
一、前言
1.学习内核的目的
①从宏观上了解Job(Spark on YARN)提交的流程。(画图)
②了解Job在提交之后,进行任务的划分,Stage的划分,任务的调度的过程!
结合: 宽依赖,窄依赖,Stage,task , job
③了解整个Job在执行期间Driver和Executor之间的通信方式
④Shuffle (区别不同的shuffle)
Spark是如何实现Shuffle!
不同的Shuffle的效率影响!
⑤Spark的内存管理 (只有统一内存管理,用什么GC回收器)
方式: 查看源码!
最终要求: 用自己的语言表述上述的知识点!
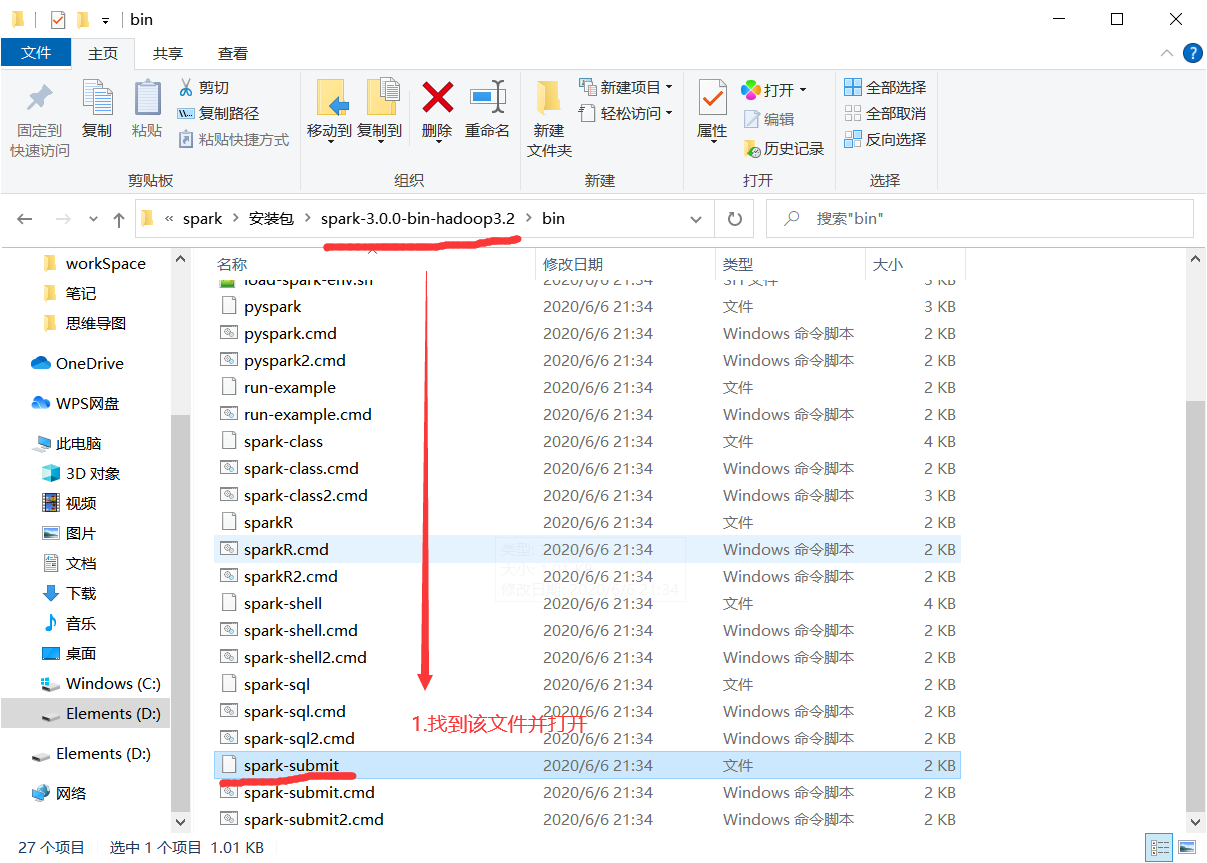
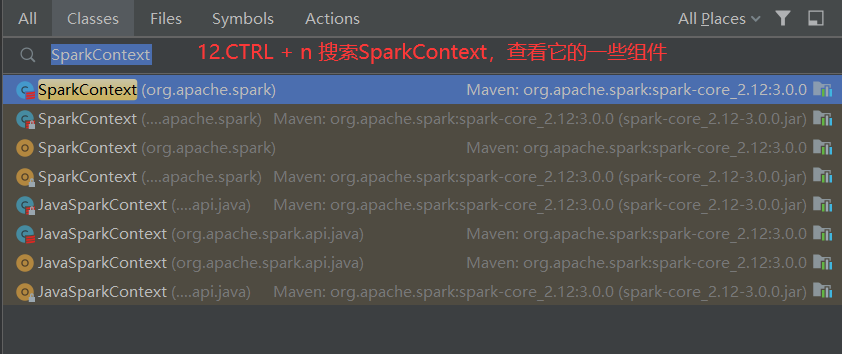
2.指定App部署的模式
在提交Job时,通过--deploy-mode:参数指定,在生产上使用cluster模式,cluster模式会在集群中选择一台机器启动Driver程序
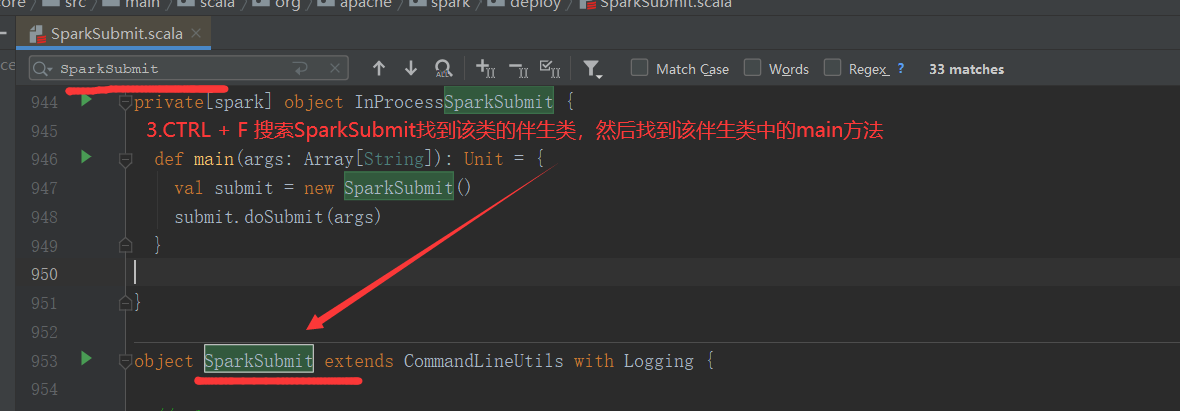
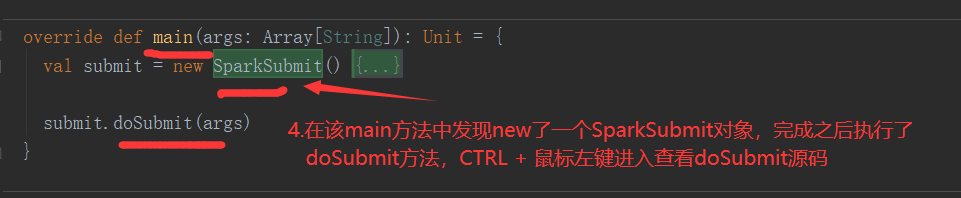
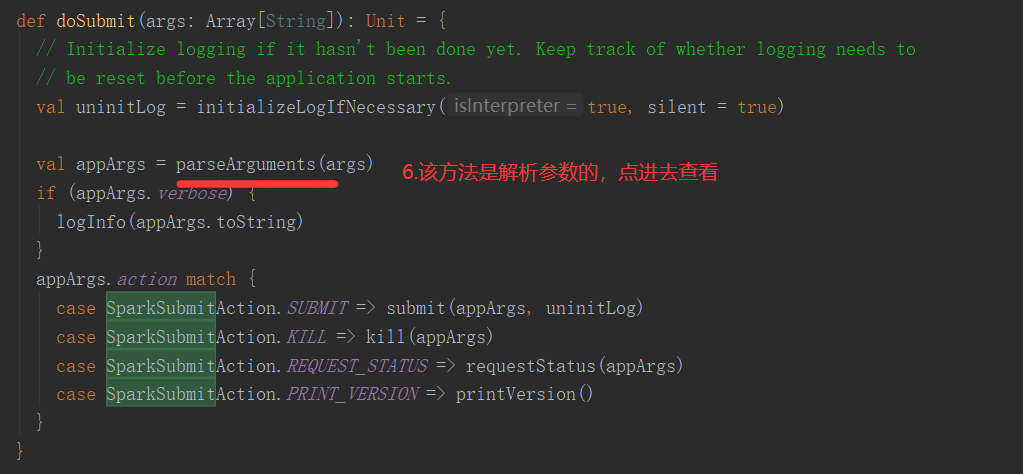
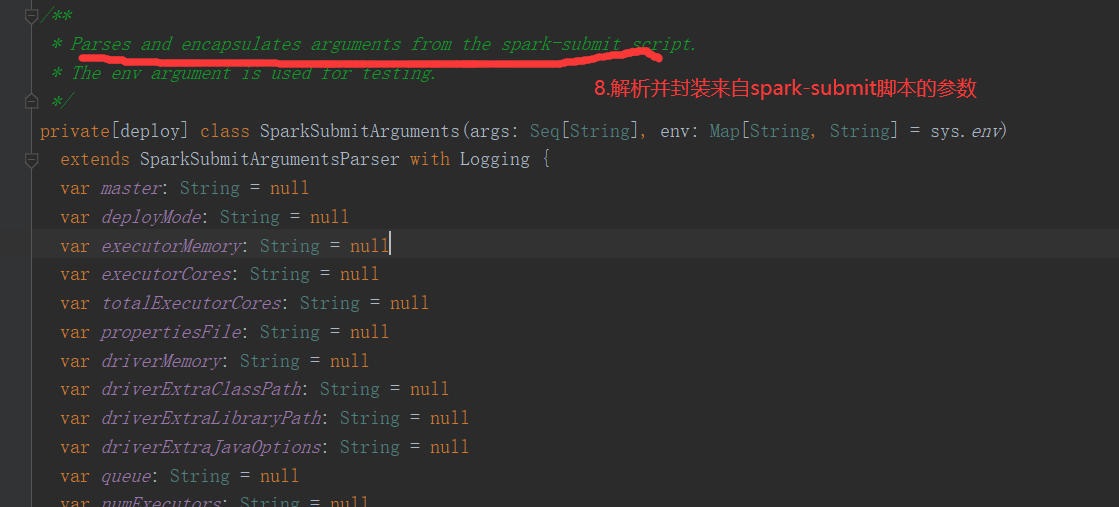
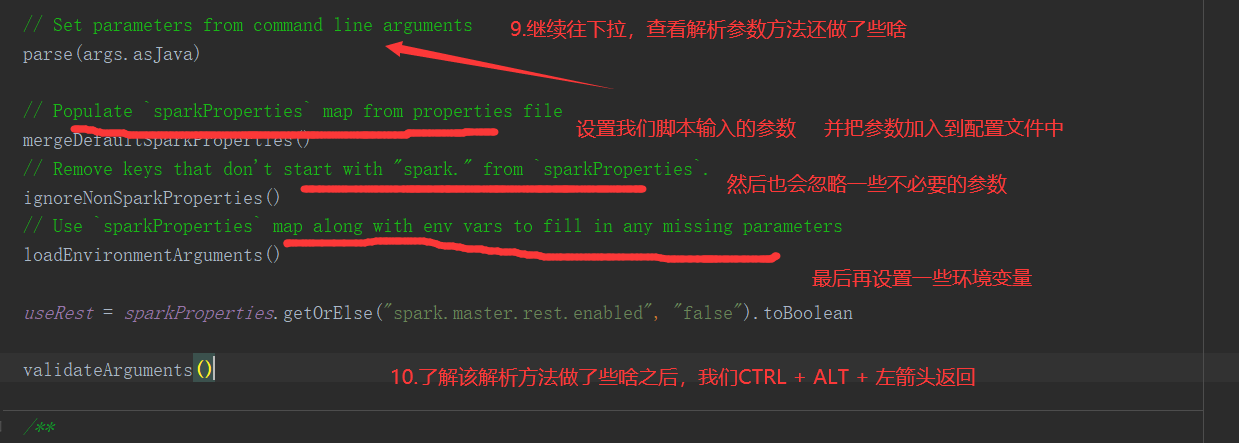
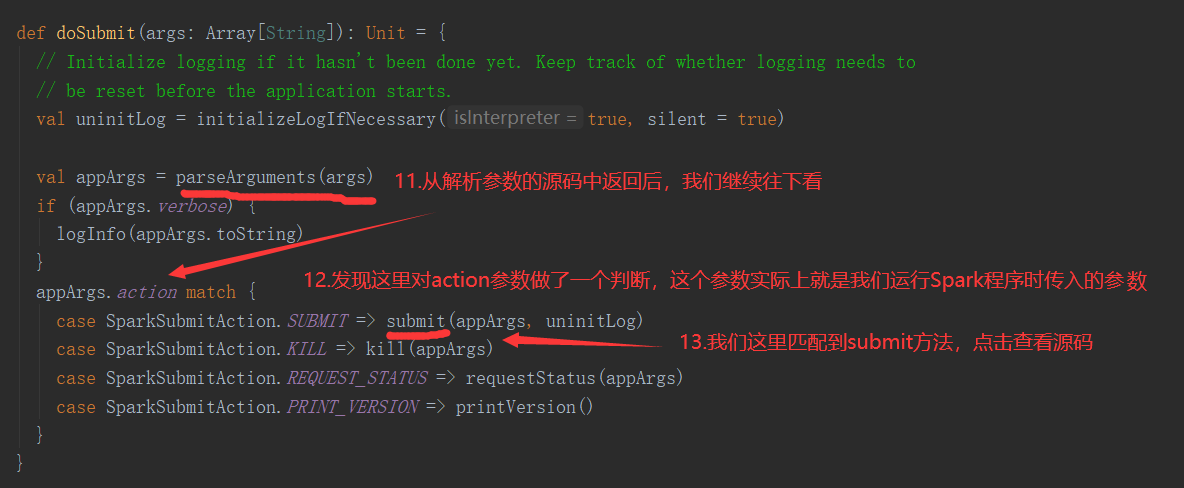
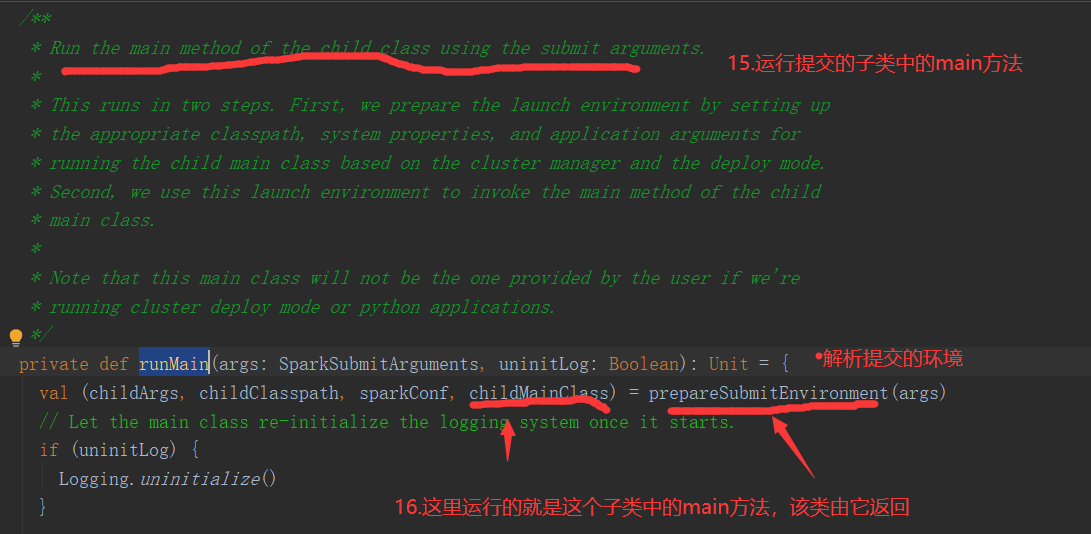
SparkOnYarnCluster提交流程源码分析(必须在idea中导入相关依赖):
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-yarn_2.12</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.0.0</version> </dependency>





