机器学习第二次作业
1.Iris数据集结构
将数据集载入后输出
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.keys())
n_samples, n_features = iris.data.shape
print((n_samples, n_features))
print(iris.data[0])
print(iris.target.shape)
print(iris.target)
print(iris.target_names)
print("feature_names:",iris.feature_names)
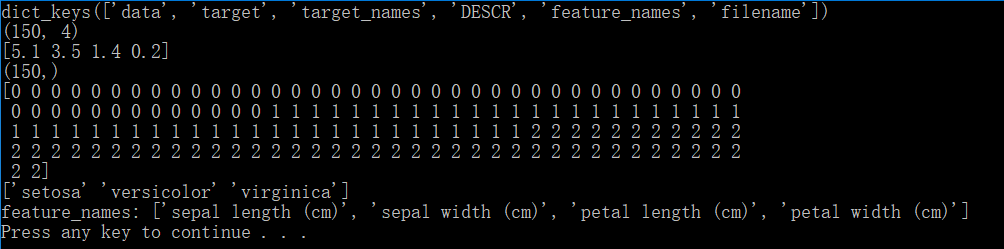
Iris数据集有5个属性:['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename']
target_names有3个属性:[‘setosa’ ‘versicolor’ ‘virginica’] (山鸢尾 (Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica) 分别用[0,1,2]来做映射)
feature_names有4个属性:['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
共150个样本。
2.可视化判别线性可分
用三种颜色表示三种花卉,绘制散点图。红色、蓝色和绿色分别代表了山鸢尾、变色鸢尾和维吉尼亚鸢尾。
x表示萼片的长度,y轴表示萼片的宽度
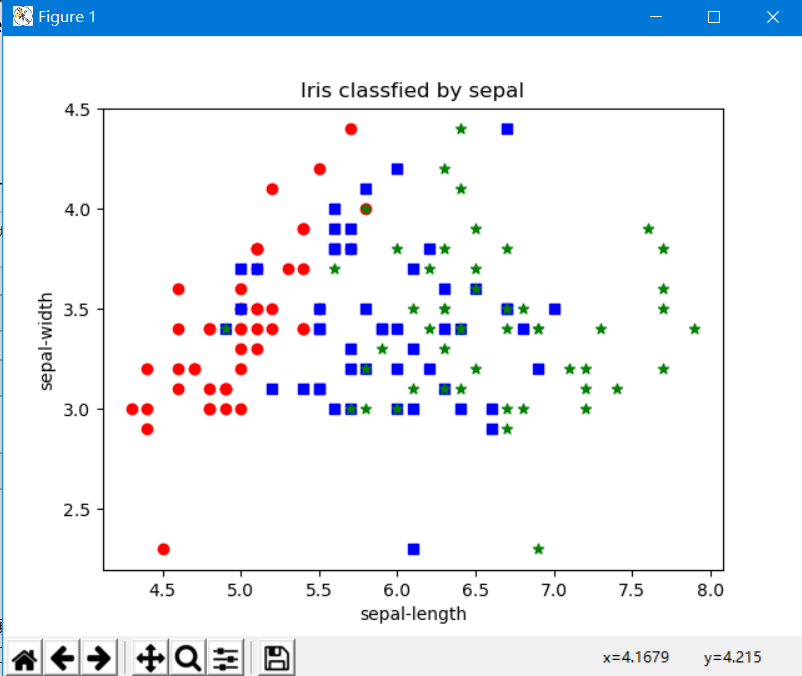
可以看到红色与绿色点集还是分得比较开的,而中间的蓝色点集则与左右两边的点混合在一起
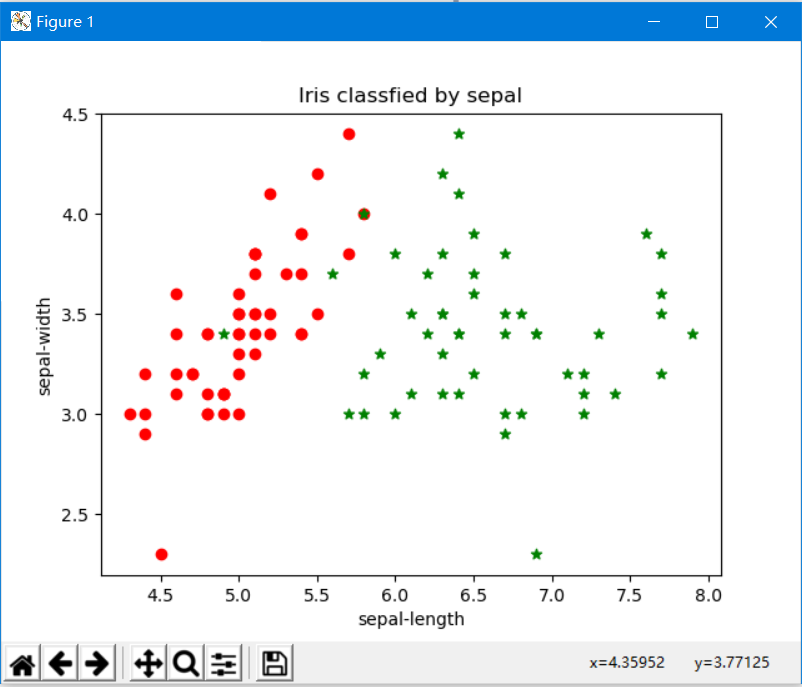
若去掉中间的蓝色点集,则更能直观看出红绿分布是线性可分的,从萼片的长宽来看,山鸢尾和维吉尼亚鸢尾线性可分
绘图代码
fname = 'iris.data'
with open(fname, 'r+', encoding='utf-8') as f:
s = [i[:-1].split(',') for i in f.readlines()]
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
iris =pd.DataFrame(data=s, columns=names)
print(iris)
iris.dropna(axis=0, how='any', inplace=True)
seto = iris.iloc[0:50,:]
vers = iris.iloc[50:100,:]
virg = iris.iloc[100:150,:]
# 统计每个品种有多少个样本
iris['class'].value_counts()
# 字符串类型的数据变成float(否则不能画图)
iris.iloc[:,:4]=iris.iloc[:,:4].astype('float')
