SpringBoot 启动流程追踪(第二篇)
上一篇文章分析了除 refresh 方法外的流程,并着重分析了 load 方法,这篇文章就主要分析 refresh 方法,可以说 refresh 方法是 springboot 启动流程最重要的一环,没有之一。我们通常在分析源码的过程中,都需要带着一个目标去看,不然看这看那,感觉什么都没有看一样。这篇文章的目标在于弄懂 SpringBoot 自动装配的原理,并且结合我们常用的 Mybatis-Plus 实战分析一下。如果你不感兴趣,可以直接跳过。
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
StartupStep beanPostProcess = this.applicationStartup.start("spring.context.beans.post-process");
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
beanPostProcess.end();
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
该方法是由 AnnotationConfigServletWebServerApplicationContext 类调用的,不过它也是调用的父类的方法,所以你可以直接挪到 AbstractApplicationContext 抽象类即可。
一、invokeBeanFactoryPostProcessors
if (beanFactory instanceof BeanDefinitionRegistry) {
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
}
else {
regularPostProcessors.add(postProcessor);
}
}
......
}
这里的 beanFactory 是 DefaultListableBeanFactory,它是 BeanDefinitionRegistry 是实例,至于怎么来的我想你应该清楚哈。然后在这片段代码里,我们比较注意的是 registryProcessor.postProcessBeanDefinitionRegistry(registry)。
这时你应该想到 beanFactoryPostProcessors 的值是怎么来的,如果你往前追溯的话,可以知道是在 prepareContext 方法里赋值的。另外需要注意到的是它分成了两个类型的 processor,一个是 regularPostProcessors,另一个是 registryProcessors。
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
// Separate between BeanDefinitionRegistryPostProcessors that implement
// PriorityOrdered, Ordered, and the rest.
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();
// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry, beanFactory.getApplicationStartup());
currentRegistryProcessors.clear();
接着我们看这段代码,这里的注释意思很清楚:不要在这里实例化 FactoryBeans,我们需要把所有的 regular beans 留给 beanFactory 的 post-processors 去处理。然后将 BeanDefinitionRegistryPostProcessors 分离为实现了 PriorityOrdered、Ordered 两类,以及剩下的为一类,然后调用 invokeBeanDefinitionRegistryPostProcessors 方法进行处理。
private static void invokeBeanDefinitionRegistryPostProcessors(
Collection<? extends BeanDefinitionRegistryPostProcessor> postProcessors, BeanDefinitionRegistry registry, ApplicationStartup applicationStartup) {
for (BeanDefinitionRegistryPostProcessor postProcessor : postProcessors) {
StartupStep postProcessBeanDefRegistry = applicationStartup.start("spring.context.beandef-registry.post-process")
.tag("postProcessor", postProcessor::toString);
postProcessor.postProcessBeanDefinitionRegistry(registry);
postProcessBeanDefRegistry.end();
}
在这里仅有一个实现了 PriorityOrdered 的 postProcessor,那就是 ConfigurationClassPostProcessor,这个是一个非常非常重要的 postProcessor,这里不妨追溯一下它的数据来源,各位可以自己追溯看看,毕竟这是看源码过程中一个必备的能力,答案就是在创建 context 的时候,调用 createApplicationContext 方法时,就设置值进去了,具体代码如下:
context = createApplicationContext();
