第1章 电商业务简介
1.1 电商业务流程
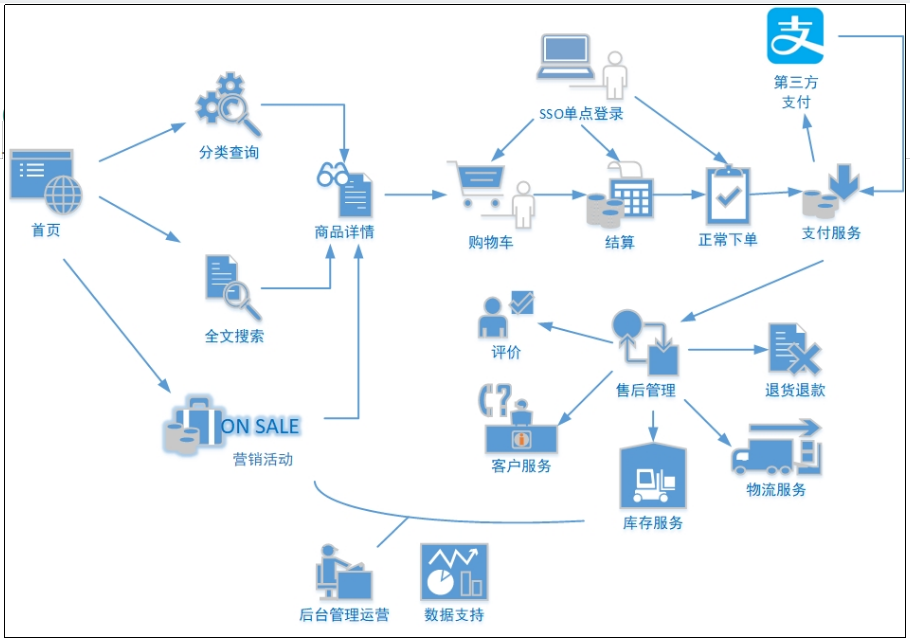
电商的业务流程可以以一个普通用户的浏览足迹为例进行说明,用户点开电商首页开始浏览,可能会通过分类查询也可能通过全文搜索寻找自己中意的商品,这些商品无疑都是存储在后台的管理系统中的。
当用户寻找到自己中意的商品,可能会想要购买,将商品添加到购物车后发现需要登录,登录后对商品进行结算,这时候购物车的管理和商品订单信息的生成都会对业务数据库产生影响,会生成相应的订单数据和支付数据。
订单正式生成之后,还会对订单进行跟踪处理,直到订单全部完成。
电商的主要业务流程包括用户前台浏览商品时的商品详情的管理,用户商品加入购物车进行支付时用户个人中心&支付服务的管理,用户支付完成后订单后台服务的管理,这些流程涉及到了十几个甚至几十个业务数据表,甚至更多。
1.2 电商常识
1.2.1 SKU和SPU
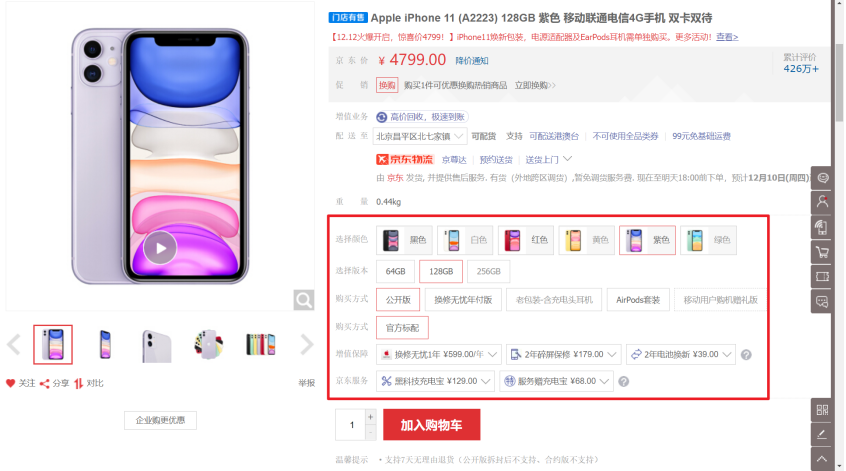
SKU=Stock Keeping Unit(库存量基本单位)。现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的SKU号。
SPU(Standard Product Unit):是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息集合。
例如:iPhoneX手机就是SPU。一台银色、128G内存的、支持联通网络的iPhoneX,就是SKU。
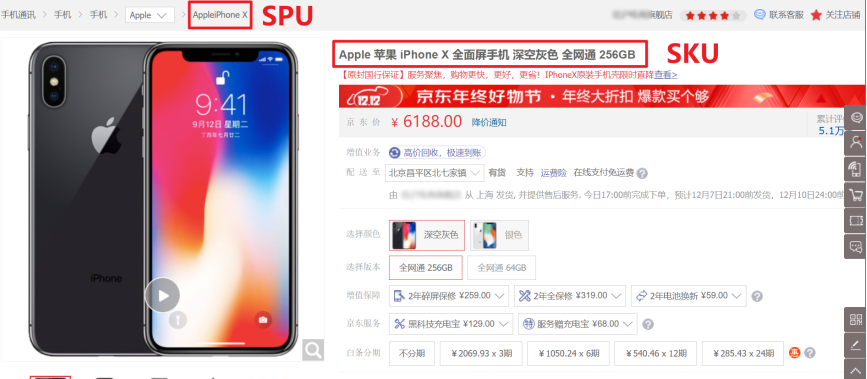