# 画出散点图
plt.scatter(x=seto['sepal-length'],y=seto['sepal-width'],color='red')
plt.scatter(x=vers['sepal-length'],y=seto['sepal-width'],color='blue',marker="s")
plt.scatter(x=virg['sepal-length'],y=seto['sepal-width'],color='green',marker='*')
plt.xlabel('sepal-length')
plt.ylabel('sepal-width')
plt.title('Iris classfied by sepal')
plt.show()
当使用花瓣的长和宽作为特征时,山鸢尾和维吉尼亚鸢尾之间的区别更明显
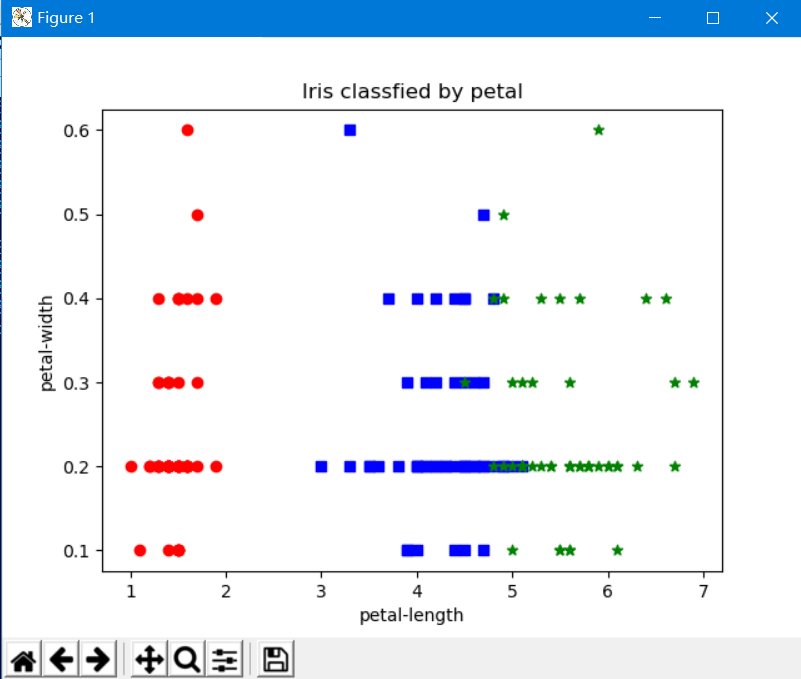
而变色鸢尾花和维吉尼亚鸢尾这两个品种无论是在花萼还是花瓣的划分上,都没有明显的界限,它们是线性不可分的。
3.MED分类器线性可分
去掉变色鸢尾,剩下山鸢尾和维吉尼亚鸢尾两个线性可分的类。
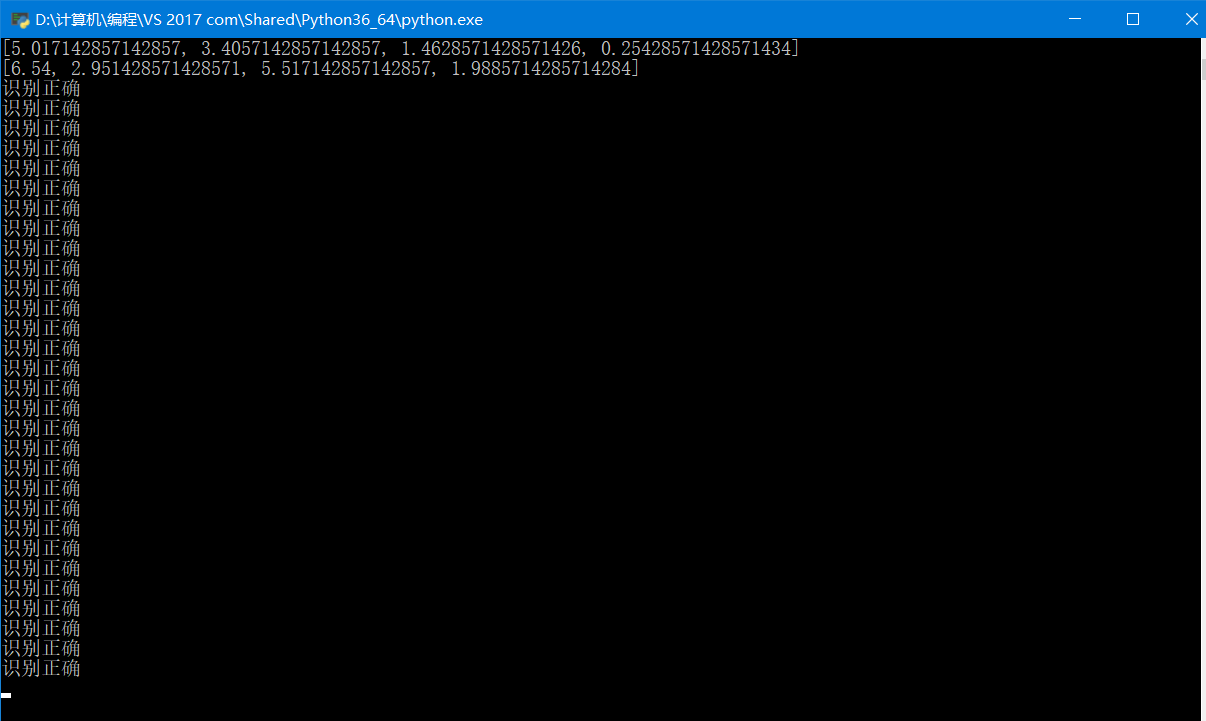
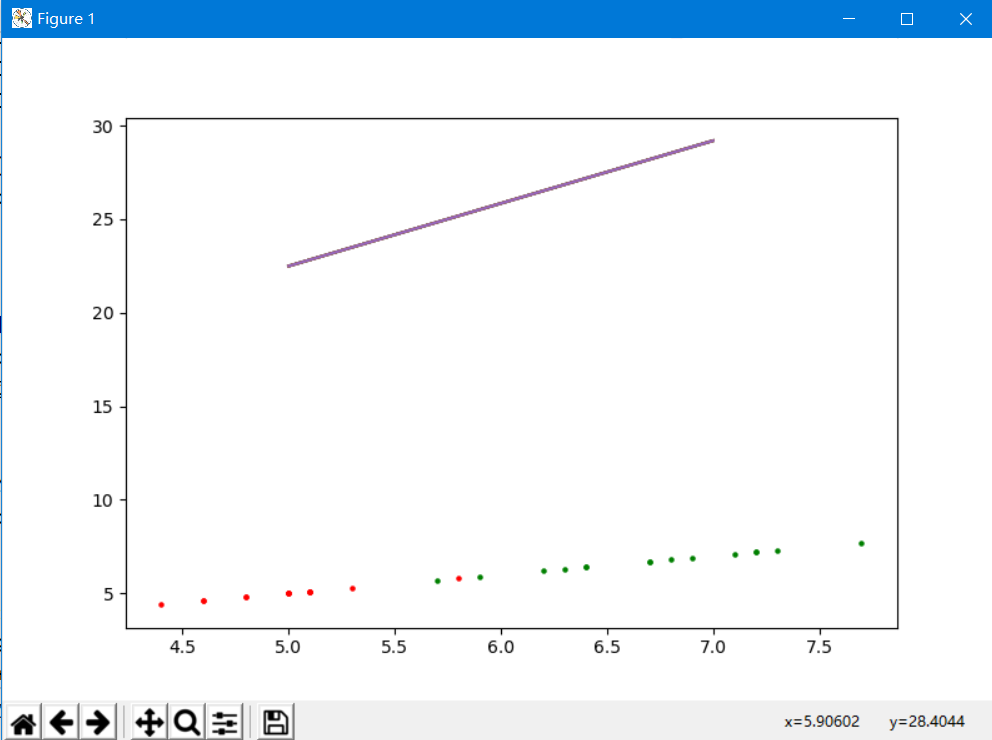
这个MED线性可分识别准确度还是很可观的,30个测试样本全部识别正确
Iris_linear = iris.data[:100]
iris_setosa = iris.data[0:50]
iris_virginica = iris.data[100:150]
def split_train(data,test_ratio):#随机划分数据集
shuffled_indices=np.random.permutation(len(data))
test_set_size=int(len(data)*test_ratio)
test_indices =shuffled_indices[:test_set_size]
train_indices=shuffled_indices[test_set_size:]
return data[train_indices],data[test_indices]
def eucldist(coords1, coords2):#求两点欧式距离
dist = 0
for (x, y) in zip(coords1, coords2):
dist += (x - y)**2
return dist**0.5
split = split_train(iris_setosa,0.3)
split = split_train(iris_virginica,0.3)
iris_setosa_train = split[0]#size35
iris_setosa_text = split[1]
iris_virginica_train = split[0]#size35
iris_virginica_text = split[1]