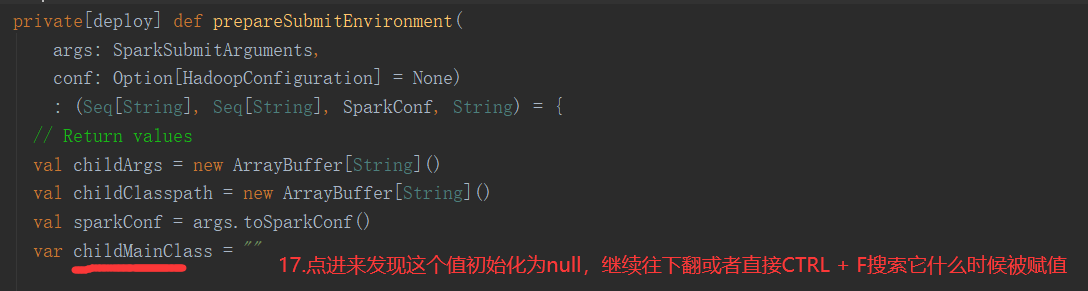
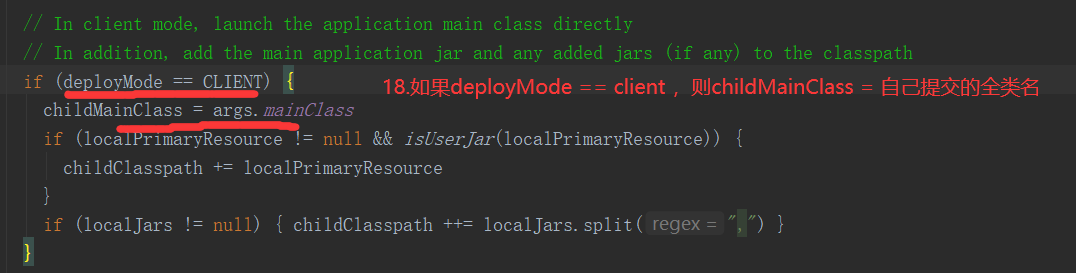
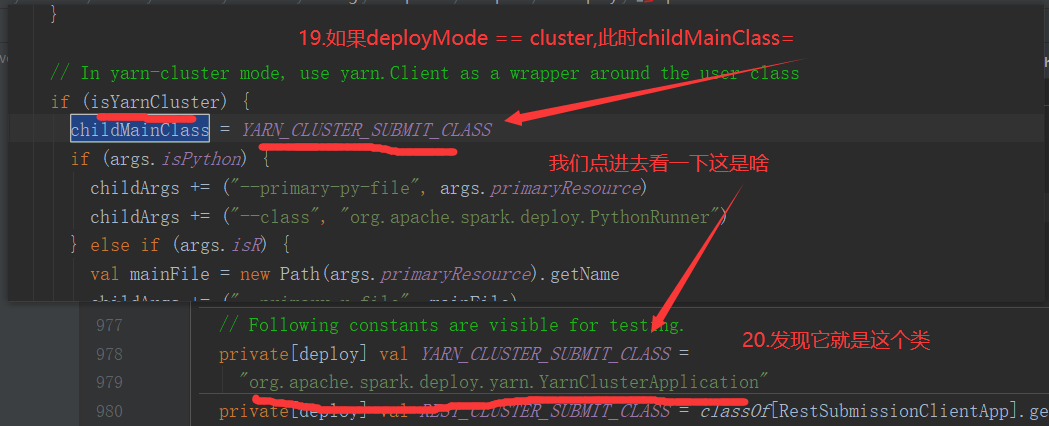






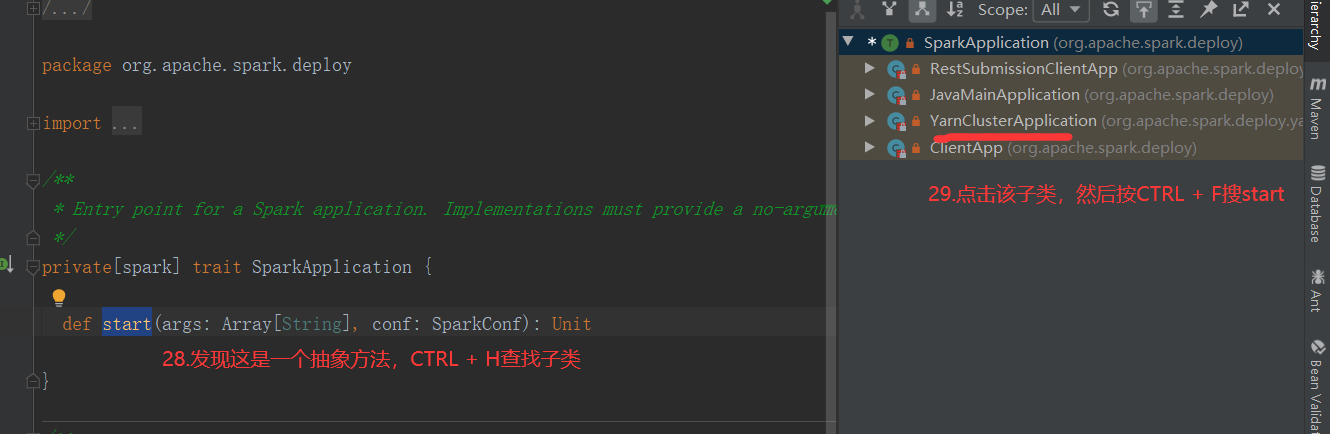
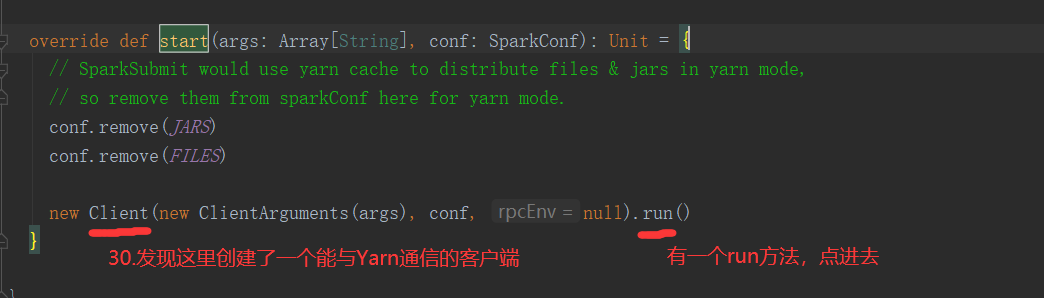
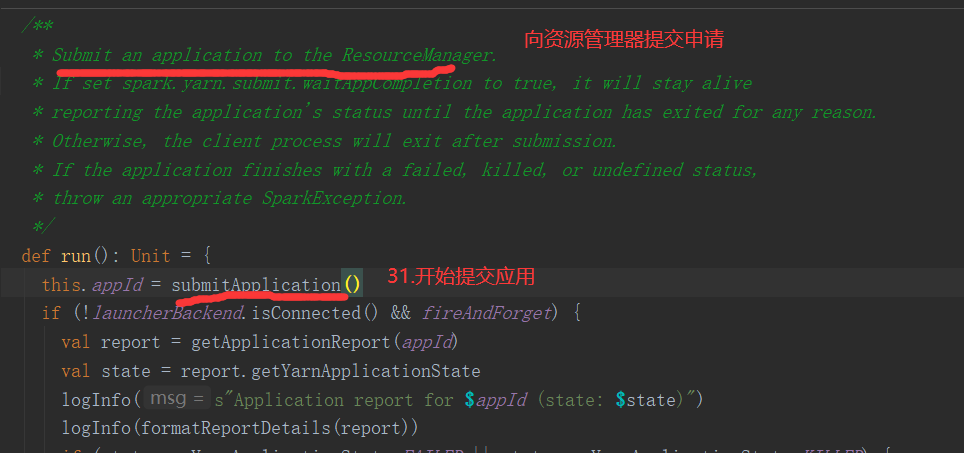
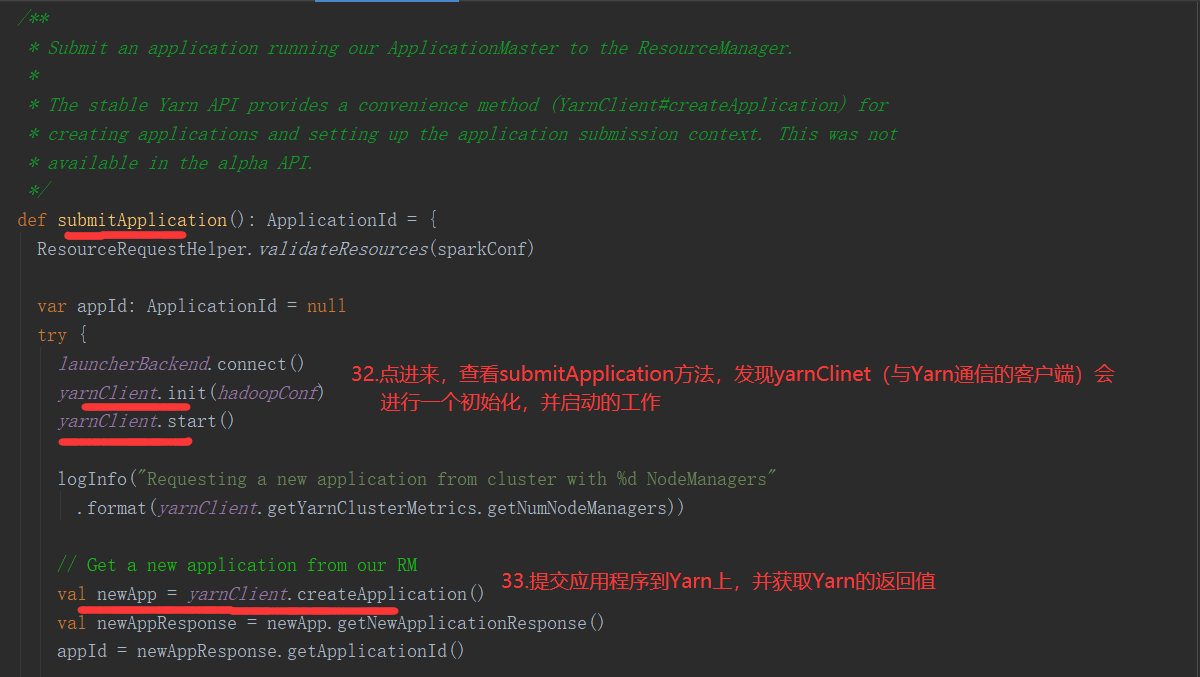
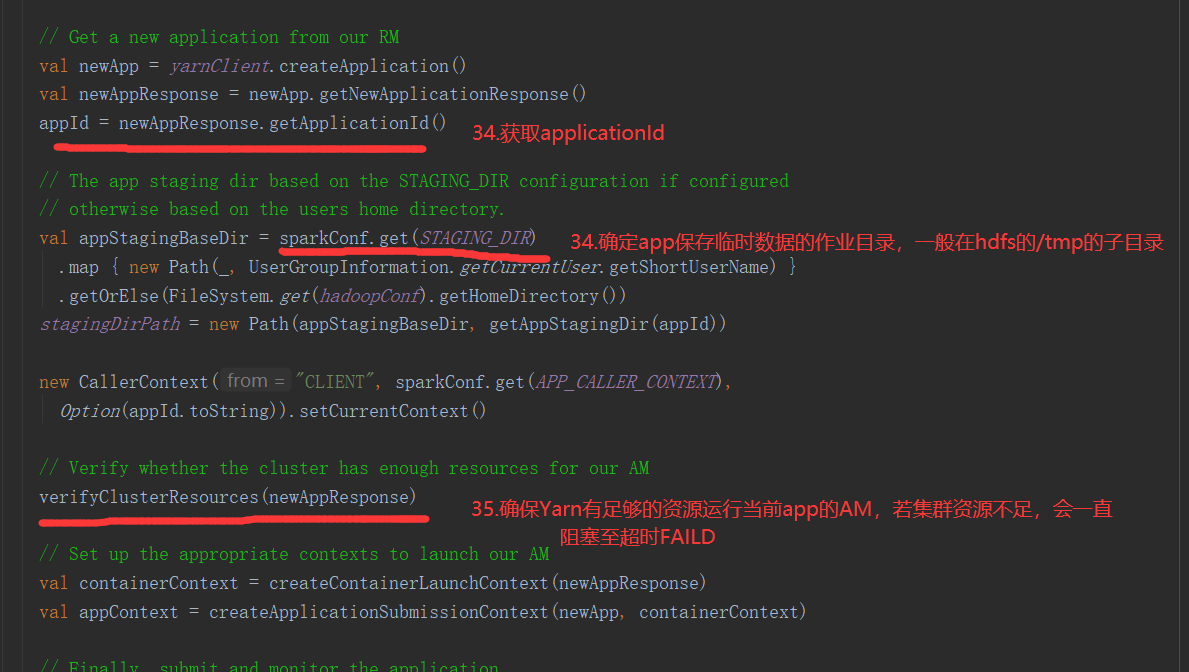
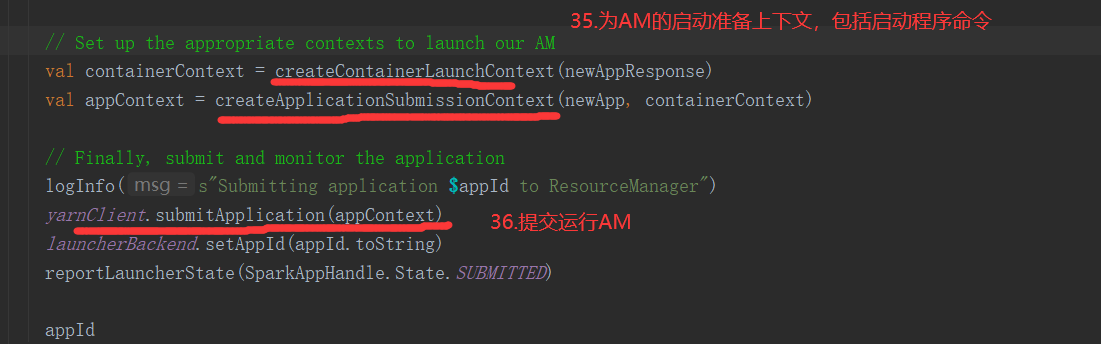