SPU表示一类商品。同一SPU的商品可以共用商品图片、海报、销售属性等。
1.2.2 平台属性和销售属性
1.平台属性

2.销售属性
1.3 电商系统表结构
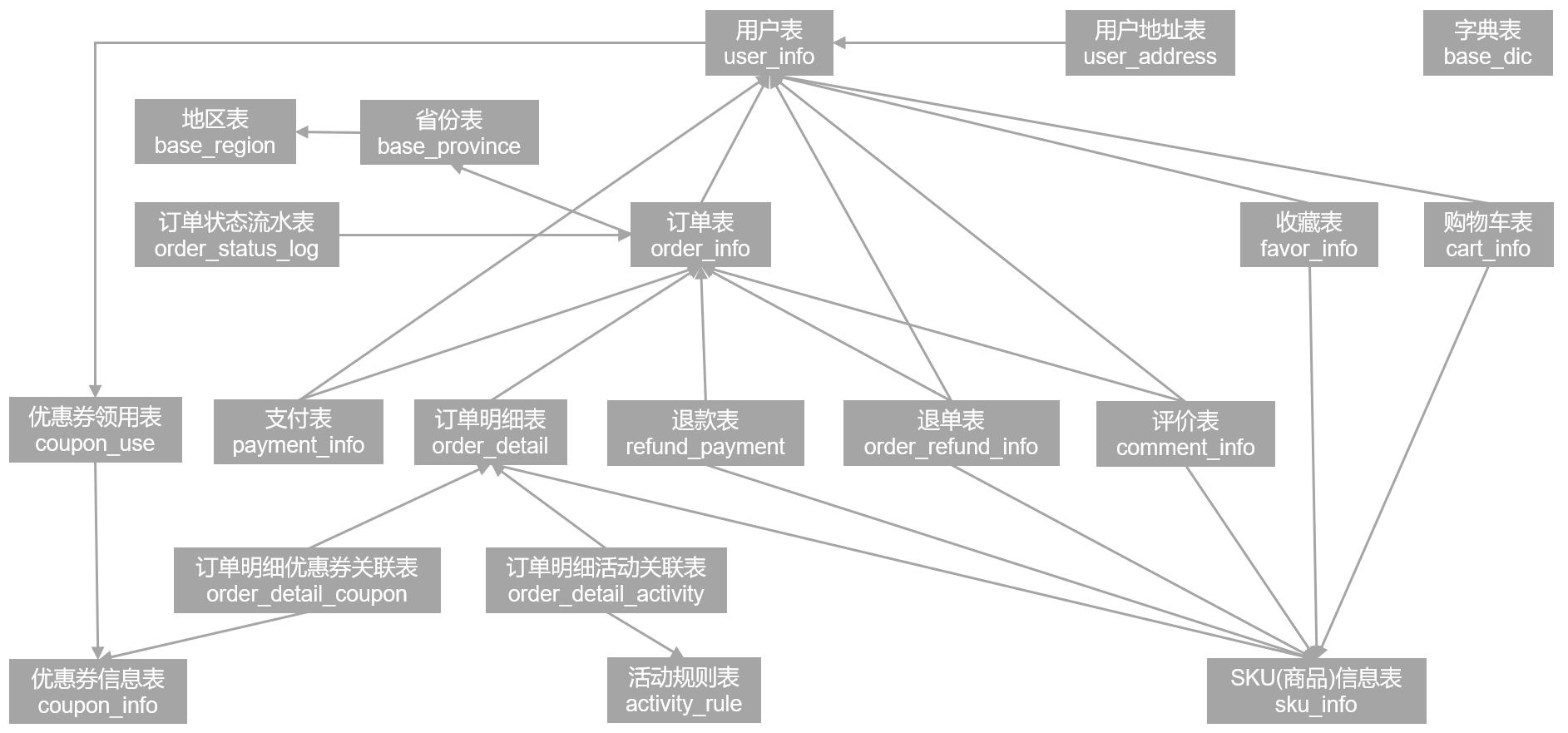
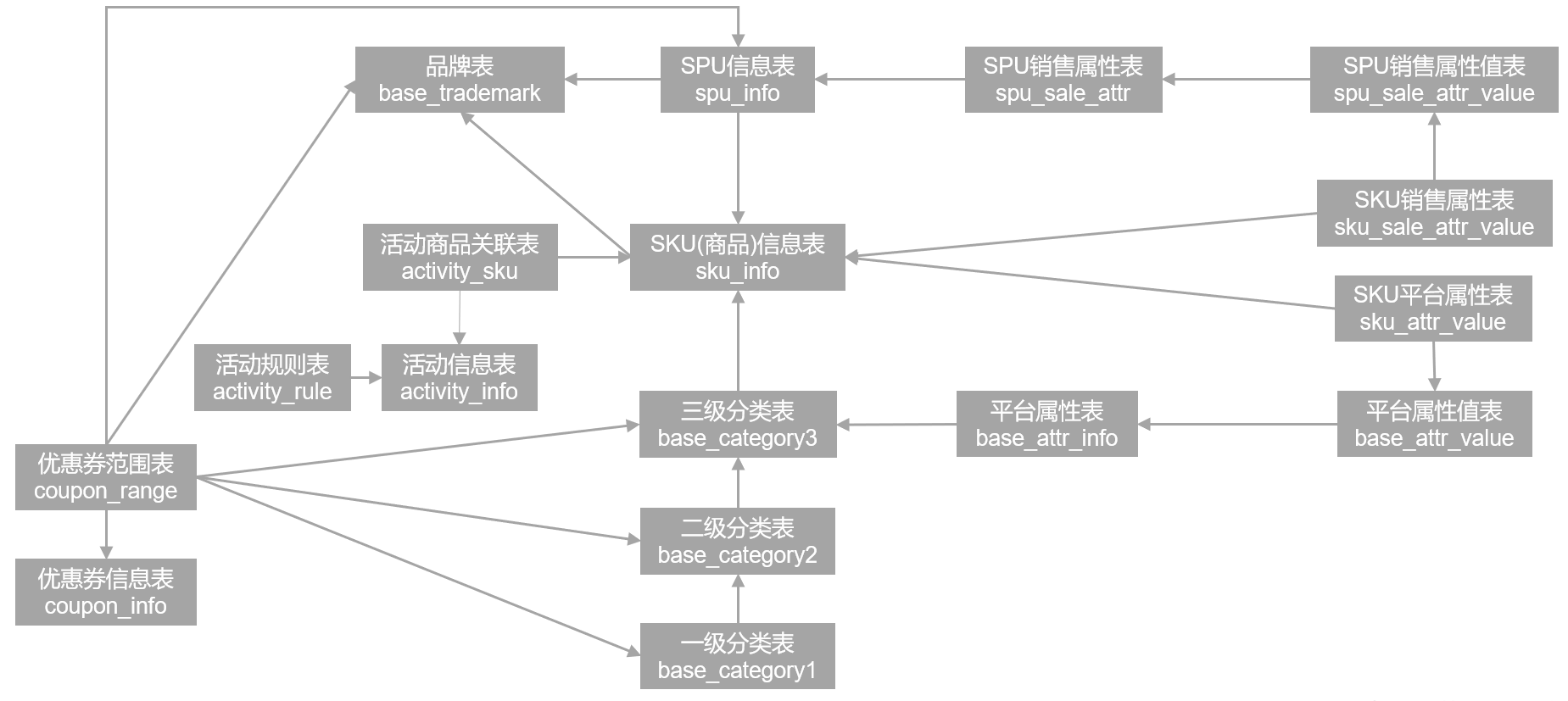
以下为本电商数仓系统涉及到的业务数据表结构关系。这34个表以订单表、用户表、SKU商品表、活动表和优惠券表为中心,延伸出了优惠券领用表、支付流水表、活动订单表、订单详情表、订单状态表、商品评论表、编码字典表退单表、SPU商品表等,用户表提供用户的详细信息,支付流水表提供该订单的支付详情,订单详情表提供订单的商品数量等情况,商品表给订单详情表提供商品的详细信息。本次讲解以此34个表为例,实际项目中,业务数据库中表格远远不止这些。
1)电商业务
2)后台管理
1.3.1 活动信息表(activity_info)
|
字段名 |
字段说明 |
|
id |
活动id |
|
activity_name |
活动名称 |
|
activity_type |
活动类型(1:满减,2:折扣) |
|
activity_desc |
活动描述 |
|
start_time |
开始时间 |
|
end_time |
结束时间 |
|
create_time |
创建时间 |
1.3.2 活动规则表(activity_rule)
|
id |
编号 |
|
activity_id |
类型 |
|
activity_type |
活动类型 |
|
condition_amount |
