

第 1 章 Prometheus入门
Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在Soundcloud以开源软件的形式进行研发,并且于2015年早期对外发布早期版本。
2016年5月继Kubernetes之后成为第二个正式加入CNCF基金会的项目,同年6月正式发布1.0版本。2017年底发布了基于全新存储层的2.0版本,能更好地与容器平台、云平台配合。
Prometheus作为新一代的云原生监控系统,目前已经有超过650+位贡献者参与到Prometheus的研发工作上,并且超过120+项的第三方集成。
1.1 Prometheus的特点
Prometheus是一个开源的完整监控解决方案,其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。 相比于传统监控系统Prometheus具有以下优点:
1)易于使用管理
(1)Prometheus核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(数据库,缓存等等)。唯一需要的就是本地磁盘,因此不会有潜在级联故障的风险。
(2)Prometheus基于Pull模型的架构方式,可以在任何地方(本地电脑,开发环境,测试环境)搭建我们的监控系统。
(3)对于一些复杂的情况,还可以使用Prometheus服务发现(Service Discovery)的能力动态管理监控目标。
2)监控服务的内部运行状态
Pometheus鼓励用户监控服务的内部状态,基于Prometheus丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获取服务和应用内部真正的运行状态。
3)强大的数据模型
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB)。所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签。如下所示:
http_request_status{code='200',content_path='/api/path',environment='produment'} => [value1@timestamp1,value2@timestamp2...]
http_request_status{code='200',content_path='/api/path2',environment='produment'} => [value1@timestamp1,value2@timestamp2...]
每一条时间序列由指标名称(Metrics Name)以及一组标签(Labels)唯一标识。每条时间序列按照时间的先后顺序存储一系列的样本值。
(1)http_request_status:指标名称(Metrics Name)
(2){code='200',content_path='/api/path',environment='produment'}:表示维度的标签,基于这些Labels我们可以方便地对监控数据进行聚合,过滤,裁剪。