public AnnotationConfigServletWebServerApplicationContext() {
this.reader = new AnnotatedBeanDefinitionReader(this);
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry, Environment environment) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
Assert.notNull(environment, "Environment must not be null");
this.registry = registry;
this.conditionEvaluator = new ConditionEvaluator(registry, environment, null);
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
public static void registerAnnotationConfigProcessors(BeanDefinitionRegistry registry) {
registerAnnotationConfigProcessors(registry, null);
这个 registerAnnotationConfigProcessors 代码过长,避免通篇都是代码,这里各位可以自己进去看看。
本文目的是分析自动装配原理,并且该原理就藏在 ConfigurationClassPostProcessor 里面,但是直接看代码找还是很难的。这里我们直接打断点分析,首先我们来到 spring-boot-autoconfigure 包下,找到 AutoConfigurationImportSelector 类,至于为什么是该类,如果你看过 @EnableAutoConfiguration 注解的话就知道了,并且 @SpringBootApplication 也包含该注解。然后你可以找到如下代码:
protected AutoConfigurationEntry getAutoConfigurationEntry(AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return EMPTY_ENTRY;
}
AnnotationAttributes attributes = getAttributes(annotationMetadata);
List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes);
configurations = removeDuplicates(configurations);
Set<String> exclusions = getExclusions(annotationMetadata, attributes);
checkExcludedClasses(configurations, exclusions);
configurations.removeAll(exclusions);
configurations = getConfigurationClassFilter().filter(configurations);
fireAutoConfigurationImportEvents(configurations, exclusions);
return new AutoConfigurationEntry(configurations, exclusions);
然后给它打上个断点,开始调试,看看是怎么跳进来的,下面只展示几个流程:
1、获取启动类 Main 方法上的 Import 注解标注的类:AutoConfigurationImportSelector.class
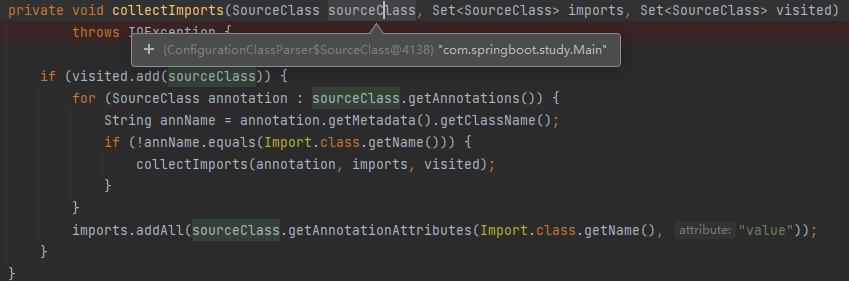
2、获取该类的 importGroup:AutoConfigurationGroup.class:
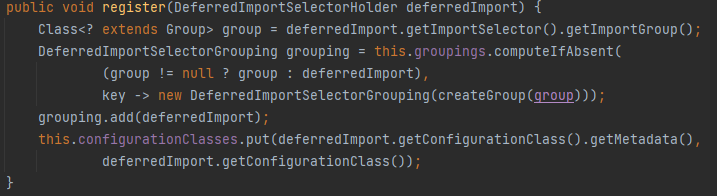
3、调用该类的 process:
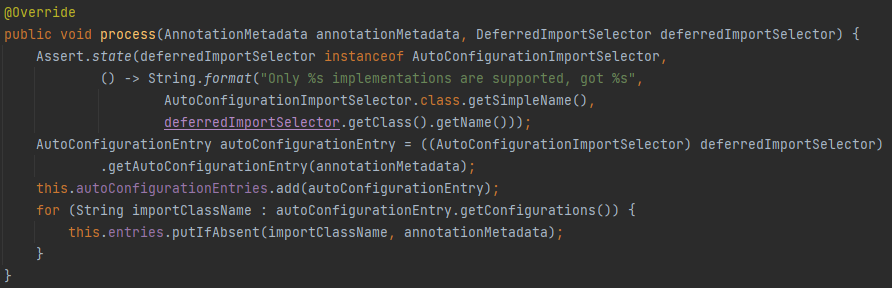
4、获取 @EnableAutoConfiguration 注解标注的类:
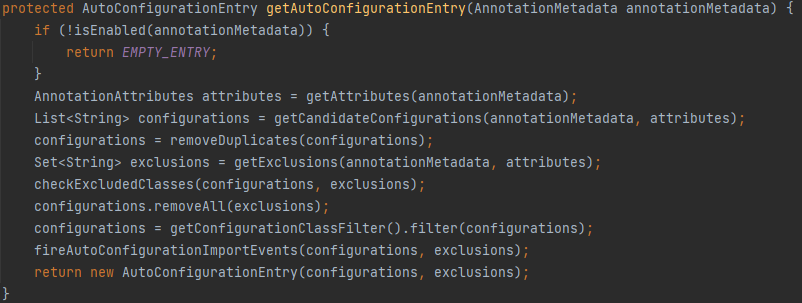
5、对 @EnableAutoConfigureation 标注的类进行处理
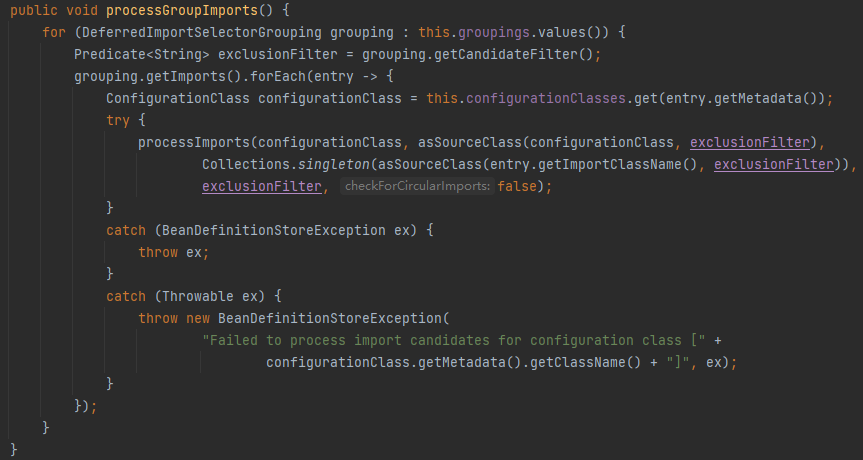
这里看 processImports 方法,从这里进去后追踪到 doProcessConfigurationClass:
protected void processConfigurationClass(ConfigurationClass configClass, Predicate<String> filter) throws IOException {
if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {
return;
}
ConfigurationClass existingClass = this.configurationClasses.get(configClass);
if (existingClass != null) {
if (configClass.isImported()) {
if (existingClass.isImported()) {
existingClass.mergeImportedBy(configClass);
}
// Otherwise ignore new imported config class; existing non-imported class overrides it.