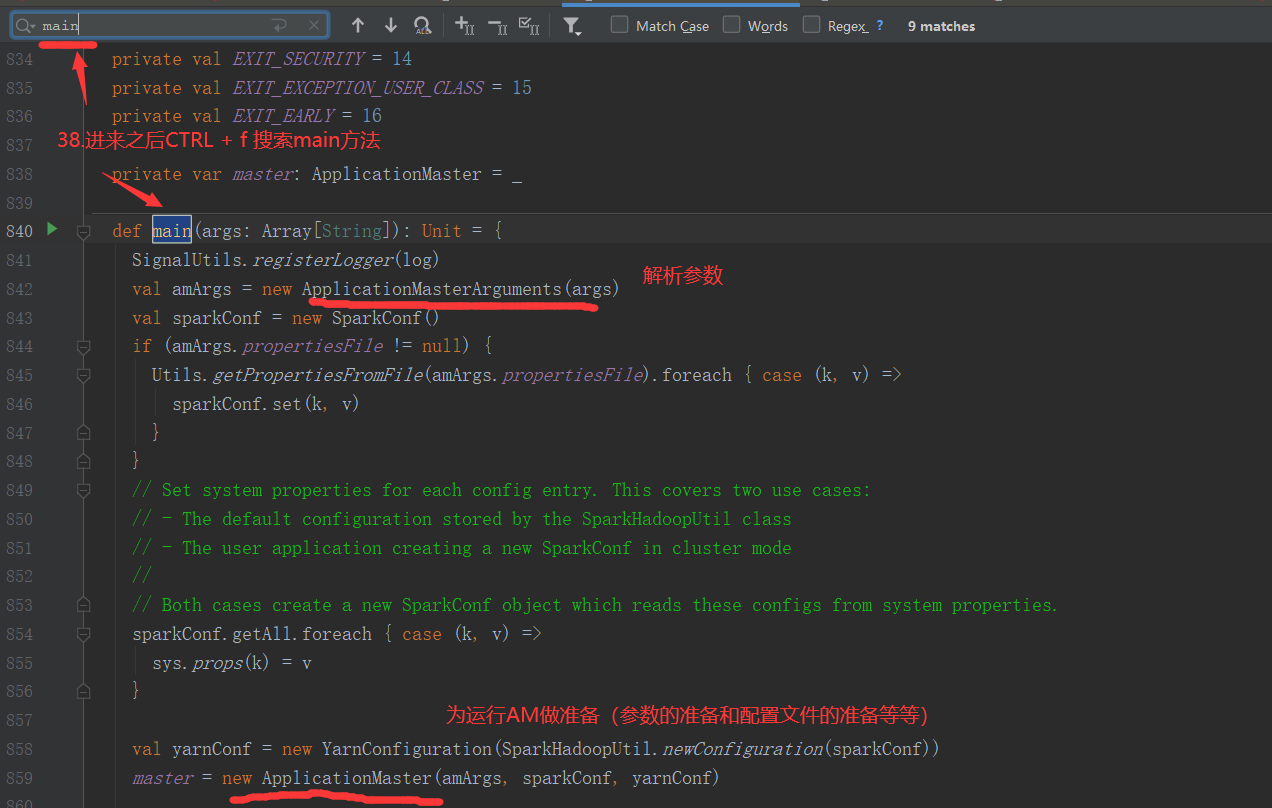






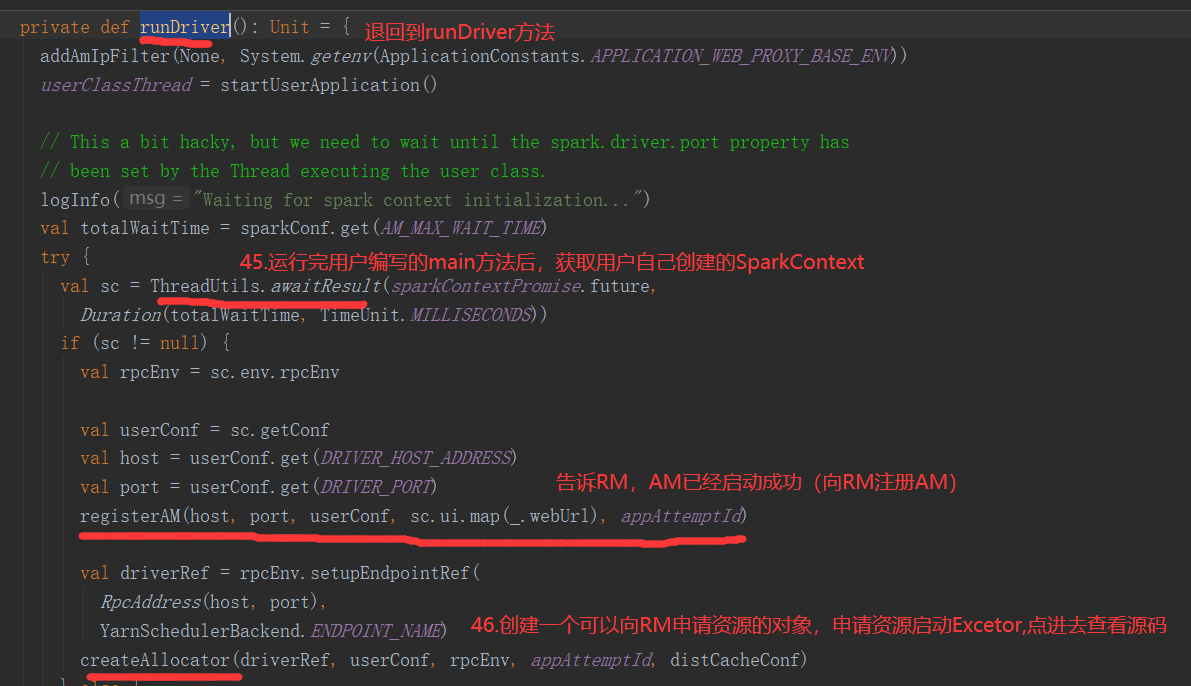
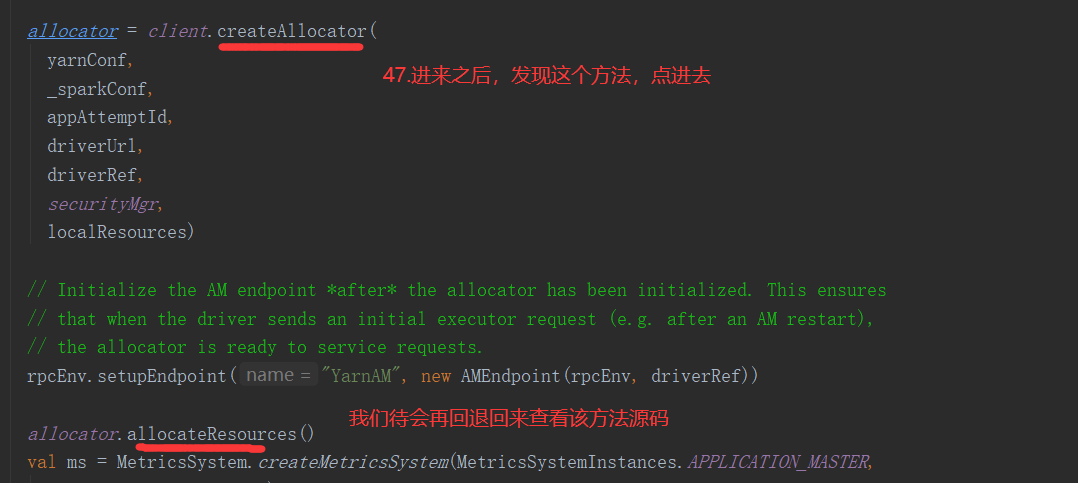
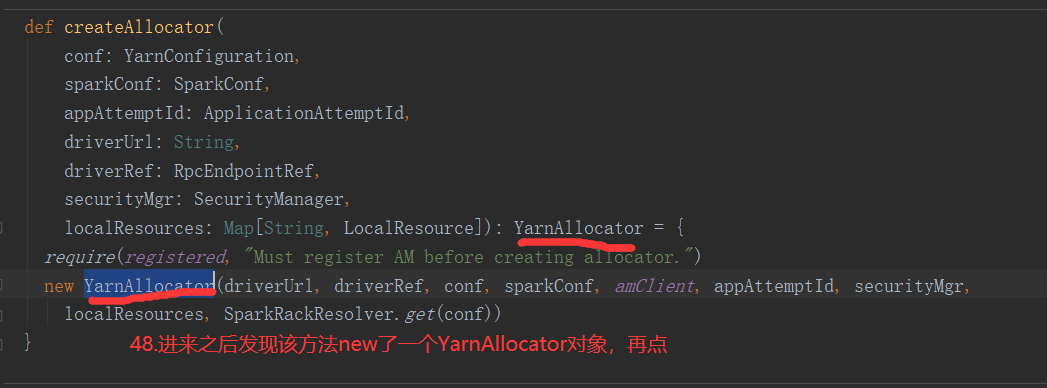

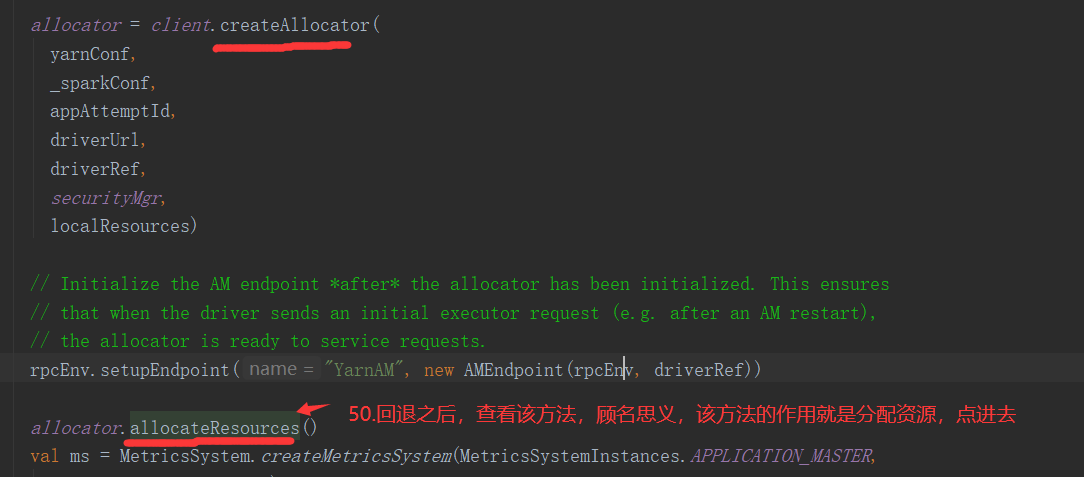






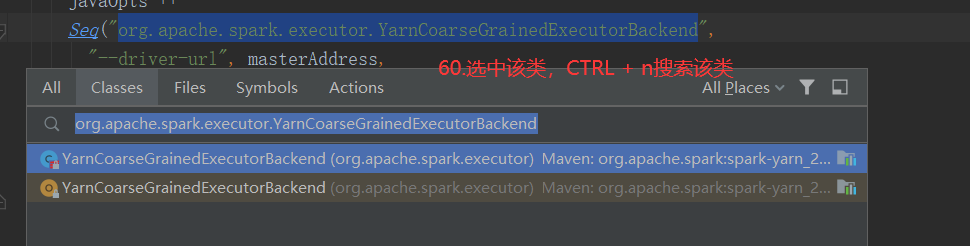














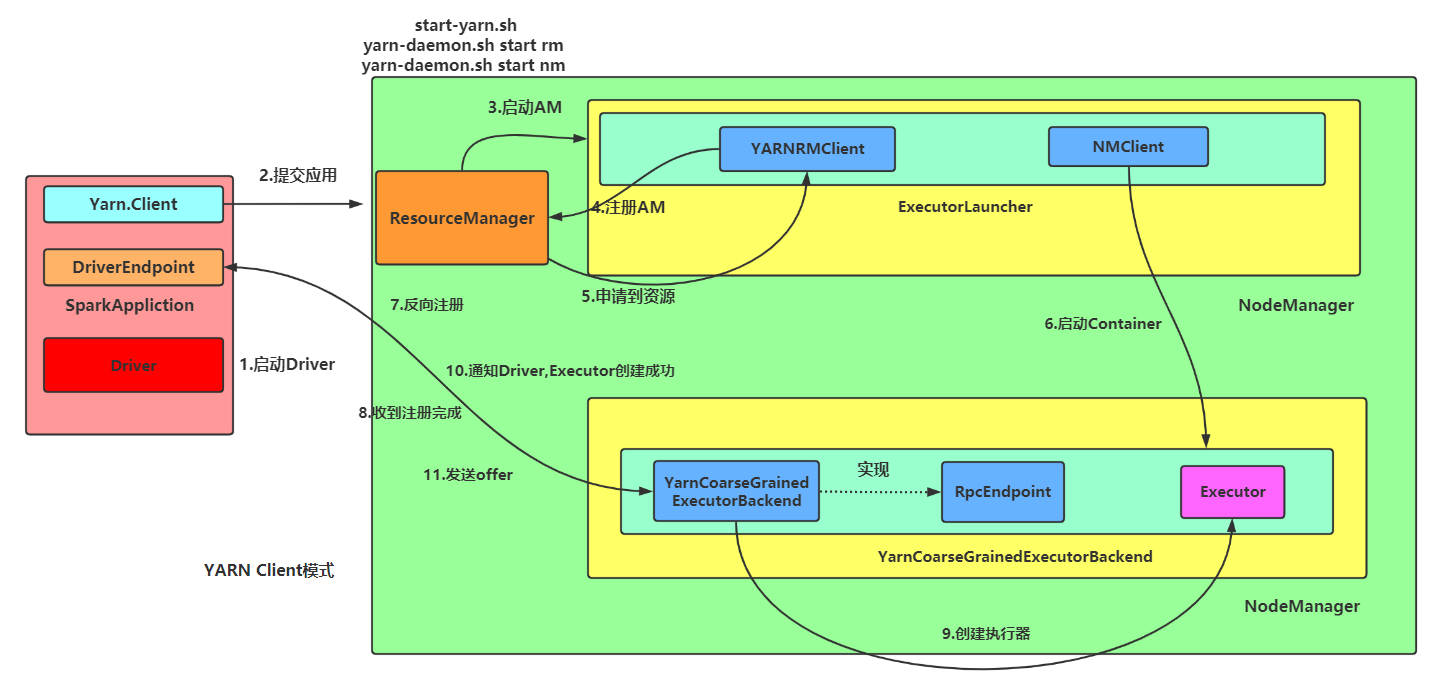
SparkOnYarnCluster提交流程架构图示:
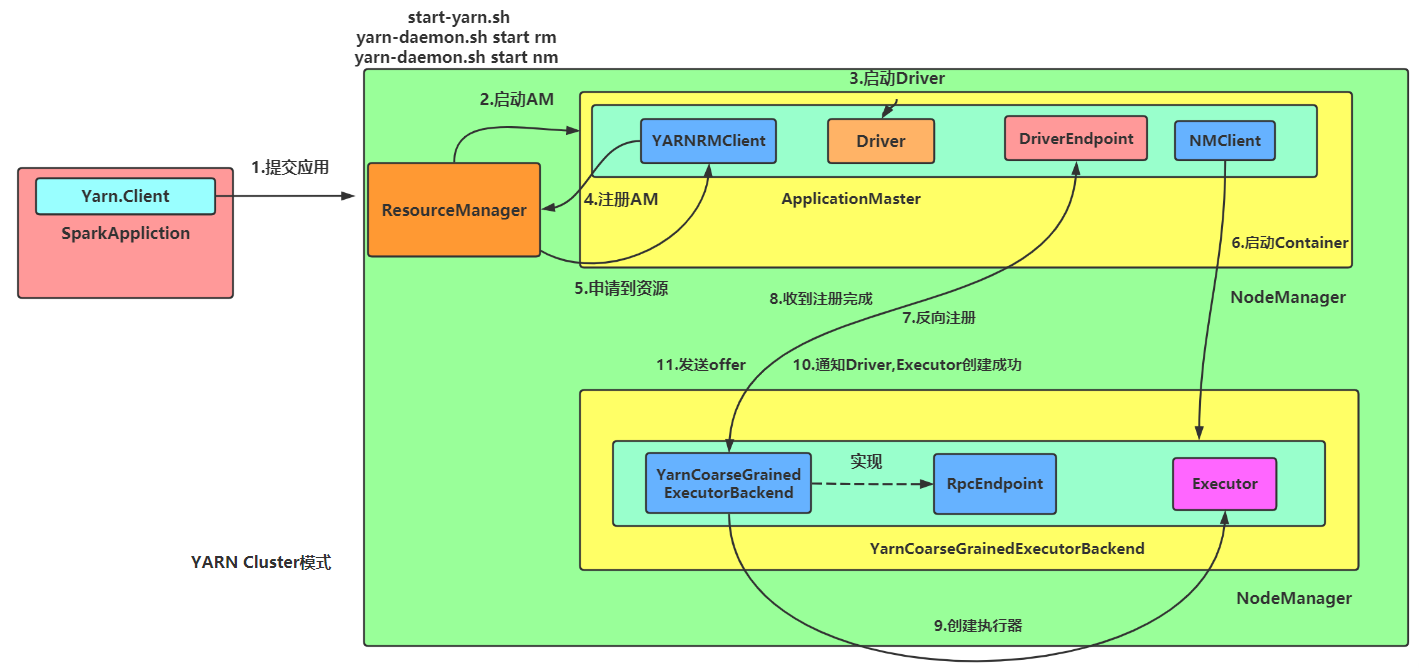
SparkOnYarnClient提交流程源码分析:


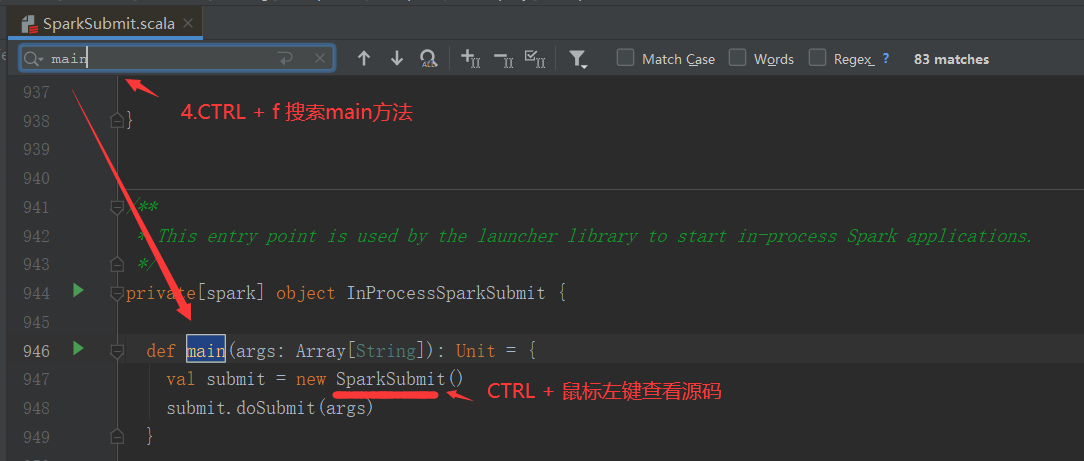
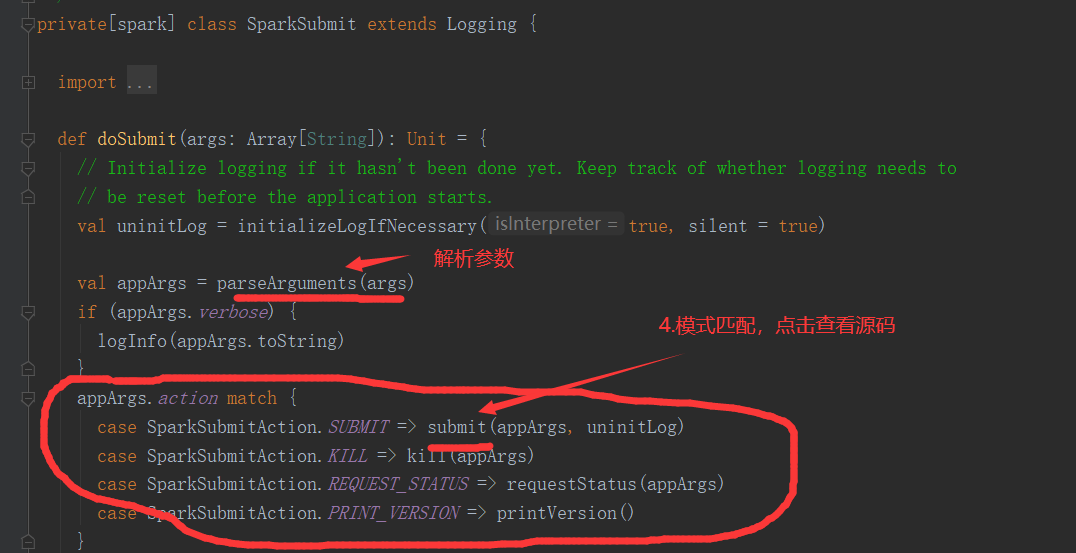