(3)[value1@timestamp1,value2@timestamp2...]:按照时间的先后顺序 存储的样本值。
4)强大的查询语言PromQL
Prometheus内置了一个强大的数据查询语言PromQL。 通过PromQL可以实现对监控数据的、聚查询合。同时PromQL也被应用于数据可视化(如Grafana)以及告警当中。
通过PromQL可以轻松回答类似于以下问题:
(1)在过去一段时间中95%应用延迟时间的分布范围?
(2)预测在4小时后,磁盘空间占用大致会是什么情况?
(3)CPU占用率前5位的服务有哪些?(过滤)
5)高效
对于监控系统而言,大量的监控任务必然导致有大量的数据产生。而Prometheus可以高效地处理这些数据,对于单一Prometheus Server实例而言它可以处理:
(1)数以百万的监控指标
(2)每秒处理数十万的数据点
6)可扩展
可以在每个数据中心、每个团队运行独立的Prometheus Sevrer。Prometheus对于联邦集群的支持,可以让多个Prometheus实例产生一个逻辑集群,当单实例Prometheus Server处理的任务量过大时,通过使用功能分区(sharding)+联邦集群(federation)可以对其进行扩展。
7)易于集成
使用Prometheus可以快速搭建监控服务,并且可以非常方便地在应用程序中进行集成。目前支持:Java,JMX,Python,Go,Ruby,.Net,Node.js等等语言的客户端SDK,基于这些SDK可以快速让应用程序纳入到 Prometheus的监控当中,或者开发自己的监控数据收集程序。同时这些客户端收集的监控数据,不仅仅支持 Prometheus,还能支持Graphite这些其他的监控工具。同时Prometheus还支持与其他的监控系统进行集成:Graphite, Statsd, Collected, Scollector, muini, Nagios等。 Prometheus社区还提供了大量第三方实现的监控数据采集支持:JMX,CloudWatch,EC2,MySQL,PostgresSQL,Haskell,Bash,SNMP,Consul,Haproxy,Mesos,Bind,CouchDB,Django,Memcached,RabbitMQ,Redis,RethinkDB,Rsyslog等等。
8)可视化
Prometheus Server中自带的Prometheus UI,可以方便地直接对数据进行查询,并且支持直接以图形化的形式展示数据。同时Prometheus还提供了一个独立的基于Ruby On Rails的Dashboard解决方案 Promdash。
最新的Grafana可视化工具也已经提供了完整的Prometheus支持,基于Grafana可以创建更加精美的监控图标。基于Prometheus提供的API还可以实现自己的监控可视化UI。
9)开放性
通常来说当我们需要监控一个应用程序时,一般需要该应用程序提供对相应监控系统协议的支持,因此应用程序会与所选择的监控系统进行绑定。为了减少这种绑定所带来的限制,对于决策者而言要么你就直接在应用中集成该监控系统的支持,要么就在外部创建单独的服务来适配不同的监控系统。
