
第1章 Spark概述
1.1 什么是Spark
回顾:Hadoop主要解决,海量数据的存储和海量数据的分析计算。
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
1.2 Hadoop与Spark历史
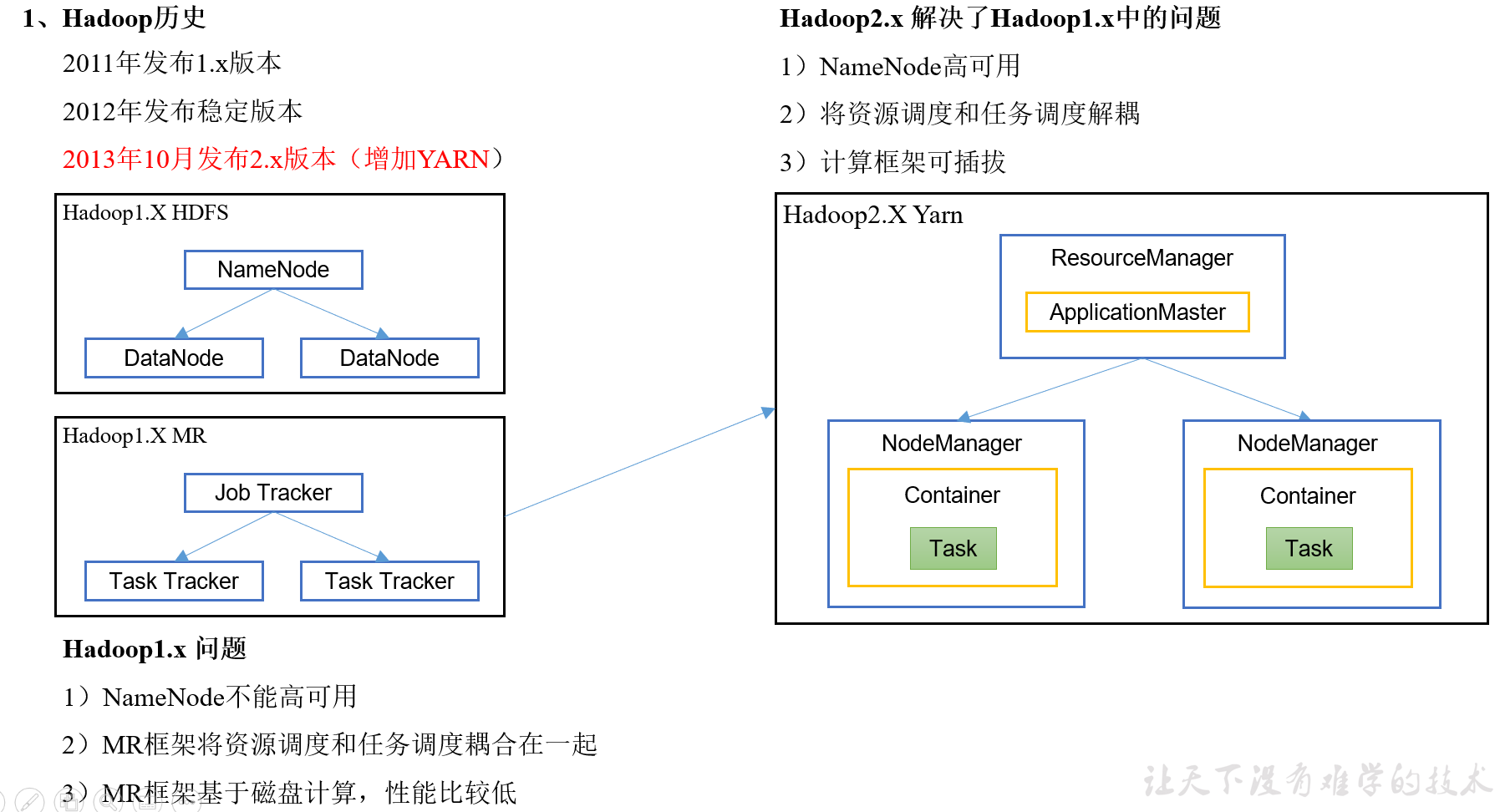
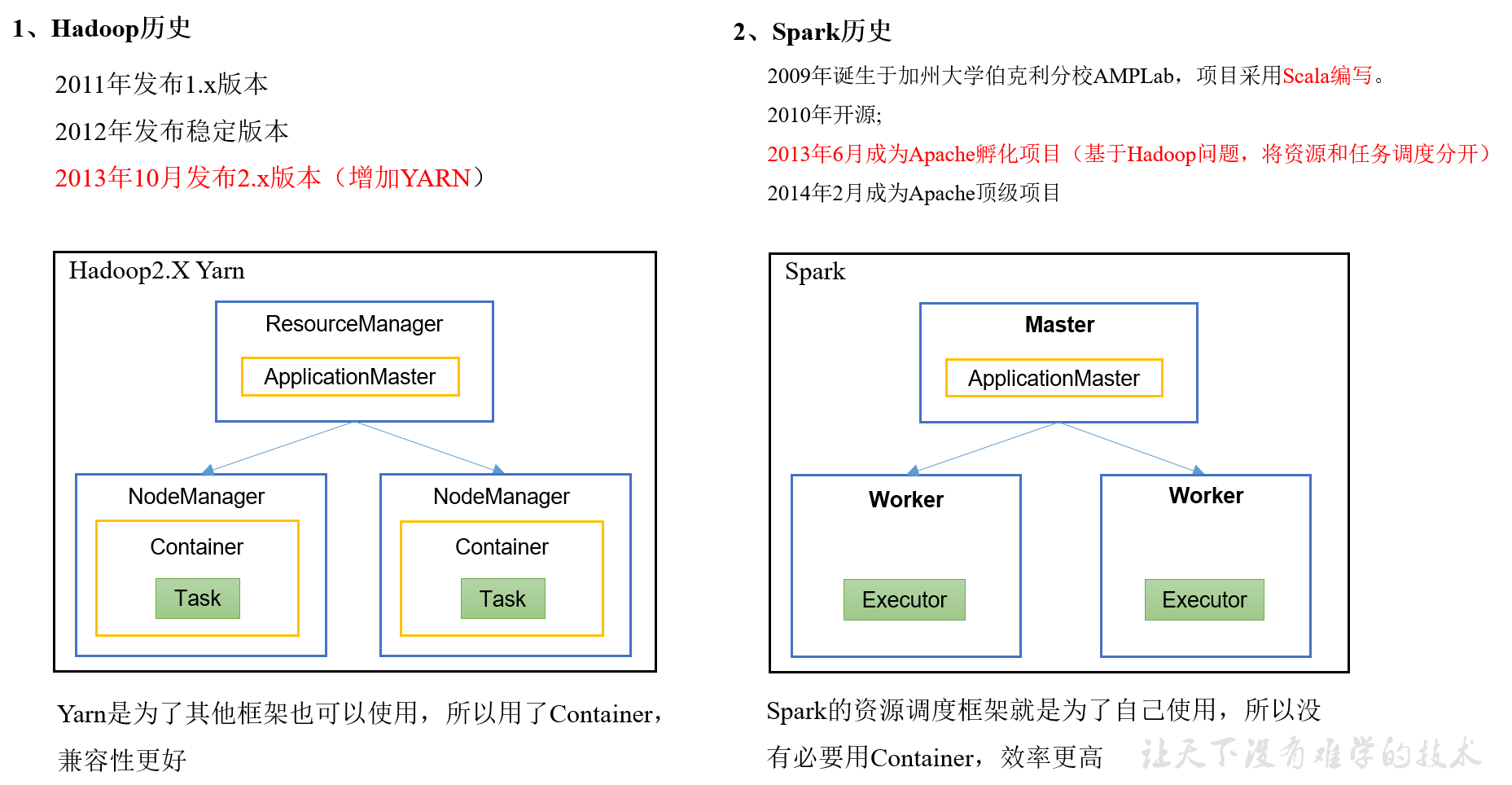
Hadoop的Yarn框架比Spark框架诞生的晚,所以Spark自己也设计了一套资源调度框架。
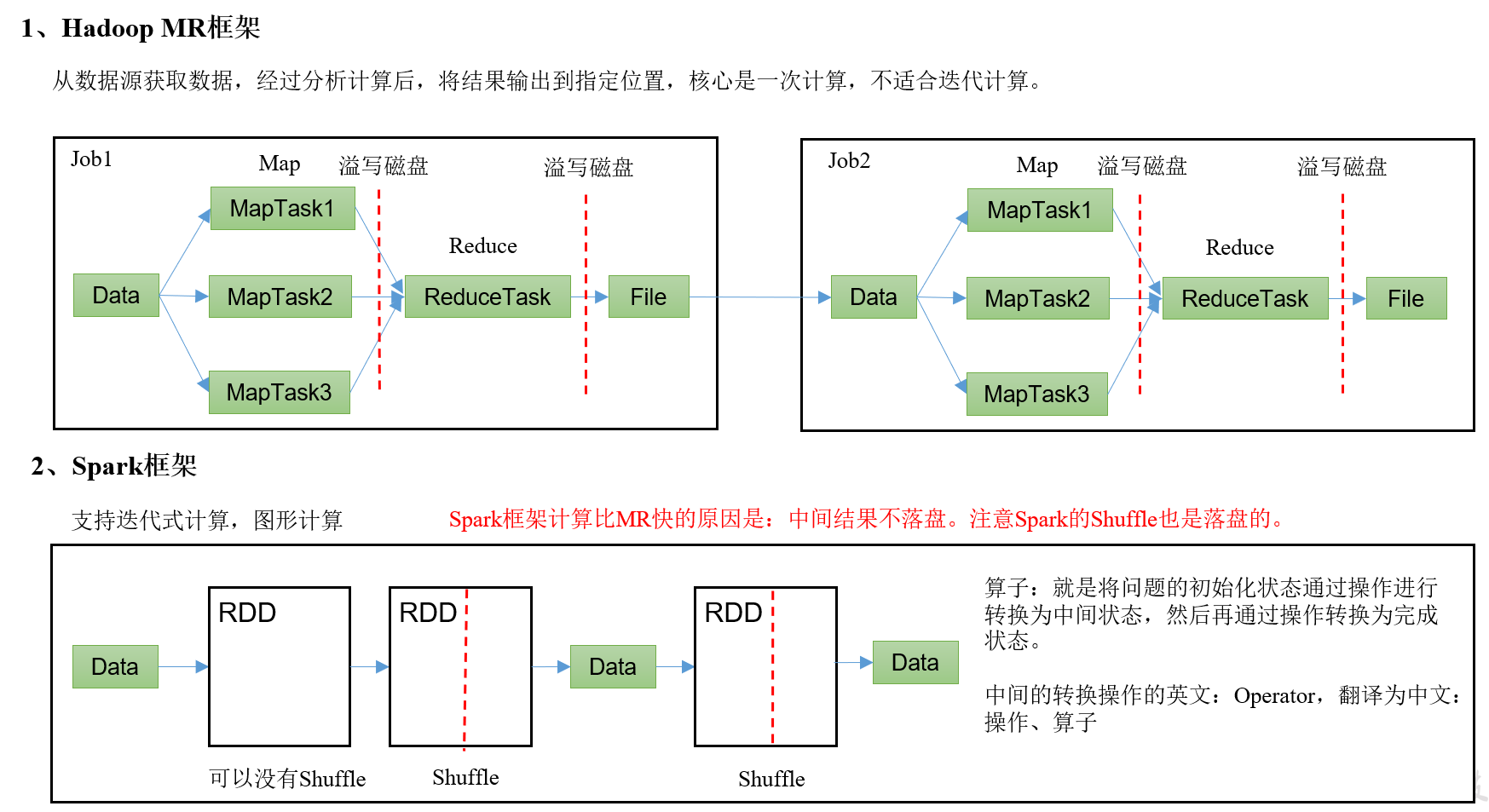
1.3MR与Spark框架对比
1.4 Spark内置模块
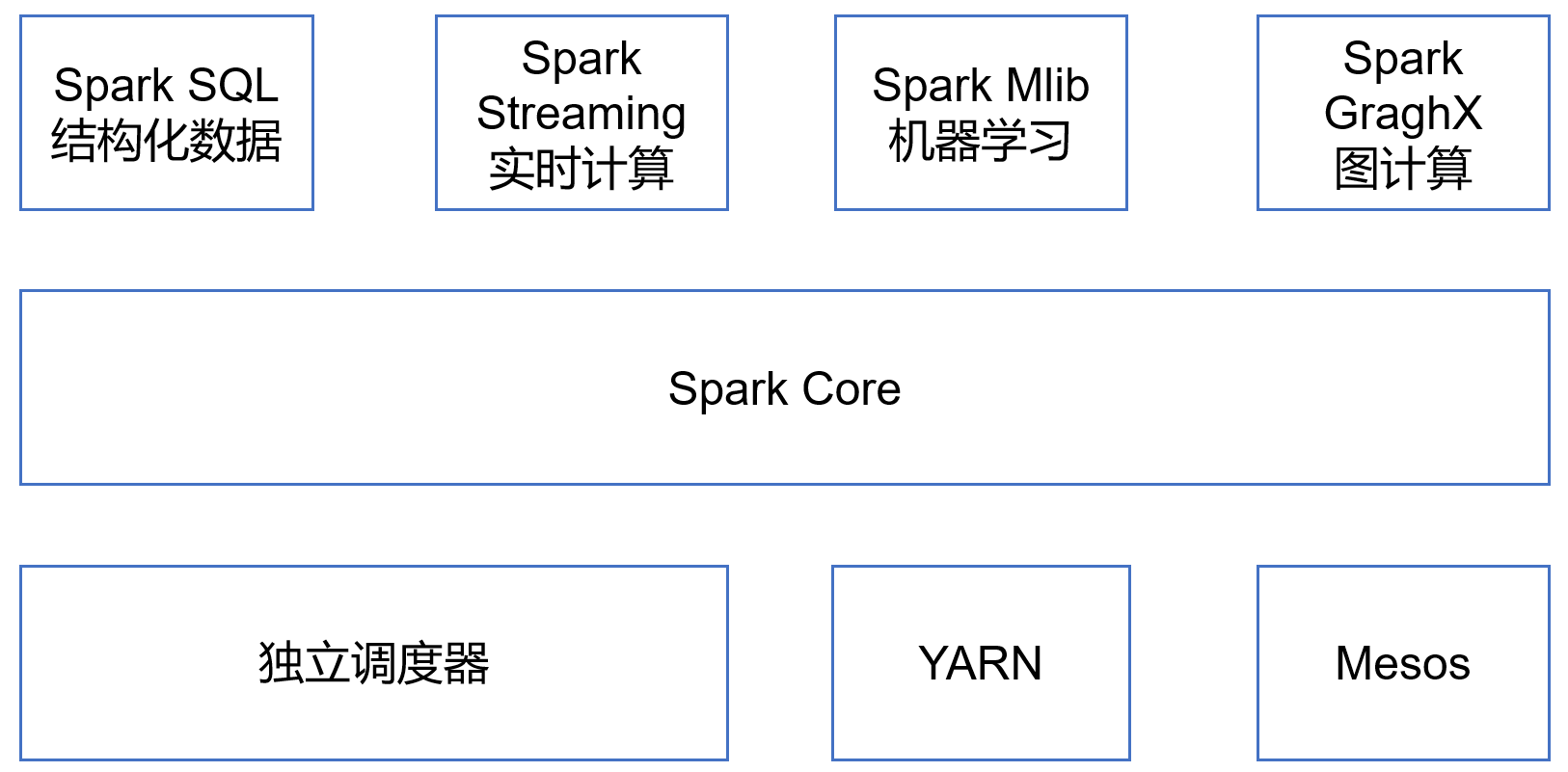
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。
集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。
Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
1.5 Spark特点
1)快:与Hadoop的MapReduce相比,Spack基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spack实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流,计算产生的中间结果存储在内存中
2)易用:Spack支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用,而且Spack支持交互式的Python和Scala的Shell,可以很方便的在Shell中使用Spack集群来验证解决问题的方法
3)通用:Spack提供了统一的解决方案,可以用于交互式查询(Spack SQL)、实时流处理(Spack Streaming)、机器学习(Spack MLib)和图计算(GraphX),这些不同类型的处理都可以在同一个应用中无缝使用,减少开发和维护产生的人力成本和部署平台的物理成本
4)兼容性:Spack可以非常方便地与其他开源产品进行融合,如:Spack可以使用Hadoop的Yarn和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS和HBase等等,这对于部署了Hadoop集群的用户特别重要,不需要做任何数据迁移就可以使用Spack
第2章 Spark运行模式
部署Spark集群大体上分为两种模式:单机模式与集群模式
大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。但是在生产环境中,并不会使用单机模式。因此,后续直接按照集群模式部署Spark集群。
下面详细列举了Spark目前支持的部署模式。
(1)Local模式:在本地部署单个Spark服务
(2)Standalone模式:Spark自带的任务调度模式。(国内常用)
(3)YARN模式:Spark使用Hadoop的YARN组件进行资源与任务调度。(国内常用)
(4)Mesos模式:Spark使用Mesos平台进行资源与任务的调度。
2.1 Spark安装地址
1)官网地址:http://spark.apache.org/
2)文档查看地址:https://spark.apache.org/docs/3.0.0/
3)下载地址:https://spark.apache.org/downloads.html
4)百度网盘下载地址:https://pan.baidu.com/s/1r47Fm_qf98cPJl8w55Aojg 提取码:m7me
2.2 Local模式
Local模式就是运行在一台计算机上的模式,通常就是用于在本机上练手和测试。
2.2.1 安装使用
1)上传spark-3.0.0-bin-hadoop3.2.tgz至/opt/software/并解压Spark安装包且重命名,文件下载地址:https://pan.baidu.com/s/10nsYJbv4AmRCutcVRqSn6Q 提取码:qv1z
tar -zxvf /opt/software/spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
mv /opt/module/spark-3.0.0-bin-hadoop3.2 /opt/module/spark-local
2)官方求PI案例
cd /opt/module/spark-local/
bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[3] /opt/module/spark-local/examples/jars/spark-examples_2.12-3.0.0.jar 16
--class:表示要执行程序的主类
--master local / local[K] 有三种情况:
(1)local: 没有指定线程数,则所有计算都运行在一个线程当中,没有任何并行计算
(2)local[K]:指定使用K个Core来运行计算,比如local[3]就是运行3个Core来执行
21/05/26 14:24:43 INFO Executor: Running task 0.0 in stage 0.0 (TID 0) 21/05/26 14:24:43 INFO Executor: Running task 2.0 in stage 0.0 (TID 2) 21/05/26 14:24:43 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
(3)local[*]:默认模式。自动帮你按照CPU最多核来设置线程数。比如CPU有16核,Spark帮你自动设置16个线程计算
21/05/26 14:24:43 INFO Executor: Running task 0.0 in stage 0.0 (TID 0) 21/05/26 14:24:43 INFO Executor: Running task 2.0 in stage 0.0 (TID 2) 21/05/26 14:24:43 INFO Executor: Running task 1.0 in stage 0.0 (TID 1) 21/05/26 14:24:44 INFO Executor: Running task 3.0 in stage 0.0 (TID 3) 21/05/26 14:24:44 INFO Executor: Running task 4.0 in stage 0.0 (TID 4) 21/05/26 14:24:44 INFO Executor: Running task 5.0 in stage 0.0 (TID 5) 21/05/26 14:24:44 INFO Executor: Running task 6.0 in stage 0.0 (TID 6) 21/05/26 14:24:44 INFO Executor: Running task 7.0 in stage 0.0 (TID 7) 21/05/26 14:24:44 INFO Executor: Running task 8.0 in stage 0.0 (TID 8) 21/05/26 14:24:44 INFO Executor: Running task 9.0 in stage 0.0 (TID 9) 21/05/26 14:24:44 INFO Executor: Running task 10.0 in stage 0.0 (TID 10) 21/05/26 14:24:44 INFO Executor: Running task 11.0 in stage 0.0 (TID 11) 21/05/26 14:24:44 INFO Executor: Running task 12.0 in stage 0.0 (TID 12) 21/05/26 14:24:44 INFO Executor: Running task 13.0 in stage 0.0 (TID 13) 21/05/26 14:24:44 INFO Executor: Running task 14.0 in stage 0.0 (TID 14) 21/05/26 14:24:44 INFO Executor: Running task 15.0 in stage 0.0 (TID 15)