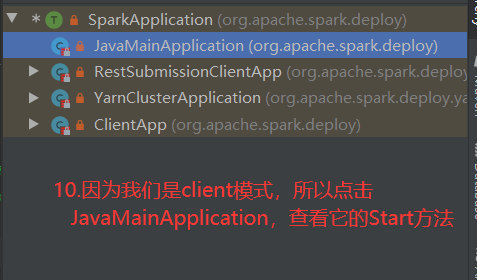
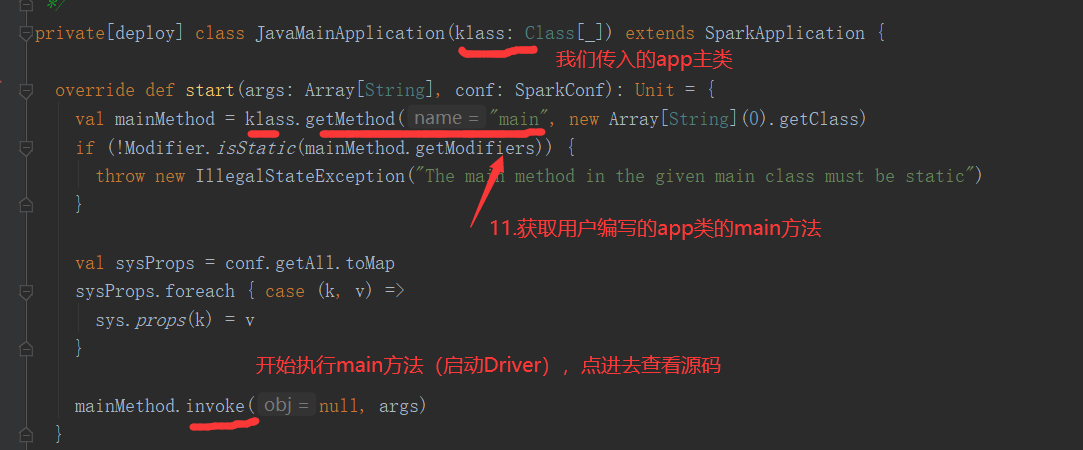





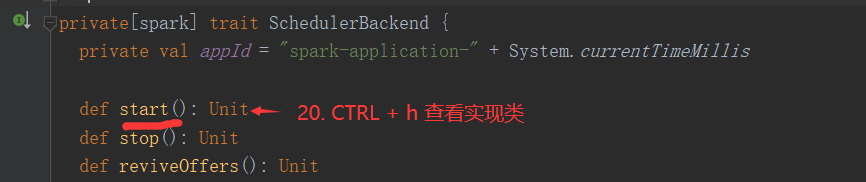


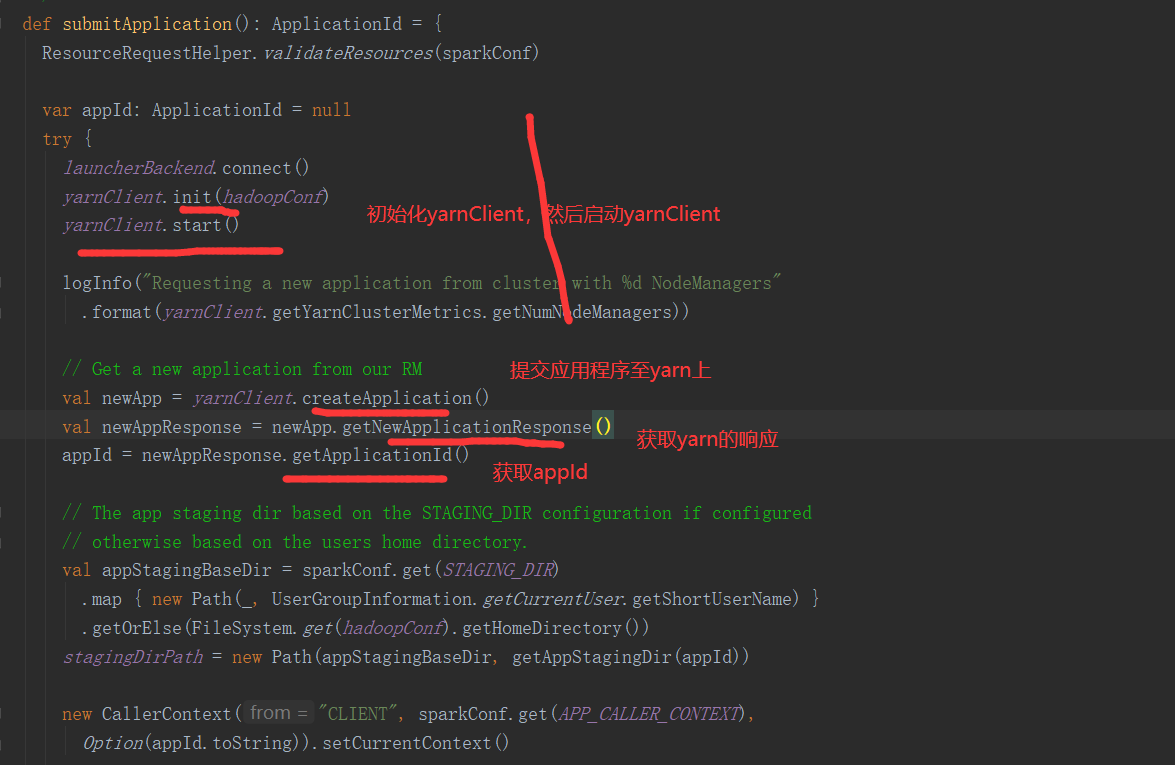
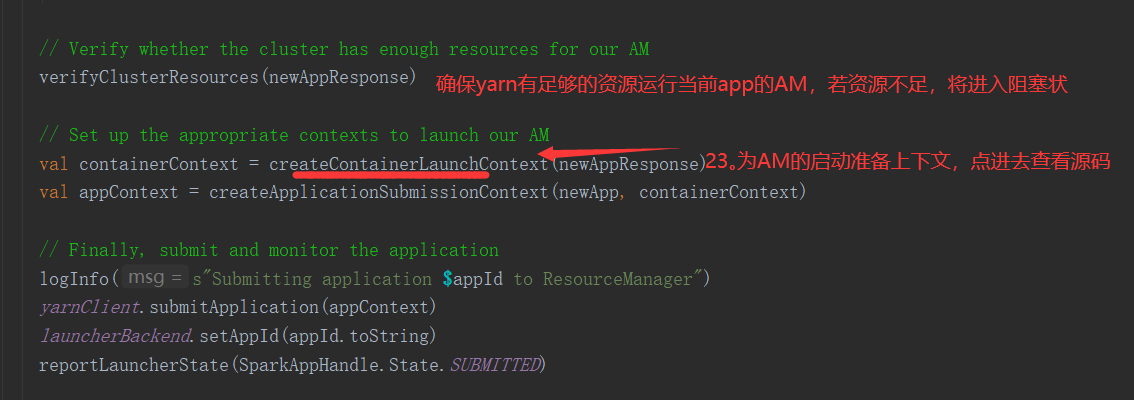









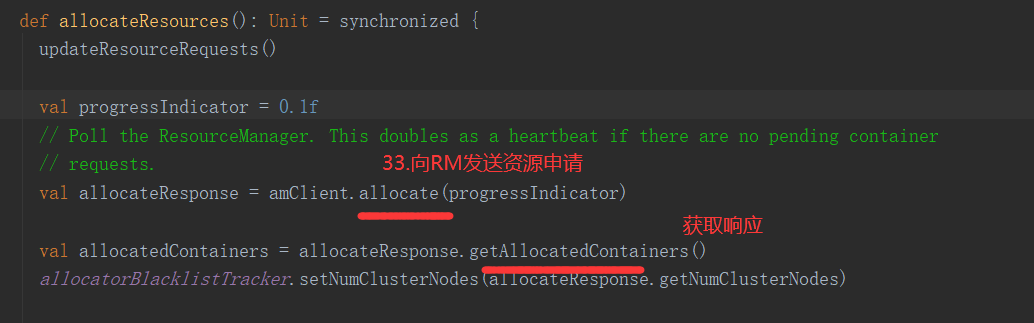

SparkOnYarnClient提交流程:
二、通信
1.IO模型
IO模型: 用什么样的方式进行数据的发送和接受!模型决定了程序通信的性能!
Java支持3种IO模型: BIO,NIO,AIO
三种模型的区别在于通道的数量(单/多),异步还是同步,阻塞还是非阻塞!
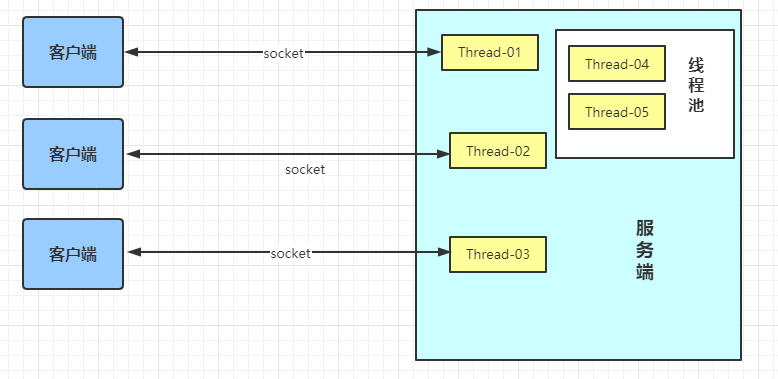
Java BIO: 同步并阻塞(传统阻塞型),服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销。JDK1.4之前的唯一选择!
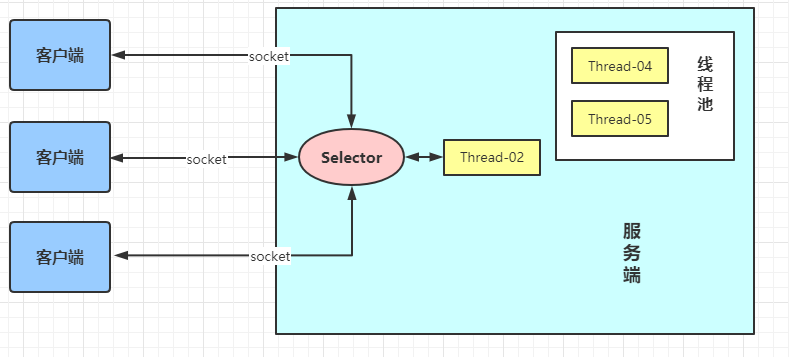
Java NIO : 同步非阻塞,服务器实现模式为一个线程处理多个请求(连接),即客户端发送的连接请求都会注册到多路复用器上,多路复用器(Selector)轮询到连接有I/O请求就进行处理。JDK1.4引入!
Java AIO(NIO.2) : 异步非阻塞,AIO 引入异步通道的概念,采用了 Proactor 模式,简化了程序编写,有效的请求才启动线程,它的特点是先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用。 AIO还没有得到广泛的使用!JDK1.7支持!
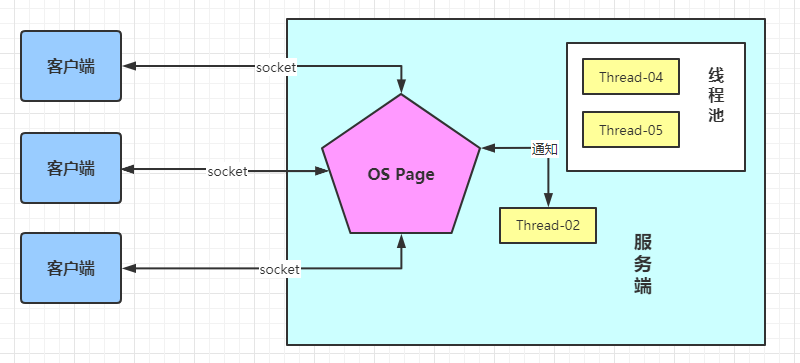
2.RPC
http,https是具体的协议,Tomcat,Jetty 是支持 http,https协议的产品。RPC(远程过程调用),是一种协议的类型,只要符合远程过程调用的特征,都可以称为RPC协议
支持RPC协议的产品例如:
AKKA , Netty ,Dubbo(Dubbo协议,底层还是Netty)
AKKA:IO(阻塞式IO)通信
Netty: NIO(非阻塞式IO)通信
在大数据领域,在分布式系统之间,频繁发送请求,传输数据,NIO效率高(Driver和Executor之间使用RPC(远程过程调用)协议通信)
3.术语介绍
3.1 EndPoint
Endpoint:通信端点,理解为一个要通信的终端进程或设备,一种抽象表达
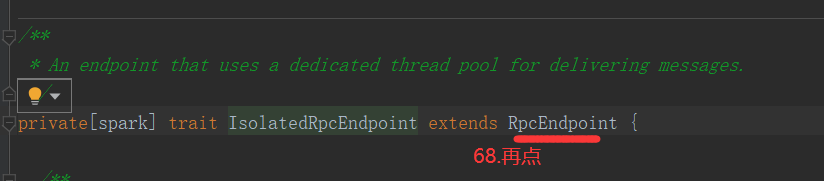
private[spark] trait RpcEndpoint private[spark] trait IsolatedRpcEndpoint extends RpcEndpointt
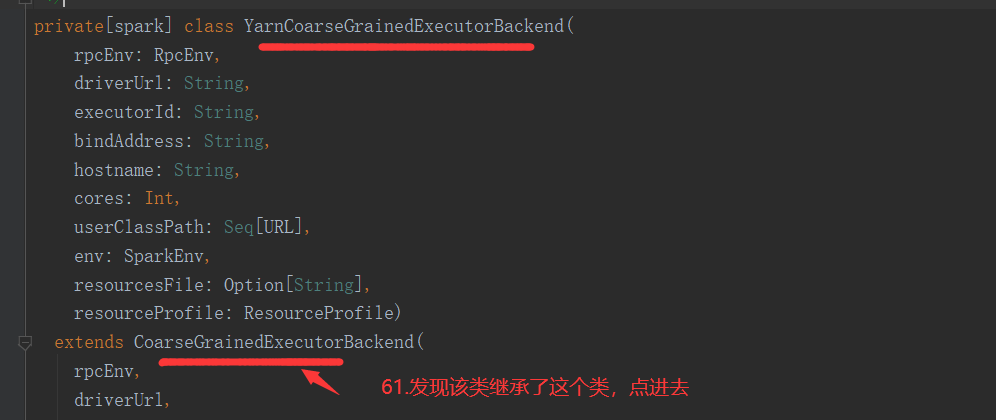
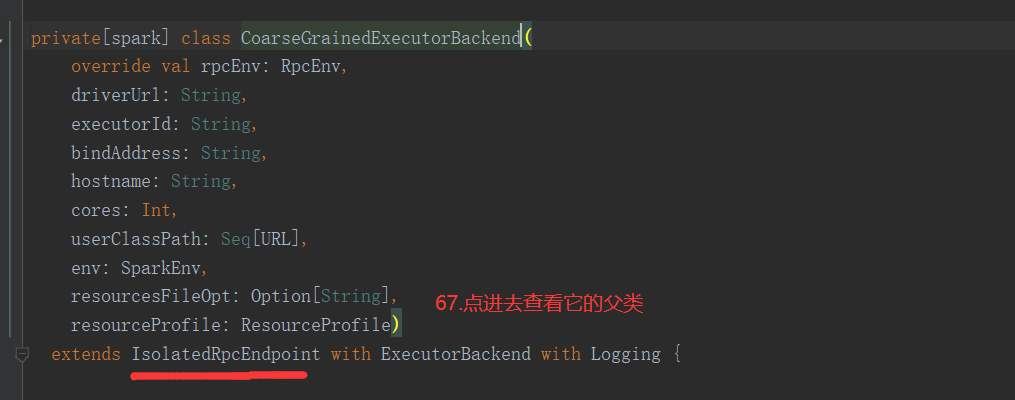
Backend: 通信后台进程服务,具体的通信设备或终端, 例如:CoarseGrainedExecutorBackend。