而对于Prometheus来说,使用Prometheus的client library的输出格式不止支持Prometheus的格式化数据,也可以输出支持其它监控系统的格式化数据,比如Graphite。 因此你甚至可以在不使用Prometheus的情况下,采用Prometheus的client library来让你的应用程序支持监控数据采集。
1.2 Prometheus的架构
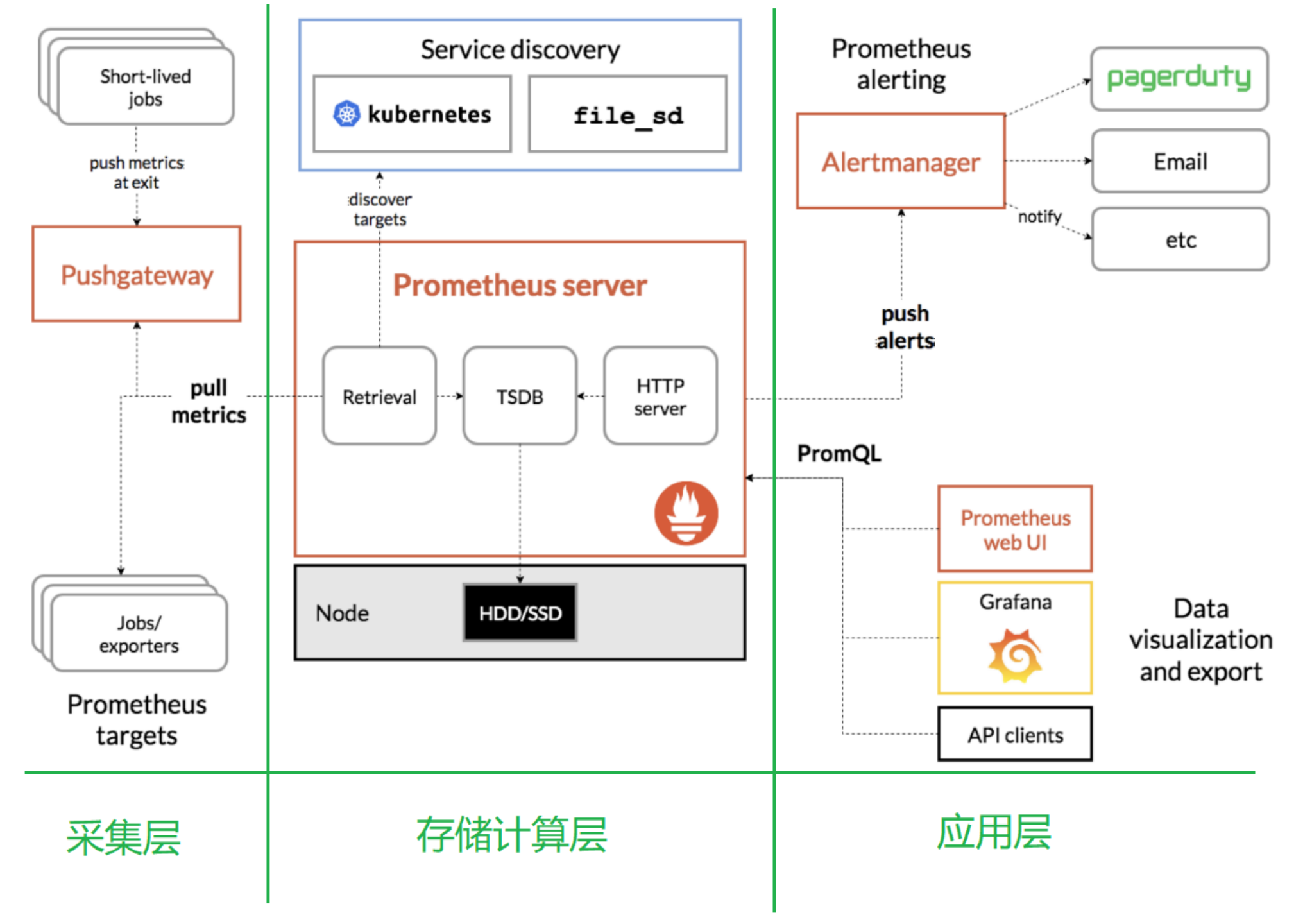
2.1 采集层
采集层分为两类,一类是生命周期较短的作业,还有一类是生命周期较长的作业。
1)短作业:直接通过API,在退出时间指标推送给Pushgateway。
2)长作业:Retrieval组件直接从Job或者Exporter拉取数据。
3)Prometheus Server,里面包含了存储引擎和计算引擎。
4)Retrieval组件为取数组件,它会主动从Pushgateway或者Exporter拉取指标数据。
5)Service discovery,可以动态发现要监控的目标。
6)TSDB,数据核心存储与查询。
7)HTTP server,对外提供HTTP服务。
2.2 存储计算层
2.3 应用层
应用层主要分为两种,一种是AlertManager,另一种是数据可视化。
1)AlertManager
对接Pagerduty,是一套付费的监控报警系统。可实现短信报警、5分钟无人ack打电话通知、仍然无人ack,通知值班人员Manager,Emial,发送邮件
2)数据可视化
(1)Prometheus build-in WebUI
(2)Grafana
(3)其他基于API开发的客户端
第 2 章 Prometheus的安装
下载地址:https://prometheus.io/download/
2.1 安装和配置Pushgateway
Prometheus在正常情况下是采用拉模式从产生metric的作业或者exporter(比如专门监控主机的NodeExporter)拉取监控数据。但是我们要监控的是Flink on YARN作业,想要让Prometheus自动发现作业的提交、结束以及自动拉取数据显然是比较困难的。
PushGateway就是一个中转组件,通过配置Flink on YARN作业将metric推到PushGateway,Prometheus再从PushGateway拉取就可以了。
2.2.1 解压
tar -zxvf /opt/software/monitor/pushgateway-1.4.0.linux-amd64.tar.gz -C /opt/module/
2.2.2 修改目录
cd /opt/module
mv pushgateway-1.4.0.linux-amd64 pushgateway-1.4.0
2.2.3 启动Pushgateway
nohup /opt/module/pushgateway-1.4.0/pushgateway --web.listen-address 0.0.0.0:9091 >/opt/module/pushgateway-1.4.0/pushgateway.log 2>&1 &