class1 = []
#print(iris_setosa_train)
for j in range(0,4):
sum = 0
for i in range(0,35):
sum = sum + iris_setosa_train[i][j]
class1.append(sum/35)
print(class1)
class2 = []
#print(iris_virginica_train)
for j in range(0,4):
sum = 0
for i in range(0,35):
sum = sum + iris_virginica_train[i][j]
class2.append(sum/35)
print(class2)
for i in range (0,15):
if (eucldist(iris_setosa_text[i], class1)<eucldist(iris_setosa_text[i], class2)):
print("识别正确")
else:
print("识别错误")
for i in range (0,15):
if (eucldist(iris_virginica_text[i], class2)<eucldist(iris_virginica_text[i], class1)):
print("识别正确")
else:
print("识别错误")
virginica_color = 'g' # 绿色代表virginica
setosa_color = 'r' # 红色代表setosa
size = 5 # 散点的大小
plt.figure(figsize=(12, 12)) # 设置画布大小
x=np.linspace(5,7,50)
for i in range(0,15):
plt.scatter(iris_setosa_text[i][0], iris_setosa_text[i][0], c=setosa_color, s=size)
plt.scatter(iris_virginica_text[i][0],iris_virginica_text[i][0], c=virginica_color, s=size)
plt.plot(x,-(class1[0]-class2[0])/(class1[1]-class2[1])*x+(class1[1]+class2[1])/2+(class1[0]-class2[0])/(class1[1]-class2[1])*(class1[0]-class2[0])/2)
plt.show()
4.白化
白化可以减少特征之间的相关性,去除噪声,通常情况下,数据进行白化处理与不对数据进行白化处理相比,算法的收敛性较好
5.线性不可分
去掉山鸢尾,剩下容易混淆的变色鸢尾和维吉尼亚鸢尾两个线性不可分的类。
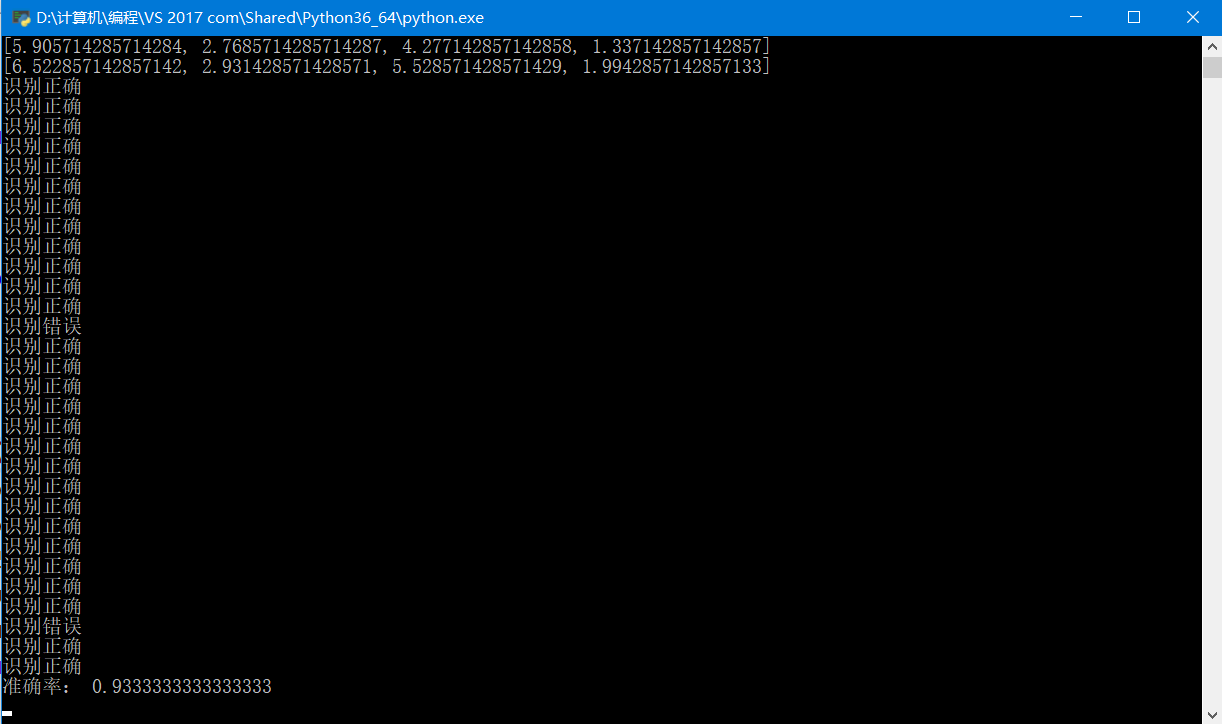
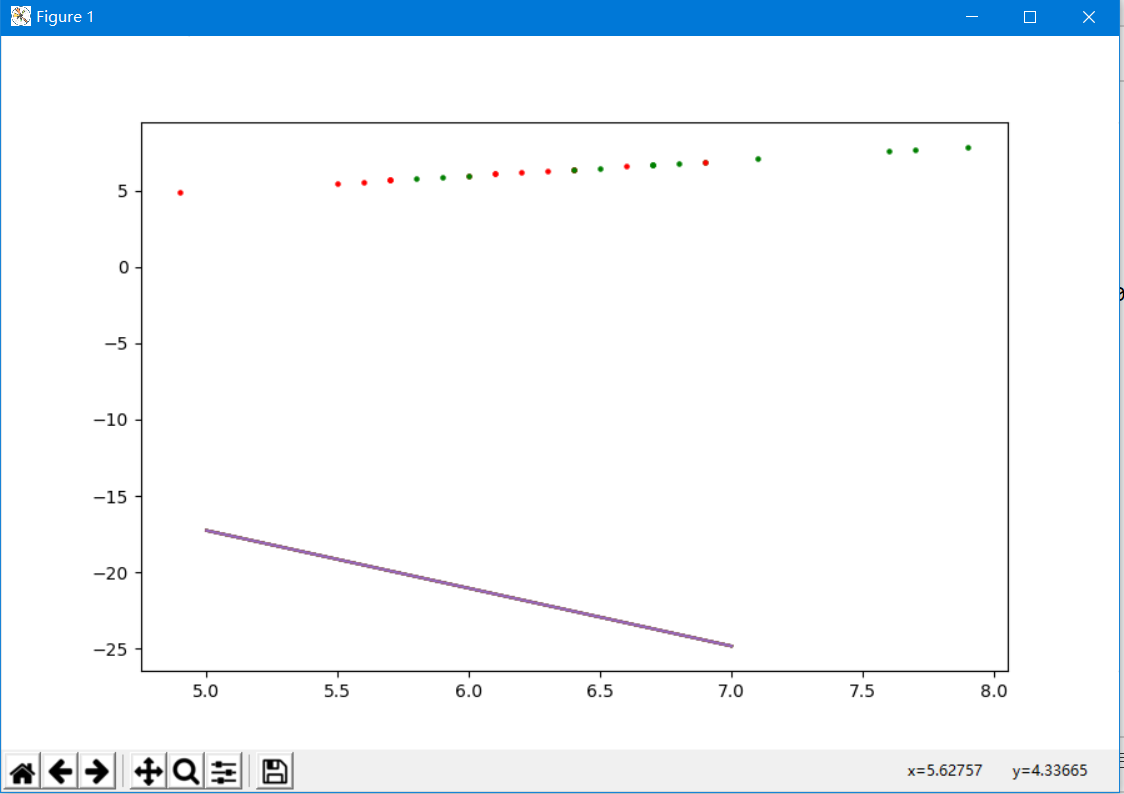
对线性不可分的两个类,MED出现了一些偏差
6.贝叶斯分类器
#贝叶斯分类器,使用贝叶斯公式。