/opt/module/spark-local/examples/jars/spark-examples_2.12-3.0.0.jar表示要运行的程序
16表示要运行程序的输入参数(计算圆周率π的次数,计算次数越多,准确率越高)
3)查看spark-submit所有参数:
bin/spark-submit
Usage: spark-submit [options] <app jar | python file | R file> [app arguments] Usage: spark-submit --kill [submission ID] --master [spark://...] Usage: spark-submit --status [submission ID] --master [spark://...] Usage: spark-submit run-example [options] example-class [example args] Options: --master MASTER_URL spark://host:port, mesos://host:port, yarn, k8s://https://host:port, or local (Default: local[*]). --deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or on one of the worker machines inside the cluster ("cluster") (Default: client). --class CLASS_NAME Your application's main class (for Java / Scala apps). --name NAME A name of your application. --jars JARS Comma-separated list of jars to include on the driver and executor classpaths. --packages Comma-separated list of maven coordinates of jars to include on the driver and executor classpaths. Will search the local maven repo, then maven central and any additional remote repositories given by --repositories. The format for the coordinates should be groupId:artifactId:version. --exclude-packages Comma-separated list of groupId:artifactId, to exclude while resolving the dependencies provided in --packages to avoid dependency conflicts. --repositories Comma-separated list of additional remote repositories to search for the maven coordinates given with --packages. --py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place on the PYTHONPATH for Python apps. --files FILES Comma-separated list of files to be placed in the working directory of each executor. File paths of these files in executors can be accessed via SparkFiles.get(fileName). --conf, -c PROP=VALUE Arbitrary Spark configuration property. --properties-file FILE Path to a file from which to load extra properties. If not specified, this will look for conf/spark-defaults.conf. --driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M). --driver-java-options Extra Java options to pass to the driver. --driver-library-path Extra library path entries to pass to the driver. --driver-class-path Extra class path entries to pass to the driver. Note that jars added with --jars are automatically included in the classpath. --executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G). --proxy-user NAME User to impersonate when submitting the application. This argument does not work with --principal / --keytab. --help, -h Show this help message and exit. --verbose, -v Print additional debug output. --version, Print the version of current Spark. Cluster deploy mode only: --driver-cores NUM Number of cores used by the driver, only in cluster mode (Default: 1). Spark standalone or Mesos with cluster deploy mode only: --supervise If given, restarts the driver on failure. Spark standalone, Mesos or K8s with cluster deploy mode only: --kill SUBMISSION_ID If given, kills the driver specified. --status SUBMISSION_ID If given, requests the status of the driver specified. Spark standalone, Mesos and Kubernetes only: --total-executor-cores NUM Total cores for all executors. Spark standalone, YARN and Kubernetes only: --executor-cores NUM Number of cores used by each executor. (Default: 1 in YARN and K8S modes, or all available cores on the worker in standalone mode). Spark on YARN and Kubernetes only: --num-executors NUM Number of executors to launch (Default: 2). If dynamic allocation is enabled, the initial number of executors will be at least NUM. --principal PRINCIPAL Principal to be used to login to KDC. --keytab KEYTAB The full path to the file that contains the keytab for the principal specified above. Spark on YARN only: --queue QUEUE_NAME The YARN queue to submit to (Default: "default"). --archives ARCHIVES Comma separated list of archives to be extracted into the working directory of each executor.
4)结果展示(该算法是利用蒙特·卡罗算法求PI)

2.2.2 官方WordCount案例
1)需求:读取多个输入文件,统计每个单词出现的总次数。
2)需求分析:
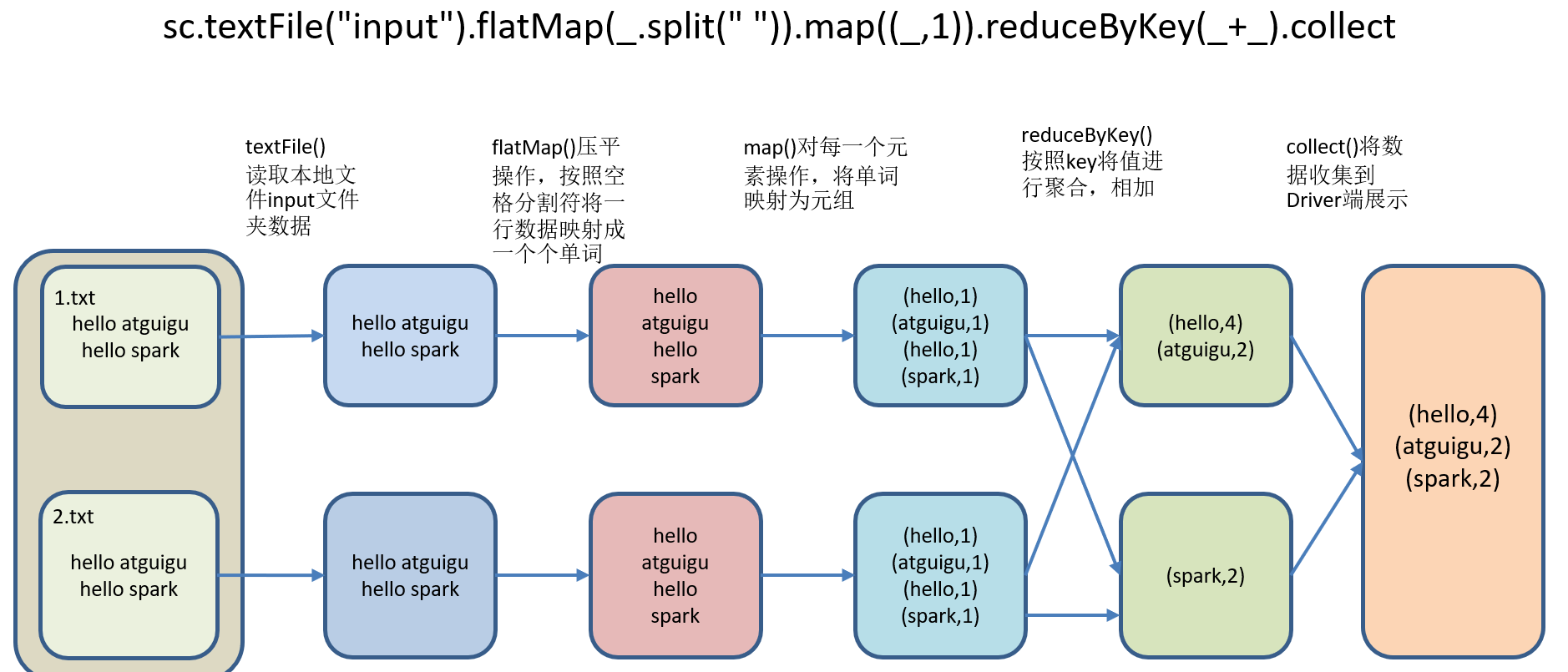
3)代码实现:
(1)准备文件
mkdir /opt/module/spark-local/input
在input下创建2个文件1.txt和2.txt,并输入以下内容:
hello atguigu
hello spark
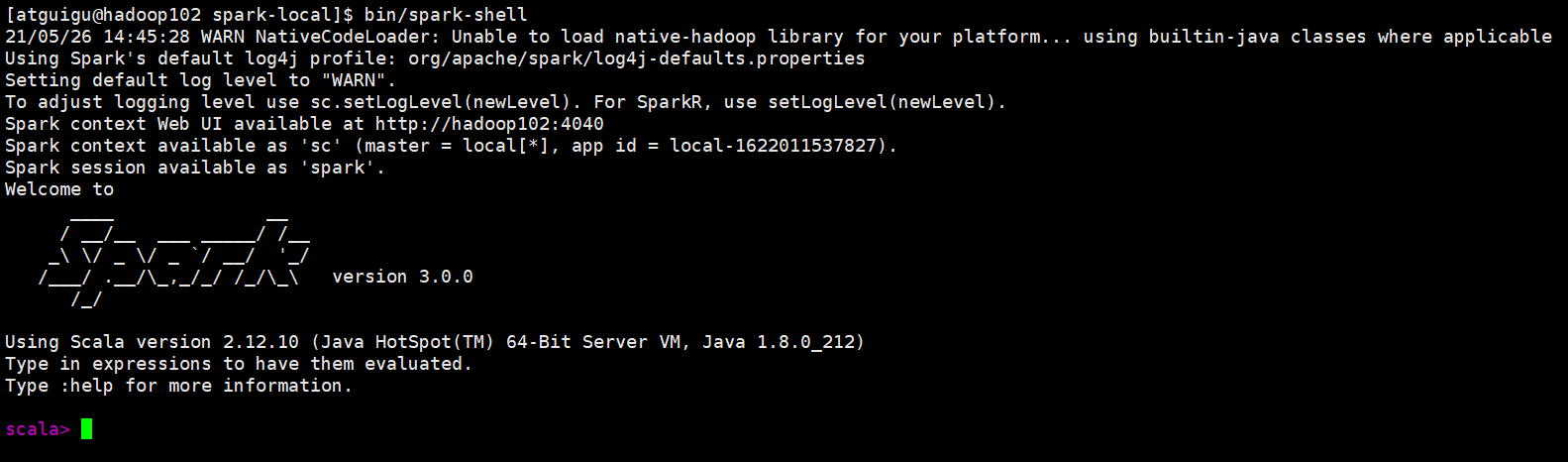
(2)启动spark-shell(sc是SparkCore程序的入口;spark是SparkSQL程序入口;master = local[*]表示本地模式运行。)
bin/spark-shell
(3)再开启一个hadoop102远程连接窗口,发现了一个SparkSubmit进程
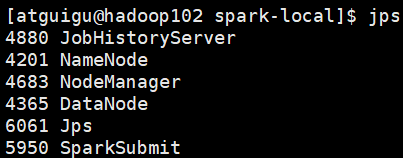
运行任务方式说明:spark-submit,是将jar上传到集群,执行Spark任务;spark-shell,相当于命令行工具,本身也是一个Application。
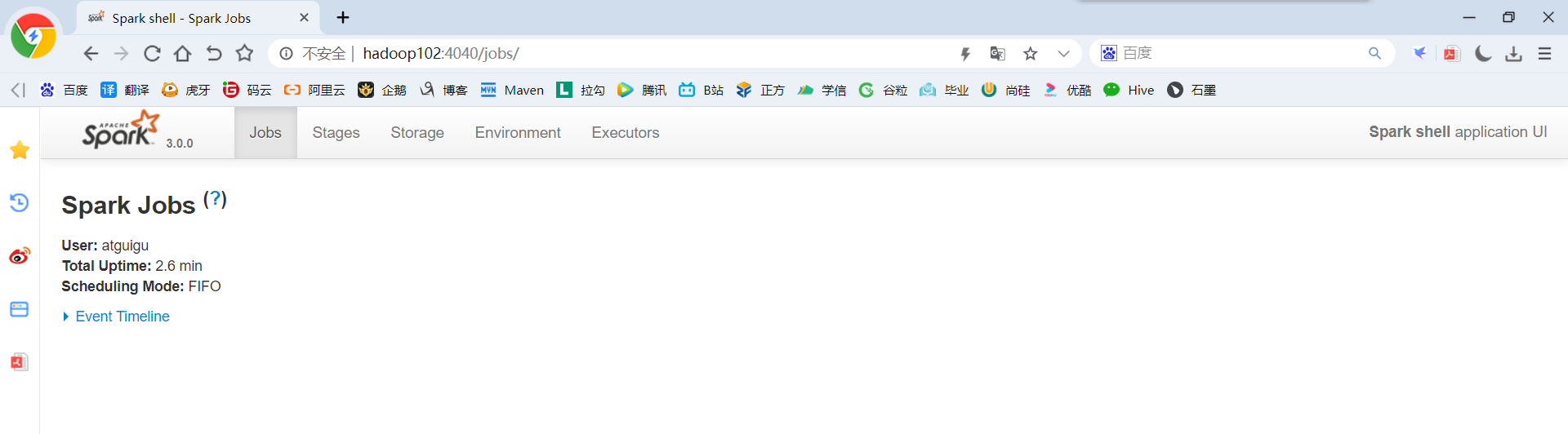
(4)登录hadoop102:4040,查看程序运行情况(注意:spark-shell窗口关闭掉,则hadoop102:4040页面关闭),本地模式下,默认的调度器为FIFO。
(5)运行WordCount程序(只有collect开始执行时,才会加载数据)
sc.textFile("/opt/module/spark-local/input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

(6)查看程序运行结果
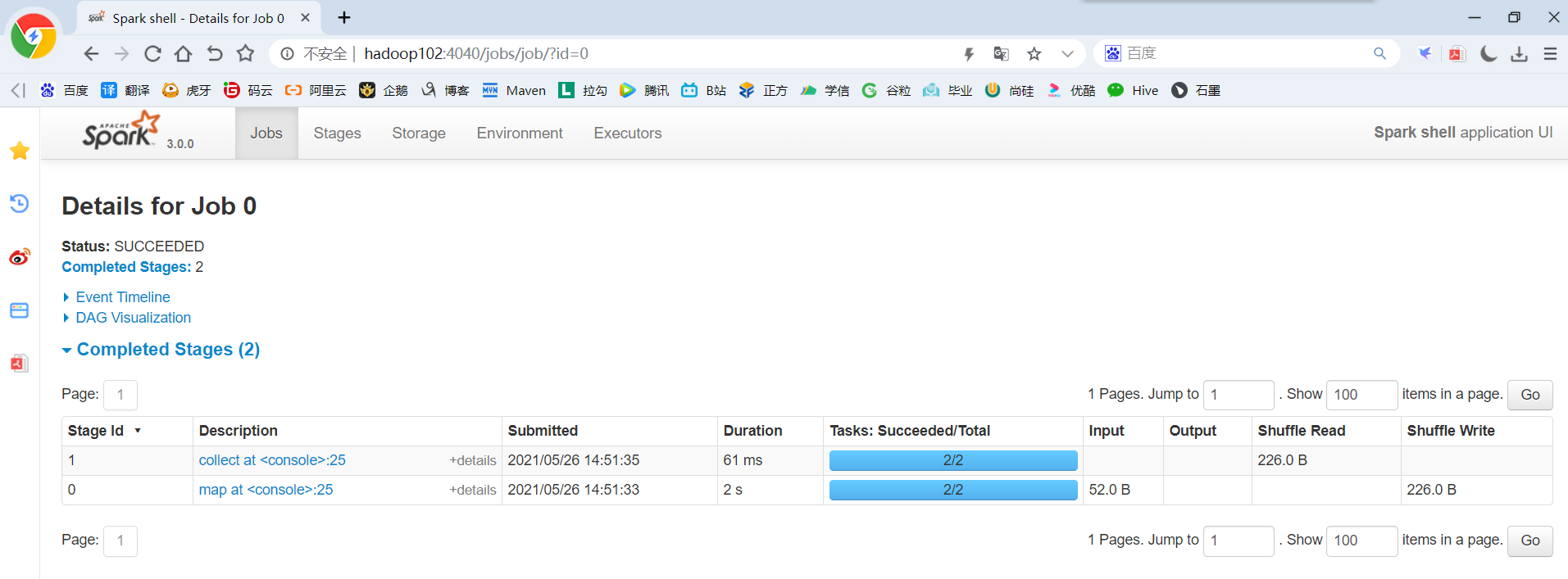
2.3 集群角色
2.3.1 Master和Worker集群资源管理
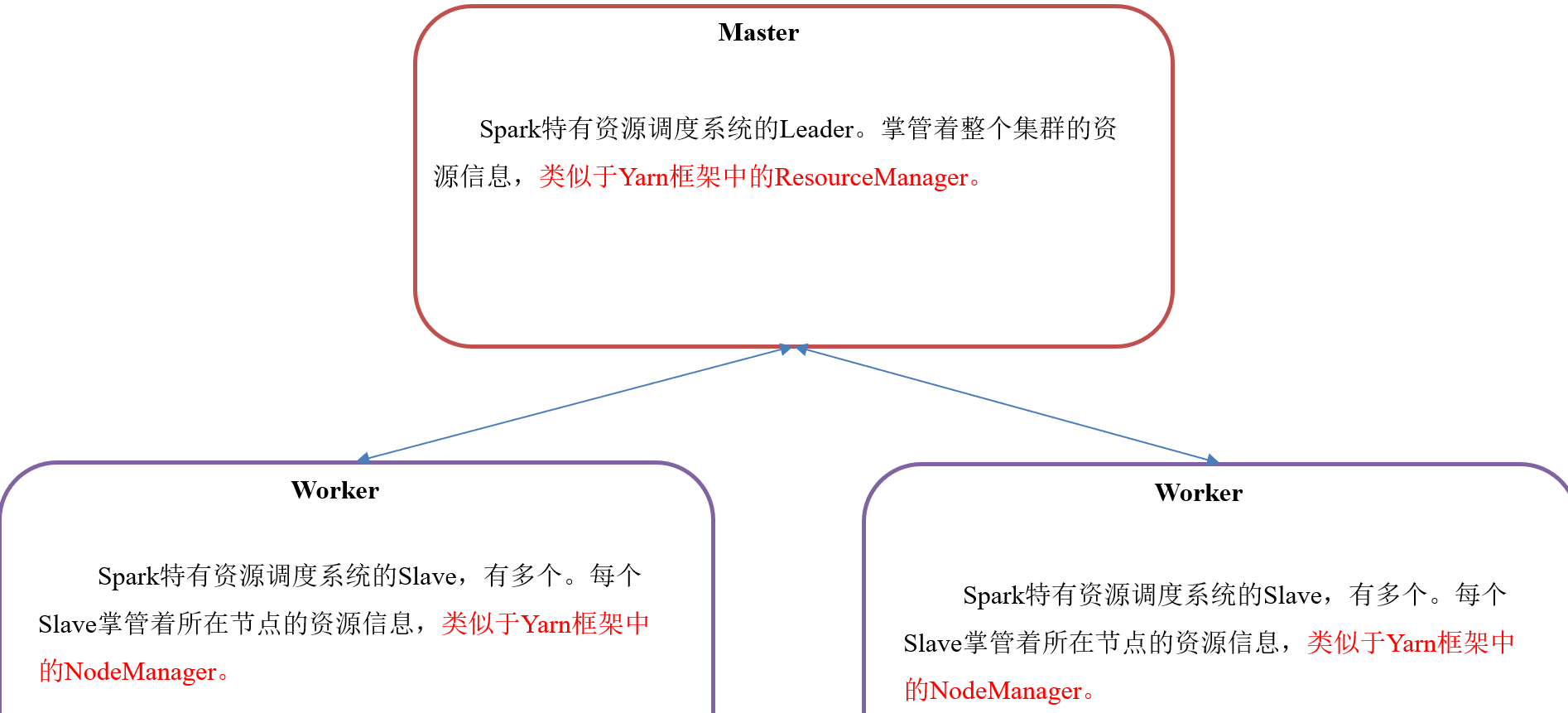
Master和Worker是Spark的守护进程、集群资源管理者,即Spark在特定模式下正常运行所必须的进程。
2.3.2 Driver和Executor任务的管理者
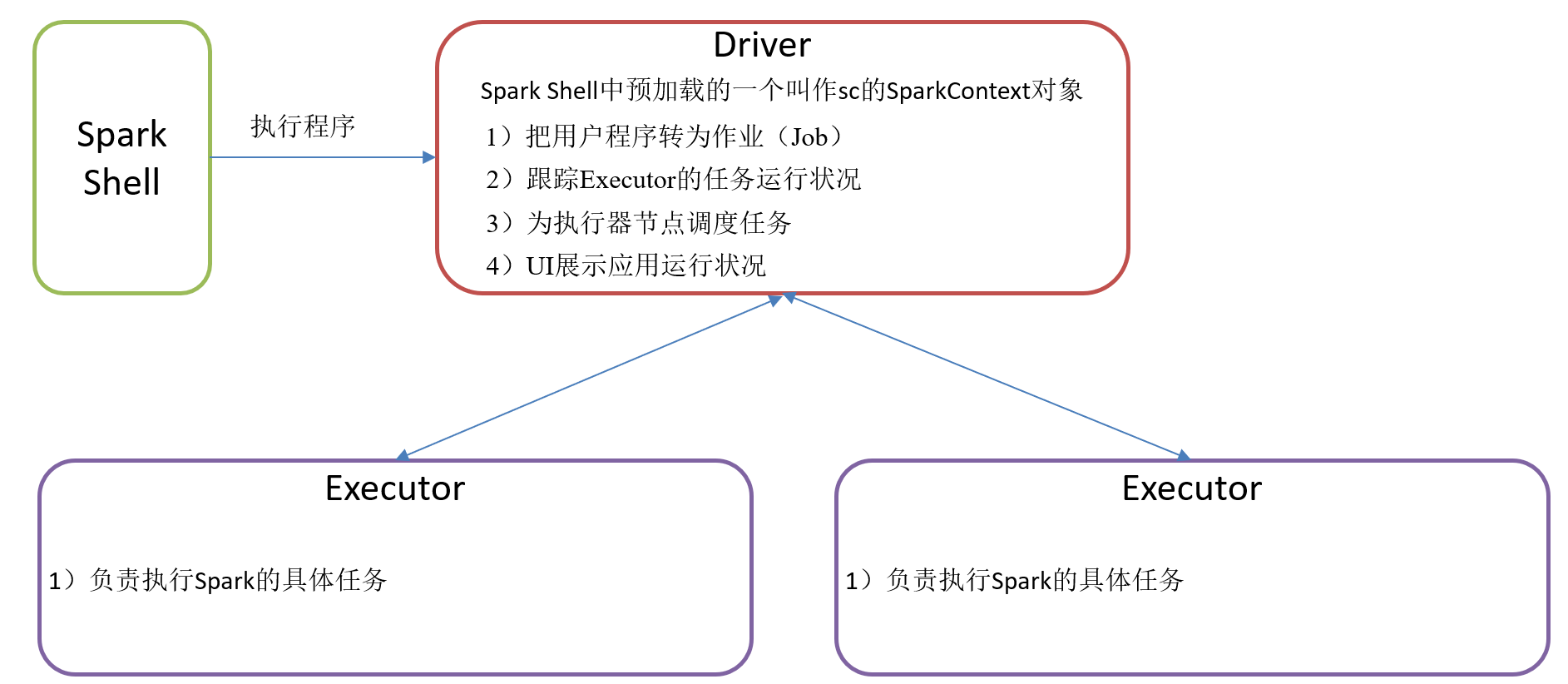
Driver和Executor是临时程序,当有具体任务提交到Spark集群才会开启的程序。
2.4 Standalone模式
Standalone模式是Spark自带的资源调动引擎,构建一个由Master + Slave构成的Spark集群,Spark运行在集群中。这个要和Hadoop中的Standalone区别开来,这里的Standalone是指只用Spark来搭建一个集群,不需要借助Hadoop的Yarn和Mesos等其他框架。
2.4.1 安装使用
1)集群规划
|
|
hadoop102 |
hadoop103 |
hadoop104 |
|
Spark |
Master Worker |
Worker |
Worker |
2)再解压一份Spark安装包,并修改解压后的文件夹名称为spark-standalone
tar -zxvf /opt/software/spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
mv /opt/module/spark-3.0.0-bin-hadoop3.2 /opt/module/spark-standalone
3)进入Spark的配置目录/opt/module/spark-standalone/conf
cd /opt/module/spark-standalone/conf/
4)修改slave文件,添加work节点:
mv slaves.template slaves
vim slaves
#将localhost删除后添加如下内容
hadoop102
hadoop103
hadoop104
5)修改spark-env.sh文件,添加master节点
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
SPARK_MASTER_HOST=hadoop102 SPARK_MASTER_PORT=7077
6)分发spark-standalone包
xsync /opt/module/spark-standalone/
7)启动spark集群,并查看三台服务器运行进程(xcall.sh是一个查看进程脚本)
sbin/start-all.sh
xcall.sh jps
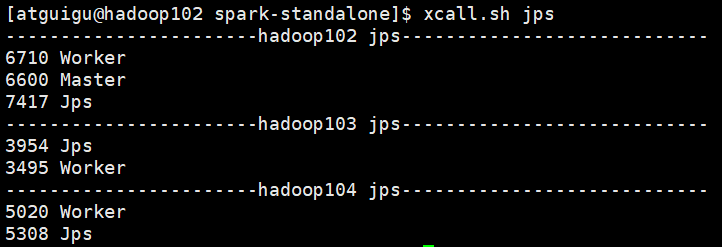
注意:如果遇到 “JAVA_HOME not set” 异常,可以在sbin目录下的spark-config.sh 文件中加入如下配置:
export JAVA_HOME=XXXX