满减金额 |
|
condition_num |
满减件数 |
|
benefit_amount |
优惠金额 |
|
benefit_discount |
优惠折扣 |
|
benefit_level |
优惠级别 |
1.3.3 活动商品关联表(activity_sku)
|
字段名 |
字段说明 |
|
id |
编号 |
|
activity_id |
活动id |
|
sku_id |
sku_id |
|
create_time |
创建时间 |
1.3.4 平台属性表(base_attr_info)
|
字段名 |
字段说明 |
|
id |
编号 |
|
attr_name |
属性名称 |
|
category_id |
分类id |
|
category_level |
分类层级 |
1.3.5 平台属性值表(base_attr_value)
|
字段名 |
字段说明 |
|
id |
编号 |
|
value_name |
属性值名称 |
|
attr_id |
属性id |
1.3.6 一级分类表(base_category1)
|
字段名 |
字段说明 |
|
id |
编号 |
|
name |
分类名称 |
1.3.7 二级分类表(base_category2)
|
字段名 |
字段说明 |
|
id |
编号 |
|
name |
二级分类名称 |
|
category1_id |
一级分类编号 |
1.3.8 三级分类表(base_category3)
|
字段名 |
字段说明 |
|
id |
编号 |
|
name |
三级分类名称 |
|
category2_id |