#将每种样本进行5折交叉验证,先验概率相同
#所以后验概率与观测似然概率成正比,只需比较观测似然概率即可得到结果
#且决策风险定位相同
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import math
def calculateProb(x,mean,var):
exponent = math.exp(math.pow((x-mean),2)/(-2*var))
p = (1/math.sqrt(2*math.pi*var))*exponent
return p
iris = load_iris().data # 加载机器学习的下的iris数据集
iris_setosa = iris[0:50]
iris_versicolor = iris[50:100]
iris_virginica = iris[100:150]
countT = 1
countF = 1
for i in range(0,5):#5折交叉验证
iris_setosa_train = np.vstack((iris_setosa[0:i*10],iris_setosa[10*(i+1):50]))
iris_setosa_text = iris_setosa[i*10:10*(i+1)]
iris_versicolor_train = np.vstack((iris_versicolor[0:i*10],iris_versicolor[10*(i+1):50]))
iris_versicolor_text = iris_versicolor[i*10:10*(i+1)]
iris_virginica_train = np.vstack((iris_virginica[0:i*10],iris_virginica[10*(i+1):50]))
iris_virginica_text = iris_virginica[i*10:10*(i+1)]
#分割处理
iris_setosa_train = np.hsplit(iris_setosa_train, 4) # 运用numpy.hsplit水平分割获取各特征集合,分割成四列
iris_versicolor_train = np.hsplit(iris_versicolor, 4)
iris_virginica_train = np.hsplit(iris_virginica, 4)
#求均值
iris_setosa_train_mean = []
iris_versicolor_train_mean = []
iris_virginica_train_mean = []
for j in range(0,4):
iris_setosa_train_mean.append(np.mean(iris_setosa_train[j]))
for j in range(0,4):
iris_versicolor_train_mean.append(np.mean(iris_versicolor_train[j]))
for j in range(0,4):
