

第1章 Azkaban概论
1.1 为什么需要工作流调度系统
1)一个完整的数据分析系统通常都是由大量任务单元组成:
Shell脚本程序,Java程序,MapReduce程序、Hive脚本等
2)各任务单元之间存在时间先后及前后依赖关系
3)为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;

1.2 常见工作流调度系统
1)简单的任务调度:直接使用Linux的Crontab来定义;
2)复杂的任务调度:开发调度平台或使用现成的开源调度系统,比如Ooize、Azkaban、 Airflow、DolphinScheduler等。
1.3 Azkaban与Oozie对比
对市面上最流行的两种调度器,给出以下详细对比,以供技术选型参考。总体来说,Ooize相比Azkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器Azkaban是很不错的候选对象。
第2章 Azkaban入门
2.1 集群模式安装
2.1.1 上传tar包(网盘下载地址:https://pan.baidu.com/s/17D0y41UssTgsMtI0YF4JrA 提取码:tags)
1)将azkaban-db-3.84.4.tar.gz,azkaban-exec-server-3.84.4.tar.gz,azkaban-web-server-3.84.4.tar.gz上传到hadoop103的/opt/software路径

2)新建/opt/module/azkaban目录,并将所有tar包解压到这个目录下
mkdir /opt/module/azkaban
3)解压azkaban-db-3.84.4.tar.gz、 azkaban-exec-server-3.84.4.tar.gz和azkaban-web-server-3.84.4.tar.gz到/opt/module/azkaban目录下
tar -zxvf /opt/software/azkaban-db-3.84.4.tar.gz -C /opt/module/azkaban/
tar -zxvf /opt/software/azkaban-exec-server-3.84.4.tar.gz -C /opt/module/azkaban/
tar -zxvf /opt/software/azkaban-web-server-3.84.4.tar.gz -C /opt/module/azkaban/
4)进入到/opt/module/azkaban目录,依次修改名称
cd /opt/module/azkaban/
mv azkaban-exec-server-3.84.4/ azkaban-exec
mv azkaban-web-server-3.84.4/ azkaban-web
2.1.2 配置MySQL
1)正常安装MySQL
(1)卸载自带的Mysql-libs(如果之前安装过mysql,要全都卸载掉)
rpm -qa | grep -i -E mysql\|mariadb | xargs -n1 sudo rpm -e --nodeps
(2)上面卸载的操作还是最好的,这里用编写脚本的方式进行操作,新建remove_mysql.sh并赋予可执行权限,运行脚本即可
#!/bin/bash service mysql stop 2>/dev/null service mysqld stop 2>/dev/null rpm -qa | grep -i mysql | xargs -n1 rpm -e --nodeps 2>/dev/null rpm -qa | grep -i mariadb | xargs -n1 rpm -e --nodeps 2>/dev/null rm -rf /var/lib/mysql rm -rf /usr/lib64/mysql rm -rf /etc/my.cnf rm -rf /usr/my.cnf
chmod +x remove_mysql.sh
(3)将安装包和JDBC驱动上传到/opt/software,共计6个(https://pan.baidu.com/s/1wojPY6P6qxjdMtc90KxP-Q 提取码:yuan)
01_mysql-community-common-5.7.29-1.el7.x86_64.rpm 02_mysql-community-libs-5.7.29-1.el7.x86_64.rpm 03_mysql-community-libs-compat-5.7.29-1.el7.x86_64.rpm 04_mysql-community-client-5.7.29-1.el7.x86_64.rpm 05_mysql-community-server-5.7.29-1.el7.x86_64.rpm mysql-connector-java-5.1.48.jar
(4)安装MySql
ls *.rpm | xargs -n1 sudo rpm -ivh
(5)启动mysql
sudo systemctl start mysqld
(6)查看mysql密码
sudo cat /var/log/mysqld.log | grep password
(7)用刚刚查到的密码进入mysql(如果报错,给密码加单引号,不管查询到的默认密码是什么直接全部复制就行)
mysql -uroot -p’password’
(8)设置复杂密码(由于mysql密码策略,此密码必须足够复杂)
set password=password("Qs23=zs32");
(9)更改mysql密码策略
set global validate_password_length=4;
set global validate_password_policy=0;
(10)设置简单好记的密码
set password=password("root123");
(11)进入msyql库
use mysql
(12)查询user表
select user, host from user;
(13)修改user表,把Host表内容修改为%
update user set host="%" where user="root";
(14)刷新
flush privileges;
(15)退出
quit;
2)连接MySQL(我的MySQL安装在Hadoop102)
mysql -hhadoop102 -uroot -proot123
3)登陆MySQL,创建Azkaban数据库
create database azkaban;

4)创建azkaban用户并赋予权限(此步可以跳过,后续配置使用root用户)
(1)设置密码有效长度4位及以上
set global validate_password_length=4;
(2)设置密码策略最低级别
set global validate_password_policy=0;
(3)创建Azkaban用户,任何主机都可以访问Azkaban,密码是azkaban123
CREATE USER 'azkaban'@'%' IDENTIFIED BY 'azkaban123';
(4)赋予Azkaban用户增删改查权限
grant select,insert,update,delete on azkaban.*to 'azkaban'@'%' with grant option;
5)创建Azkaban表,完成后退出MySQL(将azkaban-db-3.84.4.tar.gz上传至hadoop102的/opt/software/并解压,因为我的mysql安装在hadoop102上)
use azkaban;
source /opt/module/azkaban/azkaban-db-3.84.4/create-all-sql-3.84.4.sql;
quit;
6)更改MySQL包大小;防止Azkaban连接MySQL阻塞
sudo vim /etc/my.cnf
max_allowed_packet=1024M

7)重启MySQL
sudo systemctl restart mysqld
8)查看状态
sudo systemctl status mysqld

2.1.3 配置Executor Server
Azkaban Executor Server处理工作流和作业的实际执行
1)编辑azkaban.properties
vim /opt/module/azkaban/azkaban-exec/conf/azkaban.properties
#修改如下属性 default.timezone.id=Asia/Shanghai azkaban.webserver.url=http://hadoop102:8081 mysql.host=hadoop102 mysql.database=azkaban mysql.user=root mysql.password=root123 #在最后添加 executor.port=12321
2)同步azkaban-exec到所有节点
xsync /opt/module/azkaban/azkaban-exec
3)必须进入到/opt/module/azkaban/azkaban-exec路径,分别在三台机器上,启动executor server
cd /opt/module/azkaban/azkaban-exec
#如果在/opt/module/azkaban/azkaban-exec目录下出现executor.port文件,说明启动成功
bin/start-exec.sh
4)下面激活executor(每台节点都执行)
curl -G "hadoop102:12321/executor?action=activate" && echo
curl -G "hadoop103:12321/executor?action=activate" && echo
curl -G "hadoop104:12321/executor?action=activate" && echo
如果三台机器都出现如下提示,则表示激活成功:{"status":"success"}
2.1.4 配置Web Server
Azkaban Web Server处理项目管理,身份验证,计划和执行触发。
1)编辑azkaban.properties(我自己是安装在hadoop103集群上)
vim /opt/module/azkaban/azkaban-web/conf/azkaban.properties
#修改如下属性 default.timezone.id=Asia/Shanghai user.manager.xml.file=/opt/module/azkaban/azkaban-web/conf/azkaban-users.xml executor.global.properties=/opt/module/azkaban/azkaban-web/conf/global.properties mysql.host=hadoop102 mysql.database=azkaban mysql.user=root mysql.password=root123 #StaticRemainingFlowSize:正在排队的任务数 #CpuStatus:CPU占用情况 #MinimumFreeMemory:内存占用情况,测试环境下,必须将MinimumFreeMemory删除掉,否则它会认为集群资源不够,不执行 azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus
2)修改azkaban-users.xml文件,添加yuange用户
vim /opt/module/azkaban/azkaban-web/conf/azkaban-users.xml
<azkaban-users> <user groups="azkaban" password="azkaban" roles="admin" username="azkaban"/> <user password="metrics" roles="metrics" username="metrics"/> <user groups="azkaban" password="azkaban123" roles="metrics,admin" username="yuange"/> <role name="admin" permissions="ADMIN"/> <role name="metrics" permissions="METRICS"/> </azkaban-users>
3)必须进入到hadoop103的/opt/module/azkaban/azkaban-web路径,启动web server
cd /opt/module/azkaban/azkaban-web
bin/start-web.sh
4)访问 http://hadoop103:8081 ,并用yuange用户登陆
5)编写azkaban集群启动/停止脚本(在Hadoop103上编写)
vim /home/atguigu/bin/azkaban.sh
#!/bin/bash #azkaban的一键启动脚本,只接收单个start或stop参数 if(($#!=1)) then echo 请输入单个start或stop参数! exit fi #对传入的单个参数进行校验,且执行相应的启动和停止命令 if [ $1 = start ] then #启动executor xcall.sh "cd /opt/module/azkaban/azkaban-exec; bin/start-exec.sh " sleep 5s #激活executor for i in hadoop102 hadoop103 hadoop104 do curl -G $i:12321/executor?action=activate && echo done #启动web-server cd /opt/module/azkaban/azkaban-web bin/start-web.sh elif [ $1 = stop ] then cd /opt/module/azkaban/azkaban-web bin/shutdown-web.sh xcall.sh /opt/module/azkaban/azkaban-exec/bin/shutdown-exec.sh else echo 请输入单个start或stop参数! fi xcall.sh jps
6)添加可执行权限
chmod +x /home/atguigu/bin/azkaban.sh
2.2 Work Flow案例实操
2.2.1 HelloWorld案例
1)在windows环境,新建azkaban.project文件,编辑内容如下:
azkaban-flow-version: 2.0
注意:该文件作用,是采用新的Flow-API方式解析flow文件
2)新建basic.flow文件,内容如下
nodes: - name: jobA type: command config: command: echo "Hello World"
(1)Name:job名称
(2)Type:job类型。command表示你要执行作业的方式为命令
(3)Config:job配置
3)将azkaban.project、basic.flow文件压缩到一个zip文件,文件名称必须是英文