//Executor的通信终端 private[spark] class CoarseGrainedExecutorBackend( override val rpcEnv: RpcEnv, driverUrl: String, executorId: String, bindAddress: String, hostname: String, cores: Int, userClassPath: Seq[URL], env: SparkEnv, resourcesFileOpt: Option[String], resourceProfile: ResourceProfile) extends IsolatedRpcEndpoint with ExecutorBackend with Logging
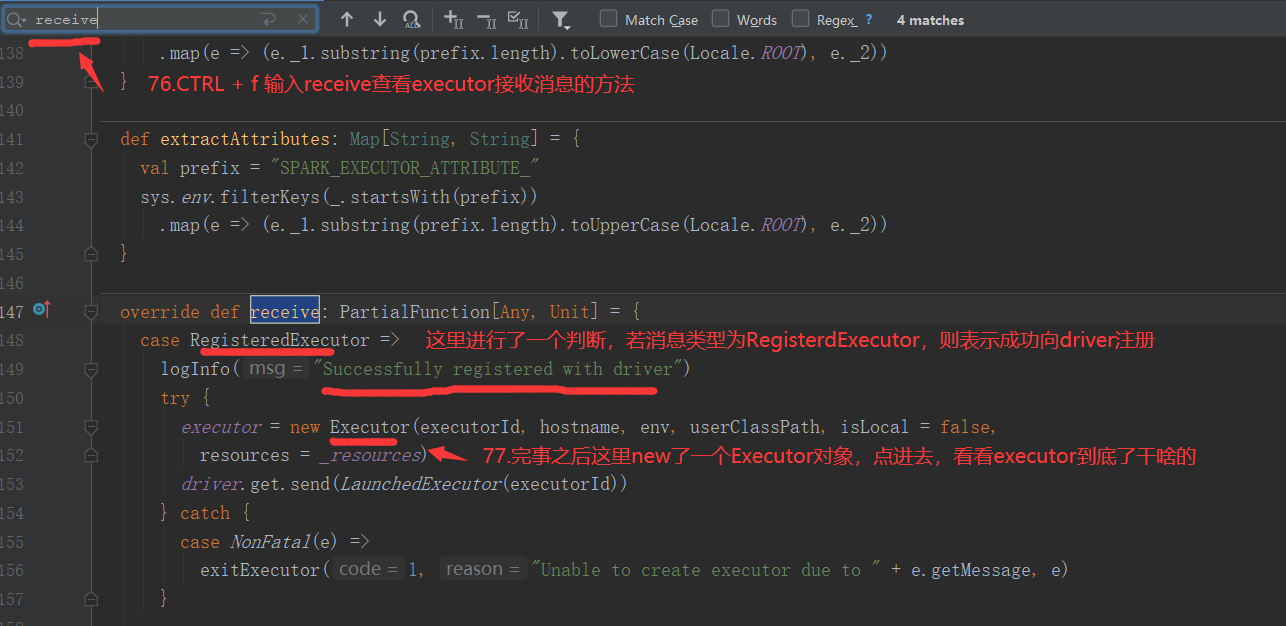
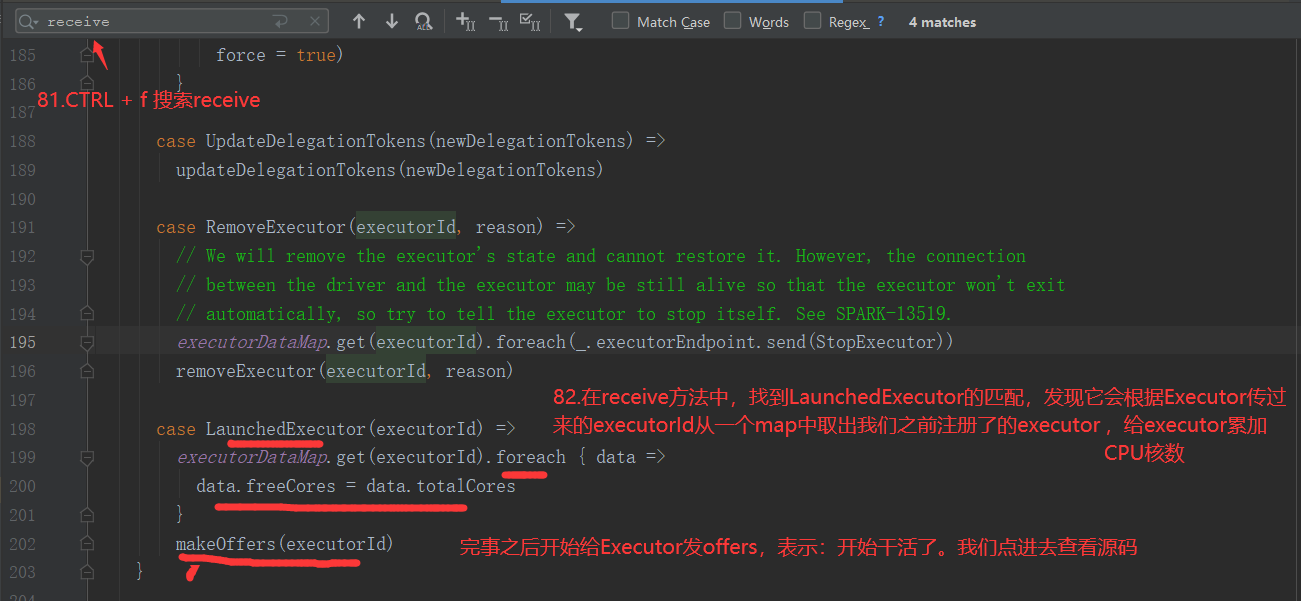
//Driver的通信终端 class DriverEndpoint extends IsolatedRpcEndpoint with Logging
send:单方发送,不要求回复!要查询收件终端的recieve
ask : 发送后要求收到回复,要查询收件终端的recieveAndReply
每个RpcEnpoint都有自己的Inbox(收件箱),和outBox(发件箱),每个RpcEnpoint只有一个Inbox,有多个outBox,每个outBox对应要发送信息的对方的inbox
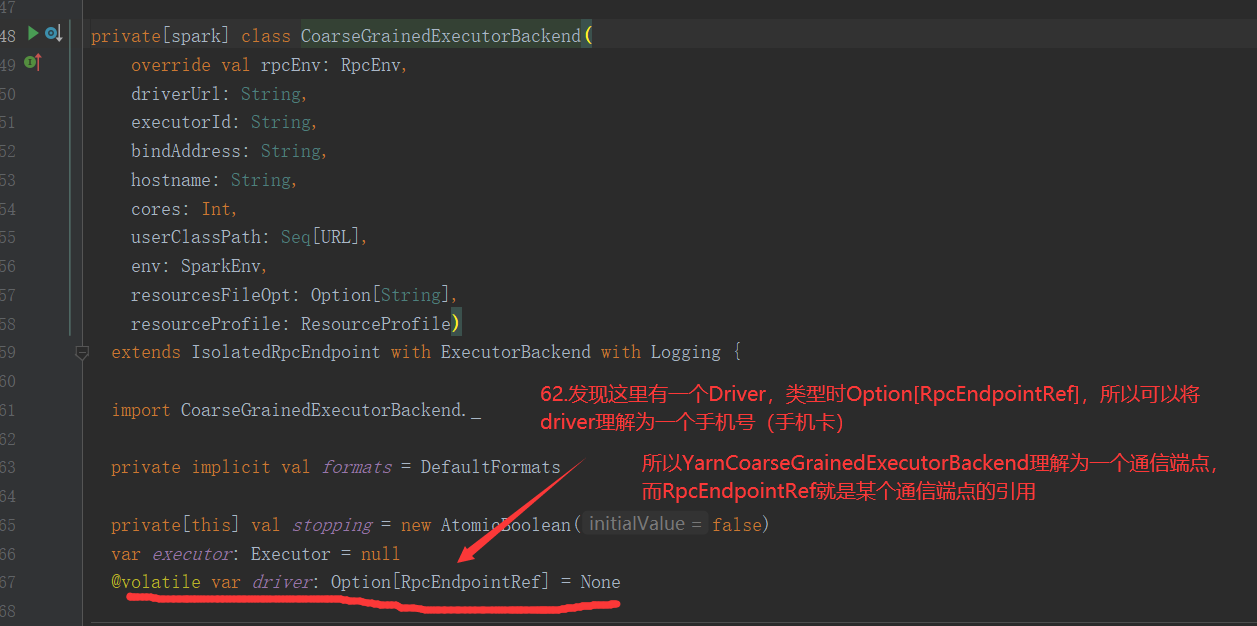
RpcEnpointRef: 通信端点的引用,可以通过引用找到通信端点,类比为手机号或邮箱地址
RpcAdress: 要发送信息的对方设备的IP地址
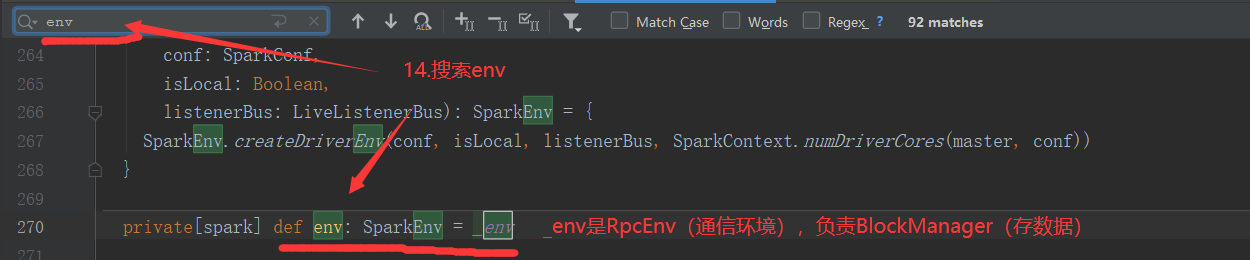
3.2 NettyRpcEnv
NettyRpcEnv: Rpc通信环境,可以类比为 通信网络(联通,移动)
// 分发处理消息 private val dispatcher: Dispatcher = new Dispatcher(this, numUsableCores) // 网络传输通信的服务端 private var server: TransportServer // 当前环境中发向每个 远程设备的 发件箱 RpcAddress(远程设备) private val outboxes = new ConcurrentHashMap[RpcAddress, Outbox]() /* 调用dispatcher.regist() 为每个EndPoint创建一个Inbox,在Inbox中放入onStart() */ rpcEnv.setupEndpoint
每个Rpc的通信端点,必须加入到通信环境中,才能通信(必须插入联通的手机卡,连上联通的网络,才能使用联通的通信服务)
NettyRpcEnv.setUpEndPoint("设备名",设备)
RpcEnpoint在加入到NettyRpcEnv后,都需要进行初始化 onStart
Dispatcher: 一个通信网络中有一个Dispatcher(类似呼叫中心,或基站)负责将消息路由到指定的线路
TransportClient: 每个NettyRpcEnv都有一个TransportClient,网络传输客户端
TransportServer: 每个NettyRpcEnv都有一个TransportServer,网络传输服务端
3.3 Dispathcer
每个RpcEnv中都有一个负责分发消息的Dispathcer(呼叫中心 / 基站):