iris_virginica_train_mean.append(np.mean(iris_virginica_train[j]))
#求方差
iris_setosa_train_var = []
iris_versicolor_train_var = []
iris_virginica_train_var = []
for j in range(0,4):
iris_setosa_train_var.append(np.var(iris_setosa_train[j]))
for j in range(0,4):
iris_versicolor_train_var.append(np.var(iris_versicolor_train[j]))
for j in range(0,4):
iris_virginica_train_var.append(np.var(iris_virginica_train[j]))
#求观测似然概率,使用setosa验证集验证
for j in range(0,10):
iris_setosa_setosa_prob = calculateProb(iris_setosa_text[j][0],iris_setosa_train_mean[0],iris_setosa_train_var[0])\
*calculateProb(iris_setosa_text[j][1],iris_setosa_train_mean[1],iris_setosa_train_var[1])\
*calculateProb(iris_setosa_text[j][2],iris_setosa_train_mean[2],iris_setosa_train_var[2])\
*calculateProb(iris_setosa_text[j][3],iris_setosa_train_mean[3],iris_setosa_train_var[3])
iris_setosa_versicolor_prob = calculateProb(iris_setosa_text[j][0],iris_versicolor_train_mean[0],iris_versicolor_train_var[0])\
*calculateProb(iris_setosa_text[j][1],iris_versicolor_train_mean[1],iris_versicolor_train_var[1])\
*calculateProb(iris_setosa_text[j][2],iris_versicolor_train_mean[2],iris_versicolor_train_var[2])\
*calculateProb(iris_setosa_text[j][3],iris_versicolor_train_mean[3],iris_versicolor_train_var[3])
iris_setosa_virginica_prob = calculateProb(iris_setosa_text[j][0],iris_virginica_train_mean[0],iris_virginica_train_var[0])\