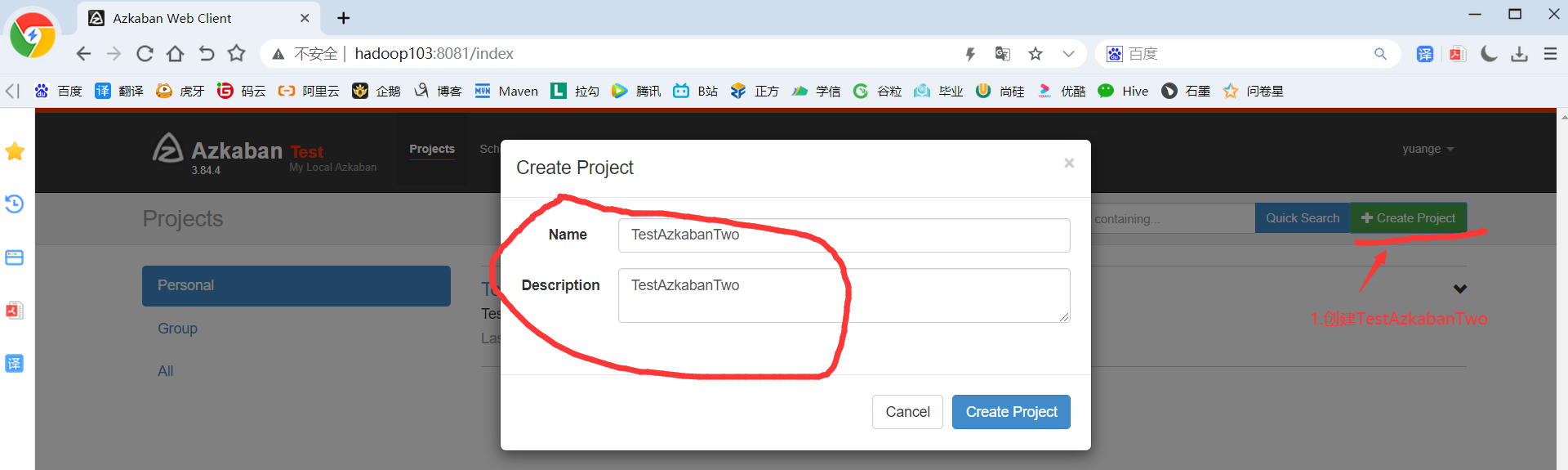
4)在WebServer新建项目:http://hadoop103:8081/index
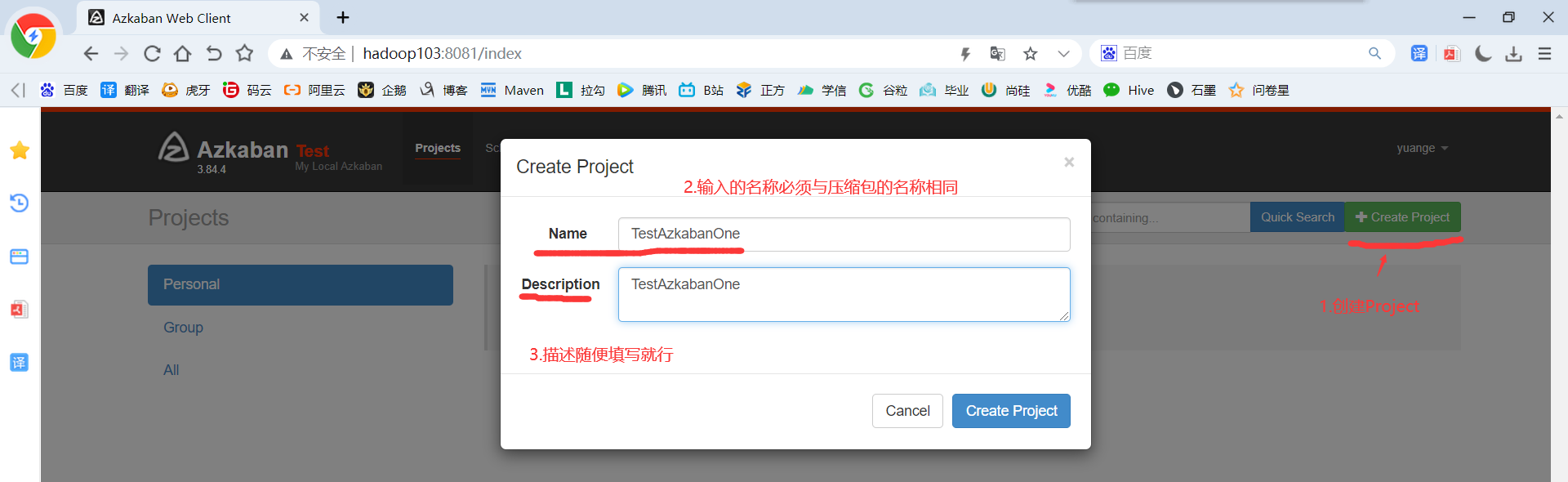
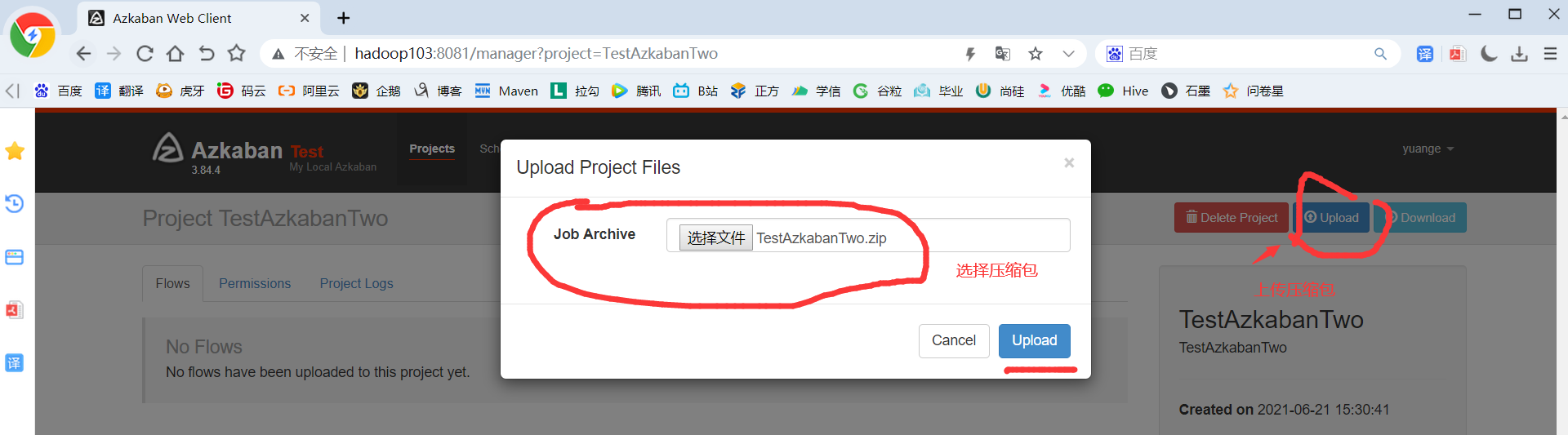
5)TestAzkabanOne.zip文件上传