// 分发消息 private[netty] class Dispatcher(nettyEnv: NettyRpcEnv, numUsableCores: Int) extends Logging { // 每个设备 及其 MessageLoop private val endpoints: ConcurrentMap[String, MessageLoop] = new ConcurrentHashMap[String, MessageLoop] // 记录在当前RpcEnv中注册的所有设备及其引用 private val endpointRefs: ConcurrentMap[RpcEndpoint, RpcEndpointRef] = new ConcurrentHashMap[RpcEndpoint, RpcEndpointRef]
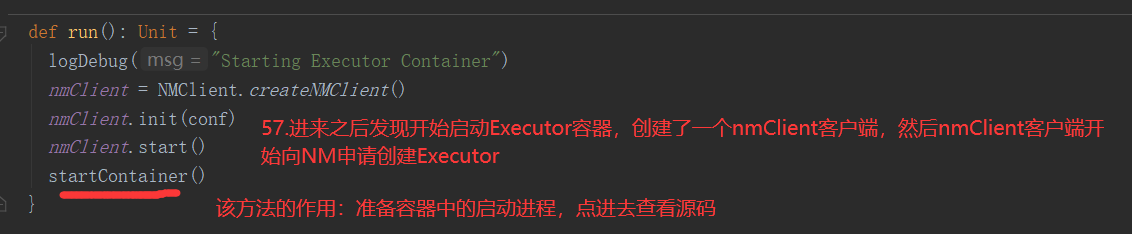
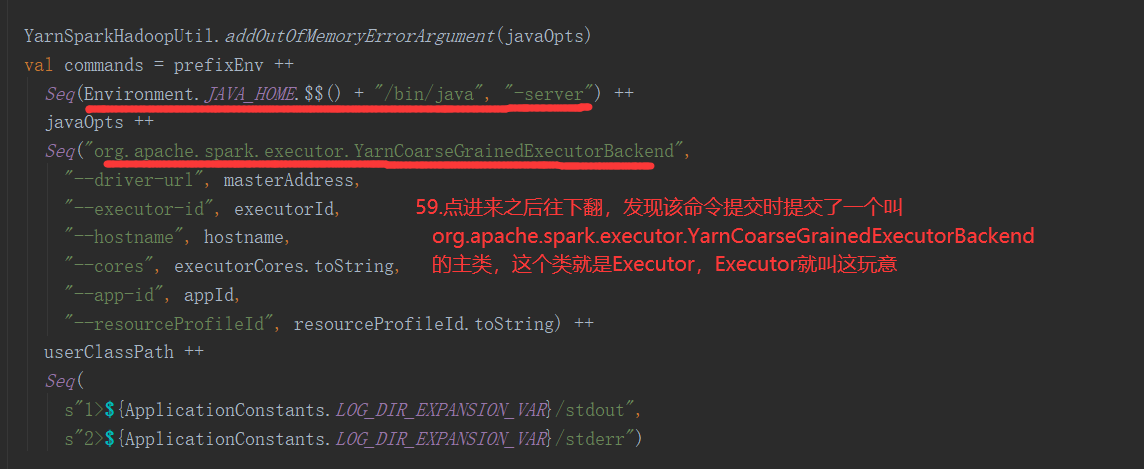
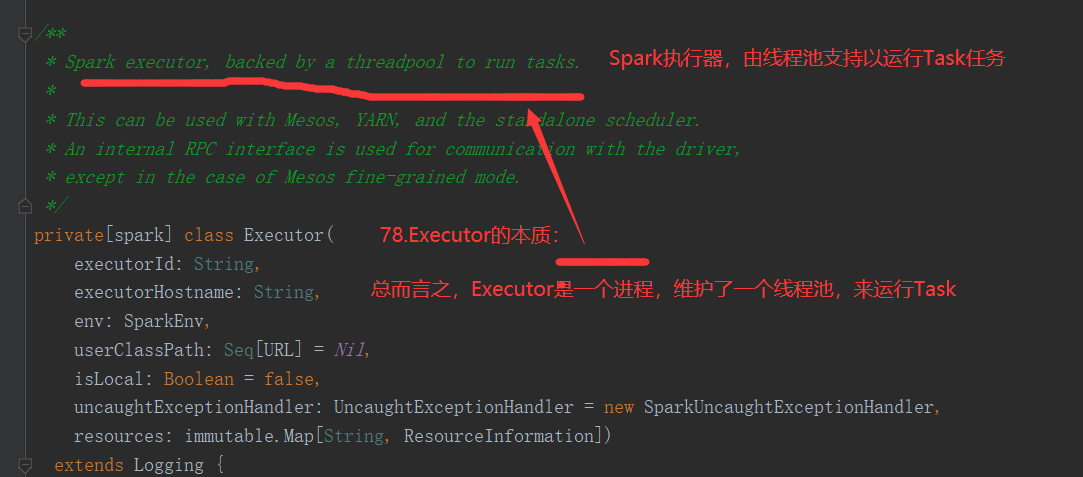
4.什么是Executor
语境(上下文):
①从通信角度:
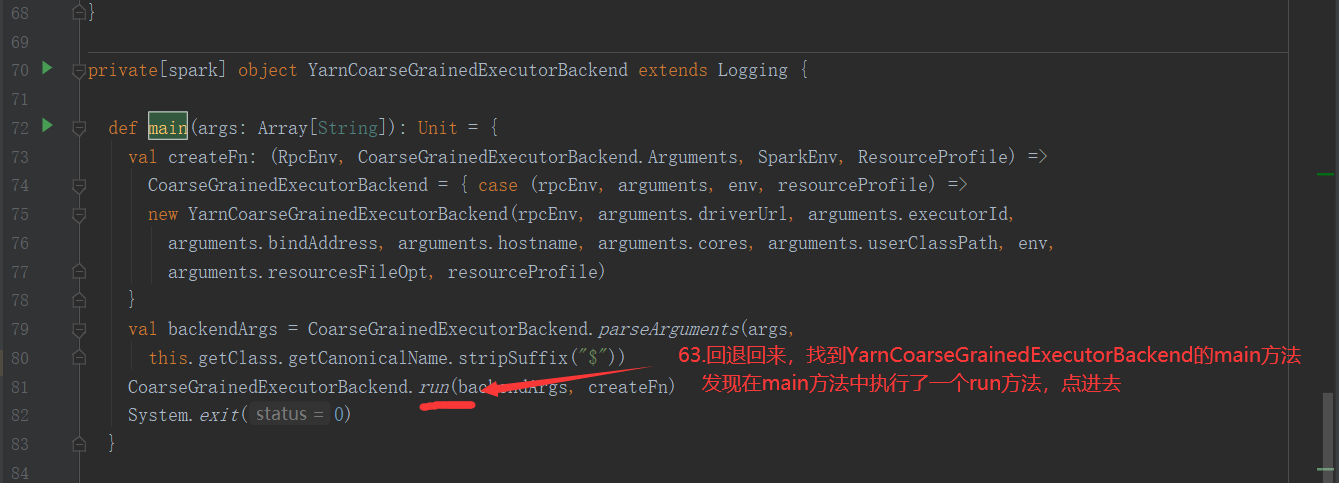
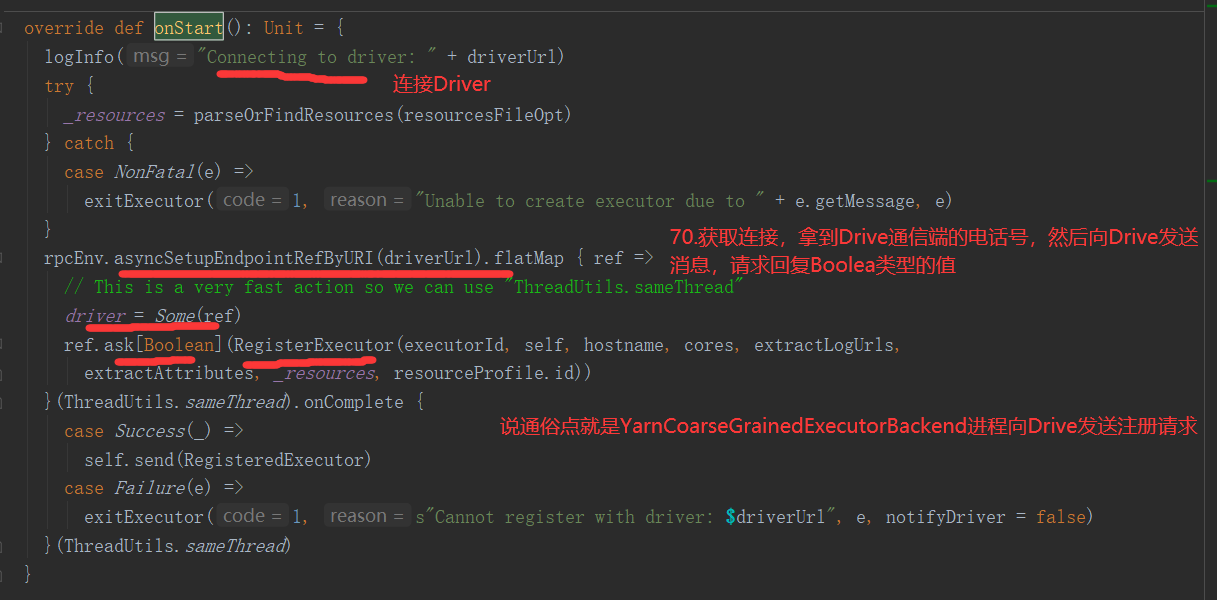
Executor: 在源码中,从整个架构来说,一个CoarseGrainedExecutorBackend就是一个Executor,CoarseGrainedExecutorBackend是 YarnCoarseGrainedExecutorBackend的一个通信后台
Executor就是Container容器中启动的YarnCoarseGrainedExecutorBackend进程,启动几个Container,就会启动几个Executor
②Job运算的角度讲,实际上: 每个CoarseGrainedExecutorBackend还有一个属性
// Executor 计算器,计算者,负责运行task,例如启动,杀死 var executor: Executor = null
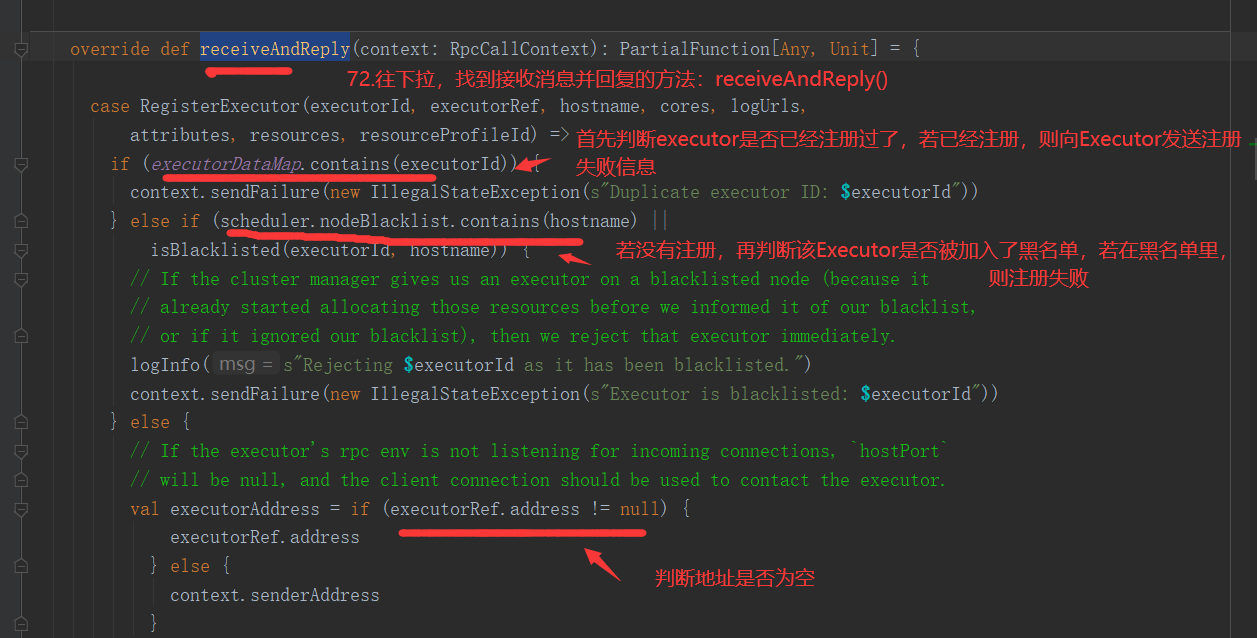
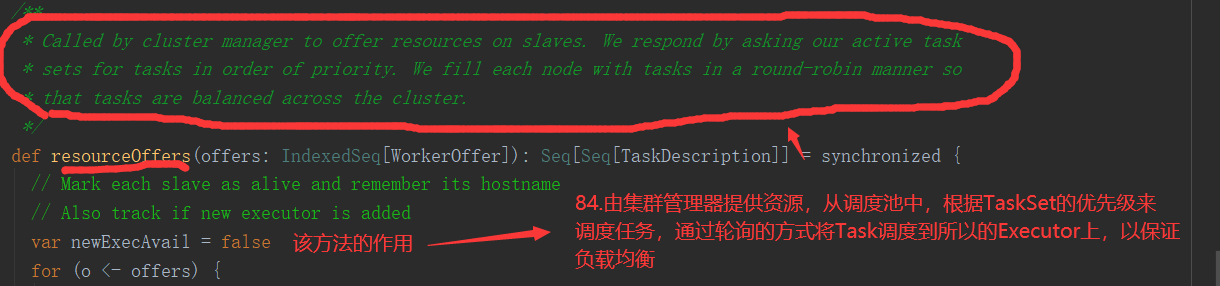
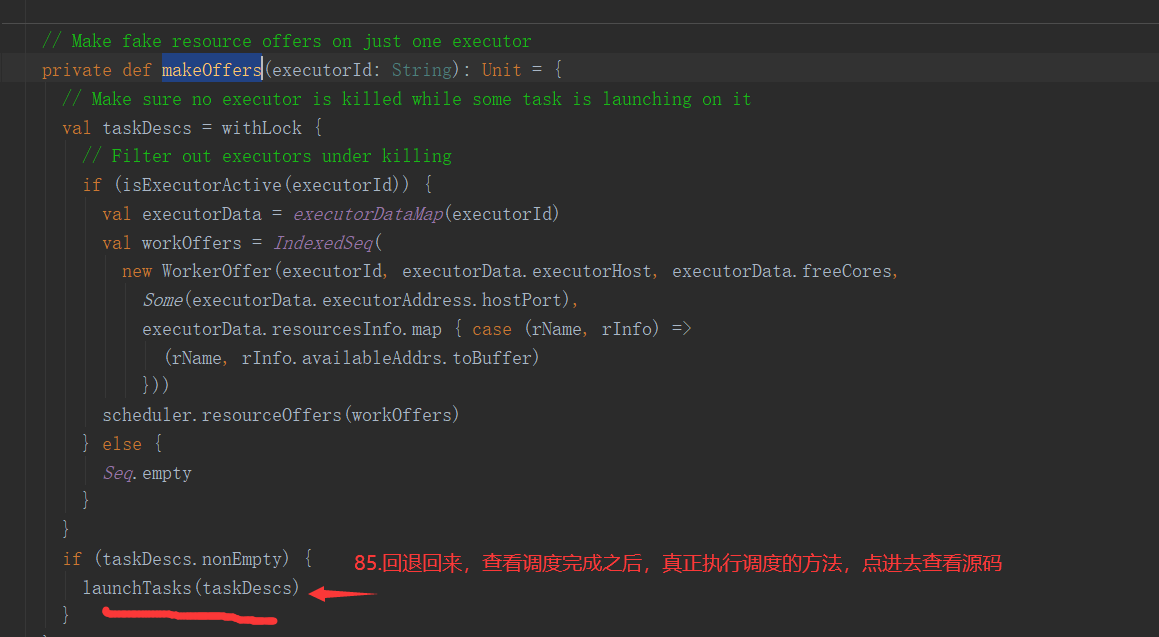
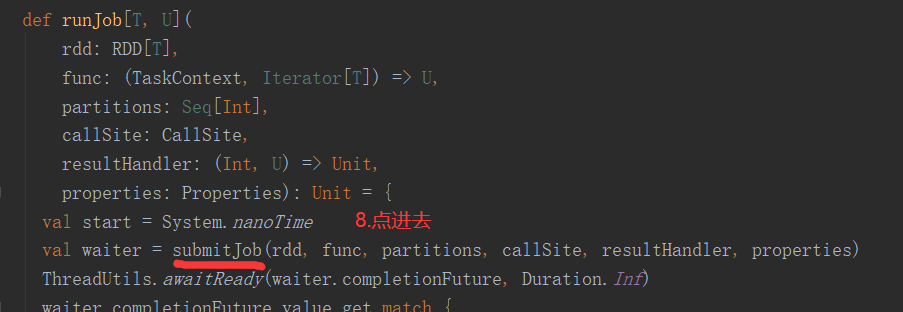
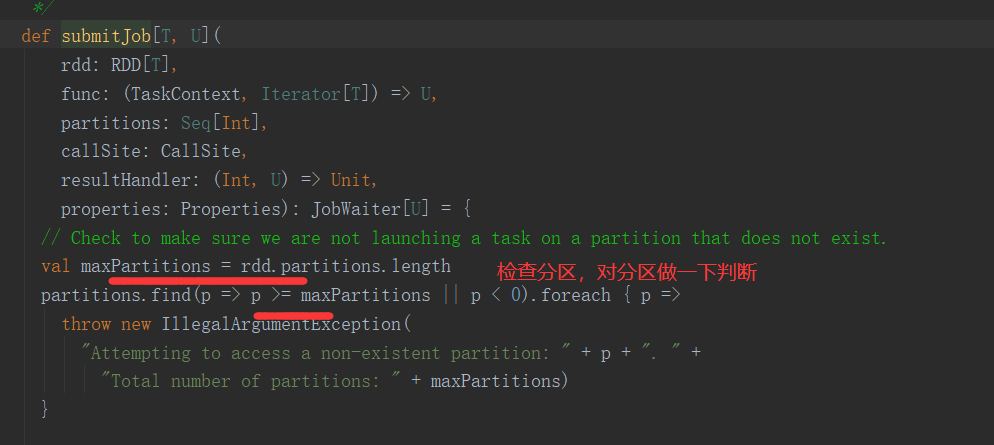
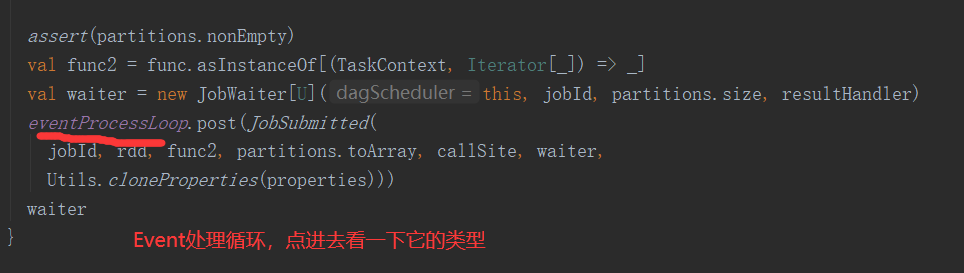
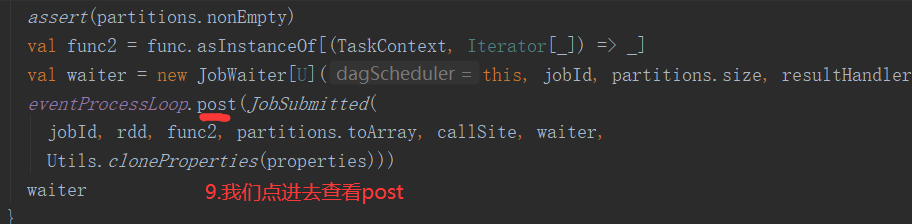
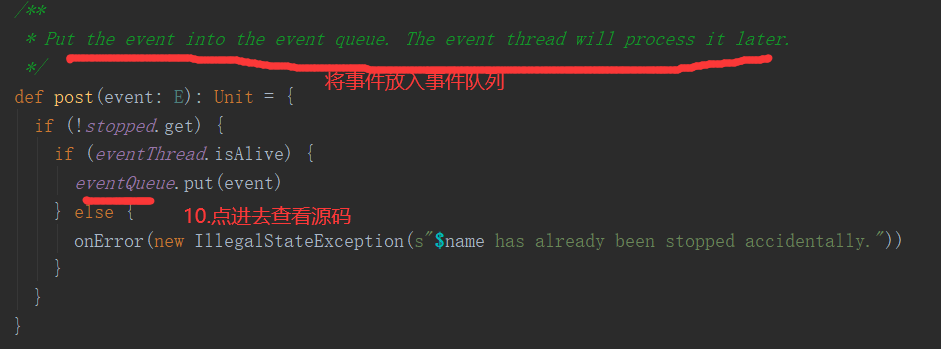
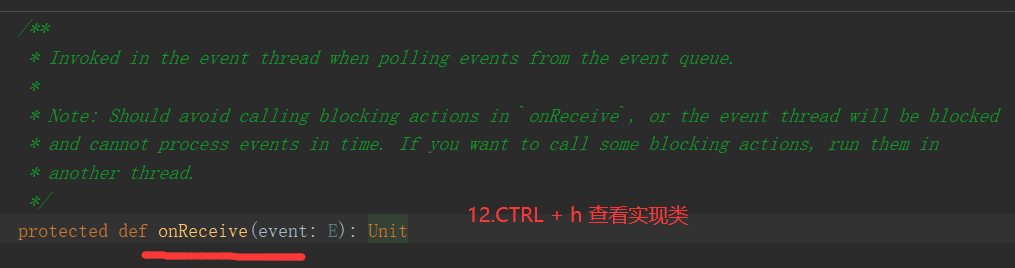
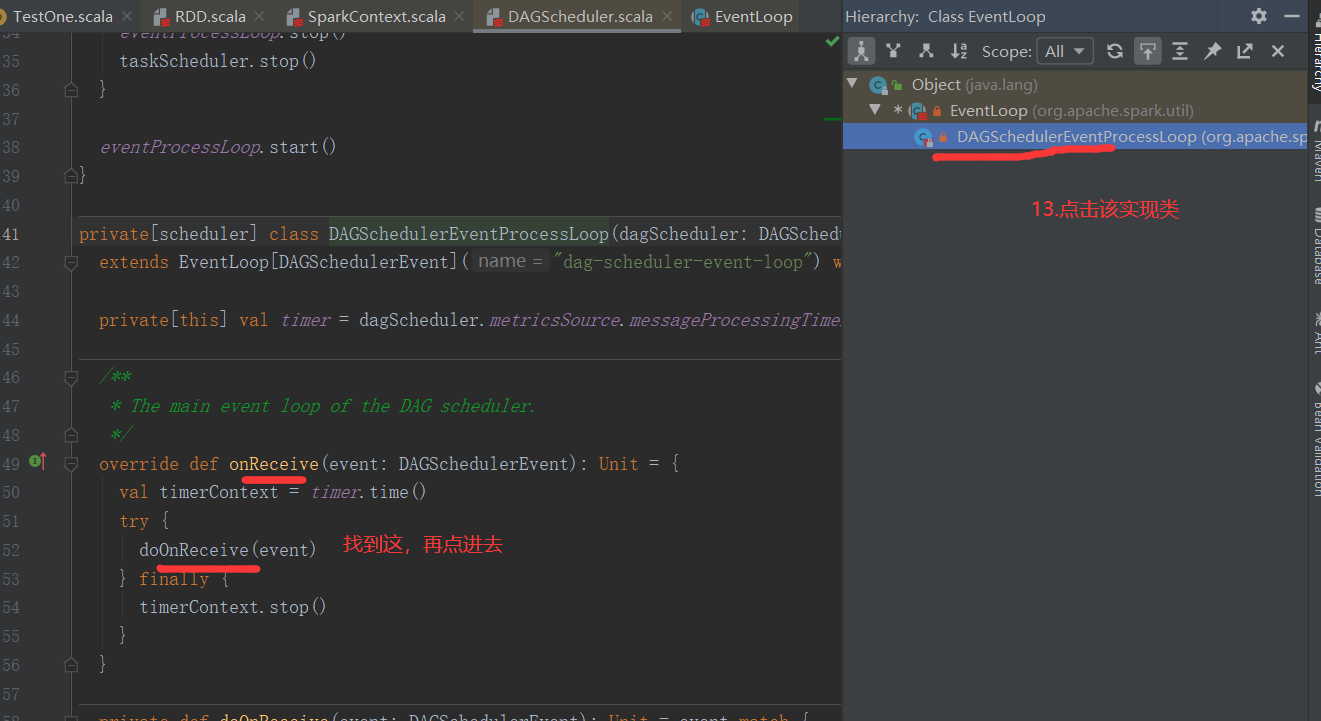
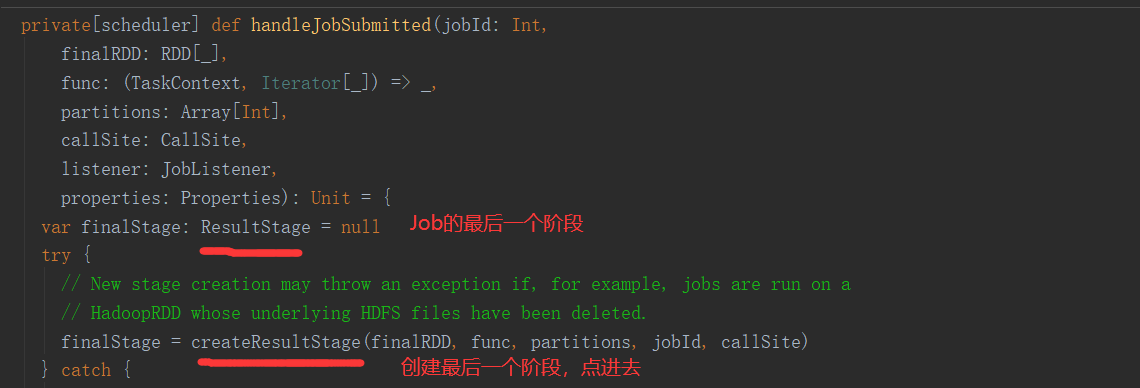
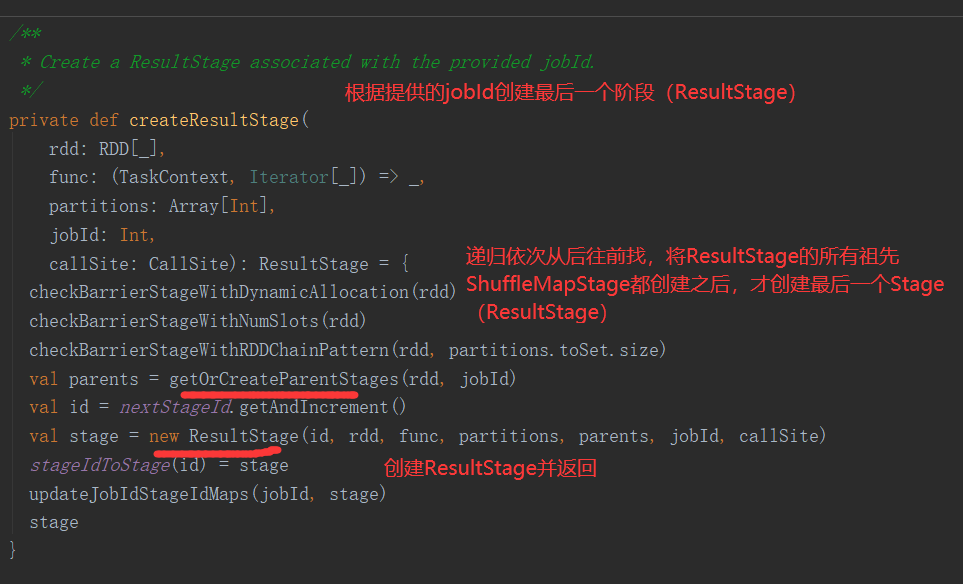
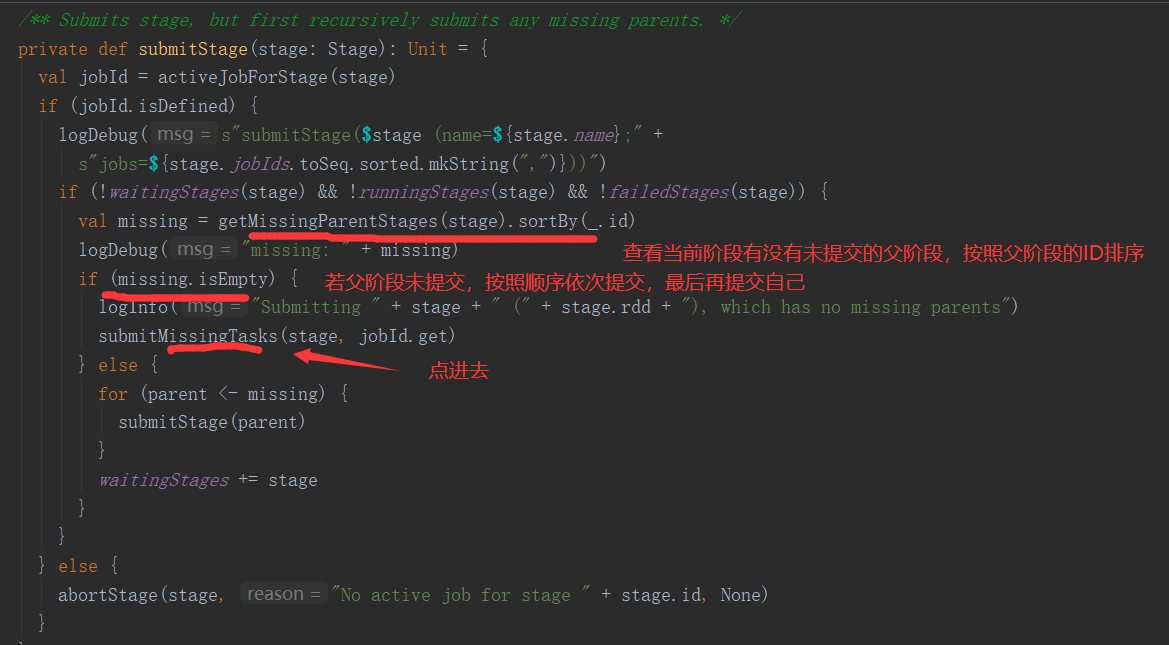
三、Job的提交
1.提交流程图
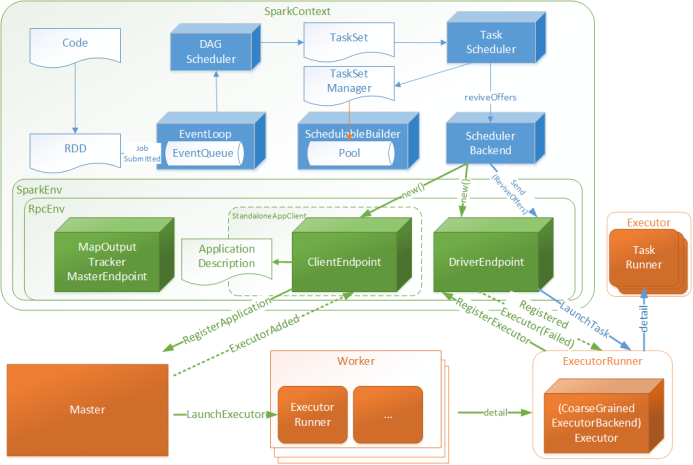
Job提交流程图源码解析:
//数据准备 def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) val rdd = sc.makeRDD(List(1,2,3,4)) rdd.collect() //关闭连接 sc.stop() }