*calculateProb(iris_setosa_text[j][1],iris_virginica_train_mean[1],iris_virginica_train_var[1])\
*calculateProb(iris_setosa_text[j][2],iris_virginica_train_mean[2],iris_virginica_train_var[2])\
*calculateProb(iris_setosa_text[j][3],iris_virginica_train_mean[3],iris_virginica_train_var[3])
if (iris_setosa_setosa_prob>iris_setosa_versicolor_prob and iris_setosa_setosa_prob>iris_setosa_virginica_prob):
print("true")
print(countT)
countT = countT + 1
else:
print("falus")
print(countF)
countF = countF + 1
print(iris_setosa_setosa_prob)
print(iris_setosa_versicolor_prob)
print(iris_setosa_virginica_prob)
#使用versicolor验证集验证
for j in range(0,10):
iris_versicolor_setosa_prob = calculateProb(iris_versicolor_text[j][0],iris_setosa_train_mean[0],iris_setosa_train_var[0])\
*calculateProb(iris_versicolor_text[j][1],iris_setosa_train_mean[1],iris_setosa_train_var[1])\
*calculateProb(iris_versicolor_text[j][2],iris_setosa_train_mean[2],iris_setosa_train_var[2])\
*calculateProb(iris_versicolor_text[j][3],iris_setosa_train_mean[3],iris_setosa_train_var[3])
iris_versicolor_versicolor_prob = calculateProb(iris_versicolor_text[j][0],iris_versicolor_train_mean[0],iris_versicolor_train_var[0])\
*calculateProb(iris_versicolor_text[j][1],iris_versicolor_train_mean[1],iris_versicolor_train_var[1])\