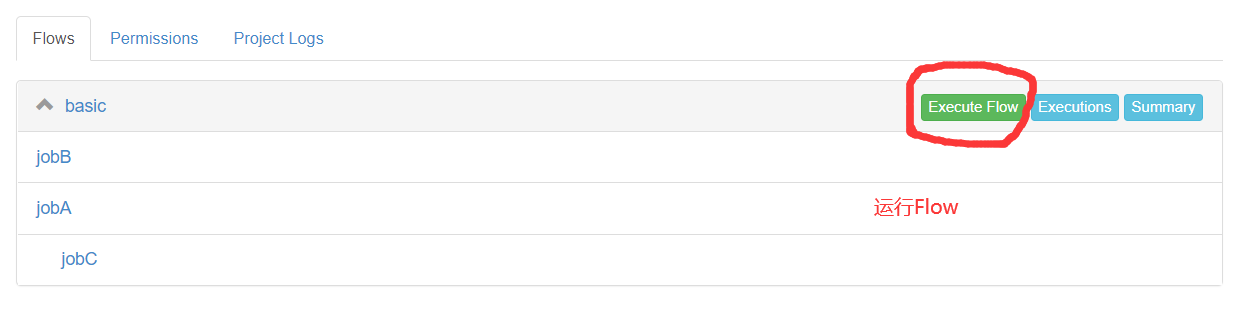
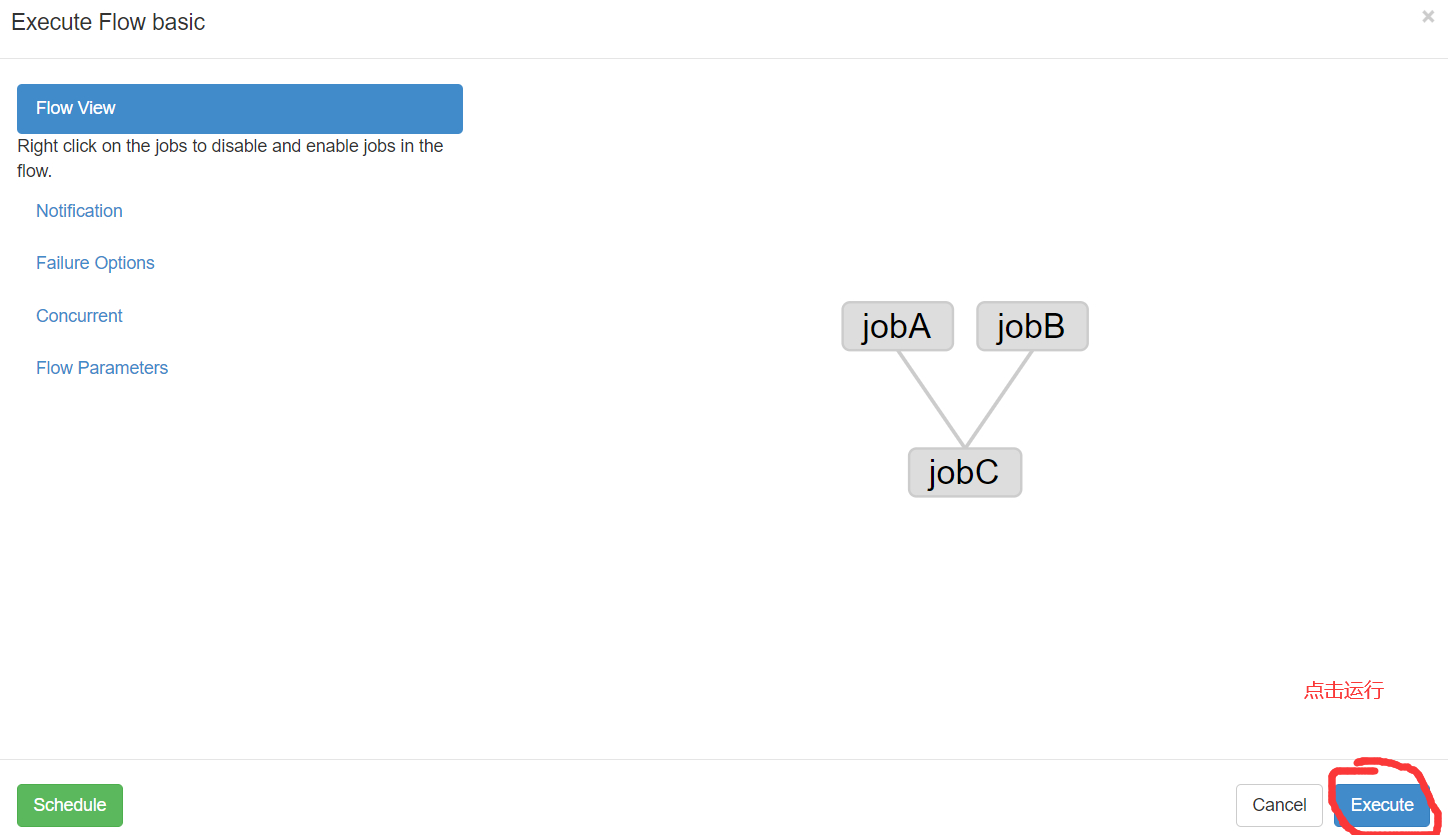
6)执行任务流
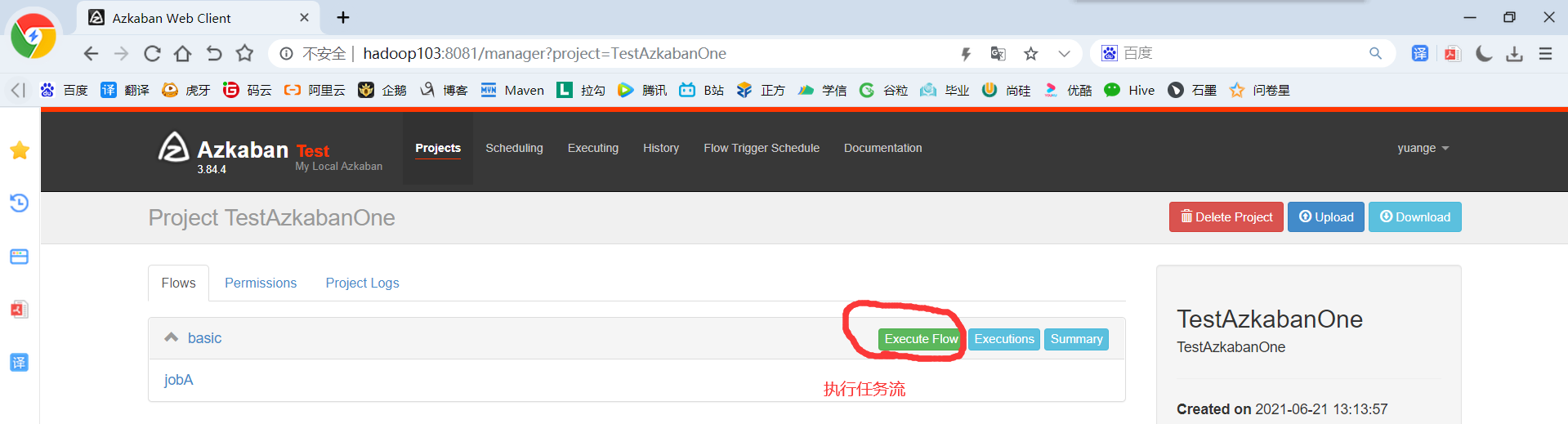

