申请岗位'): 119 break 120 requests.append(intro) 121 while '' in requests: 122 requests.remove('') 123 works_detail['2_____工作要求:'] = requests 124 works.append(works_detail) 125 # print(requests) 126 ''' 127 ['三年以上自然语言处理经验包括语义表示、搜索、知识图谱、对话系统等;', 128 '扎实的编程基础,至少精通一种编程语言,如C++,Java,python等;', 129 '熟悉深度学习以及常见机器学习算法的原理与算法,能熟练运用聚类、分类、回归、排序等模型解决有挑战性的问题;', 130 '对自然语言处理相关的分词、词性标注、实体识别、句法分析、语义分析等有深入的实践经验;', 131 '有强烈求知欲,对人工智能领域相关技术有热情;', '具有良好的数学基础,良好的英语阅读能力;', 132 '有项目管理经验,与他人合作良好,能够独立有效推动复杂项目。'] 133 ''' 134 return works, informations 135 136 137 138 def main(): 139 works, informations = get_all_page(1) 140 for index, information in enumerate(informations): 141 list = [] 142 list.append(works[index*2]) 143 list.append(works[index*2+1]) 144 information['duty'] = list 145 print(information) 146 147 148 if __name__ == '__main__': 149 main()
目前sublime还输入不了中文,所以把输出注释上,方便看清格式
运行结果:
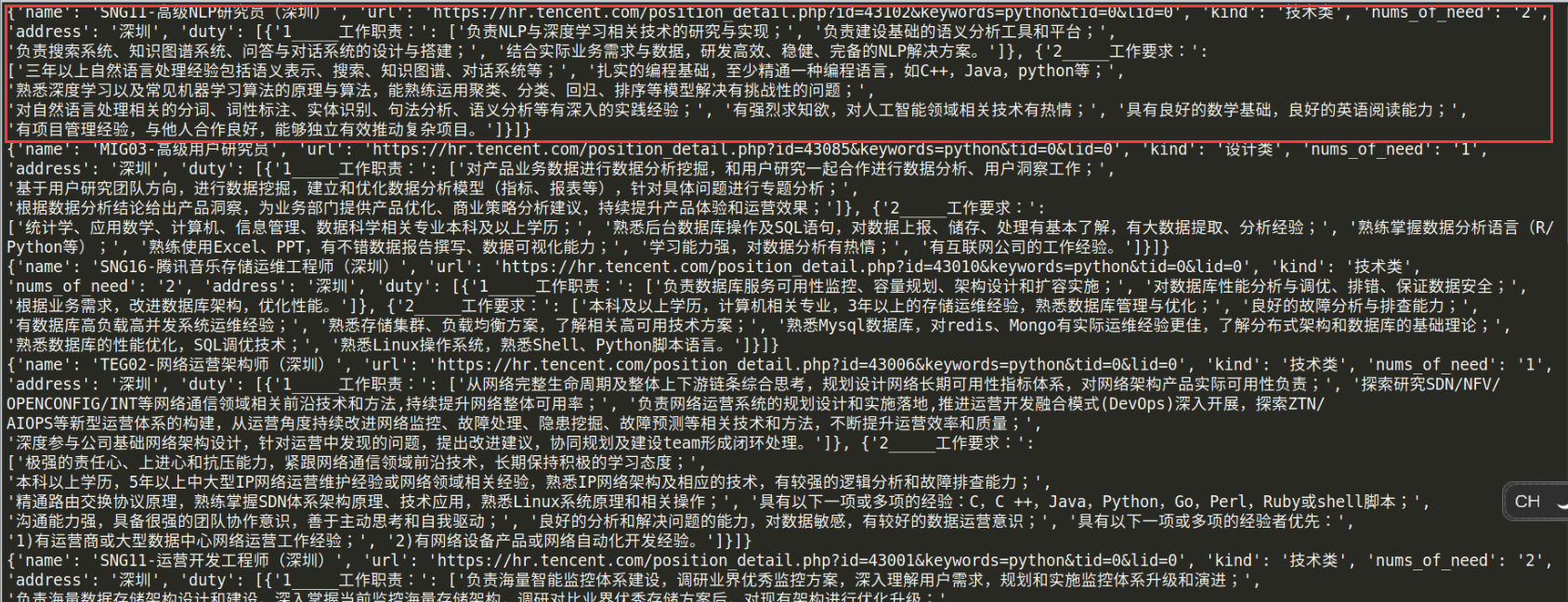
红色圈出来的是一个字典,包含第一个网页的信息(职位名称,url,位置)和详情页面的职责(工作职责,工作要求),嵌套的可能有点复杂,但目前还没有想到更简明的方法