*calculateProb(iris_versicolor_text[j][2],iris_versicolor_train_mean[2],iris_versicolor_train_var[2])\
*calculateProb(iris_versicolor_text[j][3],iris_versicolor_train_mean[3],iris_versicolor_train_var[3])
iris_versicolor_virginica_prob = calculateProb(iris_versicolor_text[j][0],iris_virginica_train_mean[0],iris_virginica_train_var[0])\
*calculateProb(iris_versicolor_text[j][1],iris_virginica_train_mean[1],iris_virginica_train_var[1])\
*calculateProb(iris_versicolor_text[j][2],iris_virginica_train_mean[2],iris_virginica_train_var[2])\
*calculateProb(iris_versicolor_text[j][3],iris_virginica_train_mean[3],iris_virginica_train_var[3])
if (iris_versicolor_versicolor_prob>iris_versicolor_setosa_prob and iris_versicolor_versicolor_prob>iris_versicolor_virginica_prob):
print("true")
print(countT)
countT = countT + 1
else:
print("falus")
print(countF)
countF = countF + 1
print(iris_setosa_setosa_prob)
print(iris_setosa_versicolor_prob)
print(iris_setosa_virginica_prob)
#使用virginica验证集验证
for j in range(0,10):
iris_virginica_setosa_prob = calculateProb(iris_virginica_text[j][0],iris_setosa_train_mean[0],iris_setosa_train_var[0])\
*calculateProb(iris_virginica_text[j][1],iris_setosa_train_mean[1],iris_setosa_train_var[1])\
*calculateProb(iris_virginica_text[j][2],iris_setosa_train_mean[2],iris_setosa_train_var[2])\