8)网页查看:hadoop102:8080(master web的端口,相当于hadoop的8088端口),目前还看不到任何任务的执行信息:

9)官方求PI案例
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop102:7077 /opt/module/spark-standalone/examples/jars/spark-examples_2.12-3.0.0.jar 15
参数说明:--master spark://hadoop102:7077指定要连接的集群的master
10)页面查看http://hadoop102:8080/,发现执行本次任务,默认采用三台服务器节点的总核数36核,每个节点内存1024M。
8080:master的webUI
4040:application的webUI的端口号
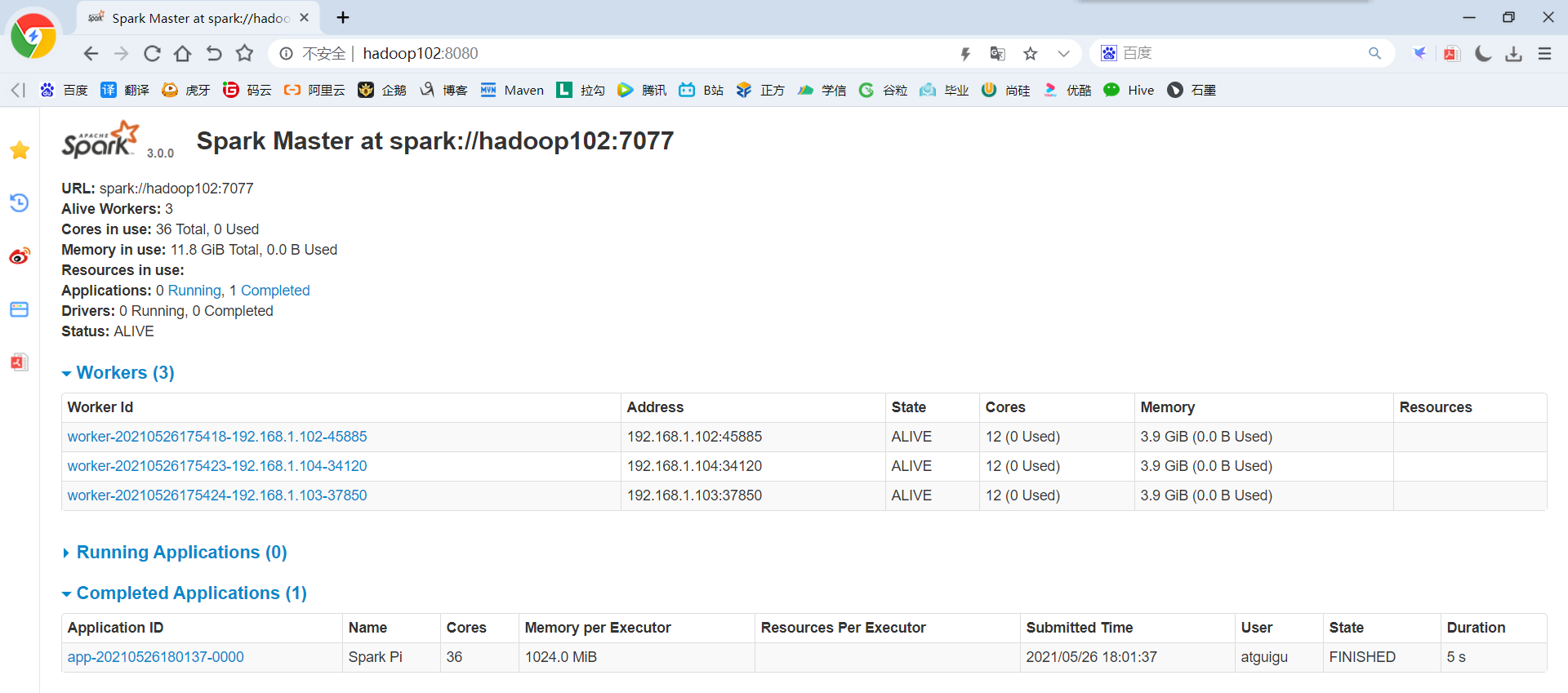
2.4.2 参数说明
1)配置Executor可用内存为2G,使用CPU核数为2个
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop102:7077 --executor-memory 2G --total-executor-cores 2 /opt/module/spark-standalone/examples/jars/spark-examples_2.12-3.0.0.jar 15
2)页面查看http://hadoop102:8080/
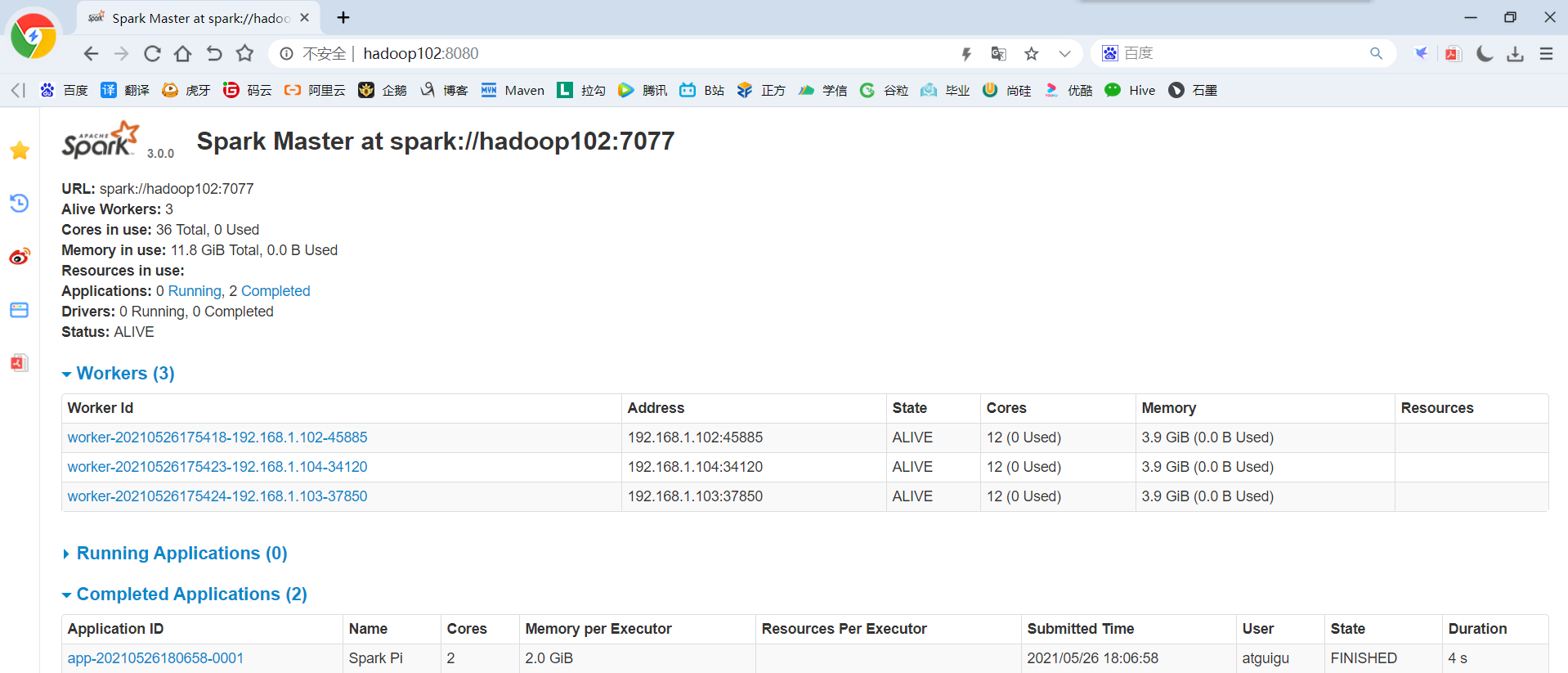
3)基本语法
bin/spark-submit \ --class <main-class> \ --master <master-url> \ ... # other options <application-jar> \ [application-arguments]
4)参数说明
|
参数 |
解释 |
可选值举例 |
|
--class |
Spark程序中包含主函数的类 |
|
|
--master |
Spark程序运行的模式 |
本地模式:local[*]、spark://hadoop102:7077、 Yarn |
|
--executor-memory 1G |
指定每个executor可用内存为1G |
符合集群内存配置即可,具体情况具体分析。 |
|
--total-executor-cores 2 |
指定所有executor使用的cpu核数为2个 |
|
|
application-jar |
打包好的应用jar,包含依赖。这个URL在集群中全局可见。 比如hdfs:// 共享存储系统,如果是file:// path,那么所有的节点的path都包含同样的jar |
|
|
application-arguments |
传给main()方法的参数 |
2.4.3 配置历史服务
由于spark-shell停止掉后,hadoop102:4040页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况。
1)修改spark-default.conf.template名称
cd /opt/module/spark-standalone/conf
mv spark-defaults.conf.template spark-defaults.conf
2)修改spark-default.conf文件,配置日志存储路径(写)
vim spark-defaults.conf
spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop102:8020/sparklogs
注意:需要启动Hadoop集群,HDFS上的目录需要提前存在(在HDFS的根目录下创建sparklogs目录)

3)修改spark-env.sh文件,添加如下配置:
vim spark-env.sh
#参数1含义:WEBUI访问的端口号为18080 #参数2含义:指定历史服务器日志存储路径(读) #参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。 export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/sparklogs -Dspark.history.retainedApplications=30"
4)分发
xsync /opt/module/spark-standalone/conf/
5)启动历史服务
sbin/start-history-server.sh
6)再次执行任务
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop102:7077 --executor-memory 2G --total-executor-cores 2 /opt/module/spark-standalone/examples/jars/spark-examples_2.12-3.0.0.jar 15
7)查看Spark历史服务地址:hadoop102:18080
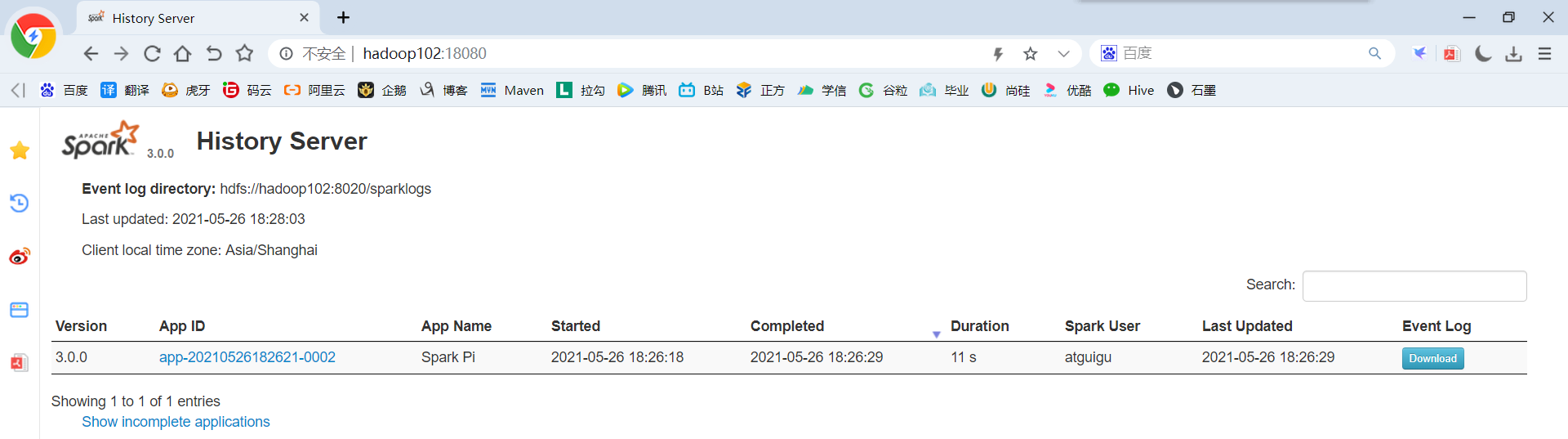
2.4.4 配置高可用(HA)
1)高可用原理
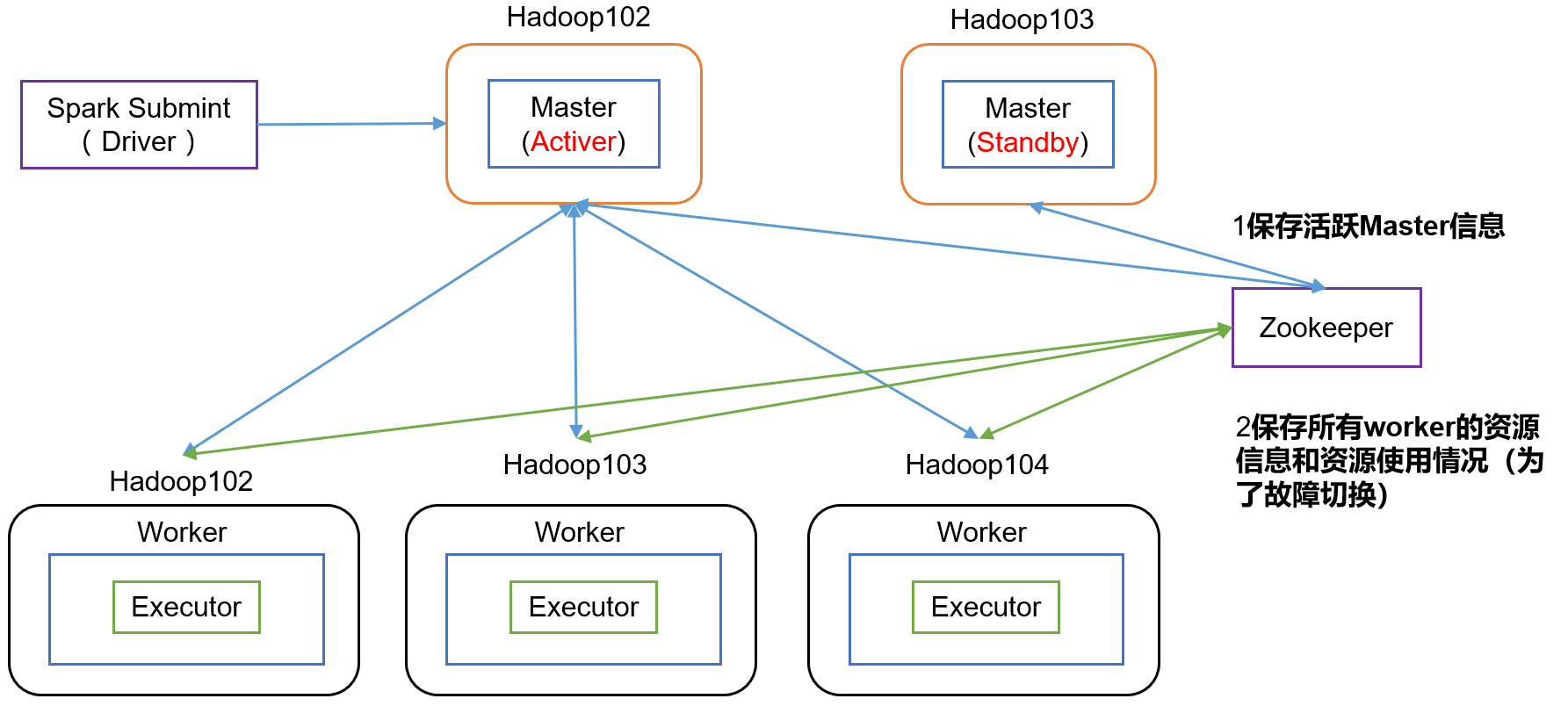
2)配置高可用
(1)停止集群及历史服务器
sbin/stop-all.sh
sbin/stop-history-server.sh
(2)Zookeeper正常安装并启动(zookeeper.sh是一个zookeeper的启动脚本)
zookeeper.sh start
(3)修改spark-env.sh文件添加如下配置:
cd /opt/module/spark-standalone/conf/ vim spark-env.sh
#注释掉如下内容: #SPARK_MASTER_HOST=hadoop102 #SPARK_MASTER_PORT=7077
#配置Spark-HA #添加上如下内容。配置由Zookeeper管理Master,在Zookeeper节点中自动创建/spark目录,用于管理: export SPARK_DAEMON_JAVA_OPTS=" -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop102,hadoop103,hadoop104 -Dspark.deploy.zookeeper.dir=/spark" #添加如下代码 #Zookeeper3.5的AdminServer默认端口是8080,和Spark的WebUI冲突,将Spark的WebUI的端口号改为8989 export SPARK_MASTER_WEBUI_PORT=8989
(4)分发配置文件
xsync /opt/module/spark-standalone/conf/spark-env.sh
(5)在hadoop102上启动全部节点及历史服务器
sbin/start-all.sh
sbin/start-history-server.sh
(6)在hadoop103上单独启动master节点
/opt/module/spark-standalone/sbin/start-master.sh
(7)在启动一个hadoop102窗口,将/opt/module/spark-local/input数据上传到hadoop集群的/spark目录