2.2.4 查看webui:http://hadoop164:9091/#
2.2 安装Node Explorer
在Prometheus的架构设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的收集,存储并且对外提供数据查询支持。因此为了能够能够监控到某些东西,如主机的CPU使用率,我们需要使用到Exporter。Prometheus周期性的从Exporter暴露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
Exporter可以是一个相对开放的概念,其可以是一个独立运行的程序独立于监控目标以外,也可以是直接内置在监控目标中。只要能够向Prometheus提供标准格式的监控样本数据即可。
为了能够采集到主机的运行指标如CPU, 内存,磁盘等信息。我们可以使用Node Exporter。Node Exporter同样采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。可以从https://prometheus.io/download/ 获取最新的node exporter版本的二进制包。
2.2.1 解压
tar -zxvf /opt/software/monitor/node_exporter-1.1.2.linux-amd64.tar.gz -C /opt/module/
2.2.2 修改目录
cd /opt/module
mv node_exporter-1.1.2.linux-amd64 node_exporter-1.1.2
2.2.3 分发到其他节点
cd /opt/module
xsync node_exporter-1.1.2/
2.2.4 三台节点启动Node Explorer
xcall "nohup /opt/module/node_exporter-1.1.2/node_exporter >node.log 2>&1 &"
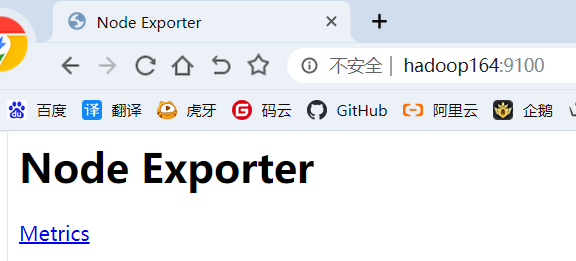
2.2.5 webui查看启动情况
2.3 Prometheus Server
Prometheus基于Golang编写,编译后的软件包,不依赖于任何的第三方依赖。只需要下载对应平台的二进制包,解压并且添加基本的配置即可正常启动Prometheus Server。
2.3.1 解压
tar -zxvf /opt/software/monitor/prometheus-2.26.0.linux-amd64.tar.gz -C /opt/module/
2.3.2 修改目录名
cd /opt/module
mv prometheus-2.26.0.linux-amd64 prometheus-2.26.0
2.3.3 修改配置文件 prometheus.yml
vim /opt/module/prometheus-2.26.0/prometheus.yml