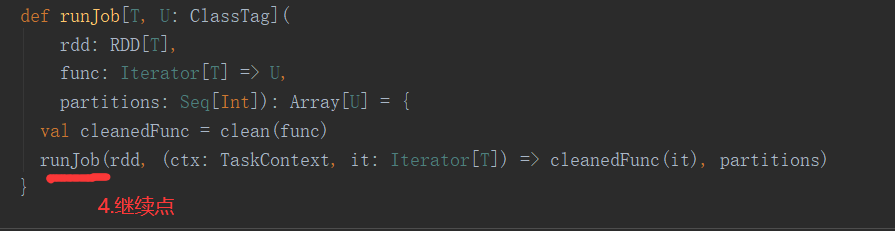

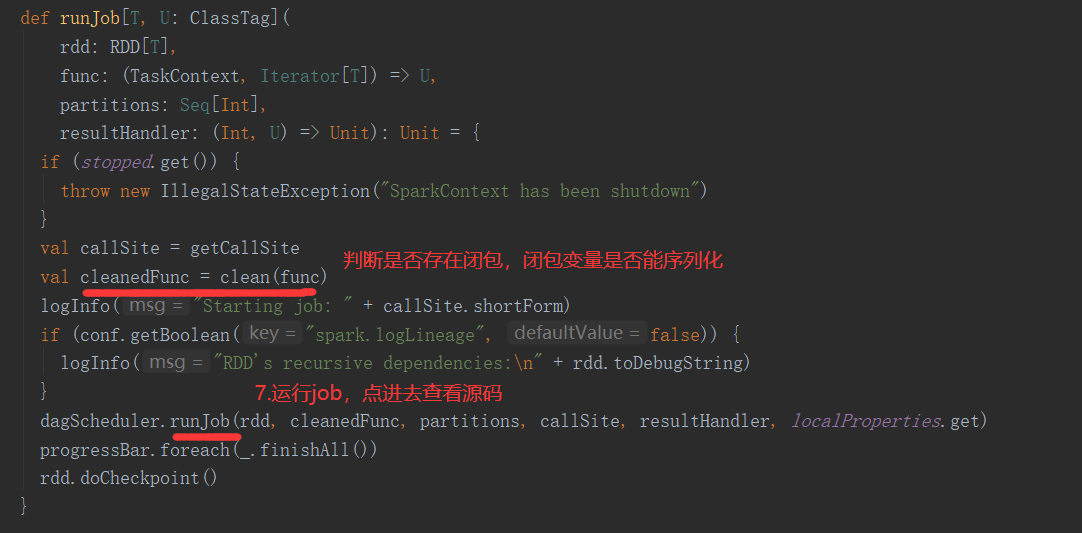












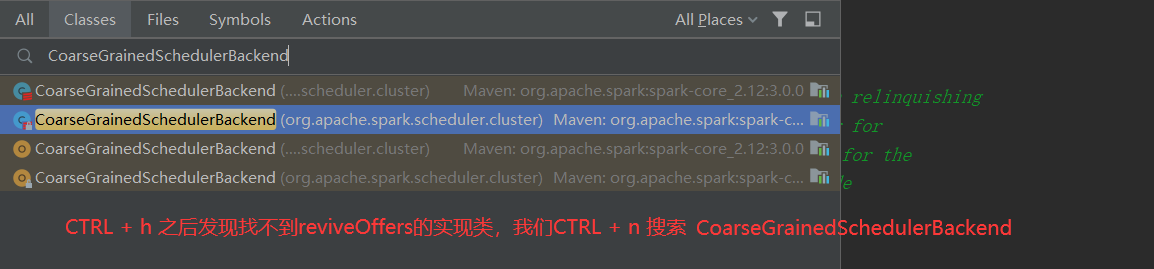
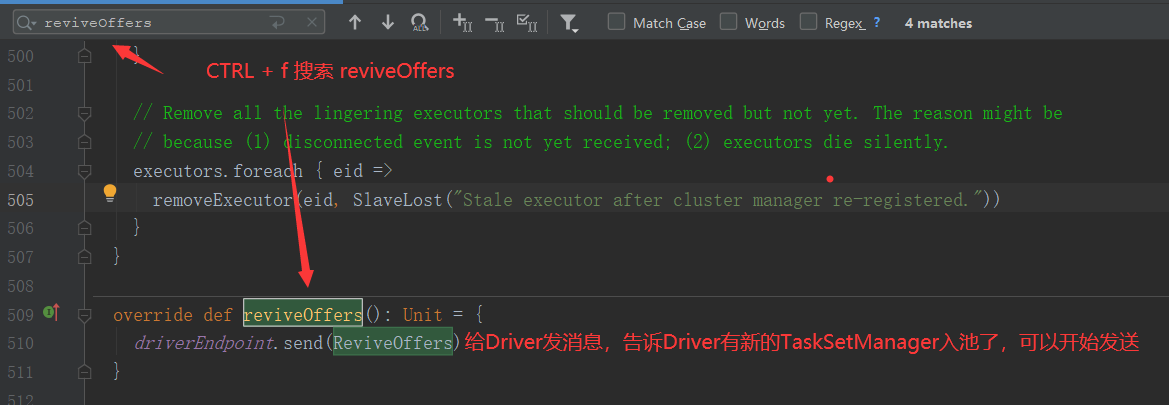
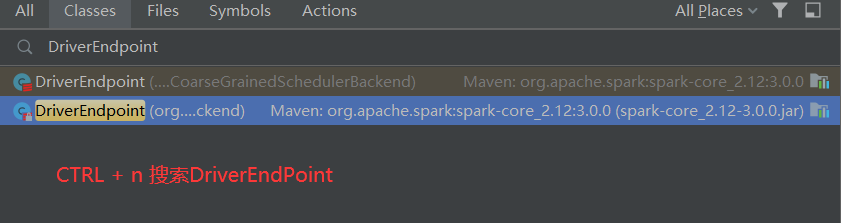