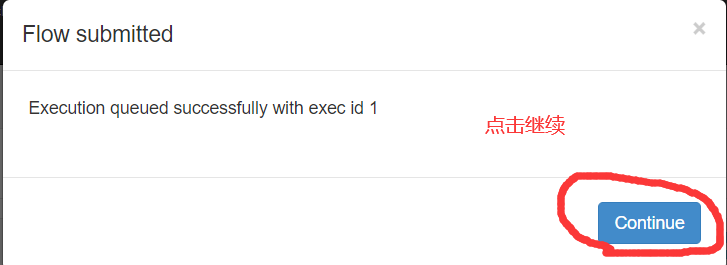
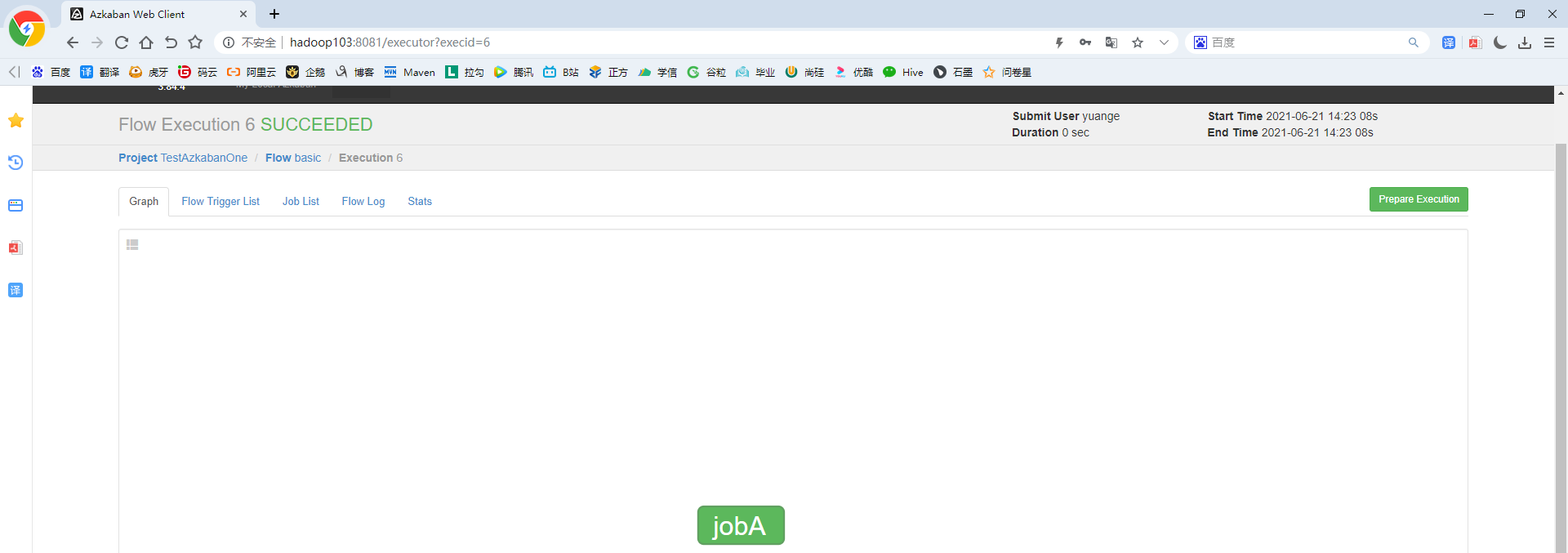
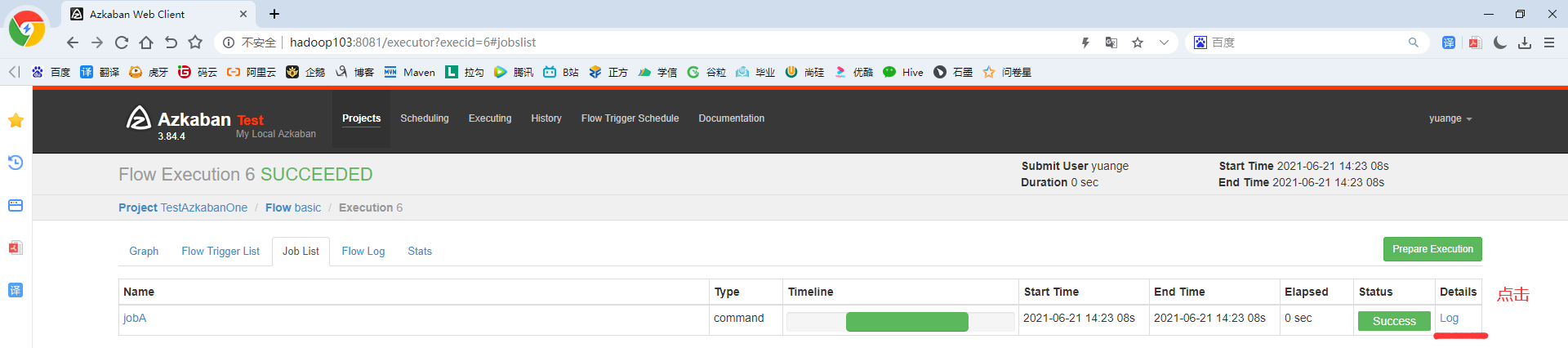
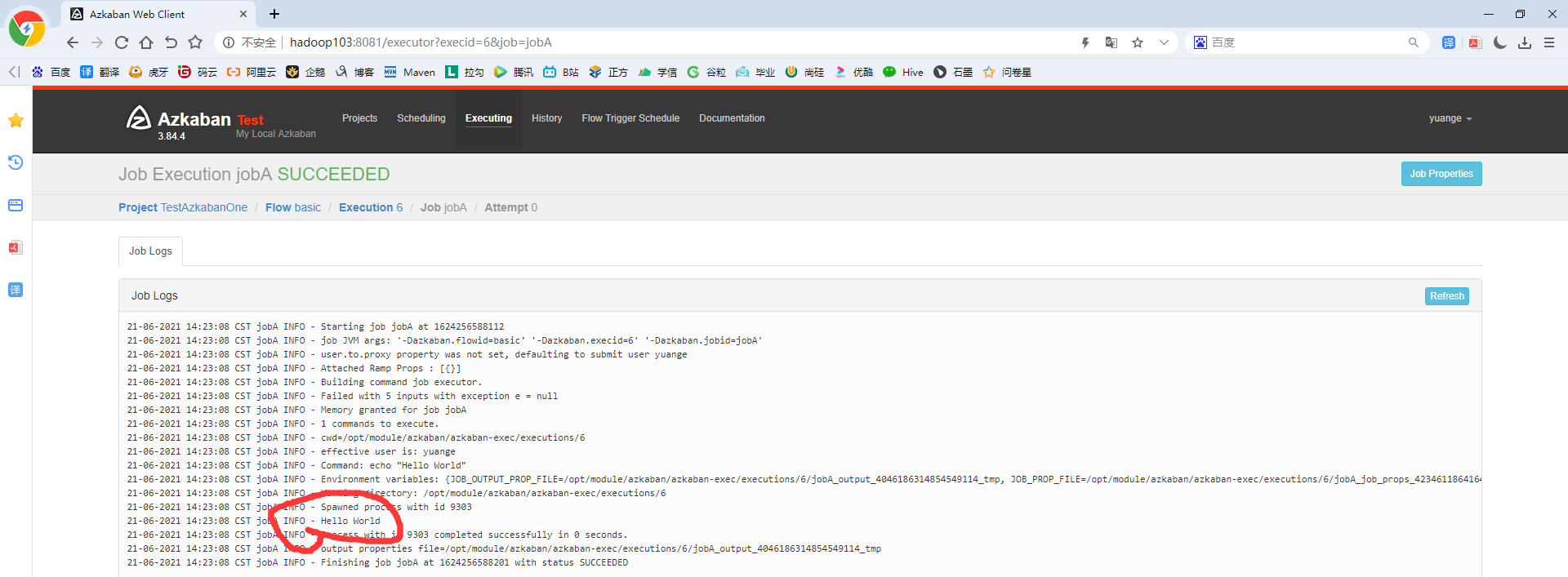
9)在日志中,查看运行结果
2.2.2 作业依赖案例
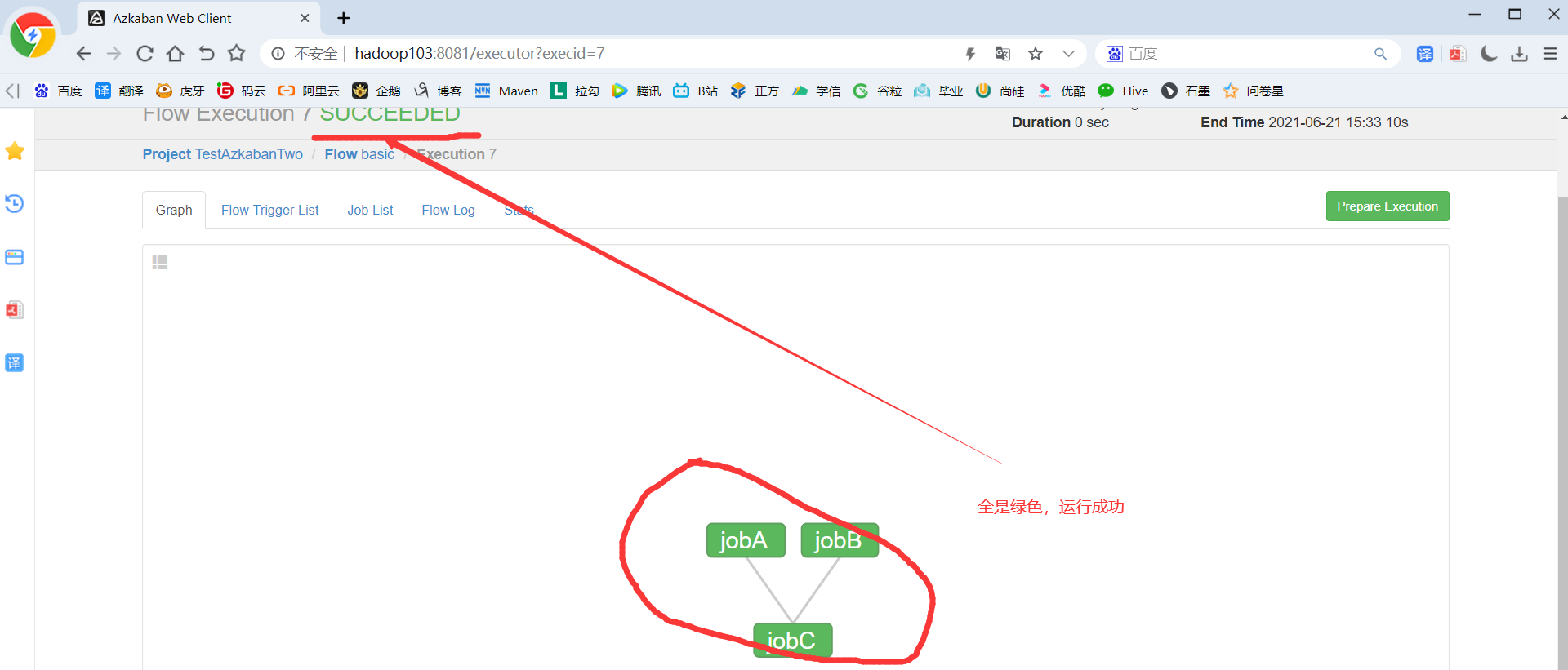
需求:JobA和JobB执行完了,才能执行JobC
1)修改basic.flow为如下内容
nodes: - name: jobC type: command # jobC 依赖 JobA和JobB dependsOn: - jobA - jobB config: command: echo "I’m JobC,我依赖于JobA和JobB" - name: jobA type: command config: command: echo "I’m JobA" - name: jobB type: command config: command: echo "I’m JobB"
2)将修改后的basic.flow和azkaban.project压缩成TestAzkabanTwo.zip文件
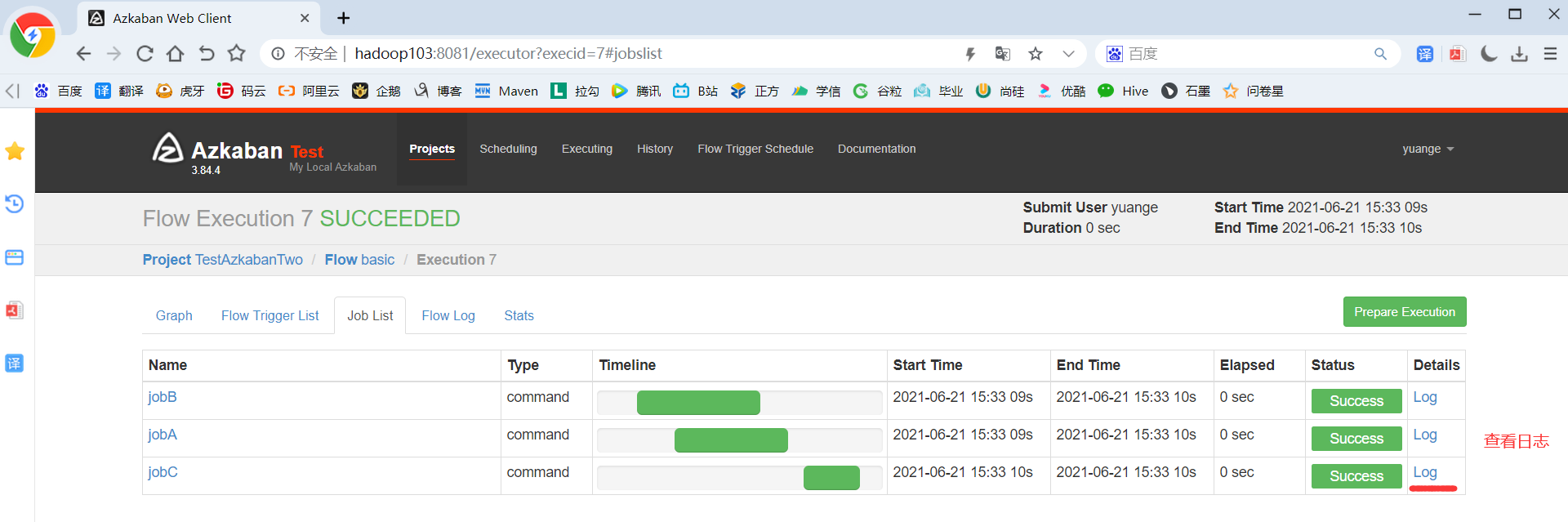
3)重复2.3.1节HelloWorld后续步骤