*calculateProb(iris_virginica_text[j][3],iris_setosa_train_mean[3],iris_setosa_train_var[3])
iris_virginica_versicolor_prob = calculateProb(iris_virginica_text[j][0],iris_versicolor_train_mean[0],iris_versicolor_train_var[0])\
*calculateProb(iris_virginica_text[j][1],iris_versicolor_train_mean[1],iris_versicolor_train_var[1])\
*calculateProb(iris_virginica_text[j][2],iris_versicolor_train_mean[2],iris_versicolor_train_var[2])\
*calculateProb(iris_virginica_text[j][3],iris_versicolor_train_mean[3],iris_versicolor_train_var[3])
iris_virginica_virginica_prob = calculateProb(iris_virginica_text[j][0],iris_virginica_train_mean[0],iris_virginica_train_var[0])\
*calculateProb(iris_virginica_text[j][1],iris_virginica_train_mean[1],iris_virginica_train_var[1])\
*calculateProb(iris_virginica_text[j][2],iris_virginica_train_mean[2],iris_virginica_train_var[2])\
*calculateProb(iris_virginica_text[j][3],iris_virginica_train_mean[3],iris_virginica_train_var[3])
if (iris_virginica_virginica_prob>iris_virginica_setosa_prob and iris_virginica_virginica_prob>iris_virginica_versicolor_prob):
print("true")
print(countT)
countT = countT + 1
else:
print("falus")
print(countF)
countF = countF + 1
print(iris_setosa_setosa_prob)
print(iris_setosa_versicolor_prob)
print(iris_setosa_virginica_prob)
print("准确率:",countT/(countT+countF))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号