return;
}
else {
// Explicit bean definition found, probably replacing an import.
// Let's remove the old one and go with the new one.
this.configurationClasses.remove(configClass);
this.knownSuperclasses.values().removeIf(configClass::equals);
}
}
// Recursively process the configuration class and its superclass hierarchy.
SourceClass sourceClass = asSourceClass(configClass, filter);
do {
sourceClass = doProcessConfigurationClass(configClass, sourceClass, filter);
}
while (sourceClass != null);
this.configurationClasses.put(configClass, configClass);
}
protected final SourceClass doProcessConfigurationClass(
ConfigurationClass configClass, SourceClass sourceClass, Predicate<String> filter)
throws IOException {
if (configClass.getMetadata().isAnnotated(Component.class.getName())) {
// Recursively process any member (nested) classes first
processMemberClasses(configClass, sourceClass, filter);
}
// Process any @PropertySource annotations
for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), PropertySources.class,
org.springframework.context.annotation.PropertySource.class)) {
if (this.environment instanceof ConfigurableEnvironment) {
processPropertySource(propertySource);
}
else {
logger.info("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +
"]. Reason: Environment must implement ConfigurableEnvironment");
}
}
// Process any @ComponentScan annotations
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
// Process any @Import annotations
processImports(configClass, sourceClass, getImports(sourceClass), filter, true);
// Process any @ImportResource annotations
AnnotationAttributes importResource =
AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
if (importResource != null) {
String[] resources = importResource.getStringArray("locations");
Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
configClass.addImportedResource(resolvedResource, readerClass);
}
}
// Process individual @Bean methods
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);
for (MethodMetadata methodMetadata : beanMethods) {
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
// Process default methods on interfaces
processInterfaces(configClass, sourceClass);
// Process superclass, if any
if (sourceClass.getMetadata().hasSuperClass()) {
String superclass = sourceClass.getMetadata().getSuperClassName();
if (superclass != null && !superclass.startsWith("java") &&
!this.knownSuperclasses.containsKey(superclass)) {
this.knownSuperclasses.put(superclass, configClass);
// Superclass found, return its annotation metadata and recurse
return sourceClass.getSuperClass();
}
}
// No superclass -> processing is complete
return null;
}
这里就是怎么处理这些 @EnableAutoConfigureation 标注的类,会先判断类上是否包含 Component 注解,不要仅看表面,比如 @Configuration 注解也是包含 Component 注解的。如果包含的话会扫描其内部类,递归处理。总的来说:
1、扫描内部类判断是否有资格注册为 bean。
2、如果包含 ComponentScan 等注解,会对包路径进行扫描,扫描到的注册为 bean。
3、加载 @Import 注解标注的类,判断其是否有资格注册为 bean。
4、加载 @ImportResource 标注的资源,注册为 bean。
5、加载 @Bean 注解标注的方法,注册为 bean。
6、加载接口方法、父类判断是否有资格注册为 bean。