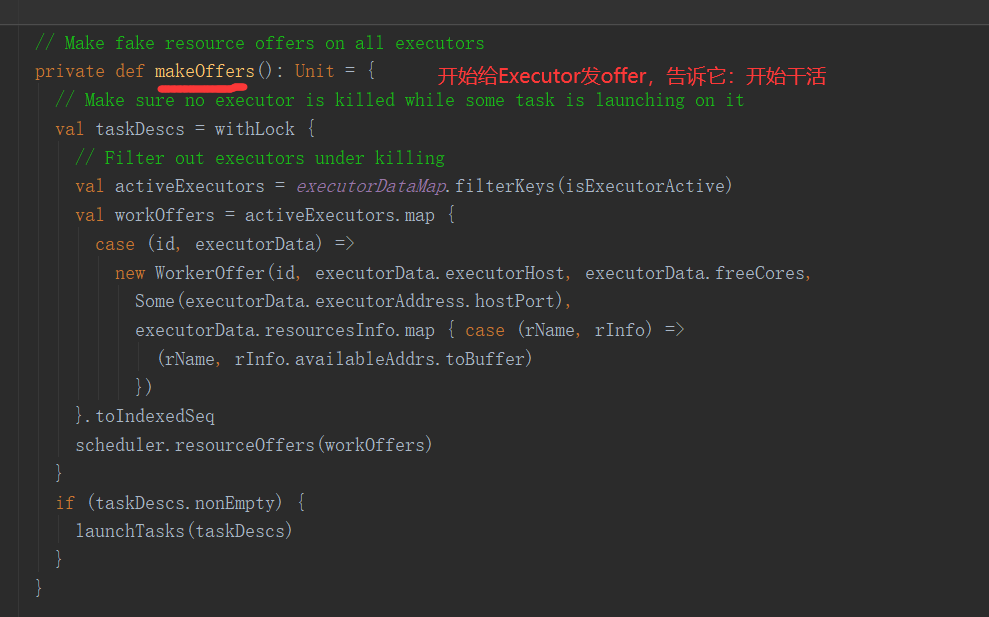
2.常见API
2.1 Stage
Stage是一组并行的Task,这些Task都用相同的shuffle依赖,并且都运行相同的函数,所有的Task都会被调度器调度运行,而它们的DAG运行图会由于shuffle的产生,而进行切分为多个阶段,然后 DAGScheduler按照拓扑结构的顺序运行这些阶段。每一个Stage都可以是一个ShuffleMap stage,或者是ResultStage。
ShuffleMap stage中的task运算的结果会作为其他阶段的输入,而ResultStage会直接运行Spark的行动算子,对于ShuffleMap Stage,Spark还会追踪Map输出所在的节点。
每一个Stage都有一个firstJobId,用于标识首先提交次Stage的Job,如果是FIFO调度器,那么将允许早期提交的Job先计算,或者先容错恢复。
每个Stage都会在出现错误时,都会重新尝试计算多次
private[scheduler] abstract class Stage( val id: Int, // stage的id,后续调度时,ID小的stage一般是靠前的,会优先执行 val rdd: RDD[_], // stage的最后一个RDD val numTasks: Int, //在 ShuffleMapStage 等于 当前Stage的最大分区数,在ResultStage,取决于使用的算子 val parents: List[Stage], // 父Stage val firstJobId: Int, // 运行的第一个Job的Id val callSite: CallSite) extends Logging
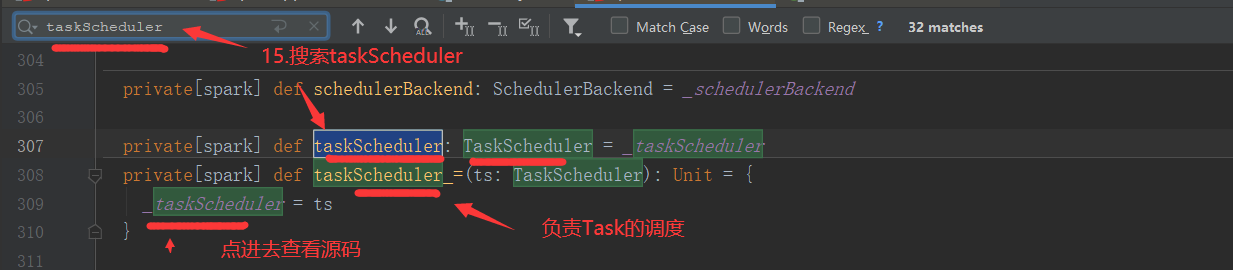
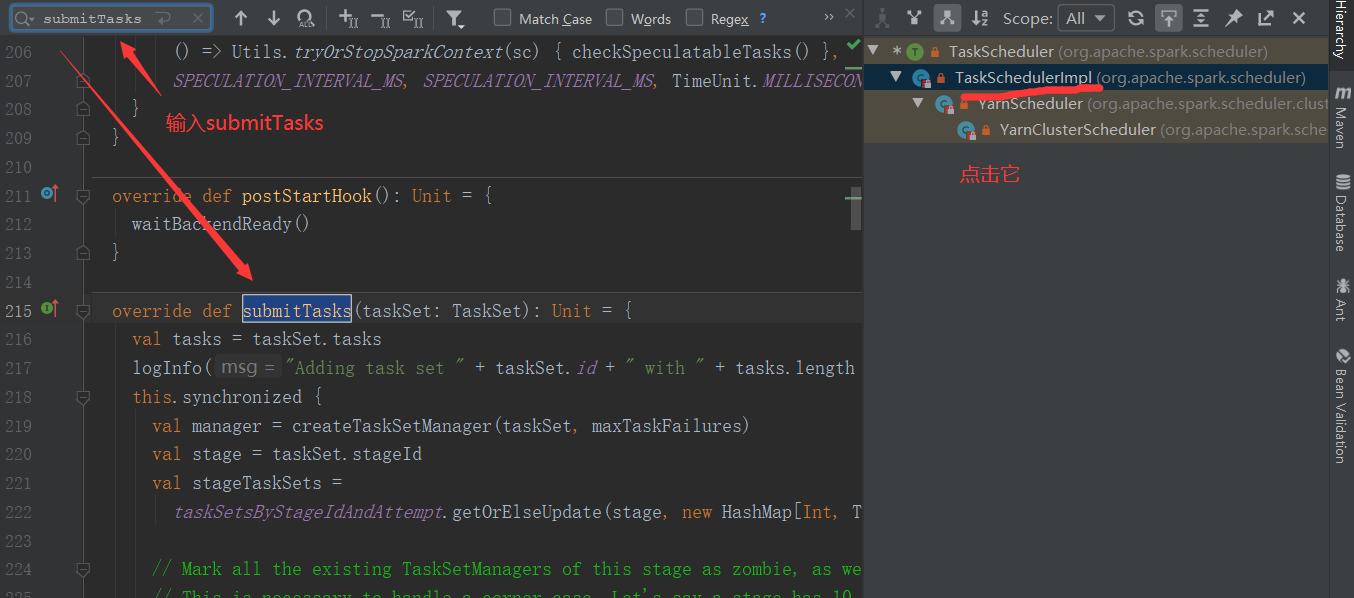
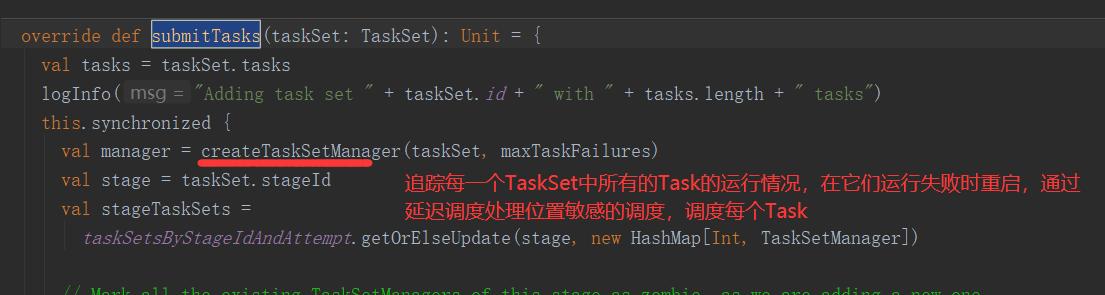
2.2 TaskManager
负责一个TaskSet中任务的调度(将任务发给Executor执行),追踪当前TaskSet中的Task运行的状态,在失败时重试,通过延迟调度处理位置敏感的调度(某些Task需要在同一个节点上运行)
private[spark] class TaskSetManager( sched: TaskSchedulerImpl, val taskSet: TaskSet, val maxTaskFailures: Int, blacklistTracker: Option[BlacklistTracker] = None, clock: Clock = new SystemClock()) extends Schedulable with Logging
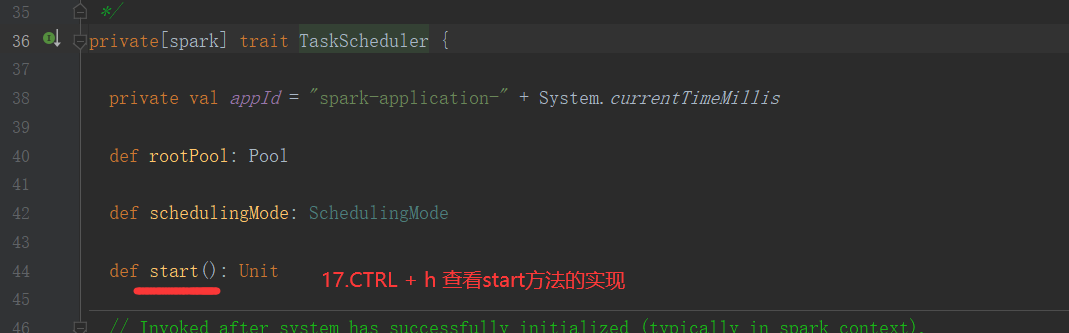
2.3 SchedulableBuilder
private[spark] trait SchedulableBuilder { def rootPool: Pool def buildPools(): Unit def addTaskSetManager(manager: Schedulable, properties: Properties): Unit }
2.3.1 FIFOSchedulableBuilder(实现一)
默认的调度器,按照Job中Stage提交的先后顺序,进行调度
在TaskSchedulerImpl对象中被赋值:
def initialize(backend: SchedulerBackend): Unit = { this.backend = backend schedulableBuilder = { schedulingMode match { // 由调度模式决定 取决于spark.scheduler.mode,默认为FIFO case SchedulingMode.FIFO => new FIFOSchedulableBuilder(rootPool) case SchedulingMode.FAIR => new FairSchedulableBuilder(rootPool, conf) case _ => throw new IllegalArgumentException(s"Unsupported $SCHEDULER_MODE_PROPERTY: " + s"$schedulingMode") } } schedulableBuilder.buildPools() }
2.3.2 FairSchedulableBuilder(实现二)
公平调度器,采取公平算法调度
private[spark] class FIFOSchedulingAlgorithm extends SchedulingAlgorithm { // TaskSetManager: Schedulable override def comparator(s1: Schedulable, s2: Schedulable): Boolean = { val priority1 = s1.priority val priority2 = s2.priority /* 根据 (priority1 - priority2) 的结果,进行返回 结果为负数,返回 -1 结果为0,返回0 结果为正数,返回 1 */ var res = math.signum(priority1 - priority2) if (res == 0) { // stageId 小的是靠前的阶段 val stageId1 = s1.stageId val stageId2 = s2.stageId res = math.signum(stageId1 - stageId2) } res < 0 } }
四、Shuffle
1.shuffle的简介
在Spark中,很多算子都会引起RDD中数据的重分区,新的分区被创建,旧的分区被合并或数据被重新分配,在重分区的过程中,如果数据发生了跨节点的移动,就称为shuffle,shuffle的作用就是为了在不同的task中交换数据
2.shuffle的实现方式
2.1 HashShuffle
Spark1.6.3 之前,使用HashShuffle,HashShuffle使用Hash算法将RDD中的数据,进行分区,使用未优化的HashShuffle,将每个分区的数据单独存放在一个文件中
生成的文件数量= MapTask数量 * 分区数(ReduceTask数量)
弊端:
①随着MapTask数量的提高,生成大量的小文件,传输效率低!
②缓冲区占用内存空间大
单个节点执行shuffle时缓冲区的消耗为: M * R * spark.shuffle.file.buffer(32K)
优化后HashShuffle: 每个Core计算的所有的task,会将数据先写入到buffer中,在buffer中完成相同分区数据的合并,最终每个分区单独存放在一个文件中
生成的文件数量= core数 * 分区数
2.2 SortShuffle(sort-based shuffle)
随着Hadoop2.0的发布,Spark借鉴了Hadoop2.0中的shuffle过程(sort-based shuffle),sort-based shuffle核心要义:一个MapTask最终只生成一个数据文件,这个文件中有若干个分区,以及一个index文件,其中记录了分区的边界
Hadoop2.0的shuffle:
在MapTask上,先分区------>溢写前,进行排序----->溢写为一个片段
所有片段全部溢写完成后------->merge------->合并为一个总的文件
SortShuffle的结果就是一个Executor上的每个MapTask,只产生一个文件,这个文件有若干分区!在产生文件时,默认SortShuffleWriter会进行排序
sort-based shuffle生成的文件数: 2 * MapTask的数量,并不是所有的sort-based shuffle都会对shuffle写出的数据进行排序
2.4 总结
在老的版本中,可以通过spark.shuffle.manager进行配置,新的版本中已经去掉了此配置项,统一为Sort-based Shuffle。
3.shuffle的写出方式
MapTask端需要将数据写出罗盘,在写出时可以采取不同的策略
3.1 ShuffleWriter
ShuffleWriter负责将MapTask的数据写出
private[spark] abstract class ShuffleWriter[K, V] { /** Write a sequence of records to this task's output */ @throws[IOException] def write(records: Iterator[Product2[K, V]]): Unit /** Close this writer, passing along whether the map completed */ def stop(success: Boolean): Option[MapStatus] }
3.2 BypassMergeSortShuffleWriter
BypassMergeSortShuffle是HashShuffle和Sort-BaseShuffle的折中方案,本质是使用Hash Shuffle的方式处理数据,在最后将所有的文件拼接合并为1个文件,并生成索引文件! 可以理解为HashShuffle 的 Shuffle Fetch优化版,在过程中还是会产生大量的中间文件,BypassMergeSortShuffleWriter在分区过多时,不适合,效率低,因为需要持续打开全部分区的文件流和序列化器
SortShuffleManager会在以下情况,使用BypassMergeSortShuffleWriter的:
①不能实现在map端聚合
②分区数必须 <= spark.shuffle.sort.bypassMergeThreshold(默认200)(自己配置)
忽略Merge后的排序,因为是将分区进行拼接
3.3 UnsafeShuffleWriter(几乎不使用)
Spark在1.5版本开始了Tungsten计划,在1.5.0-1.5.2版本推出了Tungsten-sort的选项,类似一种实验性质,本质上还是Sort-BaseShuffle,只是用 UnsafeShuffleWriter进行写出,采用了BytesToBytesMap的数据结构,将对数据的排序转换为对指针数组的排序,能够基于二进制数据直接操作,对GC有很大提升
限制:
①不支持map端聚合
②序列化器必须支持重定向
③分区数 < 16777216
可惜的是,1.6已经被取消
3.4 SortShuffleWriter(默认)
特征:
①支持map端聚合
②支持排序(Map端),按照Key进行排序
③支持sort-based shuffle,最终生成一个结果文件和一个索引文件
override def write(records: Iterator[Product2[K, V]]): Unit = { // SortShuffleWriter 支持map端聚合,可选! sorter = if (dep.mapSideCombine) { new ExternalSorter[K, V, C]( context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer) } else { // In this case we pass neither an aggregator nor an ordering to the sorter, because we don't // care whether the keys get sorted in each partition; that will be done on the reduce side // if the operation being run is sortByKey. new ExternalSorter[K, V, V]( context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer) } // 都创建了一个ExternalSorter sorter.insertAll(records) // Don't bother including the time to open the merged output file in the shuffle write time, // because it just opens a single file, so is typically too fast to measure accurately // (see SPARK-3570). val mapOutputWriter = shuffleExecutorComponents.createMapOutputWriter( dep.shuffleId, mapId, dep.partitioner.numPartitions) sorter.writePartitionedMapOutput(dep.shuffleId, mapId, mapOutputWriter) // 写出所有分区的数据 最终生成索引文件和数据文件 val partitionLengths = mapOutputWriter.commitAllPartitions() mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths, mapId) }
def insertAll(records: Iterator[Product2[K, V]]): Unit = { // TODO: stop combining if we find that the reduction factor isn't high val shouldCombine = aggregator.isDefined if (shouldCombine) { // Combine values in-memory first using our AppendOnlyMap val mergeValue = aggregator.get.mergeValue val createCombiner = aggregator.get.createCombiner var kv: Product2[K, V] = null val update = (hadValue: Boolean, oldValue: C) => { if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2) } while (records.hasNext) { addElementsRead() kv = records.next() // PartitionedAppendOnlyMap 将kv对聚合到map中 map.changeValue((getPartition(kv._1), kv._1), update) // 判断是否该溢写 maybeSpillCollection(usingMap = true) } } else { // Stick values into our buffer while (records.hasNext) { addElementsRead() val kv = records.next() // PartitionedPairBuffer 将kv对,放入buffer不聚合 buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C]) maybeSpillCollection(usingMap = false) } } }
3.5 ShuffleMapTask
一旦一个Task需要将当前stage的结果写出到shuffle,此时这个Task使用ShuffleMapTask实现
override def runTask(context: TaskContext): MapStatus = { // 获取Shuffle的Writer dep.shuffleWriterProcessor.write(rdd, dep, mapId, context, partition) }
def write( var writer: ShuffleWriter[Any, Any] = null try { val manager = SparkEnv.get.shuffleManager //获取writer writer = manager.getWriter[Any, Any]( //写出 writer.write( rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]]) writer.stop(success = true).get } } }
4.Hadoop的shuffle和sparkshuffle之间的区别
sort-based shuffle : 一个MapTask生成一个数据文件和一个索引文件
区别:
hadoop:
MapTask: map--------->sort--------->merge
ReduceTask: sort--------->reduce
spark :
MapTask: map--------->sort--------->merge
ReduceTask: merge----->算子
spark的shuffle在ReduceTask端不排序
四、内存管理
1.GC
①Java的垃圾回收线程是自动帮我们回收垃圾,收堆内存的垃圾
②只能使用System.gc() ,只能通过垃圾回收器来收垃圾
③当堆的内存不够的时候,一定会来收垃圾
2.内存的管理
在Spark中有两种内存管理:
①静态内存管理(3.0之前): 指通过参数指定每个部分使用的内存的比例,是固定的
②统一(动态)内存管理(3.0只剩): 每个部分,即storage,execution,other使用的内存比例和数值可以动态变化
3.垃圾回收器
jdk1.7 : 默认使用CMS
jdk1.8: 默认使用 Parallel Scavenge
jdk1.9 : 默认使用G1(presto)
Spark使用G1
//Spark使用G1,可以在SparkEnv中配置 -XX:+UseG1GC