hadoop fs -mkdir -p /spark
hadoop fs -put /opt/module/spark-local/input/ /spark
(8)Spark HA集群访问
bin/spark-shell --master spark://hadoop102:7077,hadoop103:7077 --executor-memory 2G --total-executor-cores 2
参数说明:--master spark://hadoop102:7077指定要连接的集群的master
(9)执行WordCount程序
sc.textFile("hdfs://hadoop102:8020/spark/input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

3)高可用测试
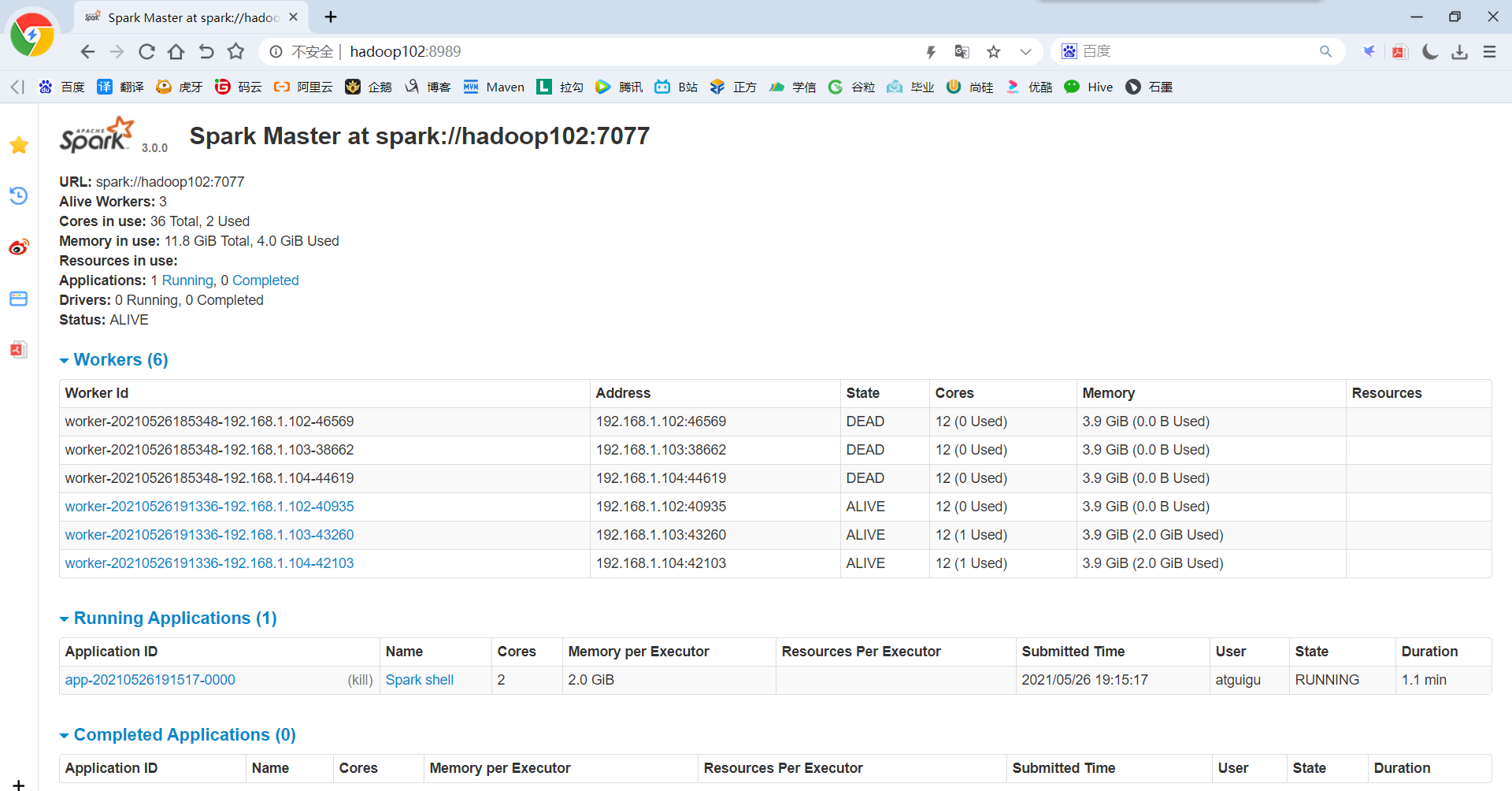
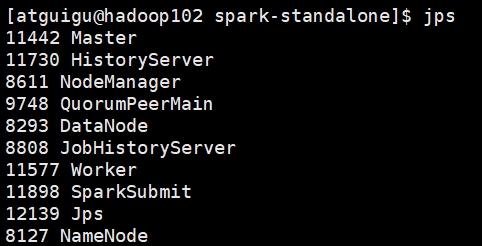
(1)查看hadoop102的master进程
jps
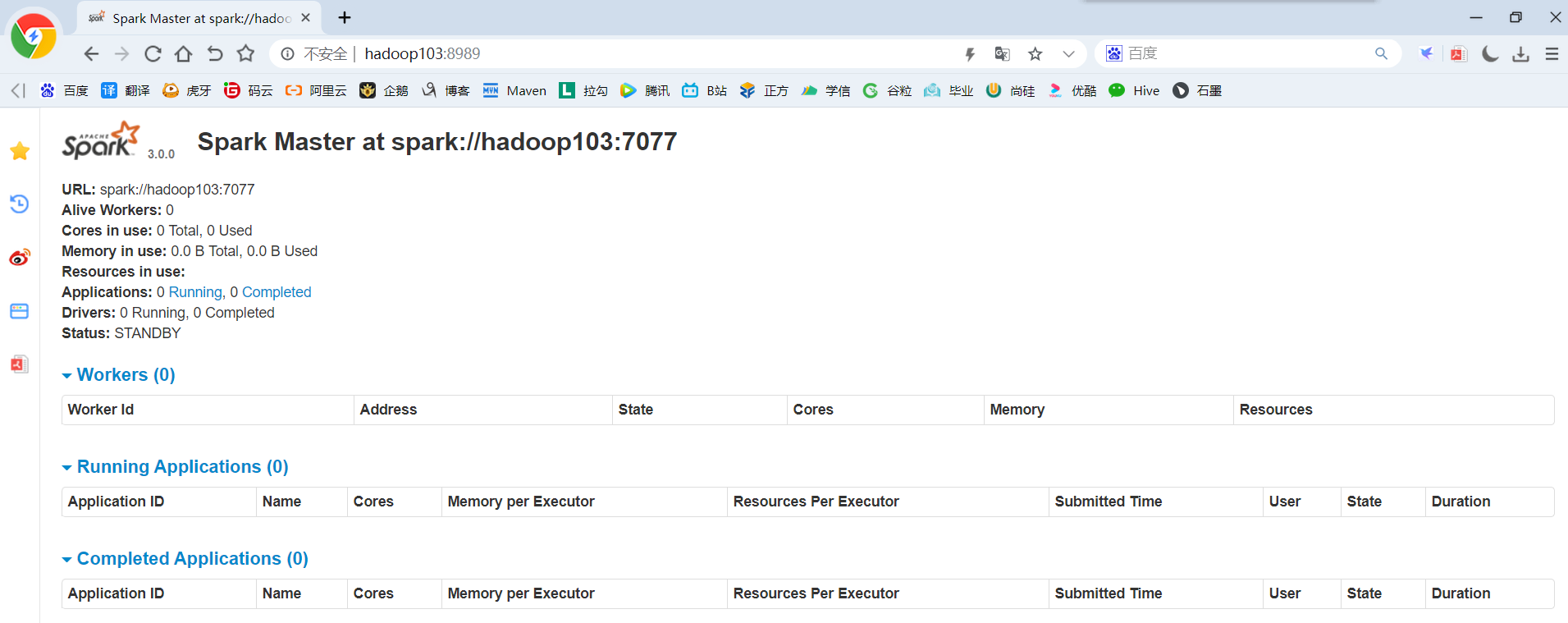
(2)Kill掉hadoop102的master进程,页面中观察http://hadoop103:8080/的状态是否切换为alive
kill -9 11442
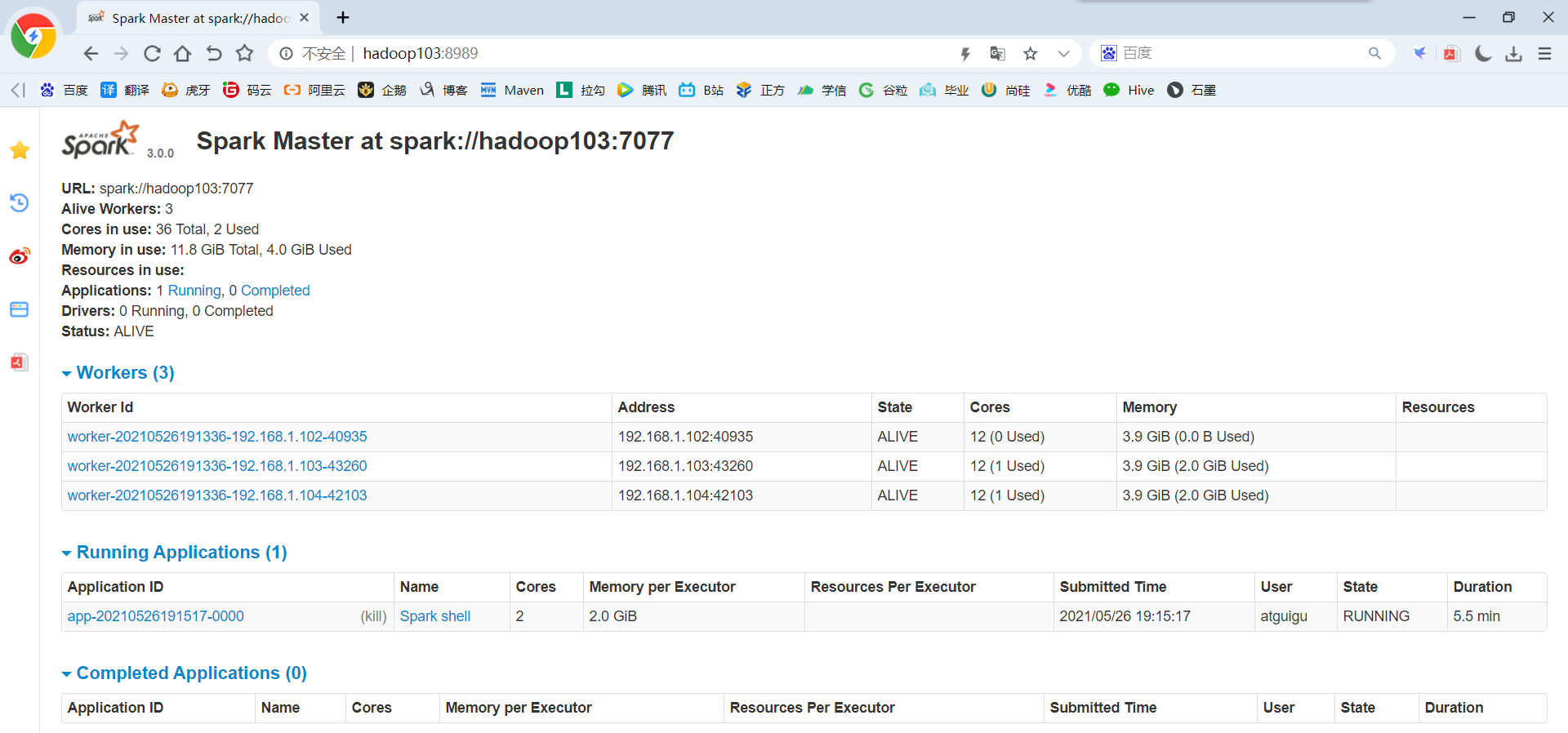
(3)再启动hadoop102的master进程
sbin/start-master.sh
2.4.5 运行流程
Spark有standalone-client和standalone-cluster两种模式,主要区别在于:Driver程序的运行节点。
1)客户端模式
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop102:7077,hadoop103:7077 --executor-memory 2G --total-executor-cores 2 --deploy-mode client /opt/module/spark-standalone/examples/jars/spark-examples_2.12-3.0.0.jar 15
参数说明:--deploy-mode client,表示Driver程序运行在本地客户端
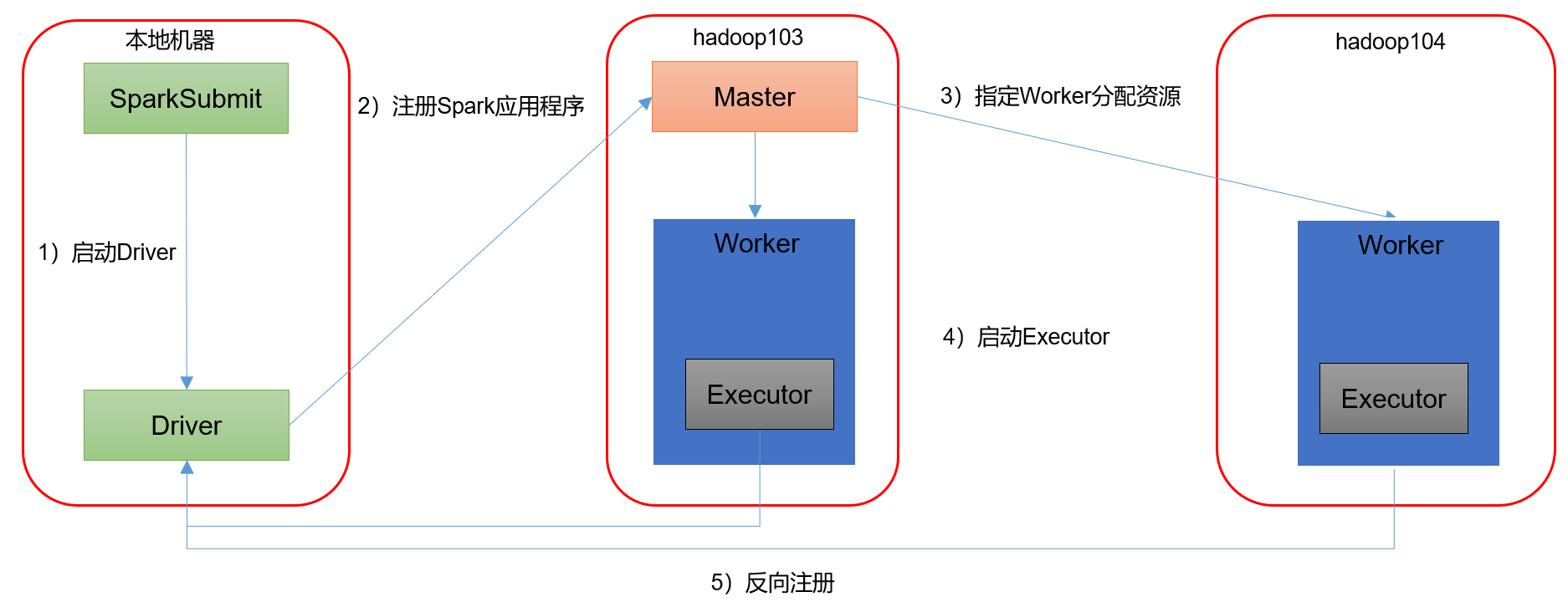
2)集群模式模式
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop102:7077,hadoop103:7077 --executor-memory 2G --total-executor-cores 2 --deploy-mode cluster /opt/module/spark-standalone/examples/jars/spark-examples_2.12-3.0.0.jar 15
参数说明:--deploy-mode cluster,表示Driver程序运行在集群
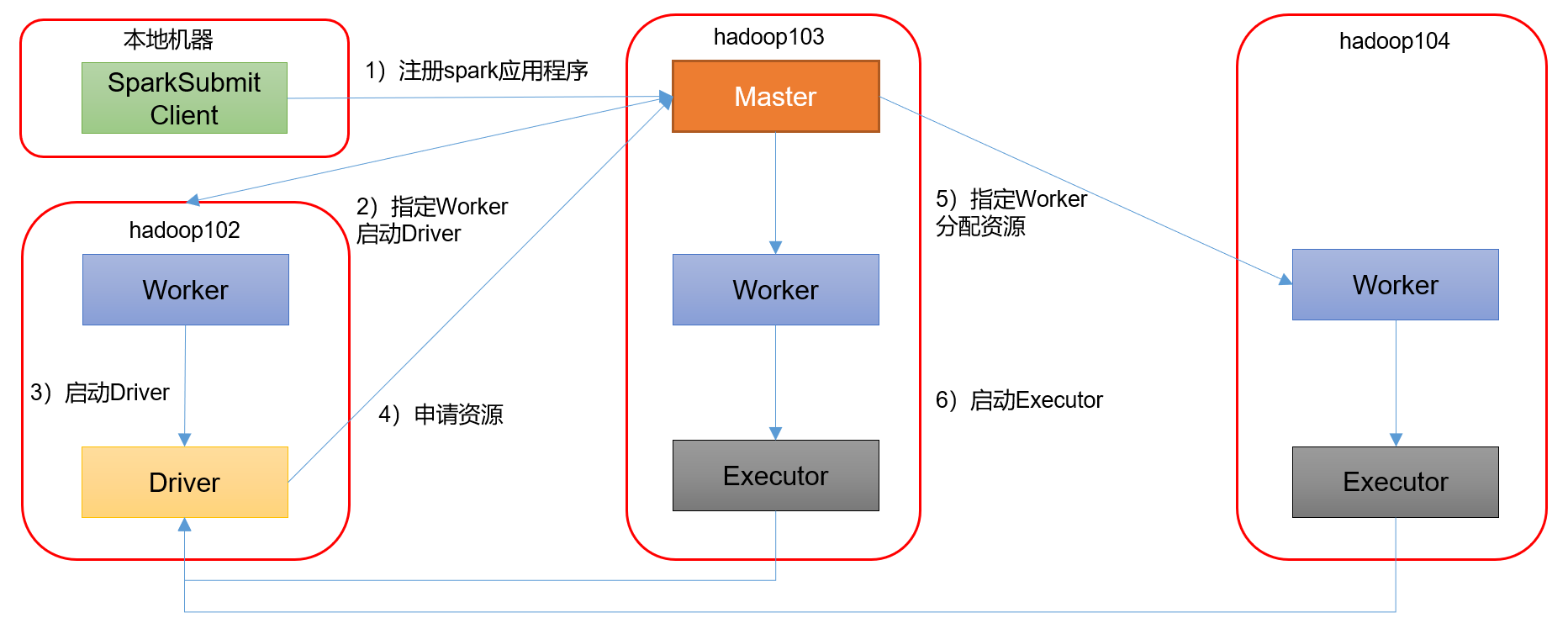
(1)查看http://hadoop103:8989/页面,点击Completed Drivers里面的Worker

(2)跳转到Spark Worker页面,点击Finished Drivers中Logs下面的stdout

(3)最终打印结果如下
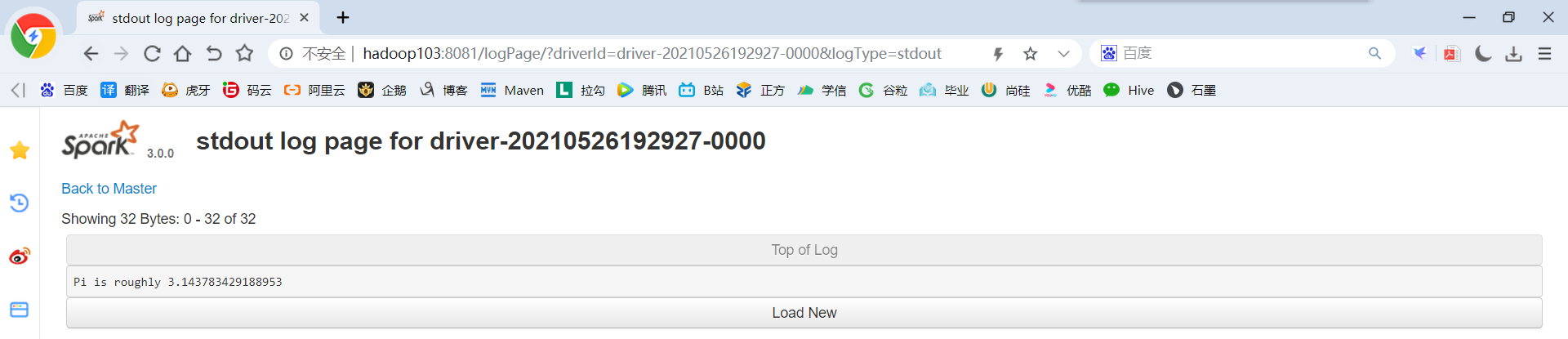
注意:在测试Standalone模式,cluster运行流程的时候,阿里云用户访问不到Worker,因为Worker是从Master内部跳转的,这是正常的,实际工作中我们不可能通过客户端访问的,这些端口对外都会禁用,需要的时候会通过授权到Master访问Worker
2.5 Yarn模式(重点)
Spark客户端直接连接Yarn,不需要额外构建Spark集群。
2.5.1 安装使用
1)停止Standalone模式下的spark集群(包括haoop103上的master)
#hadoop102上执行
sbin/stop-all.sh
#hadoop103上停止master /opt/module/spark-standalone/sbin/stop-master.sh
#停止zookeeper zookeeper.sh stop
#hadoop102上停止Standalone历史服务器 sbin/stop-history-server.sh
2)为了防止和Standalone模式冲突,再单独解压一份spark
tar -zxvf /opt/software/spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
3)进入到/opt/module目录,修改spark-3.0.0-bin-hadoop3.2名称为spark-yarn
cd /opt/module/
mv spark-3.0.0-bin-hadoop3.2 spark-yarn
4)修改hadoop配置文件/opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml,添加如下内容(因为测试环境虚拟机内存较少,防止执行过程进行被意外杀死,若之前配置过了就无需重复配置)
vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
5)分发配置文件
xsync /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
6)修改/opt/module/spark-yarn/conf/spark-env.sh,添加YARN_CONF_DIR配置,保证后续运行任务的路径都变成集群路径
mv /opt/module/spark-yarn/conf/spark-env.sh.template /opt/module/spark-yarn/conf/spark-env.sh
vim /opt/module/spark-yarn/conf/spark-env.sh
#添加如下配置
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
7)启动HDFS以及YARN集群(之前编写了一个hdp.sh的Hadoop集群启动脚本)
hdp.sh start
8)执行一个程序
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.0.0.jar 15
参数说明:--master yarn,表示Yarn方式运行;--deploy-mode表示客户端方式运行程序
9)如果运行的时候,抛出如下异常ClassNotFoundException:com.sun.jersey.api.client.config.ClientConfig
-原因分析:Spark2中jersey版本是2.22,但是yarn中还需要依赖1.9,版本不兼容
-解决方式:在yarn-site.xml中,添加
<property>
<name>yarn.timeline-service.enabled</name>
<value>false</value>
</property>
10)查看hadoop103:8088页面,点击History,查看历史页面
思考:目前是Hadoop的作业运行日志展示,如果想获取Spark的作业运行日志,怎么办?