2.2.4 自动失败重试案例
需求:如果执行任务失败,需要重试3次,重试的时间间隔10000ms
1)编译配置流
nodes: - name: JobA type: command config: command: sh /not_exists.sh retries: 3 retry.backoff: 10000
retries:重试次数
retry.backoff:重试的时间间隔
2)将修改后的basic.flow和azkaban.project压缩成TestAzkabanThree.zip文件
3)重复2.3.1节HelloWorld后续步骤
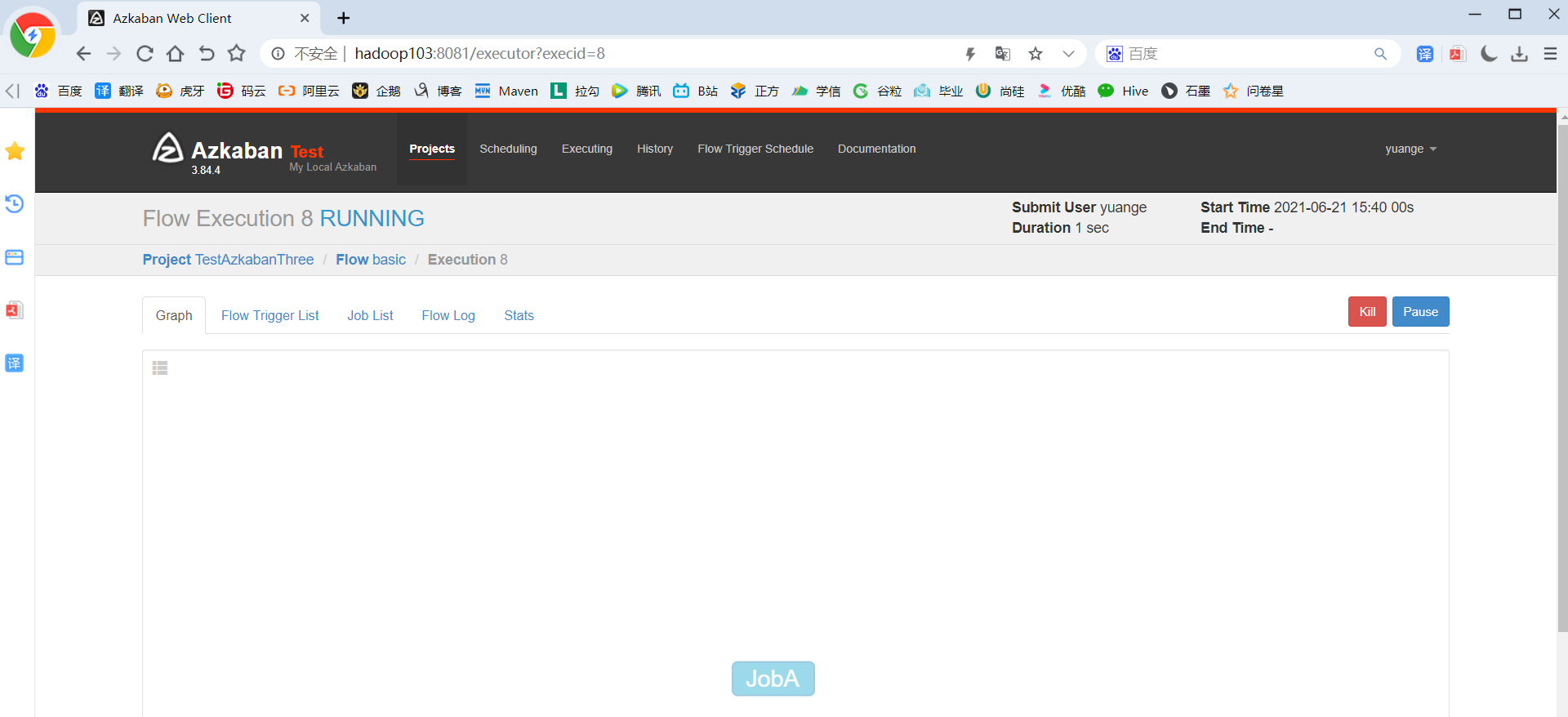
4)执行并观察到一次失败+三次重试


5)也可以点击上图中的Log,在任务日志中看到,总共执行了4次

6)也可以在Flow全局配置中添加任务失败重试配置,此时重试配置会应用到所有Job
config: retries: 3 retry.backoff: 10000 nodes: - name: JobA type: command config: command: sh /not_exists.sh
2.2.5 手动失败重试案例
需求:JobA=》JobB(依赖于A)=》JobC=》JobD=》JobE=》JobF。生产环境,任何Job都有可能挂掉,可以根据需求执行想要执行的Job
1)编译配置流
nodes: - name: JobA type: command config: command: echo "This is JobA." - name: JobB type: command dependsOn: - JobA config: command: echo "This is JobB." - name: JobC type: command dependsOn: - JobB config: command: echo "This is JobC." - name: JobD type: command dependsOn: - JobC config: command: echo "This is JobD." - name: JobE type: command dependsOn: - JobD config: command: echo "This is JobE." - name: JobF type: command dependsOn: - JobE config: command: echo "This is JobF."
2)将修改后的basic.flow和azkaban.project压缩成TestAzkabanFour.zip文件
3)重复2.3.1节HelloWorld后续步骤