这里说完还是比较抽象,我们不如以 mybatis-plus-boot-starter 作示例:
# Auto Configure
org.springframework.boot.env.EnvironmentPostProcessor=\
com.baomidou.mybatisplus.autoconfigure.SafetyEncryptProcessor
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.baomidou.mybatisplus.autoconfigure.IdentifierGeneratorAutoConfiguration,\
com.baomidou.mybatisplus.autoconfigure.MybatisPlusLanguageDriverAutoConfiguration,\
com.baomidou.mybatisplus.autoconfigure.MybatisPlusAutoConfiguration
以上是 mybatis-plus 的 spring.factories,可以看到 EnableAutoConfiguration 注解的内容有哪些,这里我们比较关注的应该是 MybatisPlusAutoConfiguration:
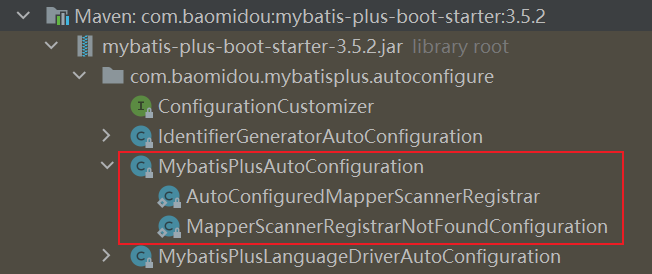
它拥有两个内部类,按顺序第一个没有 component 注解,所以不会注册为 bean,第二个有 Configuration 注解、Import 注解,并且导入的是第一个类,还有一个 Conditional 注解,也就是是否有资格注册成为 bean。

现在让我们看看执行顺序是怎么样的,让我们重新来到 doProcessConfigurationClass 方法,并且 configClass 是 MybatisPlusAutoConfiguration。
第一步会扫描到两个内部类,至于怎么处理后面再看,因为这是一个递归函数。第二步会判断该类是否包含 PropertySources 注解,这个名字一看就是处理类的属性的。第三步会判断其是否包含 ComponentScan 注解,递归扫描可被注册的类。第四步就是扫描其 Import 的类,比如这里导入的就是 AutoConfiguredMapperScannerRegistrar,但是其无法注册为 bean,因为它不包含任何可被注册为 bean 的注解。后面的就不说了。这几步流程完成后,Spring 已经注册了绝大部分的 bean 了。但是并没有发现 mybatis-plus 的 mapper bean 是什么时候注册的。
我们继续往下看:
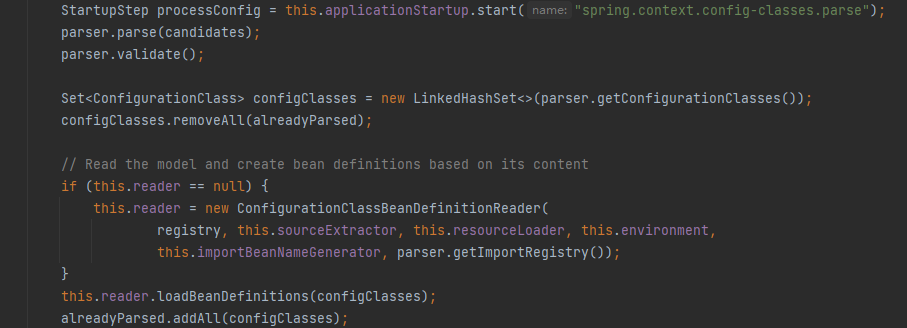
上述流程都是在 parser.parse(candidates) 中发生的,configClasses 就是我们解析到注册的 bean,接下来就看看 this.reader.loadBeanDefinitions(configClasses) 方法:
private void loadBeanDefinitionsForConfigurationClass(
ConfigurationClass configClass, TrackedConditionEvaluator trackedConditionEvaluator) {
if (trackedConditionEvaluator.shouldSkip(configClass)) {
String beanName = configClass.getBeanName();
if (StringUtils.hasLength(beanName) && this.registry.containsBeanDefinition(beanName))
this.registry.removeBeanDefinition(beanName);
}
this.importRegistry.removeImportingClass(configClass.getMetadata().getClassName());
return;
}
if (configClass.isImported()) {
registerBeanDefinitionForImportedConfigurationClass(configClass);
}
for (BeanMethod beanMethod : configClass.getBeanMethods()) {
loadBeanDefinitionsForBeanMethod(beanMethod);
}
loadBeanDefinitionsFromImportedResources(configClass.getImportedResources());
loadBeanDefinitionsFromRegistrars(configClass.getImportBeanDefinitionRegistrars());
}
private void loadBeanDefinitionsFromRegistrars(Map<ImportBeanDefinitionRegistrar, AnnotationMetadata> registrars) {
registrars.forEach((registrar, metadata) ->
registrar.registerBeanDefinitions(metadata, this.registry, this.importBeanNameGenerator));
}
这里我们直接看到最后一段代码,我们假设 configClass 是 MapperScannerRegistrarNotFoundConfiguration,那么其 registrars 就是 AutoConfiguredMapperScannerRegistrar,这里就会执行 registerBeanDefinitions 方法,该方法最后注册了一个 processor:MapperScannerConfigurer,他会扫描 @Mapper 注解的 bean。
到这里 invokeBeanDefinitionRegistryPostProcessors 的流程就介绍的差不多了,现在来看看后面的 invokeBeanFactoryPostProcessors 方法,现在主要看 ConfigurationClassPostProcessor 和 MapperScannerConfigurer 的调用。第一个其源码注释就是为 bean 创建代理子类,为 bean 的实例化作准备,而第二个确什么都没有做。那么 @Mapper 注解标注的 bean 什么时候实例化呢?这个目前不清楚什么时候调用的,不过网上搜的是在 AbstractBeanFactory 类中实例化的,关键代码如下:
// Create bean instance.