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['hadoop164:9090'] # 添加 PushGateway 监控配置 - job_name: 'pushgateway' static_configs: - targets: ['hadoop164:9091'] labels: instance: pushgateway # 添加 Node Exporter 监控配置 - job_name: 'node exporter' static_configs: - targets: ['hadoop162:9100', 'hadoop163:9100', 'hadoop164:9100'] labels: instance: node exporter
配置说明:
(1)global配置块:控制Prometheus服务器的全局配置
(2)scrape_interval:配置拉取数据的时间间隔,默认为1分钟。
(3)evaluation_interval:规则验证(生成alert)的时间间隔,默认为1分钟。
(4)rule_files配置块:规则配置文件
(5)scrape_configs配置块:配置采集目标相关, prometheus监视的目标。Prometheus自身的运行信息可以通过HTTP访问,所以Prometheus可以监控自己的运行数据。
(6)job_name:监控作业的名称
(7)static_configs:表示静态目标配置,就是固定从某个target拉取数据
(8)targets:指定监控的目标,其实就是从哪儿拉取数据。Prometheus会从http://hadoop1:9090/metrics上拉取数据。
2.3.4 启动Prometheus
nohup /opt/module/prometheus-2.26.0/prometheus --config.file=prometheus.yml > /opt/module/prometheus-2.26.0/prometheus.log 2>&1 &
2.3.5 webui查看启动情况
1)浏览器输入:http://hadoop164:9090/
2)选择Status -> Targets
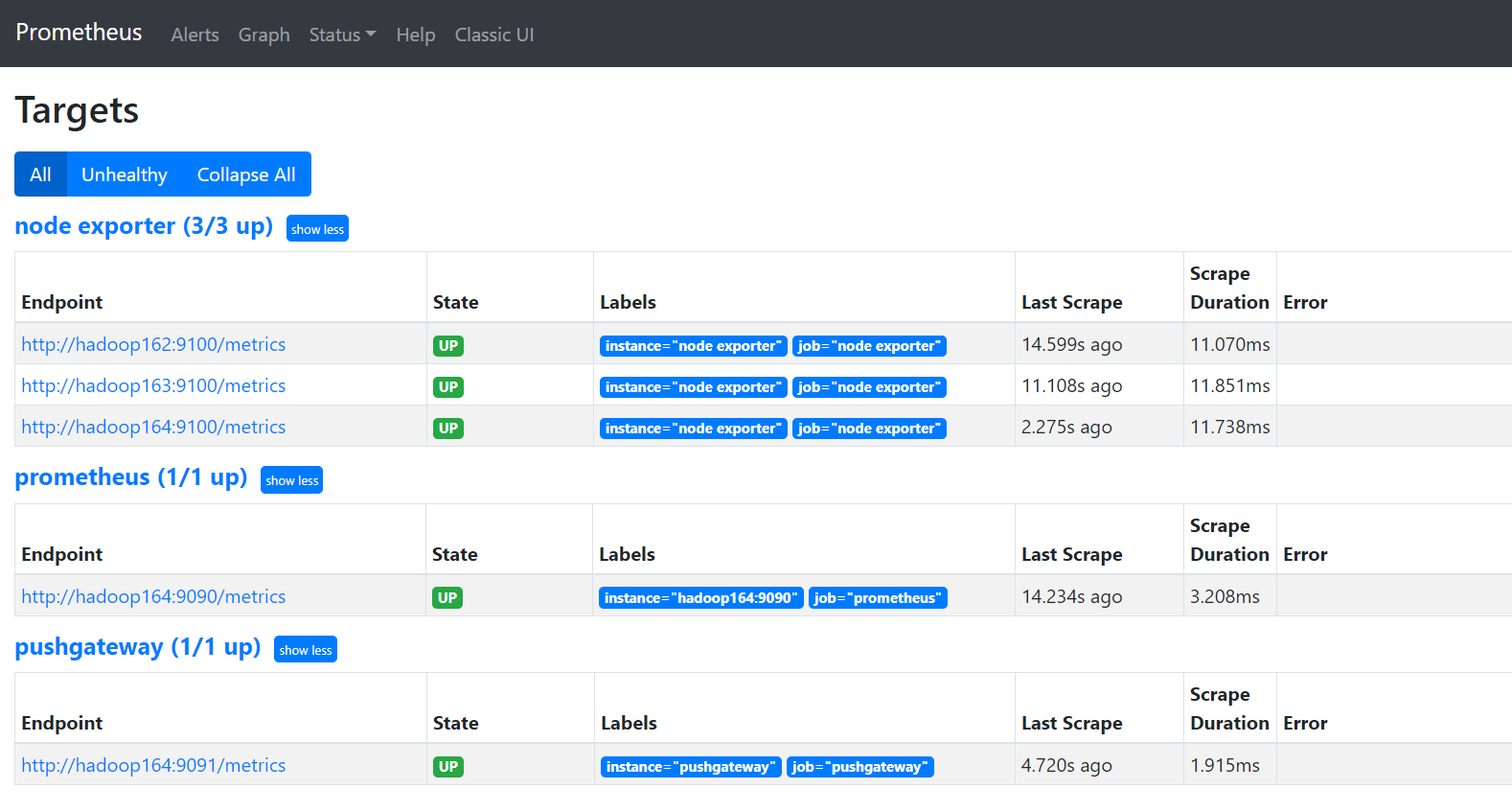
3)prometheus、pushgateway和node exporter都是up状态,表示安装启动成功
第 3 章 Flink集成Prometheus
Flink 提供的 Metrics 可以在 Flink 内部收集一些指标,通过这些指标让开发人员更好地理解作业或集群的状态。由于集群运行后很难发现内部的实际状况,跑得慢或快,是否异常等,开发人员无法实时查看所有的 Task 日志。比如作业很大或者有很多作业的情况下,该如何处理?此时 Metrics 可以很好的帮助开发人员了解作业的当前状况。
从Flink的源码结构我们可以看到,Flink官方支持Prometheus,并且提供了对接Prometheus的jar包,很方便就可以集成。
3.1 copy jar到flink的lib目录下
cd /opt/module/flink-yarn