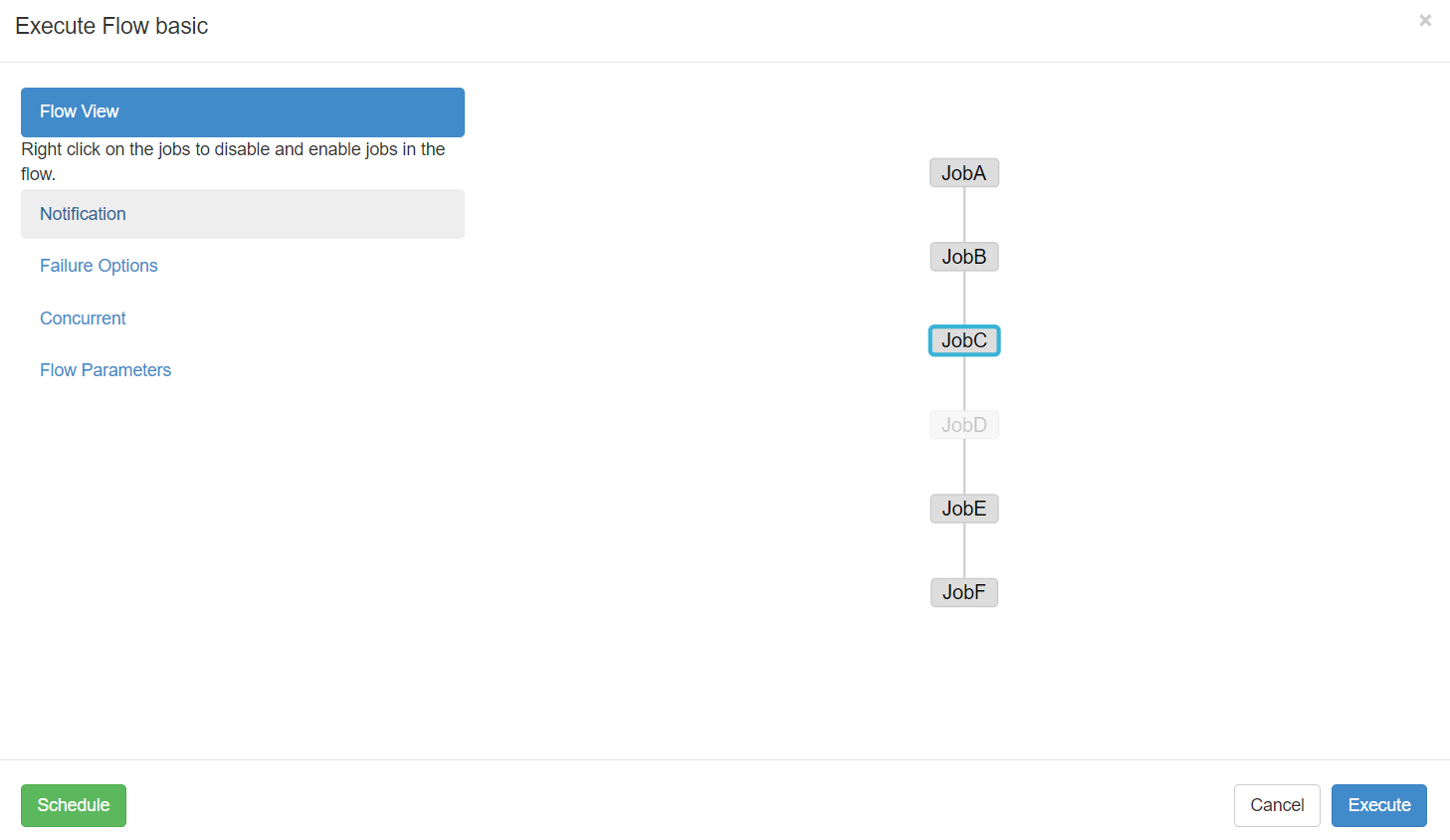
Enable和Disable下面都分别有如下参数:
Parents:该作业的上一个任务
Ancestors:该作业前的所有任务
Children:该作业后的一个任务
Descendents:该作业后的所有任务
Enable All:所有的任务
4)可以根据需求选择性执行对应的任务
第3章 Azkaban进阶
3.1 定时执行案例
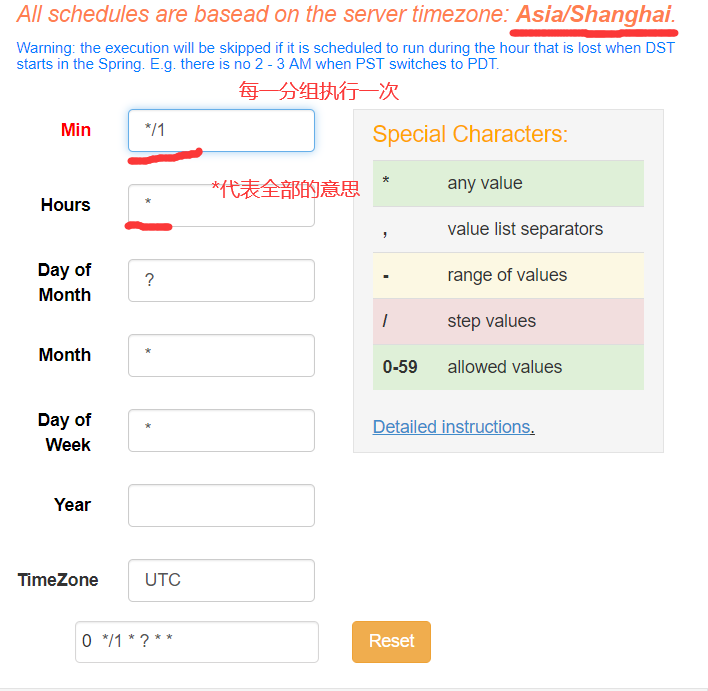
需求:JobA每间隔1分钟执行一次;
1)Azkaban可以定时执行工作流。在执行工作流时候,选择左下角Schedule
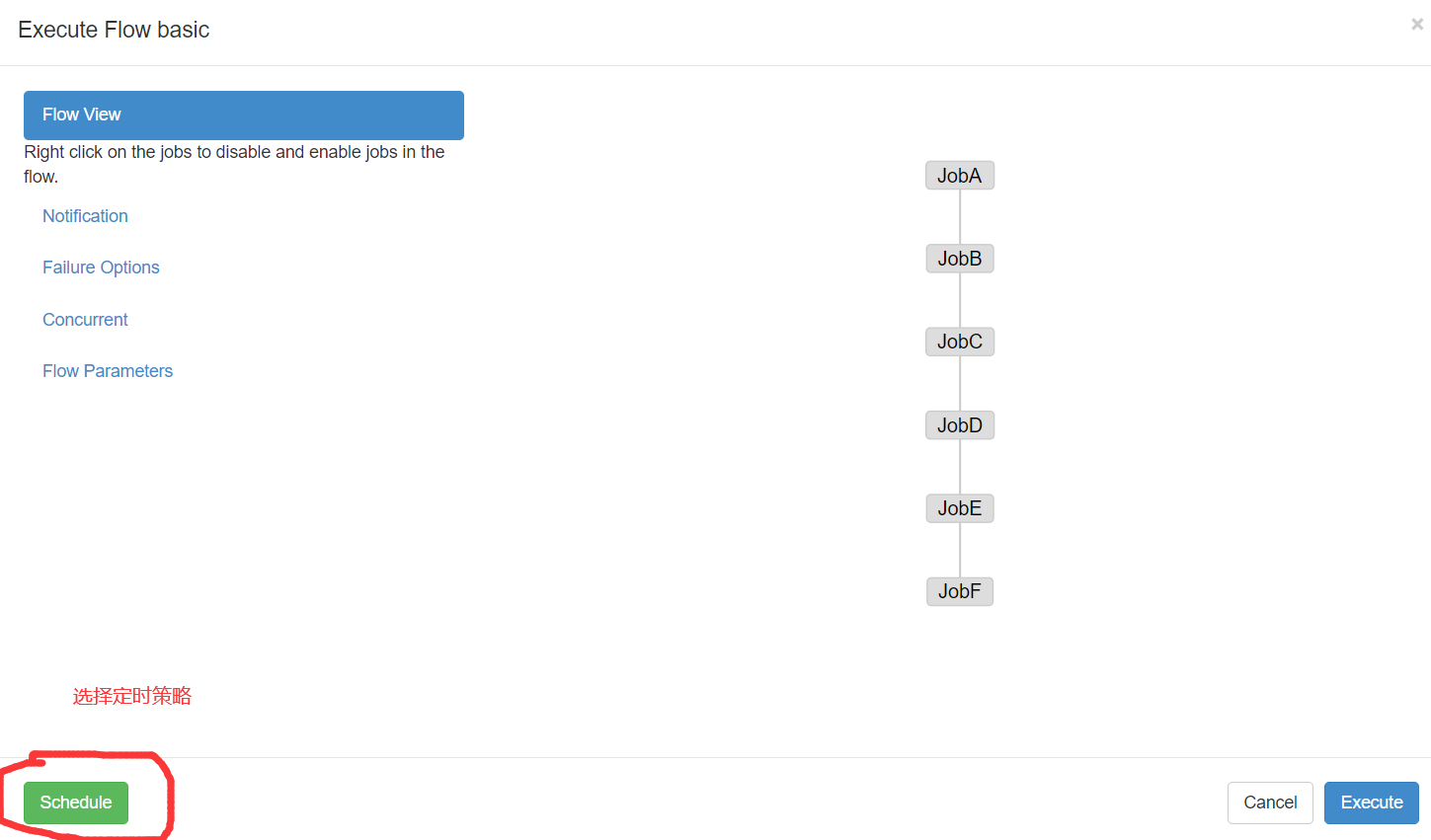
2)右上角注意时区是上海,然后在左面填写具体执行事件,填写的方法和crontab配置定时任务规则一致。
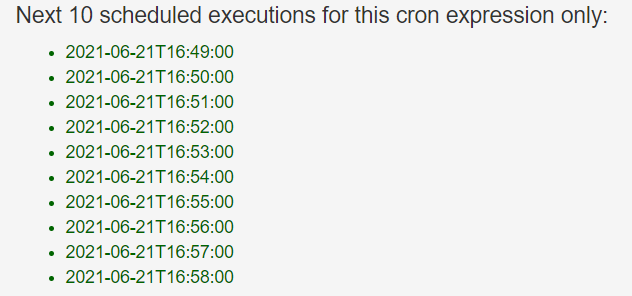
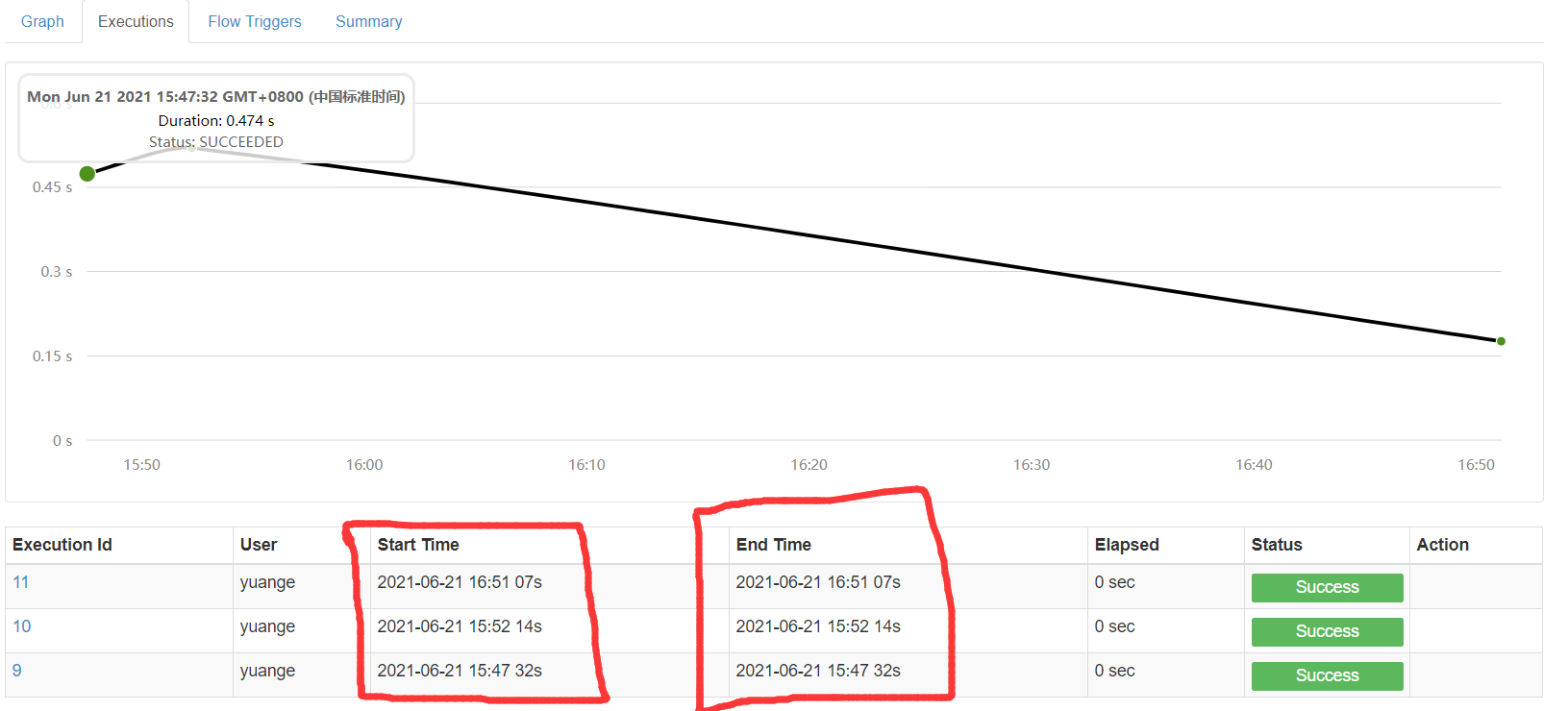
3)观察结果