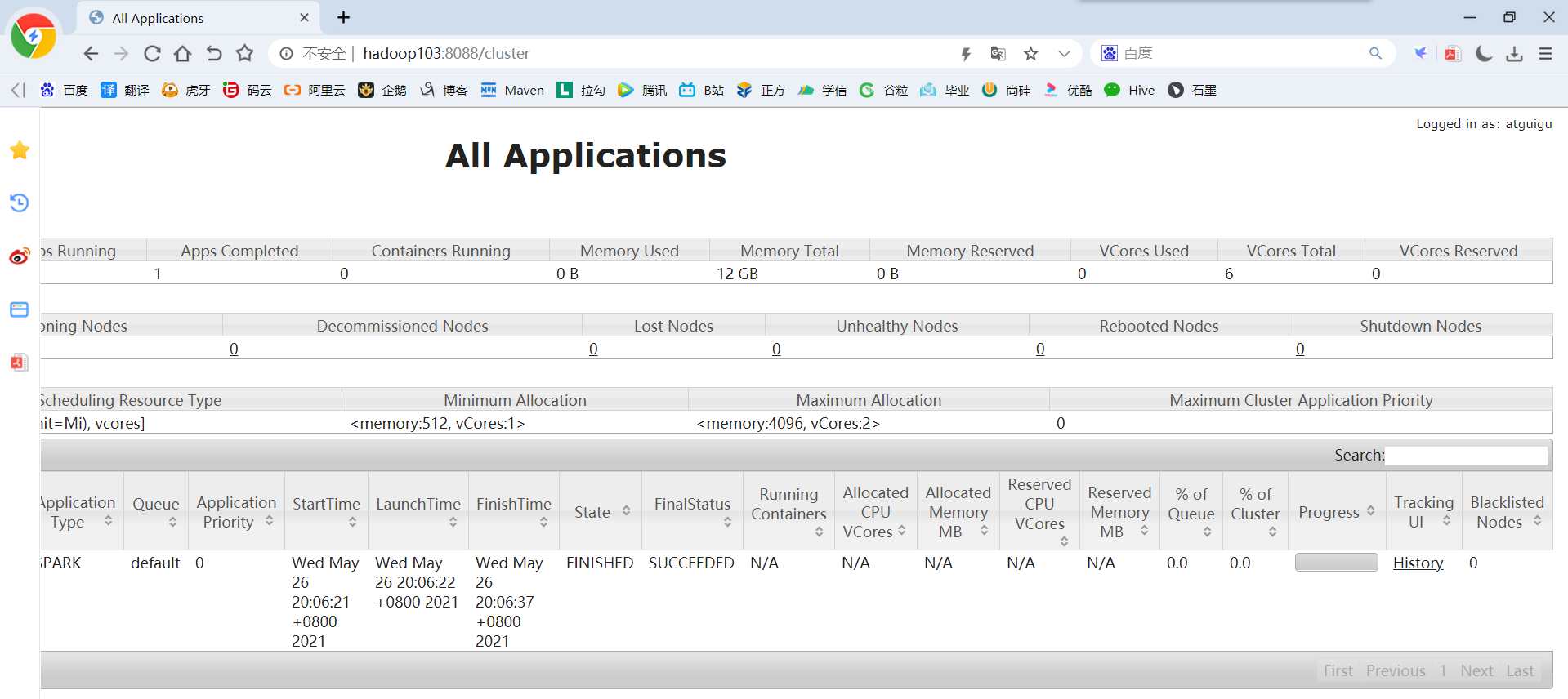
2.5.2 配置历史服务
由于是重新解压的Spark压缩文件,所以需要针对Yarn模式,再次配置一下历史服务器。
1)修改spark-default.conf.template名称
mv /opt/module/spark-yarn/conf/spark-defaults.conf.template /opt/module/spark-yarn/conf/spark-defaults.conf
2)修改spark-default.conf文件,配置日志存储路径(写)
vim /opt/module/spark-yarn/conf/spark-defaults.conf
spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop102:8020/sparklogs
3)修改spark-env.sh文件,添加如下配置:
vim /opt/module/spark-yarn/conf/spark-env.sh
# 参数1含义:WEBUI访问的端口号为18080 # 参数2含义:指定历史服务器日志存储路径 # 参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数 export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/sparklogs -Dspark.history.retainedApplications=30"
2.5.3 配置查看历史日志
为了从Yarn上关联到Spark历史服务器,需要配置关联路径。
1)修改配置文件/opt/module/spark-yarn/conf/spark-defaults.conf
vim /opt/module/spark-yarn/conf/spark-defaults.conf
#添加如下内容: spark.yarn.historyServer.address=hadoop102:18080 spark.history.ui.port=18080
2)重启Spark历史服务
sbin/stop-history-server.sh
sbin/start-history-server.sh
3)提交任务到Yarn执行
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.0.0.jar 15
4)Web页面查看日志:http://hadoop103:8088
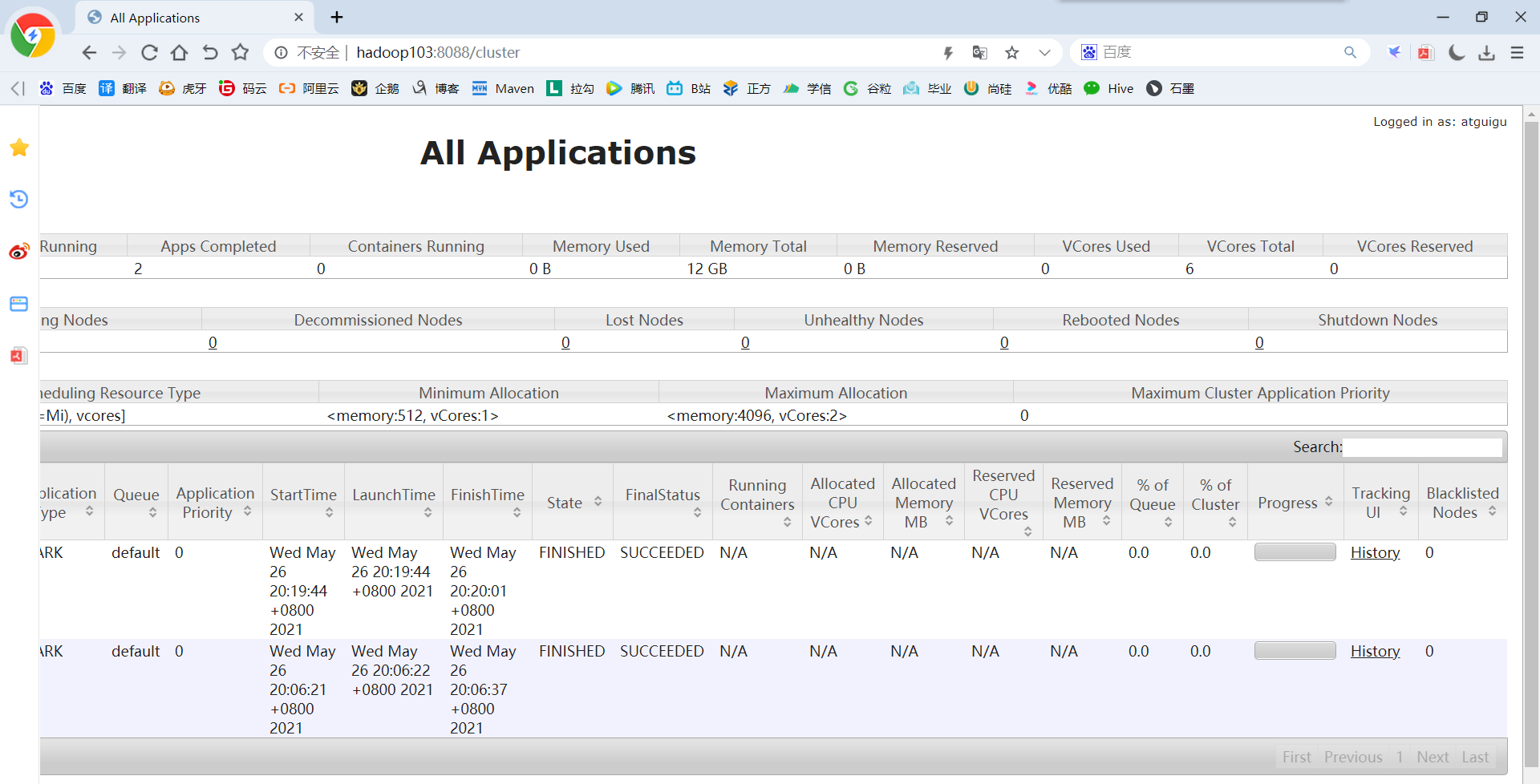
5)点击“history”跳转到 http://hadoop102:18080/
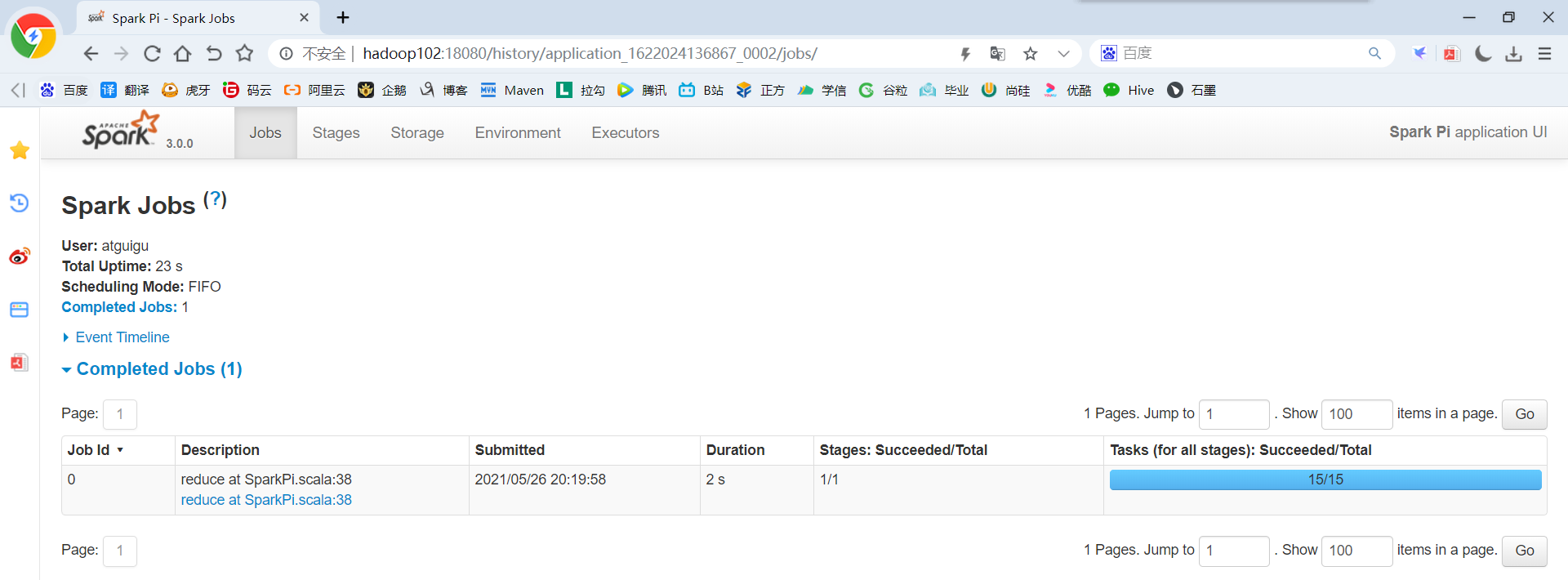
2.5.4 运行流程
Spark有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出。
yarn-cluster:Driver程序运行在由ResourceManager启动的APPMaster适用于生产环境。
1)客户端模式(默认)
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.0.0.jar 15
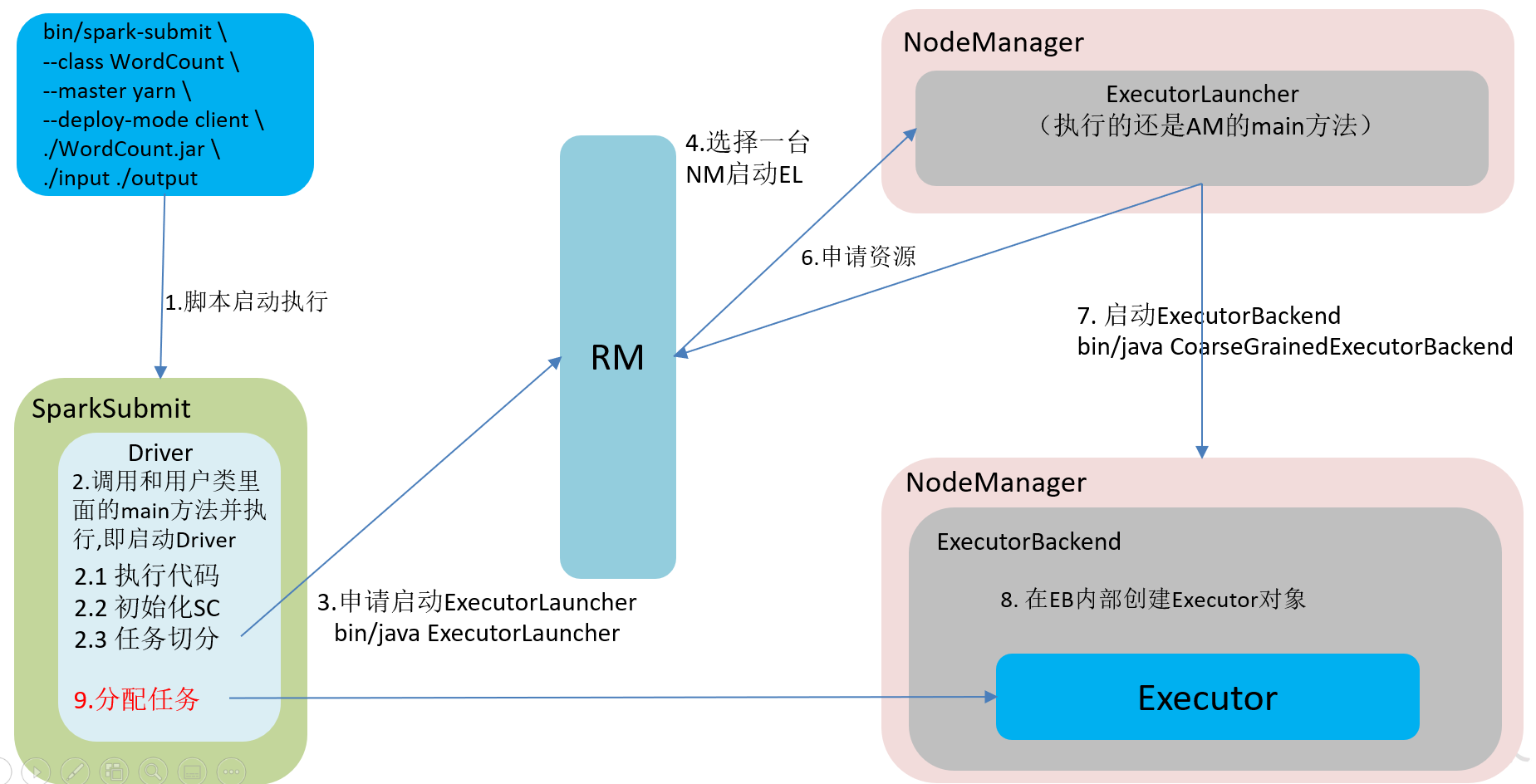
2)集群模式
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.0.0.jar 15
(1)查看http://hadoop103:8088页面,点击History按钮,跳转到历史详情页面
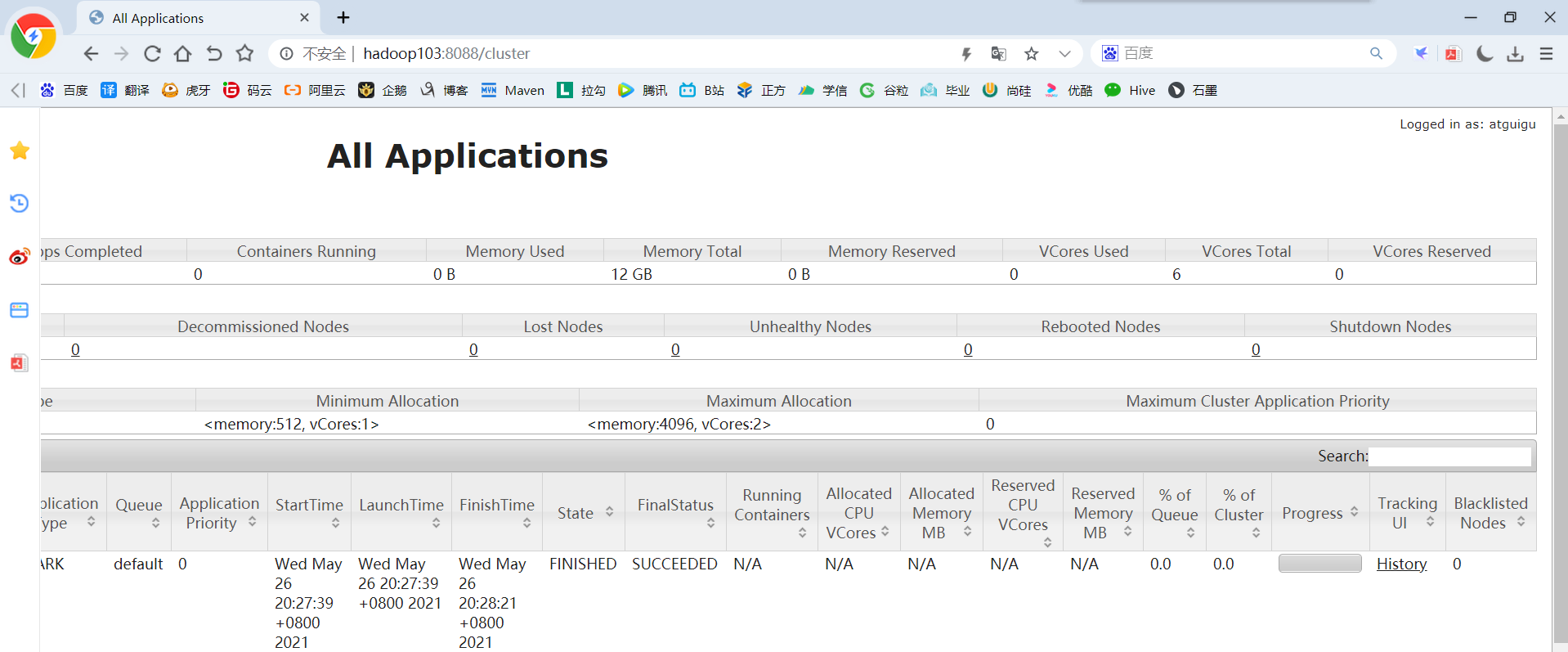
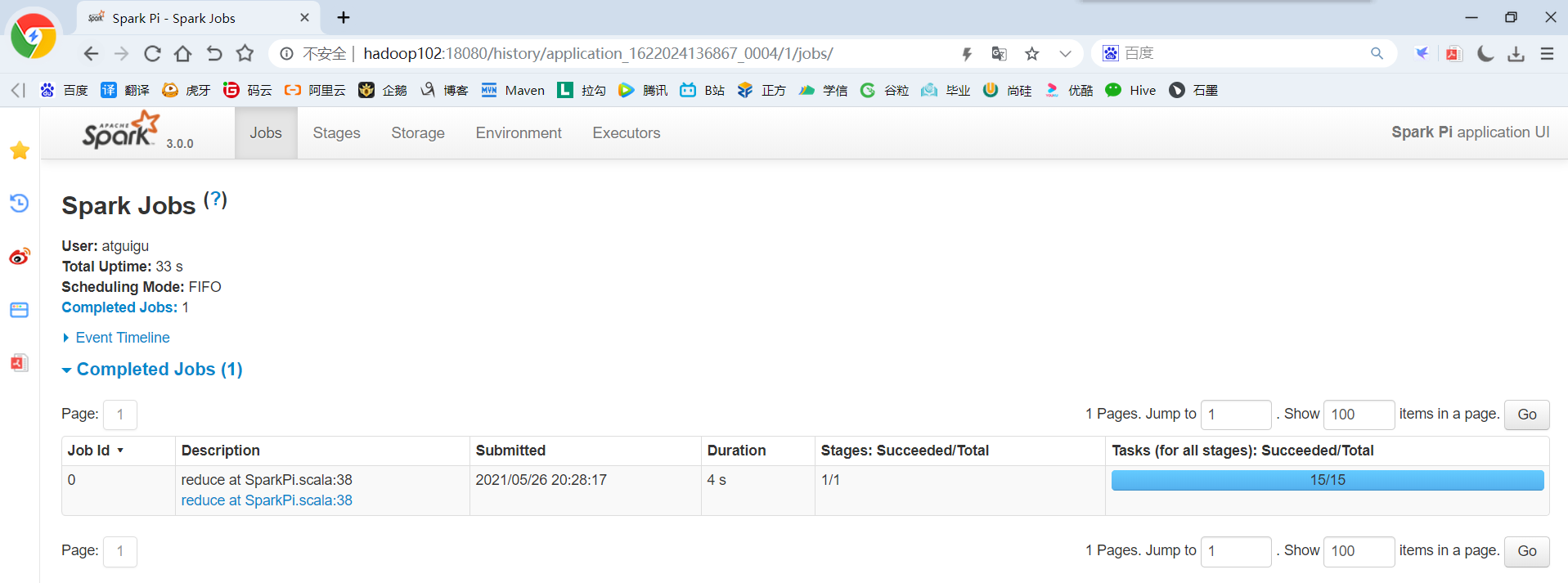
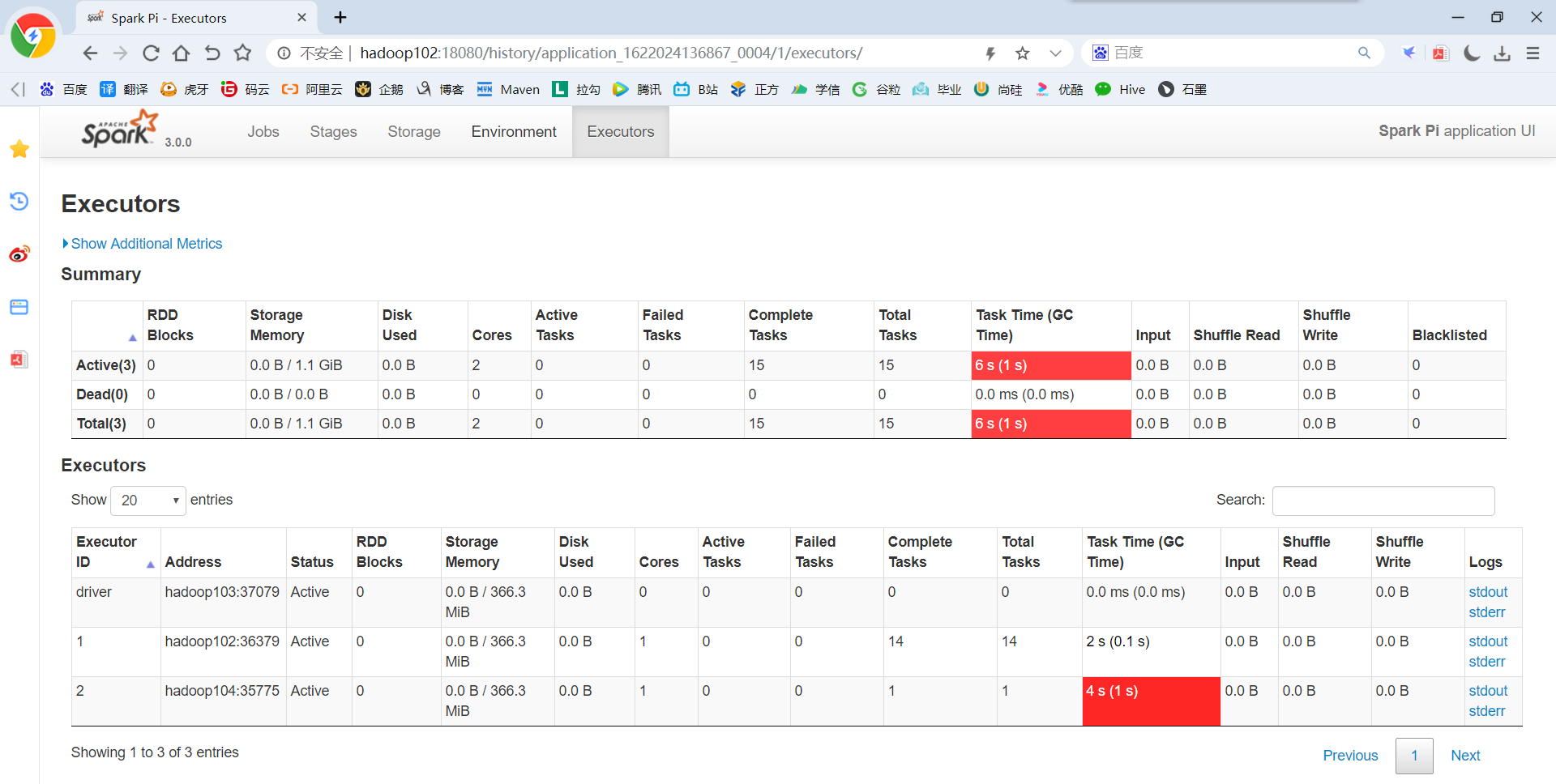
(2)http://hadoop102:18080点击Executors->点击driver中的stdout
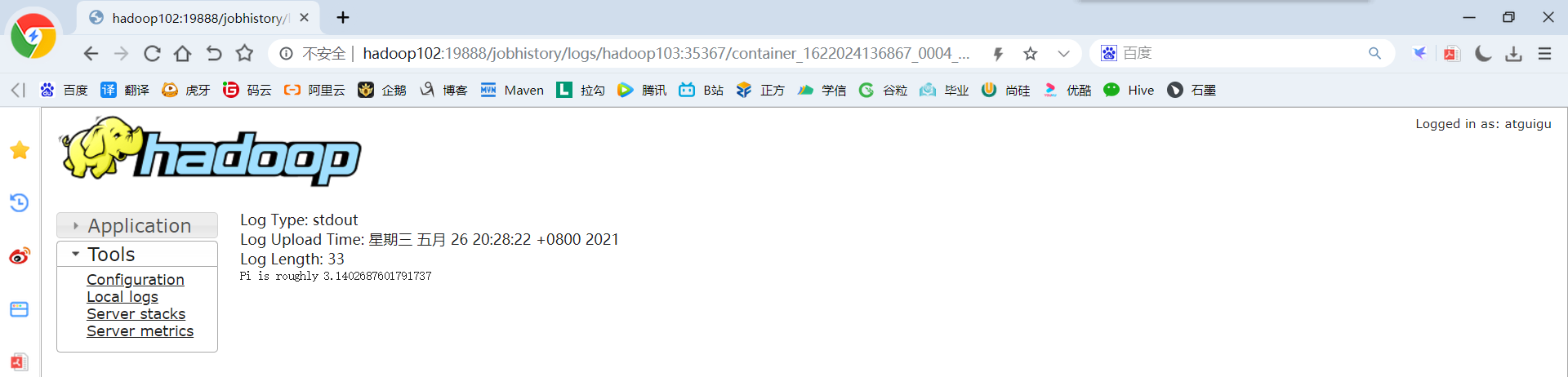
注意:如果在yarn日志端无法查看到具体的日志,则在yarn-site.xml中添加如下配置并启动Yarn历史服务器
vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
#hadoop历史服务器启动 #方式一 mr-jobhistory-daemon.sh start historyserver #方式二 /opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver
2.6 Mesos模式(了解)
Spark客户端直接连接Mesos;不需要额外构建Spark集群。国内应用比较少,更多的是运用Yarn调度。
2.7 几种模式对比
|
模式 |
Spark安装机器数 |
需启动的进程 |
所属者 |
|
Local |
1 |
无 |
Spark |
|
Standalone |
3 |
Master及Worker |
Spark |
|
Yarn |
1 |
Yarn及HDFS |
Hadoop |
2.8 端口号总结
1)Spark查看当前Spark-shell运行任务情况端口号:4040