cp plugins/metrics-prometheus/flink-metrics-prometheus-1.13.1.jar ./lib
3.2 修改flink配置
cd /opt/module/flink-yarn/conf
vim flink-conf.yaml
#添加如下配置与Prometheus集成 ##### 与Prometheus集成配置 ##### metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter # PushGateway的主机名与端口号 metrics.reporter.promgateway.host: hadoop164 metrics.reporter.promgateway.port: 9091 # Flink metric在前端展示的标签(前缀)与随机后缀 metrics.reporter.promgateway.jobName: flink-metrics metrics.reporter.promgateway.randomJobNameSuffix: true metrics.reporter.promgateway.deleteOnShutdown: false
3.3 运行一个Flink Job
/opt/module/flink-yarn/bin/yarn-session.sh -d
/opt/module/flink-yarn/bin/flink run -c com.yuange.flinkrealtime.app.dwd.DwdLogApp /opt/module/applog/flink-realtime-1.0-SNAPSHOT.jar
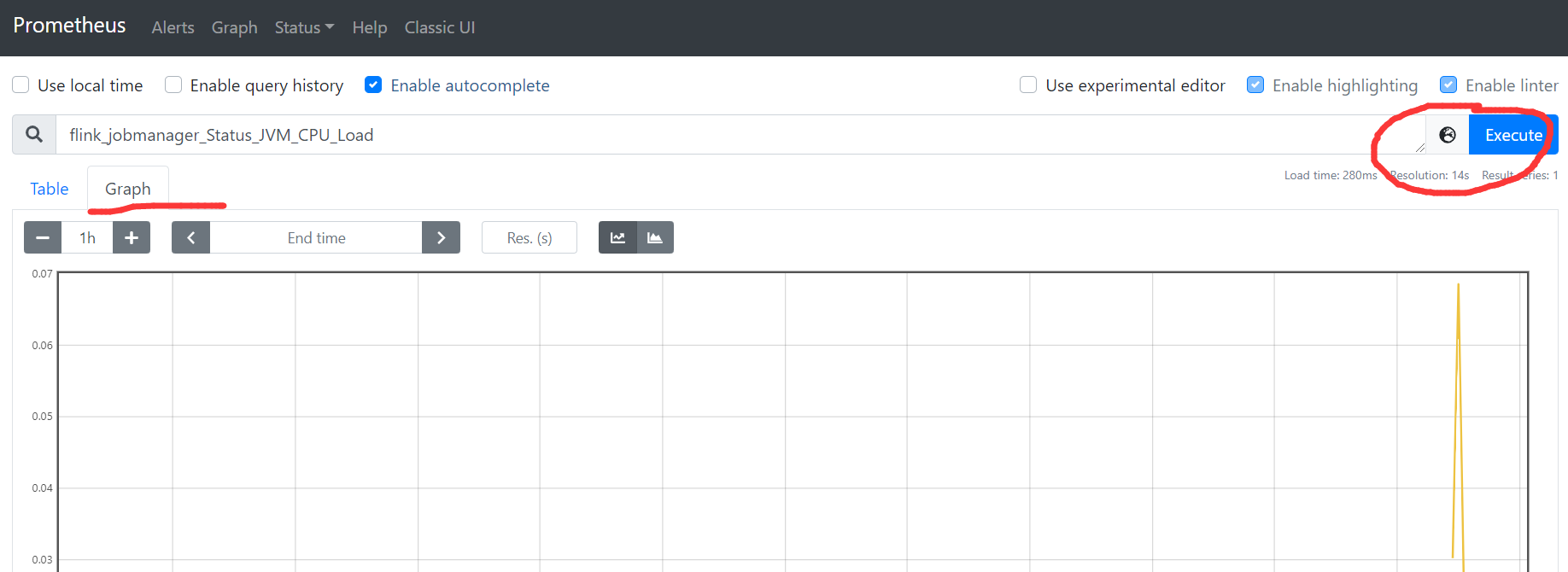
3.4 在Prometheus ui监控Flink Job
1)浏览器输入: http://hadoop164:9090/
2)选择一个要监控的flink指标

3)点击执行
第 4 章 Prometheus集成Grafana
4.1 为什么需要集成Granfana
1)Prometheus自带的ui图形不够丰富
2)Prometheus自带的ui设置不能保存
3)Prometheus自带ui不支持自动刷新
4)Granfana ui更真丰富
5)Granfana ui 的设置能保存, 下次直接打开就可以查看
6)Granfana 在ui展示更专业和酷炫
4.2 安装和配置Granfana
4.2.1 下载Grafana安装包
官方仓库:https://dl.grafana.com/oss/release/grafana-7.4.3-1.x86_64.rpm
国内镜像:https://repo.huaweicloud.com/grafana/7.4.3/grafana-7.4.3-1.x86_64.rpm
wget https://repo.huaweicloud.com/grafana/7.4.3/grafana-7.4.3-1.x86_64.rpm -P /opt/software
4.2.2 安装Grafana
1)如果是使用的docker容器需要安装下面的依赖(如果是虚拟机跳过这个步骤)