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// Explicitly remove instance from singleton cache: It might have been put there
// eagerly by the creation process, to allow for circular reference resolution.
// Also remove any beans that received a temporary reference to the bean.
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
二、registerBeanPostProcessors
该方法和上面的步骤也差不多,registerBeanPostProcessors 方法的作用是将所有的 BeanPostProcessor(后置处理器)注册到 BeanFactory 中。
三、onRefresh
该方法会创建 WebServer,没啥好说的。
四、finishBeanFactoryInitialization
finishBeanFactoryInitialization 法的作用是完成 BeanFactory 的初始化过程。在应用程序上下文启动时,会调用该方法来完成 BeanFactory 的初始化工作,包括实例化和初始化所有的非延迟加载的单例 Bean。
具体来说,finishBeanFactoryInitialization 方法会按照以下步骤完成 BeanFactory 的初始化:
- 实例化所有非延迟加载的单例 Bean:根据 Bean 定义信息,通过反射或其他方式实例化所有非延迟加载的单例 Bean,并将它们放入容器中。
- 依赖注入:对所有实例化的 Bean 进行依赖注入,即将它们所依赖的其他 Bean 注入到相应的属性中。
- 初始化:对所有实例化并注入依赖的 Bean 进行初始化。这包括调用 Bean 的初始化方法(如果有定义的话),以及应用任何配置的 Bean 后置处理器对 Bean 进行处理。
- 完成 BeanFactory 的初始化:将 BeanFactory 的状态设置为已初始化完成,标记整个初始化过程的结束。
通过调用 finishBeanFactoryInitialization 方法,Spring 容器能够确保所有非延迟加载的单例 Bean 都被正确实例化、注入依赖和初始化,从而使它们可以在应用程序中被正常使用。
五、finishRefresh
finishRefresh 方法的作用是在应用程序上下文刷新完成后执行一些额外的操作。
在应用程序上下文的刷新过程中,会调用该方法来完成一些与刷新相关的收尾工作。
具体来说,finishRefresh方法会按照以下步骤完成额外的操作:
- 初始化生命周期处理器:对于实现了 Lifecycle 接口的 Bean,会调用它们的 start 方法来启动这些 Bean。
- 发布应用程序上下文已完成事件:通过 ApplicationEventPublisher,发布一个 ContextRefreshedEvent 事件,通知其他监听器应用程序上下文已完成刷新。
- 注册 ApplicationListener 的 Bean:将实现了 ApplicationListener 接口的 Bean 注册到应用程序上下文中,以便监听其他事件。
- 初始化其他单例 Bean:对于非延迟加载的单例 Bean,会调用它们的初始化方法(如果有定义的话)。
- 发布应用程序上下文已启动事件:通过 ApplicationEventPublisher,发布一个 ContextStartedEvent 事件,通知其他监听器应用程序上下文已启动。
通过调用finishRefresh方法,Spring容器能够在应用程序上下文刷新完成后执行一些额外的操作,如启动生命周期处理器、发布事件等。这些操作可以用于执行一些初始化、通知或其他自定义的逻辑,以满足特定的需求。
6、总结
refresh 方法感觉还是比较难以分析,后面部分文字内容还是借鉴了 ChatGPT,感觉如果你想知道某个函数的作用时,直接问它,它或许会告诉你正确答案,比如你这样问:finishRefresh 方法的作用是啥?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号