需求分析
1.程序可读入任意英文文本文件,该文件中英文词数大于等于1个。
2.程序需要很壮健,能读取容纳英文原版《哈利波特》10万词以上的文章。
基本功能
1.指定单词词频统计功能:用户可输入从该文本中想要查找词频的一个或任意多个英文单词,运行程序的统计功能可显示对应单词在文本中出现的次数和柱状图。
2.高频词统计功能:用户从键盘输入高频词输出的个数k,运行程序统计功能,可按文本中词频数降序显示前k个单词的词频及单词。
3.统计该文本所有单词数量及词频数,并能将单词及词频数按字典顺序输出到文件result.txt。
环境需求
1.测试机环境:Windows环境
2.JDK版本:jdk8u161
3.JRE版本:jre8u161
功能设计
1.新建文本文件data.txt
2.统计各个单词出现的次数
3.如果次数相同,安装单词的字典顺序排序
4.输出单词个数
5.输入要查询的单词,显示它出现的次数
6.输出结果并将其存储到result.txt文件中
设计实现
通过Map集合,以键值对的方式去存储单词和出现的次数,定义一个文件字节读取流,去读取磁盘中的文件,创建了一个BufferReader的缓冲流,将字符流对象传进去,提高读取的效率,创建一个split数组,用来分割字符串,通过调用map的key值获取value,进行单词统计,用TreeMap实现Comparator接口,对Map集合进行排序
测试运行
- 程序的运行截图如下图:
- 单词查找:
![]()
![]()
- 单词个数统计:
![]()
- 词频统计:
![]()
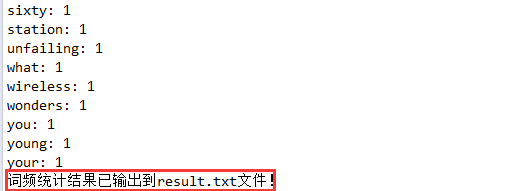
- 词频输出结果:
![]()
代码片段
Map<String, Integer> wordsCount = new TreeMap<String,Integer>(); //存储单词计数信息,key值为单词,value为单词数
//单词的词频统计
for (String li : lists) {
if(wordsCount.get(li) != null){
wordsCount.put(li,wordsCount.get(li) + 1);
}else{
wordsCount.put(li,1);
ArrayList<Map.Entry<String,Integer>> list = new ArrayList<Map.Entry<String,Integer>>(oldmap.entrySet());
Collections.sort(list,new Comparator<Map.Entry<String,Integer>>(){
@Override
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
return o2.getValue() - o1.getValue(); //降序
}
});
try{
FileWriter fr=new FileWriter("D:\\results.txt");
BufferedWriter txt=new BufferedWriter(fr);
for (Map.Entry<String,Integer> entry: list) {
txt.write(entry.getKey()+":"+entry.getValue());
txt.newLine();
}
txt.flush();
txt.close();
System.out.println("词频统计结果已输出到result.txt文件!");
}
catch(IOException e) {
e.printStackTrace();
展示PSP
|
|
|
| 任务内容 |
计划共完成需要的时间(min) |
实际完成需要的时间(min) |
| 计划 |
10 |
9 |
| 估计这个任务需要多少时间,并规划大致工作步骤 |
15 |
20 |
| 开发 |
200 |
230 |
| 需求分析 (包括学习新技术) |
10 |
10 |
| 生成设计文档 |
10 |
15 |
| 设计复审 (和同事审核设计文档) |
10 |
12 |
| 代码规范 (为目前的开发制定合适的规范) |
10 |
9 |
| 具体设计 |
40 |
45 |
| 具体编码 |
120 |
130 |
| 代码复审 |
15 |
12 |
| 测试(自我测试,修改代码,提交修改) |
30 |
40 |
| 报告 |
15 |
15 |
| 测试报告 |
5 |
6 |
| 计算工作量 |
5 |
3 |
| 事后总结 ,并提出过程改进计划 |
6 |
4 |
具体设计和具体编码环节耗时最多,测试(自我测试,修改代码,提交修改)环节估计和实践相差巨大。具体原因可能要归结于由于Java编程功底很弱,对于Java语法结构、类的定义、函数的构造等知识方面都严重匮乏导致在代码编码上浪费了很多时间。
本次作业项目github地址

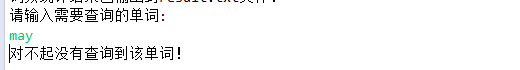



 浙公网安备 33010602011771号
浙公网安备 33010602011771号