sudo yum install -y /sbin/service fontconfig freetype urw-fonts
2)安装Granfana
sudo rpm -ivh /opt/software/grafana-7.4.3-1.x86_64.rpm
4.2.3 启动Grafana
sudo systemctl start grafana-server
4.2.4 访问Grafana web ui
1)地址:http://hadoop164:3000/login
2)默认用户名和免密都是admin
4.3 添加数据源Prometheus
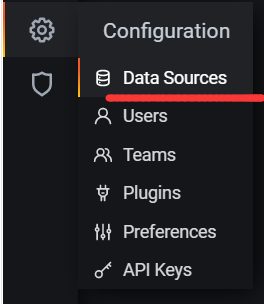
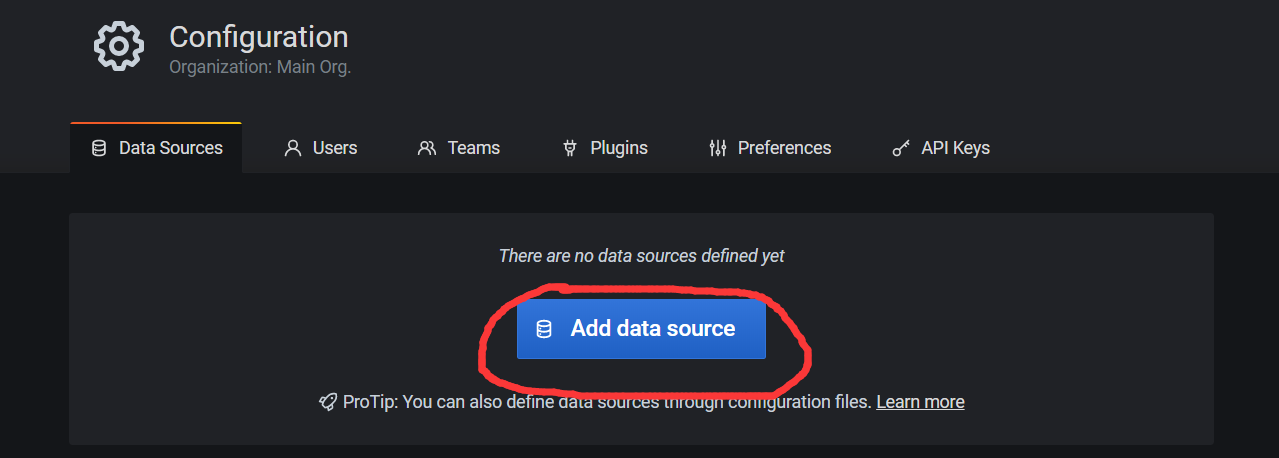
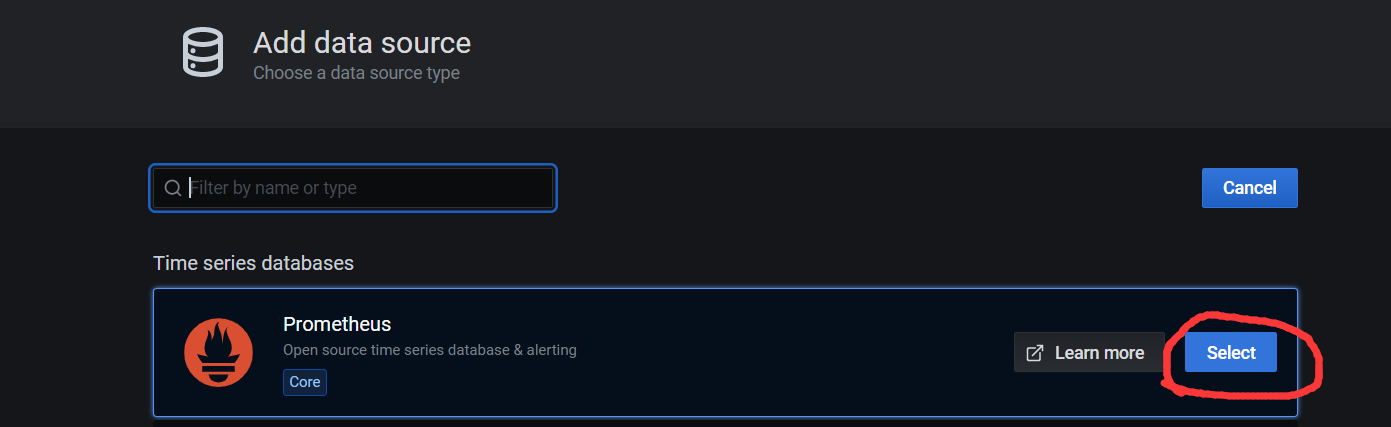
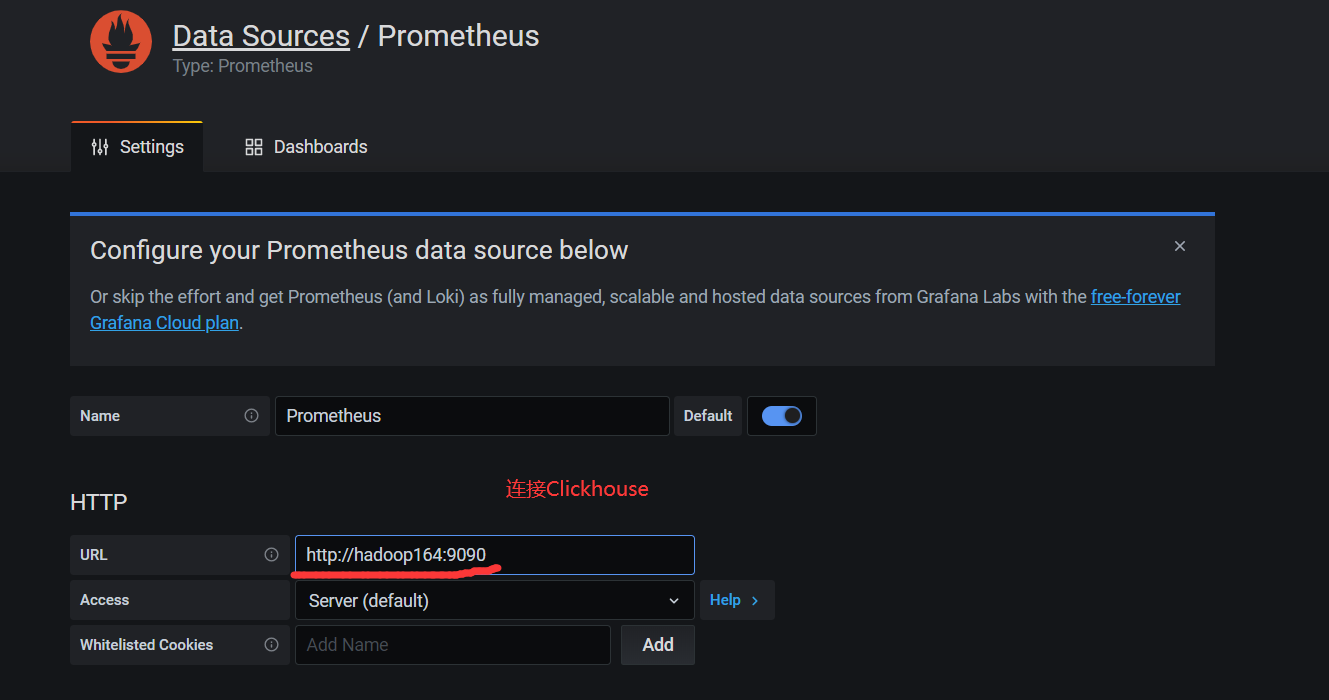

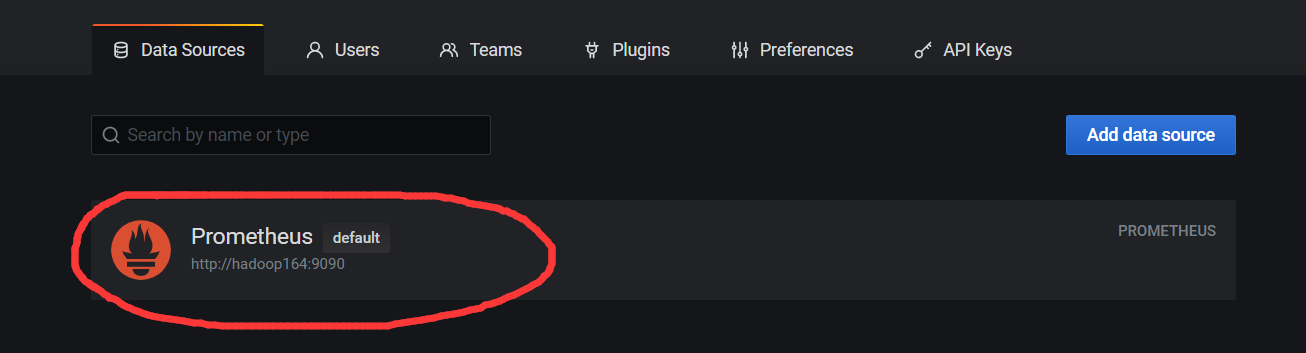
点击DataSource, 可以看到出现了Prometheus
4.4 手动添加DashBoard
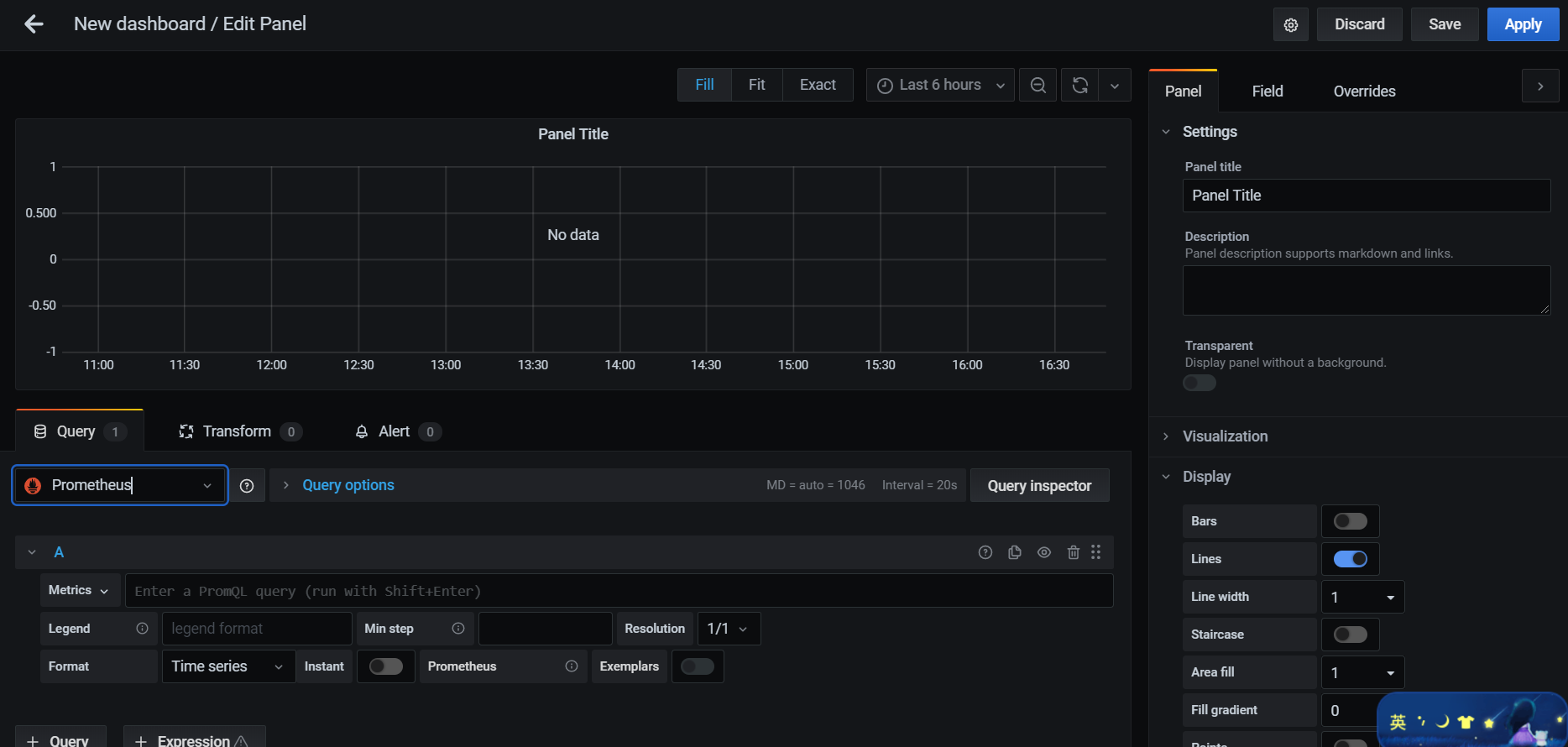
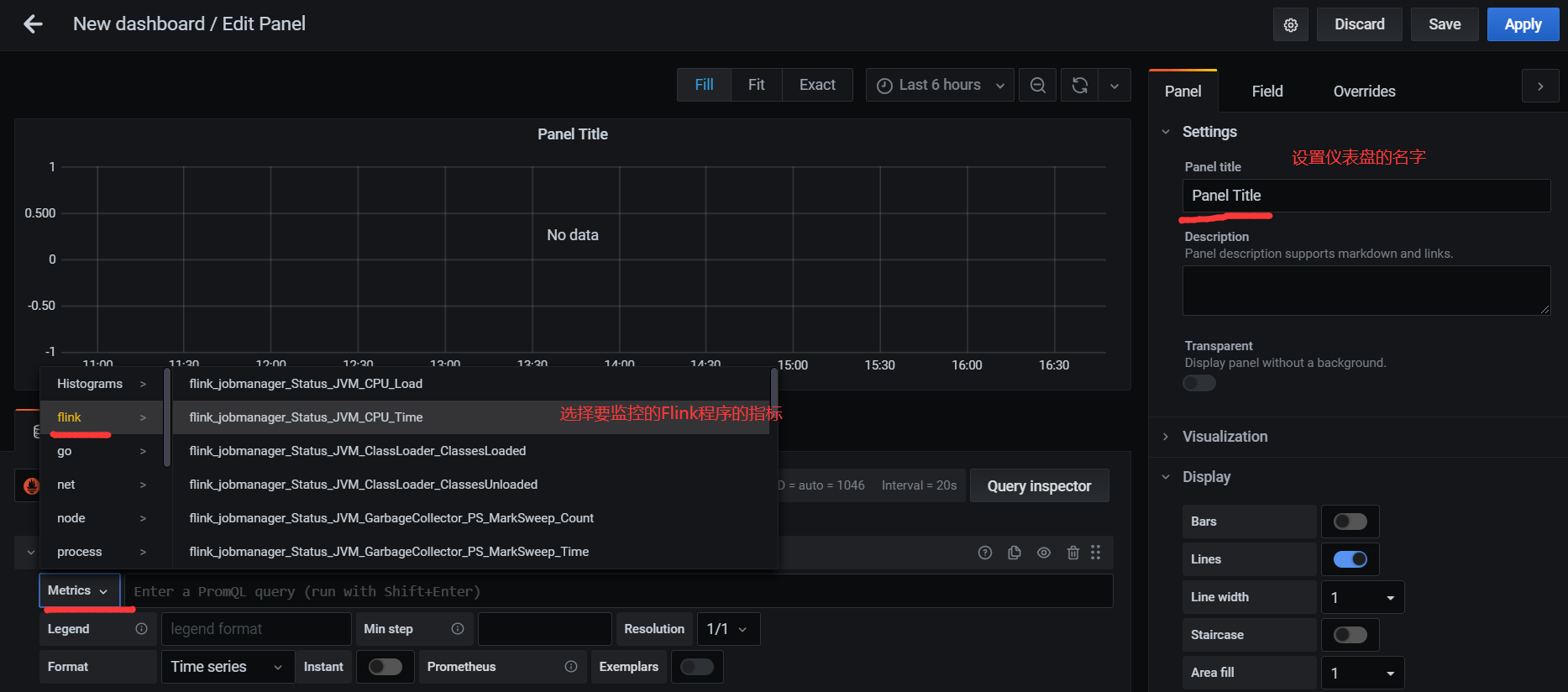
配置仪表监控项
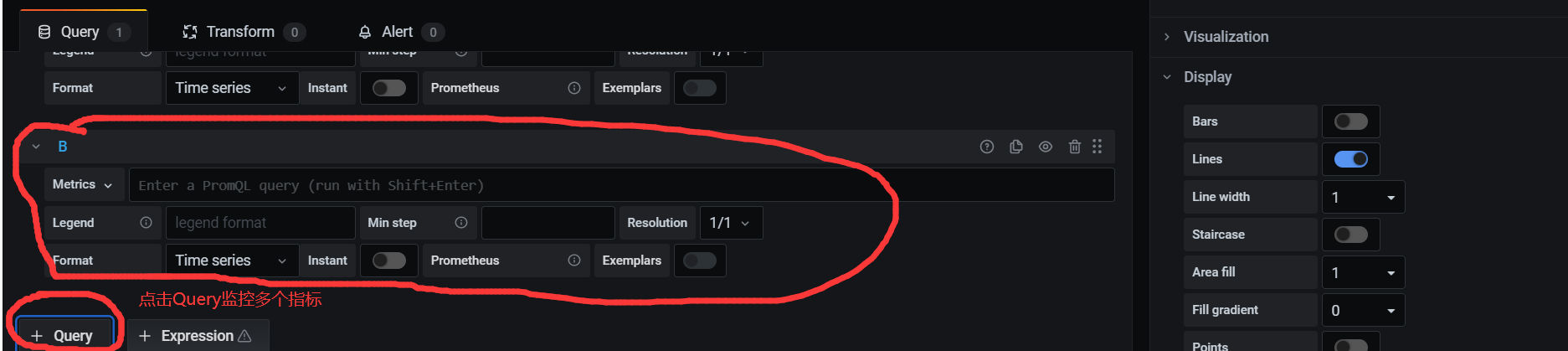
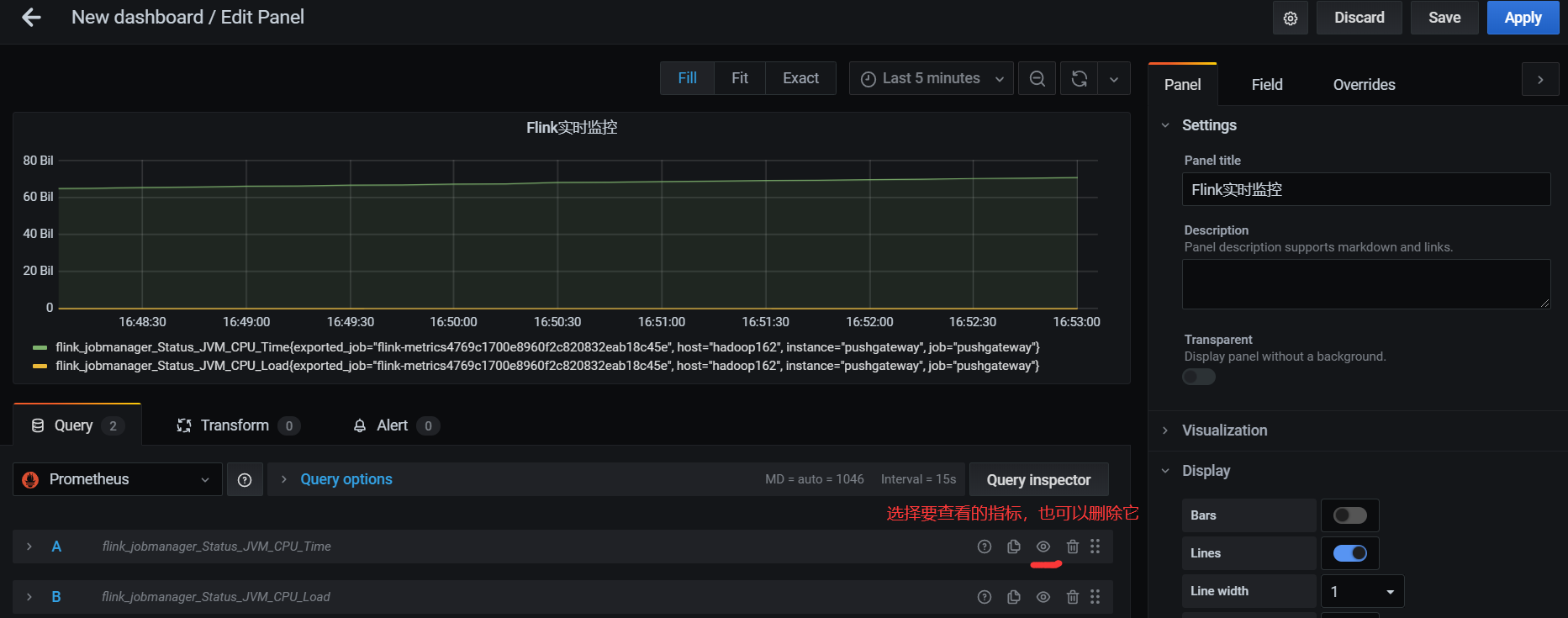
监控多个指标
4.5 直接添加Flink模板
手动一个个添加Dashboard比较繁琐,Grafana社区鼓励用户分享Dashboard,通过https://grafana.com/dashboards网站,可以找到大量可直接使用的Dashboard模板。Grafana中所有的Dashboard通过JSON进行共享,下载并且导入这些JSON文件,就可以直接使用这些已经定义好的Dashboard:
1)进入官网,搜索Flink模板:
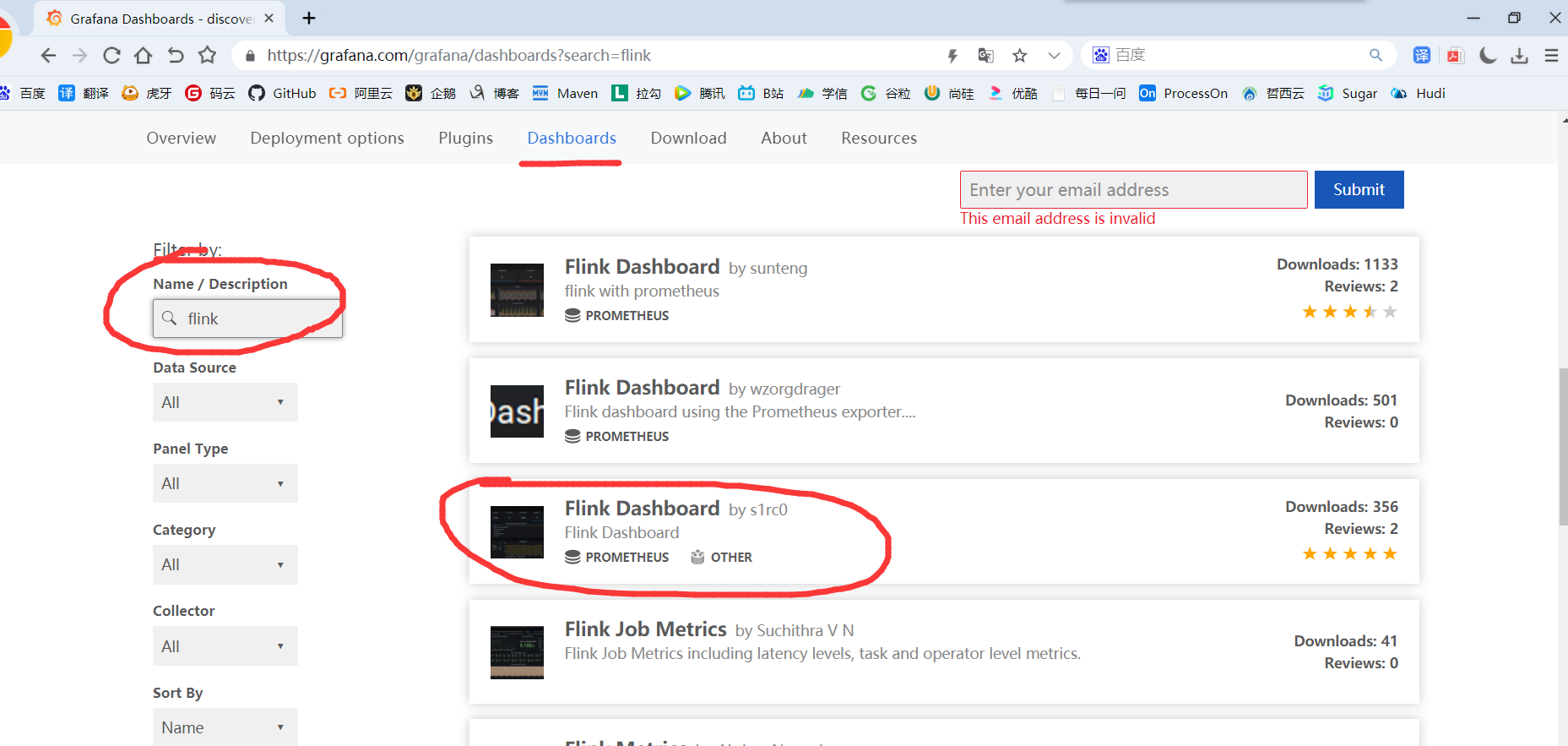
2)选择自己喜欢的模板(800+下载的这个模板相对指标较多)
3)选中跳转页面后,点击 Download JSON:
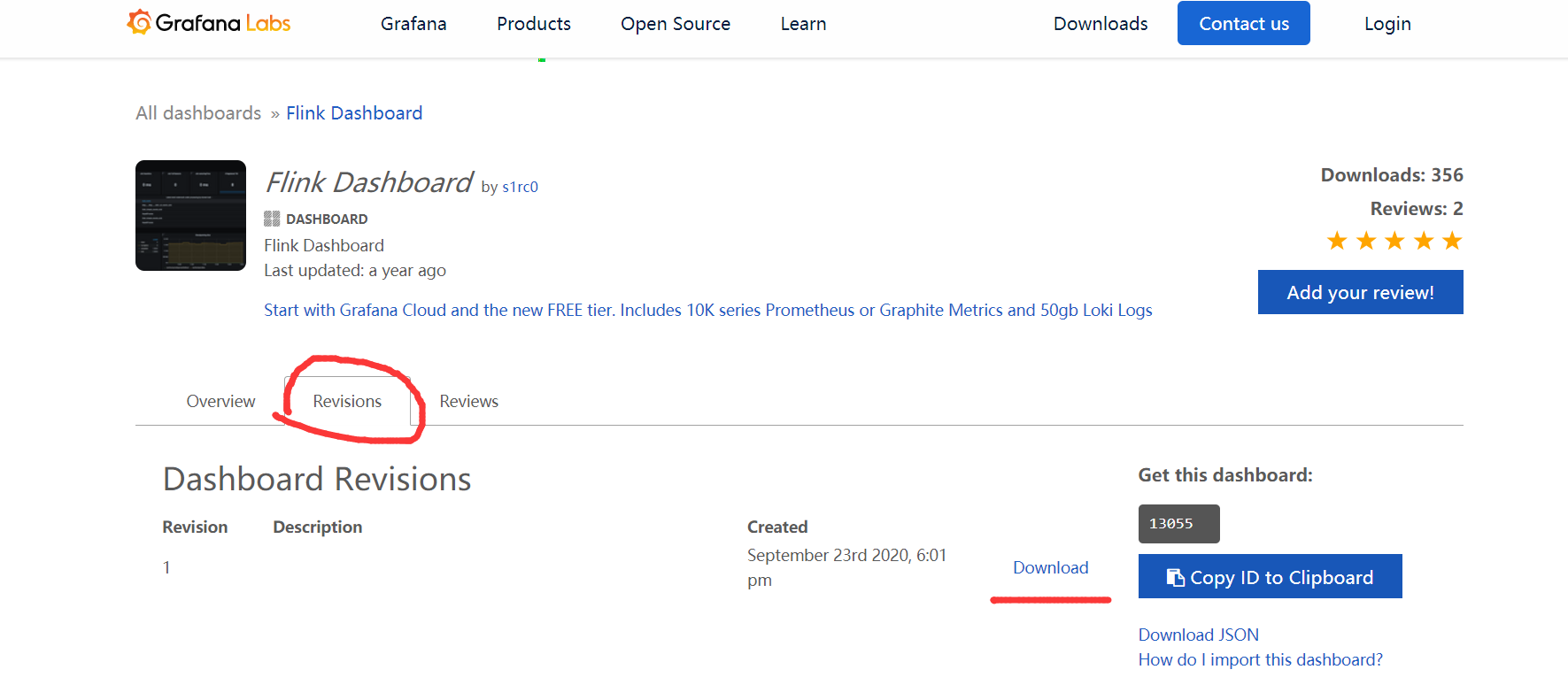
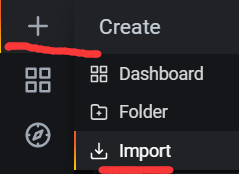
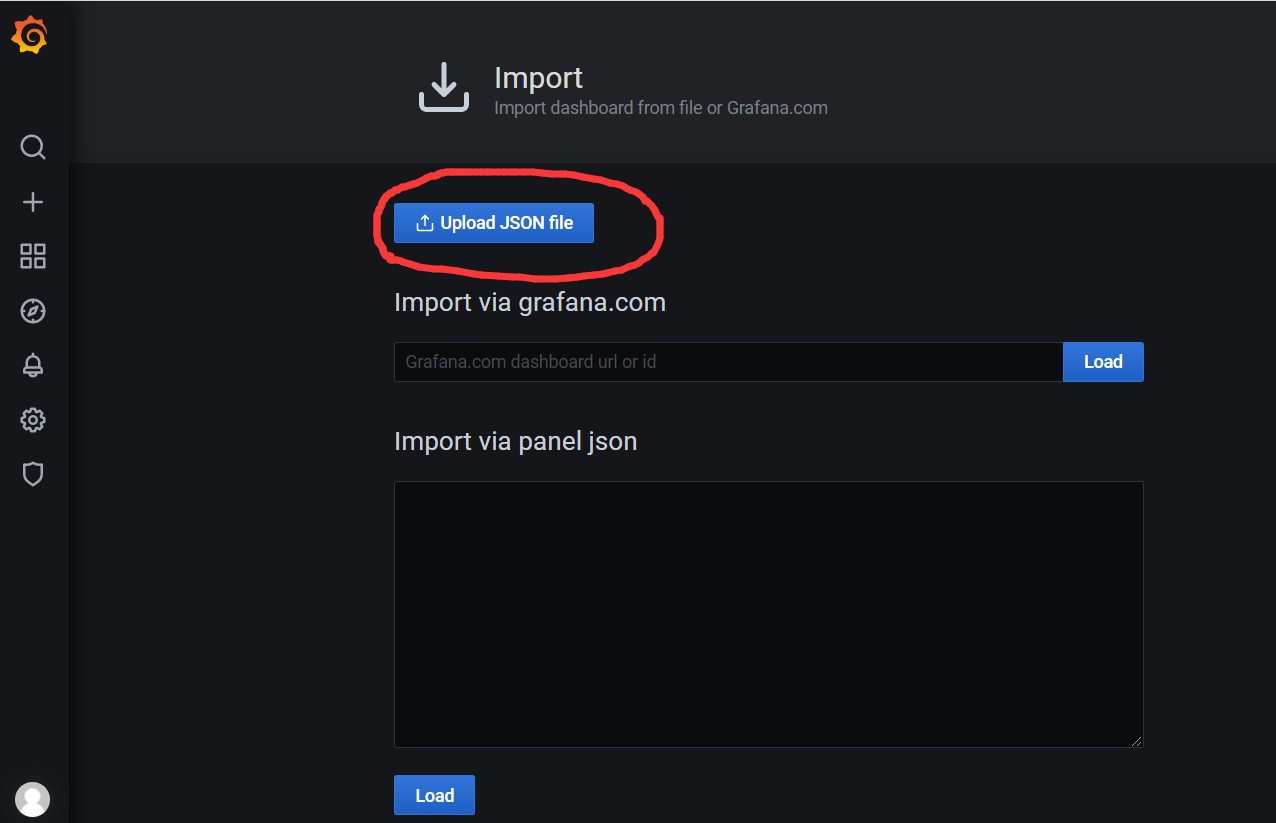
4)上次json文件
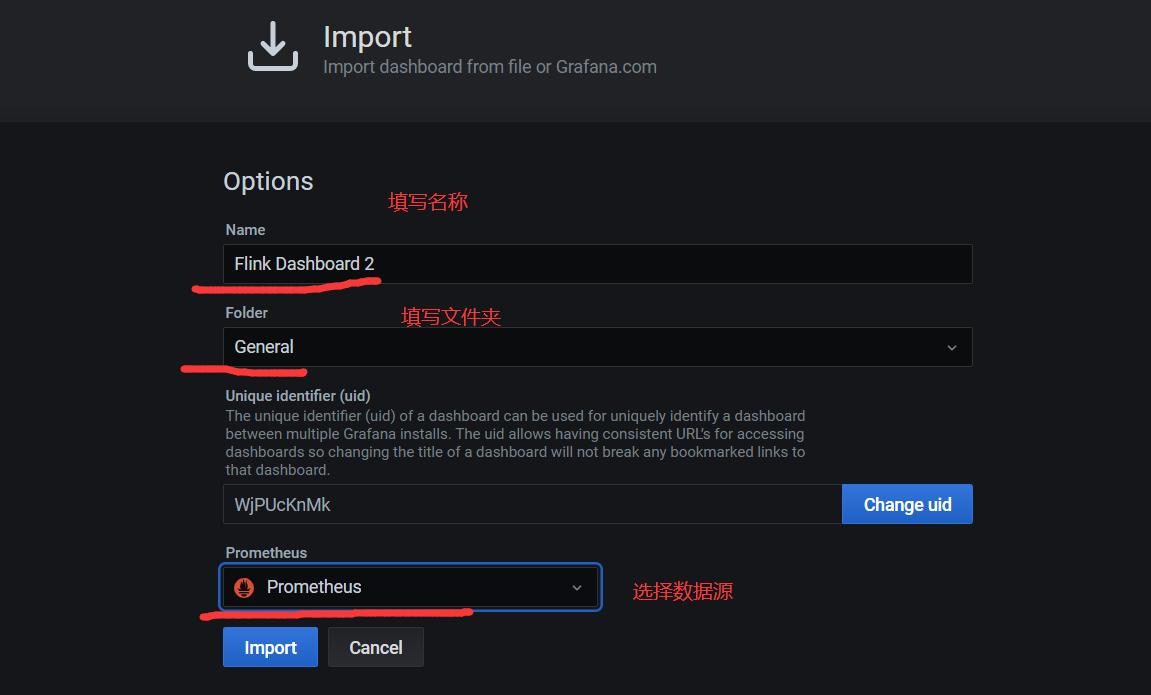
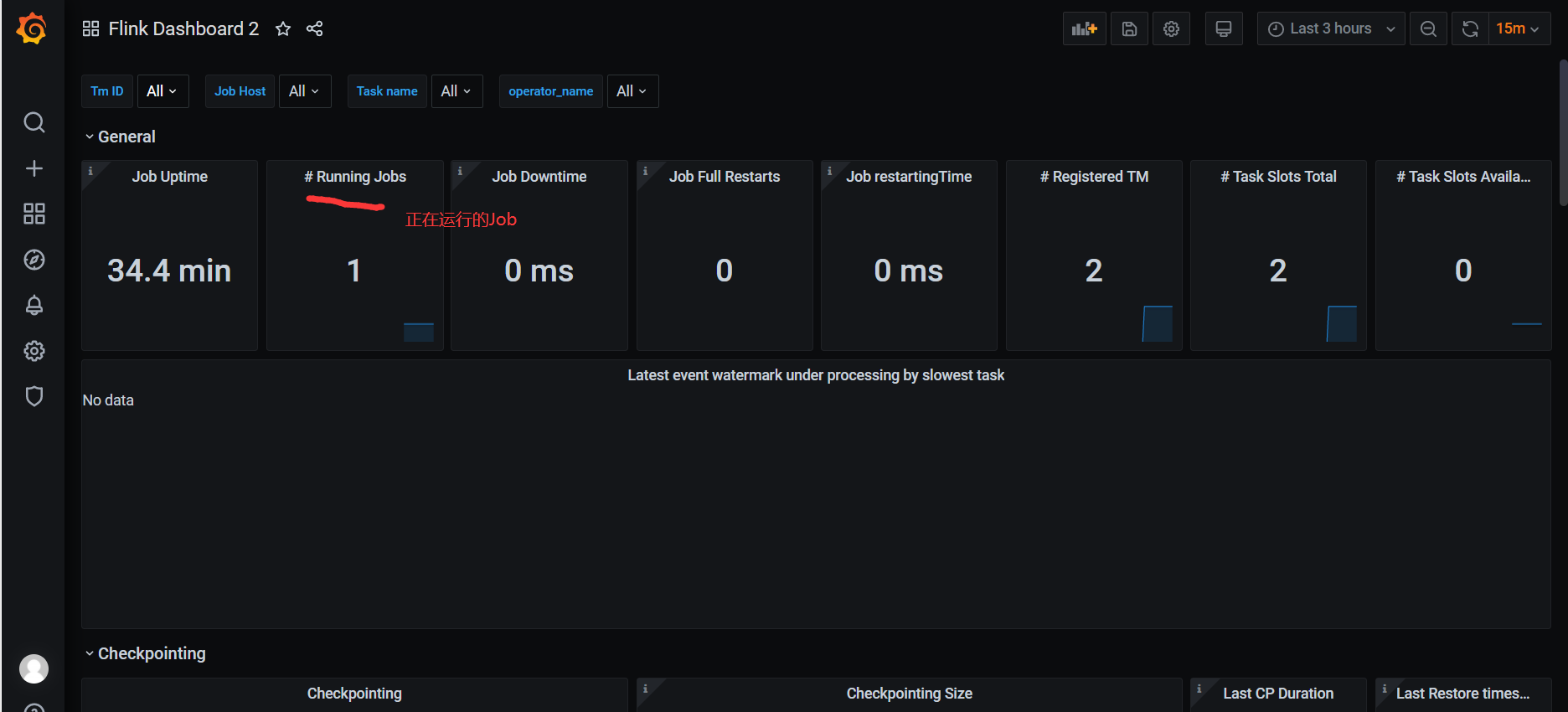
5)正常提交job,即可在grafana看到相关监控项的情况。
6)代码里env.execute(“作业名”),最好指定不同的作业名用于区分,不指定会使用默认的作业名:Flink Streaming Job,在Grafana页面就无法区分不同job!!!