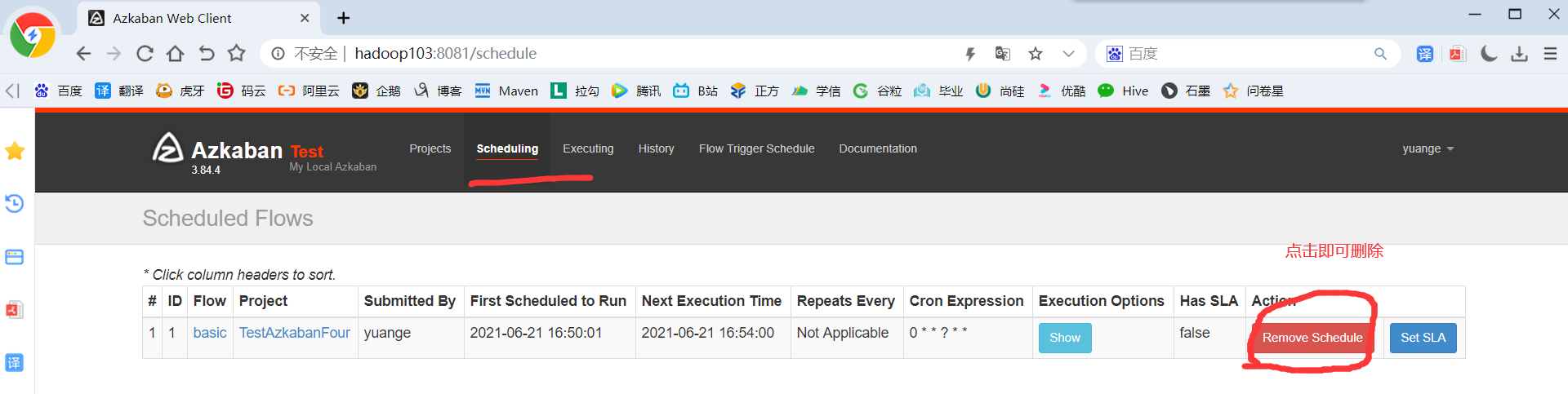
4)删除定时调度,点击remove Schedule即可删除当前任务的调度规则
3.2 邮件报警案例
3.2.1 注册邮箱
1)申请注册一个邮箱
2)点击设置--->账户

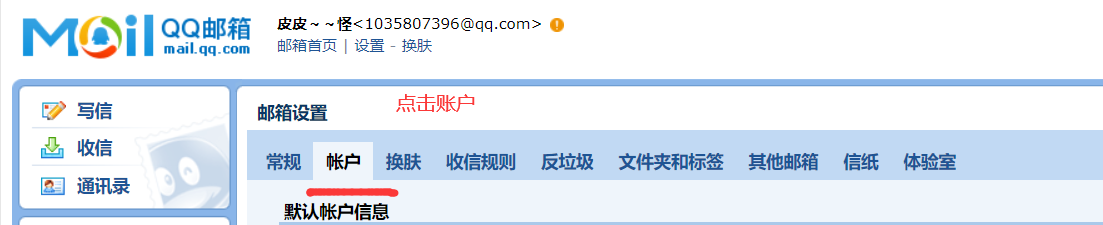
3)开启SMTP服务

4)一定要记住授权码
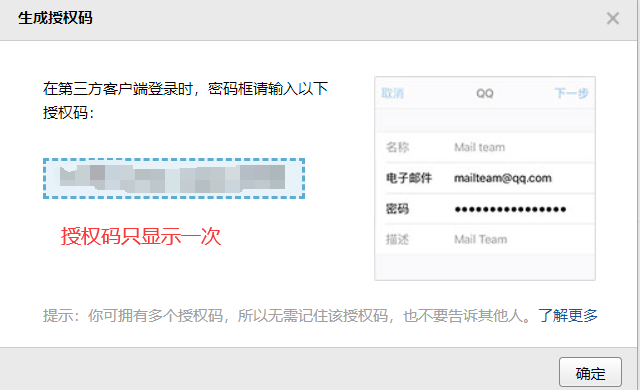
3.2.2 邮件报警案例
Azkaban默认支持通过邮件对失败的任务进行报警,配置方法如下:
1)在azkaban-web节点hadoop103上,编辑/opt/module/azkaban/azkaban-web/conf/azkaban.properties,修改如下内容:
vim /opt/module/azkaban/azkaban-web/conf/azkaban.properties
#添加如下内容: #这里设置邮件发送服务器,需要 申请邮箱,开通stmp服务 mail.sender=1035807396@qq.com mail.host=smtp.qq.com mail.user=1035807396@qq.com mail.password=用邮箱的授权码 #Job执行成功发往的邮箱 job.failure.email=1430730265@qq.com #Job执行失败发往的邮箱 job.success.email=1430730265@qq.com
2)保存并重启web-server
bin/shutdown-web.sh
bin/start-web.sh
3)编辑basic.flow,加入如下属性:
nodes: - name: jobA type: command config: command: echo "This is an email test."
4)将azkaban.project和basic.flow压缩成TestAzkabanEmail.zip
5)创建工程-->上传文件-->执行作业-->查看结果