2)Spark Master内部通信服务端口号:7077 (类比于Hadoop的8020(9000)端口)
3)Spark Standalone模式Master Web端口号:8080(类比于Hadoop YARN任务运行情况查看端口号:8088)
4)Spark历史服务器端口号:18080 (类比于Hadoop历史服务器端口号:19888)
第3章 WordCount案例实操
Spark Shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDEA中编制程序,然后打成Jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理Jar包的依赖。
3.1 编写程序
1)创建一个Maven项目
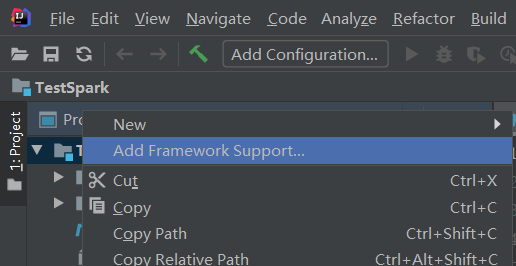
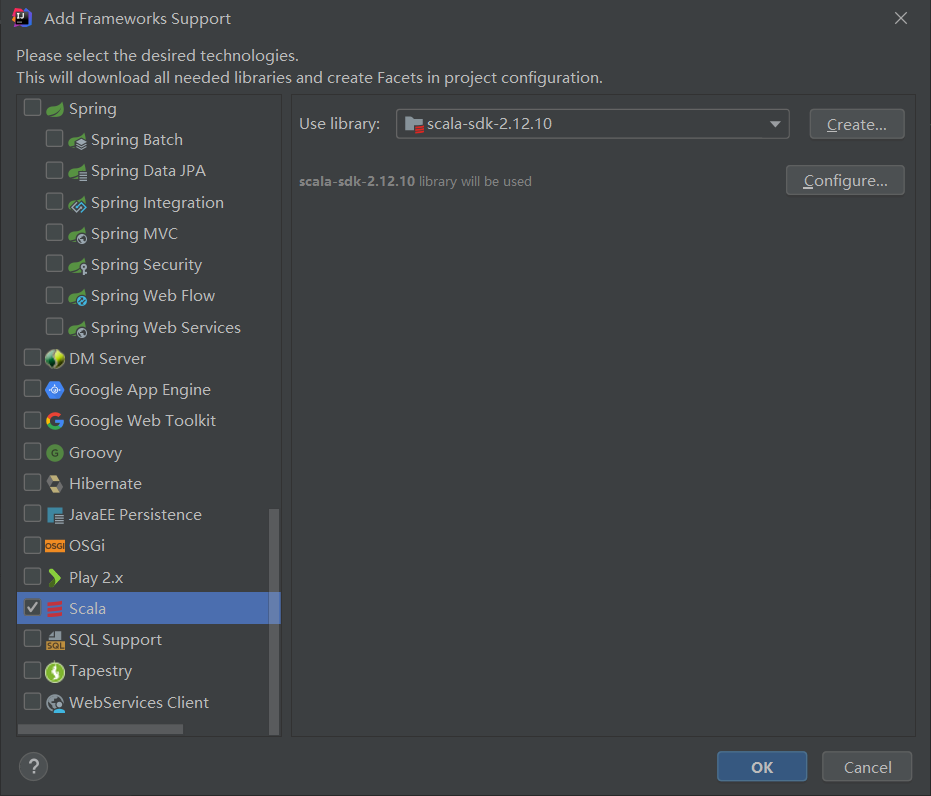
2)在项目上点击右键,Add Framework Support=》勾选scala,点击OK即可
3)在main下创建scala文件夹,并右键Mark Directory as Sources Root,然后在scala下创建包名为com.yuange.spark.day01
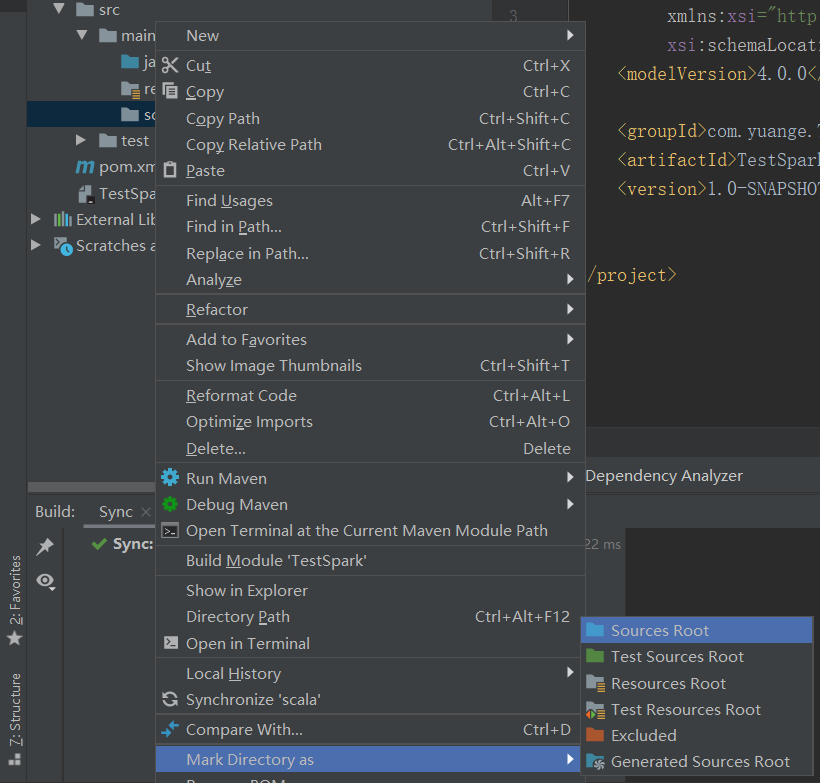
4)输入文件夹准备:在新建的Maven项目名称上右键=》新建datas文件夹=》在dats文件夹上右键=》分别新建1.txt和2.txt。每个文件里面准备一些word单词,如下:

hello atguigu
hello spark
5)导入项目依赖(如果maven版本为3.2.x,插件下载报错,那么修改插件版本为3.3.2)
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
6)创建伴生对象WordCount,编写代码
package com.yuange.spark.day01 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { //1.创建SparkConf并设置App名称 val conf = new SparkConf().setAppName("WC").setMaster("local[*]") //2.创建SparkContext,该对象是提交Spark App的入口 val sc = new SparkContext(conf) //3.读取指定位置文件:hello atguigu atguigu val lineRdd: RDD[String] = sc.textFile("datas") //4.读取的一行一行的数据分解成一个一个的单词(扁平化)(hello)(atguigu)(atguigu) val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" ")) //5. 将数据转换结构:(hello,1)(atguigu,1)(atguigu,1) val wordToOneRdd: RDD[(String, Int)] = wordRdd.map(word => (word, 1)) //6.将转换结构后的数据进行聚合处理 atguigu:1、1 =》1+1 (atguigu,2) val wordToSumRdd: RDD[(String, Int)] = wordToOneRdd.reduceByKey((v1, v2) => v1 + v2) //7.将统计结果采集到控制台打印 val wordToCountArray: Array[(String, Int)] = wordToSumRdd.collect() wordToCountArray.foreach(println) //一行搞定 //sc.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).saveAsTextFile(args(1)) //8.关闭连接 sc.stop() } }
7)打包插件
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<archive>
<manifest>
<mainClass>com.yuange.spark.day01.WordCount</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
8)打包到集群测试
(1)点击package打包,然后,查看打完后的jar包
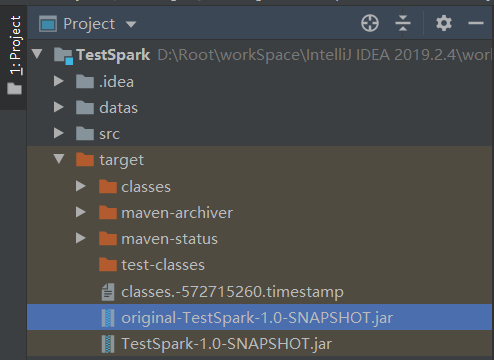
(2)将original-TestSpark-1.0-SNAPSHOT.jar上传到/opt/module/spark-yarn目录
(3)在HDFS上创建,存储输入文件的路径/spark
hadoop fs -mkdir /spark
(4)上传输入文件到/spark路径
hadoop fs -put /opt/module/spark-local/input /spark
(5)执行任务(/spark/input和/spark/ouput都是HDFS上的集群路径)
bin/spark-submit --class com.yuange.spark.day01.WordCount --master yarn original-TestSpark-1.0-SNAPSHOT.jar /spark/input/ /spark/output