4.6 添加Node Exporter模板
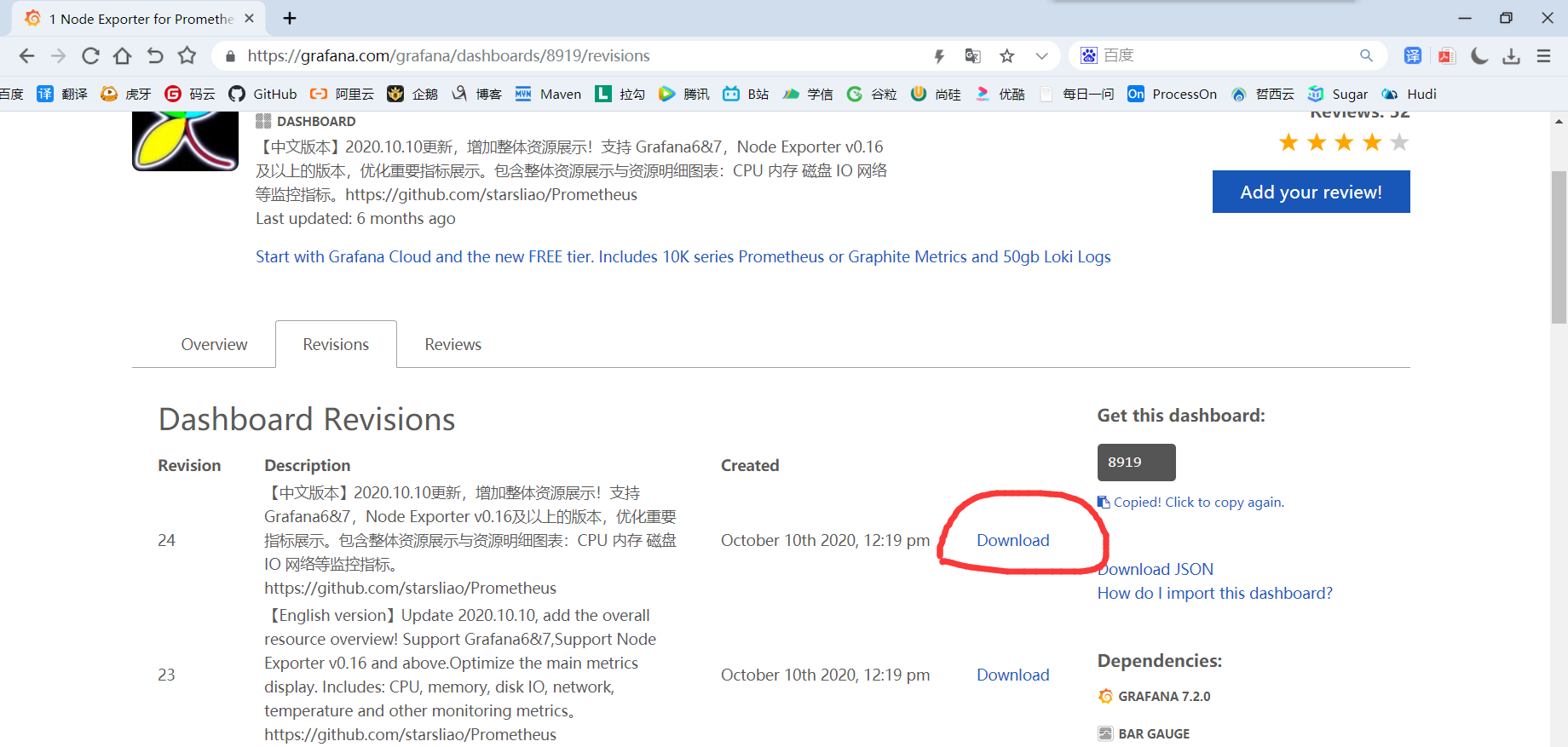
1)使用这个比较酷炫的模板: https://grafana.com/grafana/dashboards/8919
2)复制下载链接
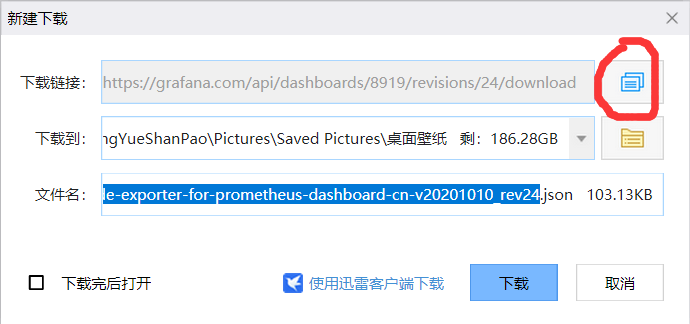
3)导入模板
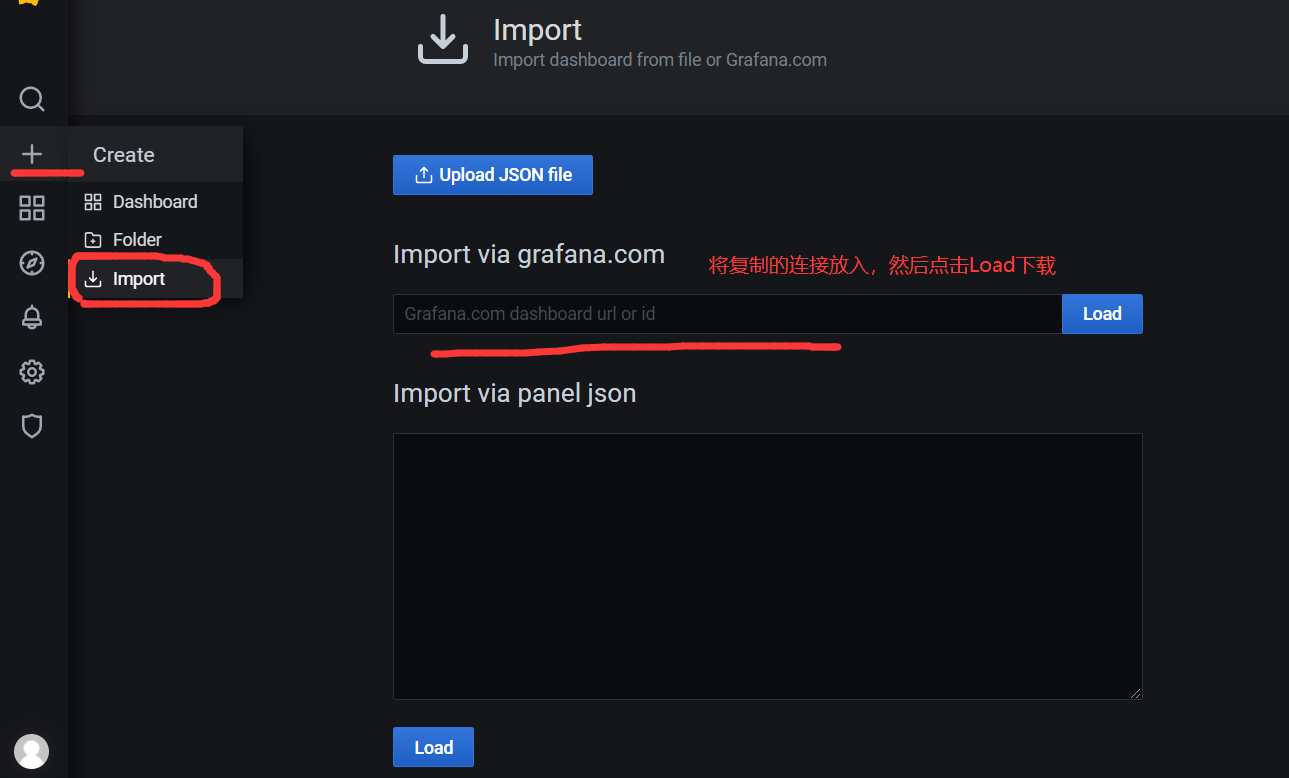
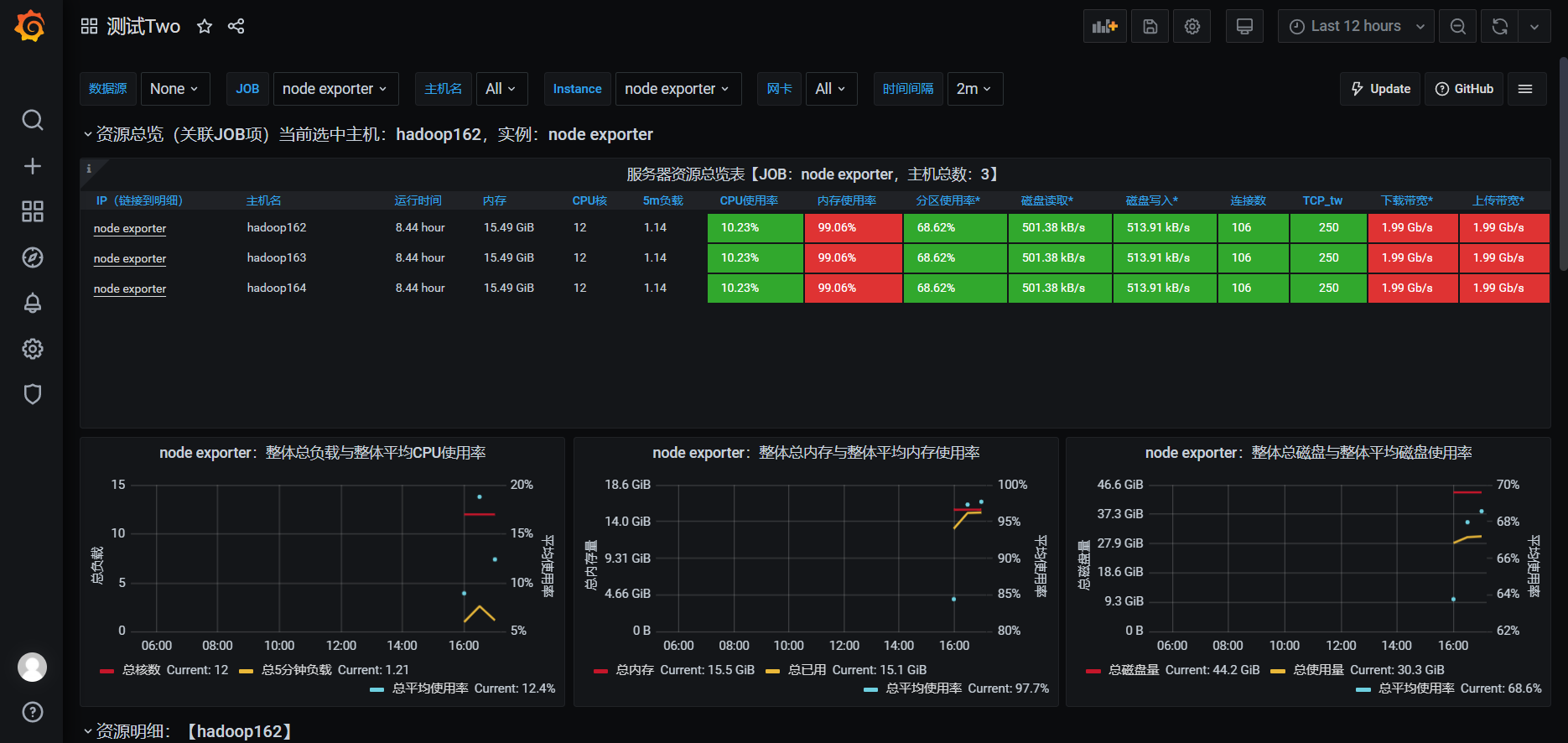
4)查看效果图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号