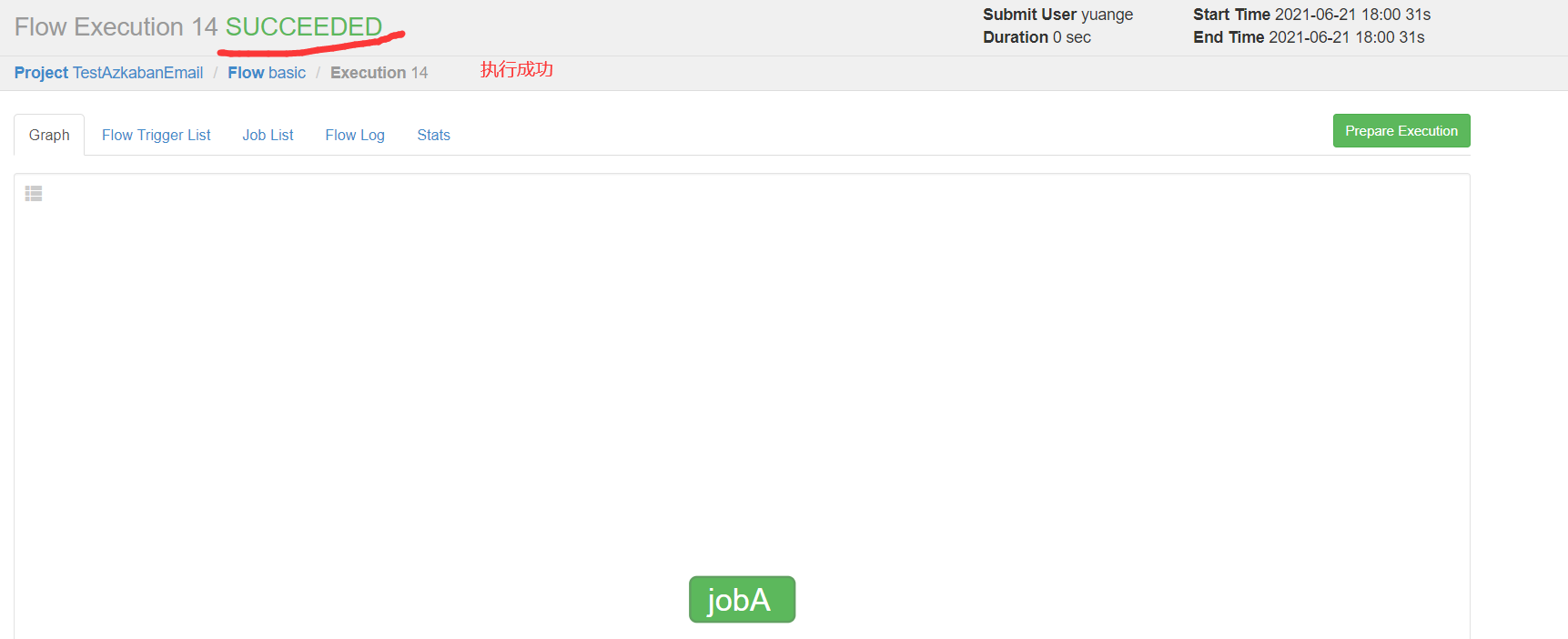

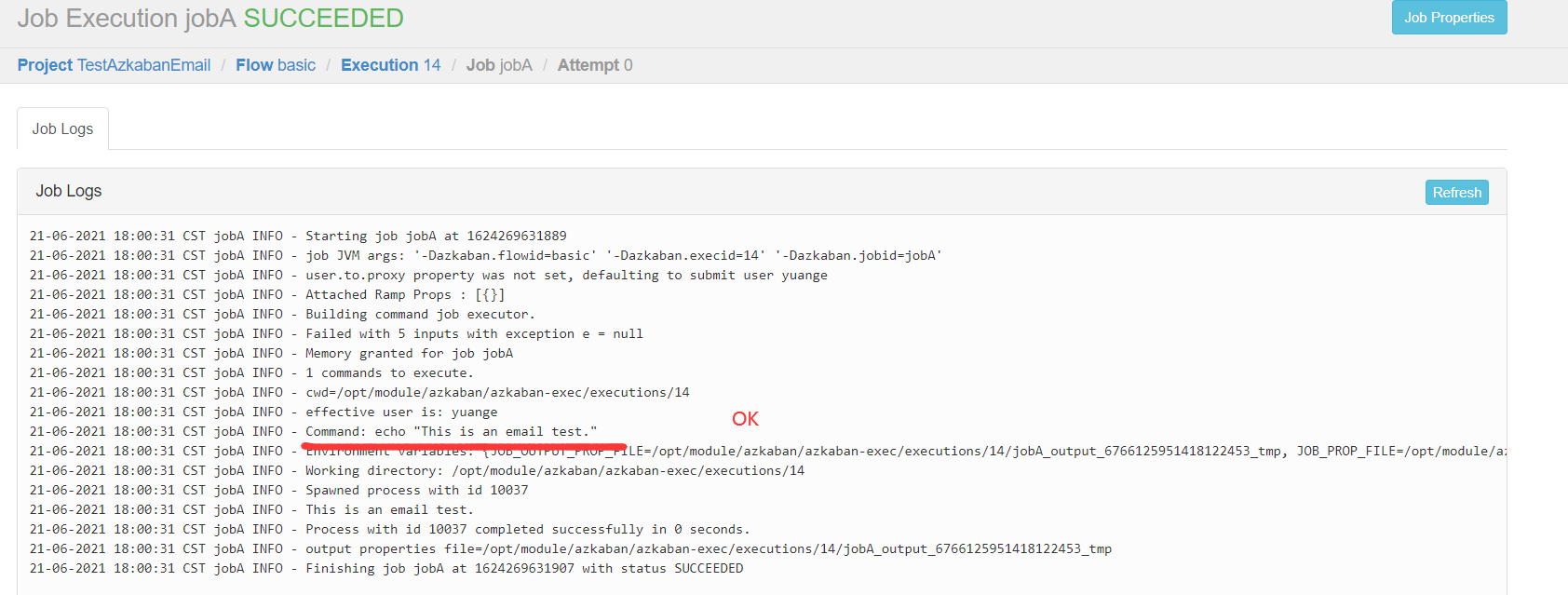
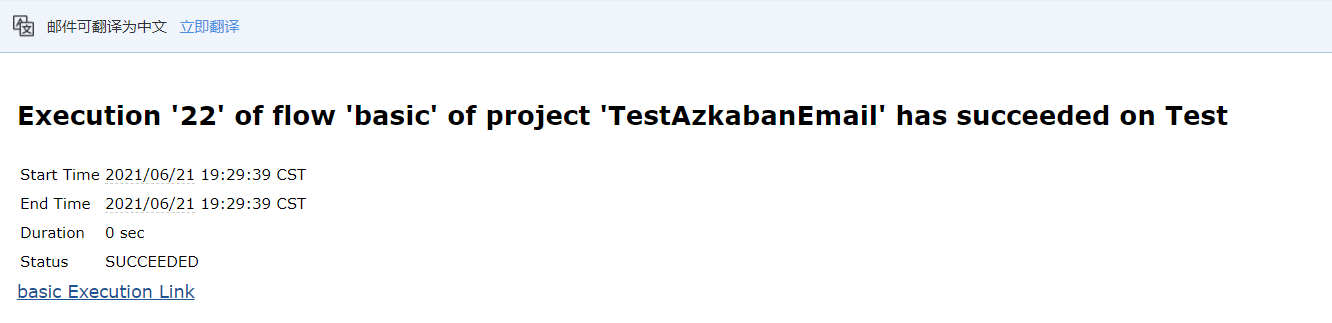
6)观察邮箱,发现执行成功或者失败的邮件
第4章 参考资料
4.1 Azkaban完整配置
见官网文档:https://azkaban.readthedocs.io/en/latest/configuration.html
4.2 YAML语法
1)语法特点
(1)大小写敏感
(2)通过缩进表示层级关系
(3)禁止使用tab缩进,只能使用空格键 (个人感觉这条最重要)
(4)缩进的空格数目不重要,只要相同层级左对齐即可
(5)使用#表示注释
2)支持的数据结构
(1)对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
(2)数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
(3)纯量(scalars):单个的、不可再分的值
3)双引号和单引号的区分
双引号"":不会转义字符串里面的特殊字符,特殊字符作为本身想表示的意思
name: "123\n123"
---------------------------
输出: 123 换行 123
如果不加引号将会转义特殊字符,当成字符串处理
4)值的写法
(1)字符串:使用”或”“或不使用引号
value0: 'hello World!' value1: "hello World!" value2: hello World!
(2)布尔值:true或false表示
(3)数字
l12 #整数 014 # 八进制整数 0xC #十六进制整数 13.4 #浮点数 1.2e+34 #指数 .inf空值 #无穷大
(4)空值
null或~表示
(5)日期:使用 iso-8601 标准表示日期
date: 2018-01-01t16:59:43.10-05:00
在springboot中yaml文件的时间格式 date: yyyy/MM/dd HH:mm:ss
(6)强制类型转换:YAML 允许使用个感叹号!,强制转换数据类型,单叹号通常是自定义类型,双叹号是内置类型
money: !!str 123 date: !Boolean true
内置类型列表
!!int # 整数类型 !!float # 浮点类型 !!bool # 布尔类型 !!str # 字符串类型 !!binary # 也是字符串类型 !!timestamp # 日期时间类型 !!null # 空值 !!set # 集合 !!omap,!!pairs # 键值列表或对象列表 !!seq # 序列,也是列表 !!map # 键值表
(7)对象:Map(属性和值)(键值对)的形式: key:(空格)v :表示一堆键值对,空格不可省略
car:
color: red
brand: BMW
一行写法,相当于JSON格式:{"color":"red","brand":"BMW"}
car:{color: red,brand: BMW}
(8)数组:一组连词线开头的行,构成一个数组
brand: - audi - bmw - ferrari
一行写法,相当于JSON:["auri","bmw","ferrari"]
brand: [audi,bmw,ferrari]
(9)文本块:|:使用|标注的文本内容缩进表示的块,可以保留块中已有的回车换行
value: | hello world! 输出结果:hello 换行 world!
+表示保留文字块末尾的换行,-表示删除字符串末尾的换行( “|” 与 文本之间须另起一行)
value: | hello value: |- hello value: |+ hello 输出:hello\n hello hello\n\n(有多少个回车就有多少个\n)
>:使用 > 标注的文本内容缩进表示的块,将块中回车替换为空格,最终连接成一行(“>” 与 文本之间的空格)
value: > hello world! 输出:hello 空格 world!
(10)锚点与引用:使用 & 定义数据锚点(即要复制的数据),使用 * 引用锚点数据(即数据的复制目的地)(注意:*引用部分不能追加内容)
name: &a yaml book: *a books: - java - *a - python 输出book: yaml 输出books:[java,yaml,python]
5)配置文件注入数据:我们可以导入配置文件处理器,以后编写配置就有提示了,@ConfigurationPropertiesIDE会提示打开在线的帮助文档
<!--导入配置文件处理器,配置文件进行绑定就会有提示-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
/** * 将配置文件中配置的每一个属性的值,映射到这个组件中 * @ConfigurationProperties:告诉SpringBoot将本类中的所有属性和配置文件中相关的配置进行绑定; * prefix = "person":配置文件中哪个下面的所有属性进行一一映射 * * 只有这个组件是容器中的组件,才能容器提供的@ConfigurationProperties功能; * */ @Component //实例化 @ConfigurationProperties(prefix = "person")//yaml或者properties的前缀 public class Person { private String name; private Integer age; private Boolean flag; private Date birthday; private Map<String,Object> maps; private List<Object> tempList; private Dog dog; //省略getter和setter以及toString方法
6)application.yaml文件
person: name: 胖先森 age: 18 flag: false birthday: 2018/12/19 20:21:22 #Spring Boot中时间格式 maps: {bookName: "西游记",author: '吴承恩'} tempList: - 红楼梦 - 三国演义 - 水浒传 dog: dogName: 大黄 dogAge: 4
7)在test中进行测试如下:
@RunWith(SpringRunner.class) @SpringBootTest public class Demo03BootApplicationTests { @Autowired private Person p1; @Test public void contextLoads() { System.out.println(p1); } }
8)application.properties文件
propertiesperson123.name=刘备 person123.age=20 person123.birthday=2018/12/19 20:21:22 person123.maps.bookName=水浒传 person123.maps.author=罗贯中 person123.temp-list=一步教育,步步为赢 person123.dog.dogName=小白 person123.dog.dogAge=5
java代码修改前缀
@Component //实例化 @ConfigurationProperties(prefix = "person123")//yaml或者properties的前缀 public class Person { private String name; private Integer age; private Boolean flag; private Date birthday; private Map<String,Object> maps; private List<Object> tempList; private Dog dog; //省略getter和setter以及toString方法
9)在test中进行测试如下:
@RunWith(SpringRunner.class) @SpringBootTest public class Demo03BootApplicationTests { @Autowired private Person p1; @Test public void contextLoads() { System.out.println(p1); } }