(6)查询运行结果
hadoop fs -cat /spark/output/*
9)注意:如果运行发生压缩类没找到
(1)原因:Spark on Yarn会默认使用Hadoop集群配置文件设置编码方式,但是Spark在自己的spark-yarn/jars 包里面没有找到支持lzo压缩的jar包,所以报错。
(2)解决方案一:拷贝lzo的包到/opt/module/spark-yarn/jars目录,并分发
cp /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar /opt/module/spark-yarn/jars
xsync /opt/module/spark-yarn/jars/hadoop-lzo-0.4.20.jar
(3)解决方案二:在执行命令的时候指定lzo的包位置
bin/spark-submit --class com.yuange.spark.day01.WordCount --master yarn --driver-class-path /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar original-TestSpark-1.0-SNAPSHOT.jar /spark/input/ /spark/output
3.2 本地调试
本地Spark程序调试需要使用Local提交模式,即将本机当做运行环境,Master和Worker都为本机。运行时直接加断点调试即可。如下:
1)代码实现
package com.yuange.spark.day01 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { //1.创建SparkConf并设置App名称 val conf = new SparkConf().setAppName("WC").setMaster("local[*]") //2.创建SparkContext,该对象是提交Spark App的入口 val sc = new SparkContext(conf) //3.读取指定位置文件:hello atguigu atguigu val lineRdd: RDD[String] = sc.textFile("datas") //4.读取的一行一行的数据分解成一个一个的单词(扁平化)(hello)(atguigu)(atguigu) val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" ")) //5. 将数据转换结构:(hello,1)(atguigu,1)(atguigu,1) val wordToOneRdd: RDD[(String, Int)] = wordRdd.map(word => (word, 1)) //6.将转换结构后的数据进行聚合处理 atguigu:1、1 =》1+1 (atguigu,2) val wordToSumRdd: RDD[(String, Int)] = wordToOneRdd.reduceByKey((v1, v2) => v1 + v2) //7.将统计结果采集到控制台打印 val wordToCountArray: Array[(String, Int)] = wordToSumRdd.collect() wordToCountArray.foreach(println) //一行搞定 //sc.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).saveAsTextFile(args(1)) //8.关闭连接 sc.stop() } }
2)调试流程
(1)打断点
(2)以Debug模式运行
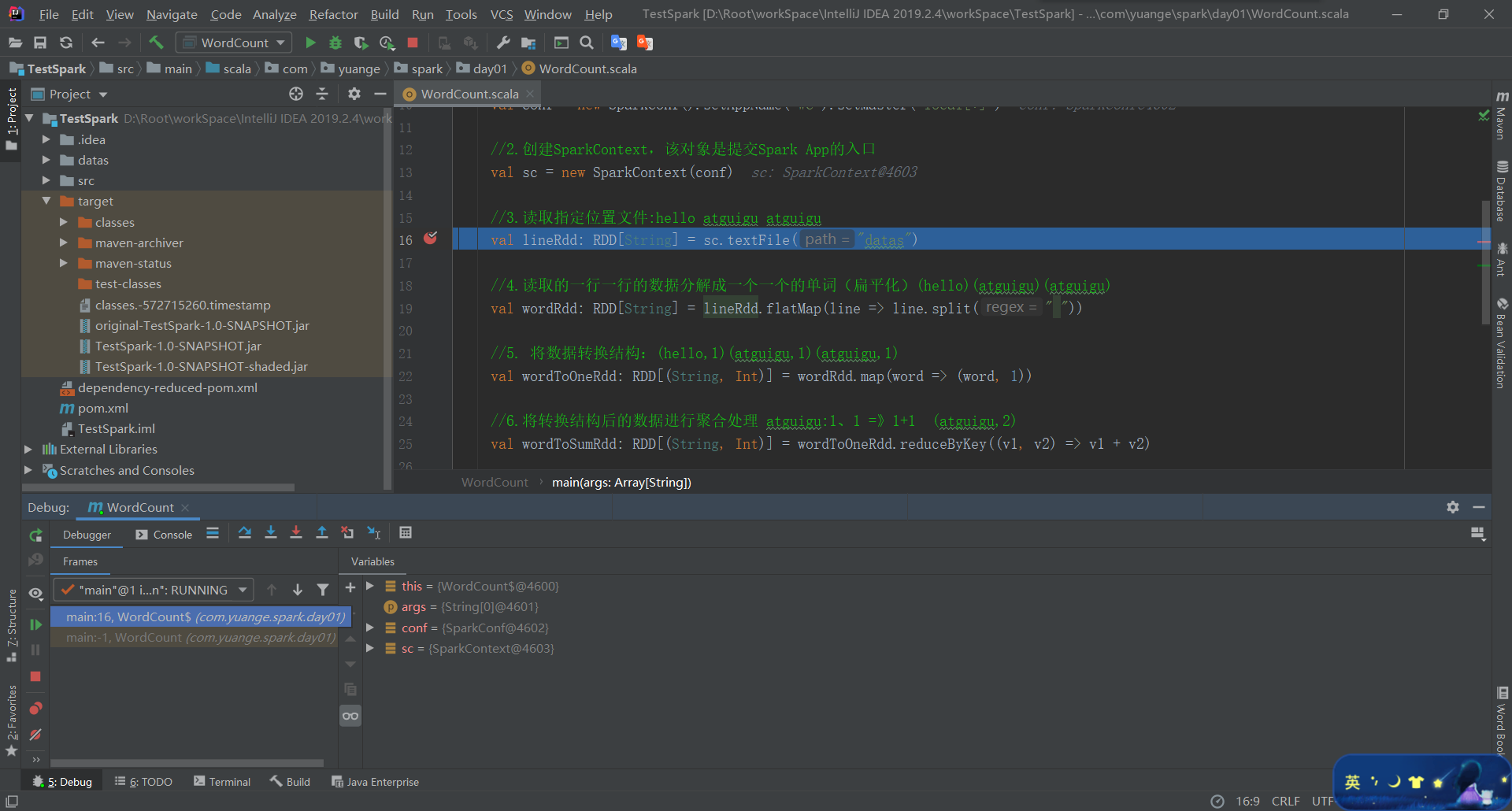
(3)往下一行代码执行,找到下图中的按钮,点击一次即可
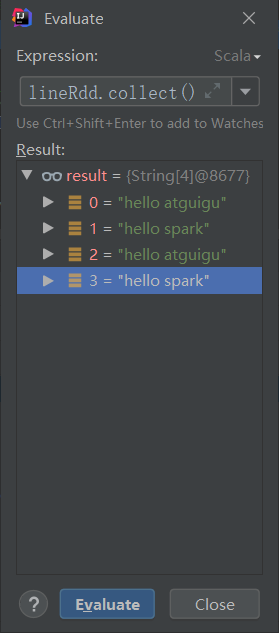
(4)找到下图的按钮,或者按快捷键Alt + F8,在输入框中输入 lineRdd.collect()就会出现数据

3.3 关联源码
1)按住ctrl键,点击RDD
2)提示下载或者绑定源码,点击Choose Sources...
![]()
3)解压资料包中spark-3.0.0.tgz到非中文路径。例如解压到:C:\workspace\root\spark-3.0.0\
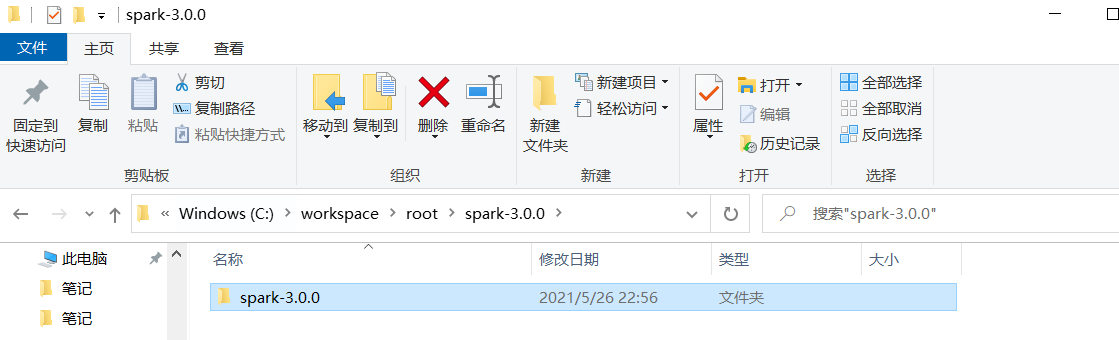
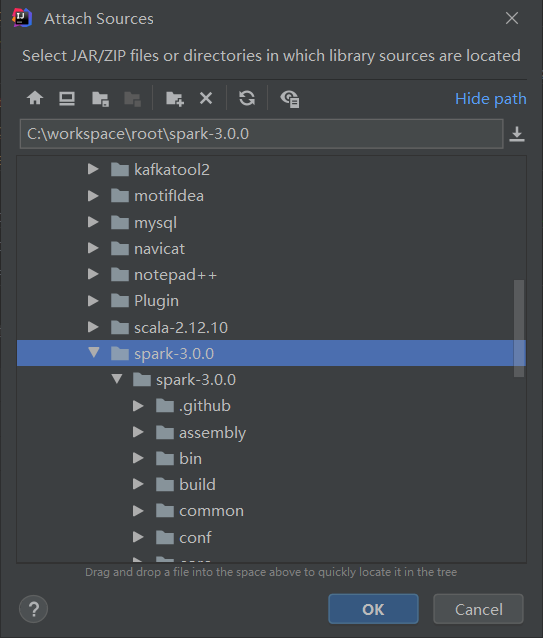
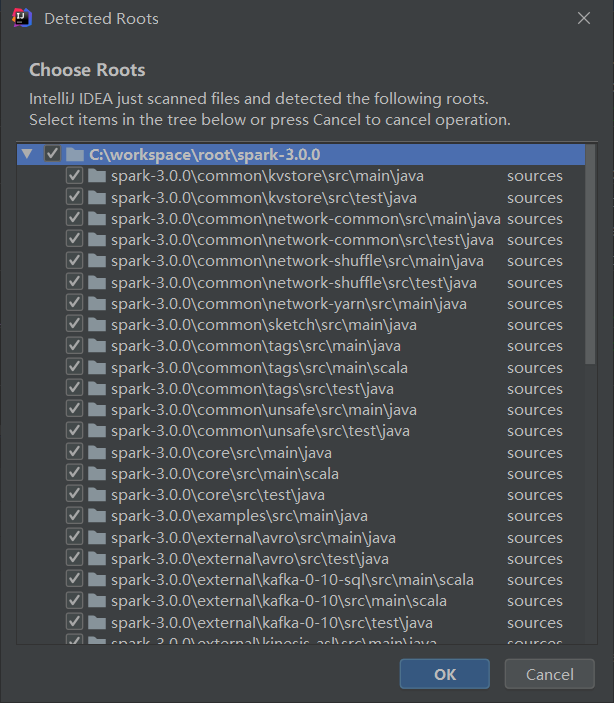
4)选择源码路径C:\workspace\root\spark-3.0.0\ ,点击OK即可
3.4 异常处理
如果本机操作系统是Windows,如果在程序中使用了Hadoop相关的东西,比如写入文件到HDFS,则会遇到如下异常:
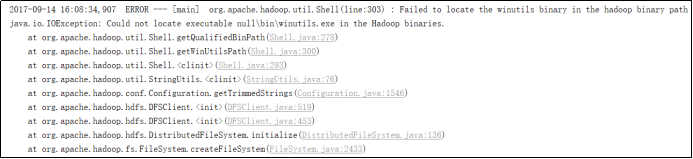
出现这个问题的原因,并不是程序的错误,而是用到了Hadoop相关的服务,解决办法
1)配置HADOOP_HOME环境变量
2)在IDEA中配置Run Configuration,添加HADOOP_HOME变量