二级分类编号 |
1.3.9 字典表(base_dic)
|
字段名 |
字段说明 |
|
dic_code |
编号 |
|
dic_name |
编码名称 |
|
parent_code |
父编号 |
|
create_time |
创建日期 |
|
operate_time |
修改日期 |
1.3.10 省份表(base_province)
|
字段名 |
字段说明 |
|
id |
id |
|
name |
省名称 |
|
region_id |
大区id |
|
area_code |
行政区位码 |
|
iso_code |
国际编码 |
|
iso_3166_2 |
ISO3166编码 |
1.3.11 地区表(base_region)
|
字段名 |
字段说明 |
|
id |
大区id |
|
region_name |
大区名称 |
1.3.12 品牌表(base_trademark)
|
字段名 |
字段说明 |
|
id |
编号 |
|
tm_name |
属性值 |
|
logo_url |
品牌logo的图片路径 |
1.3.13 购物车表(cart_info)
|
字段名 |
字段说明 |
|
id |
编号 |
|
user_id |
用户id |
|
sku_id |
skuid |
|
cart_price |
放入购物车时价格 |
|
sku_num |
数量 |
|
img_url |
图片文件 |
|
sku_name |
sku名称 (冗余) |
|
is_checked |
|
|
create_time |
创建时间 |
|
operate_time |
修改时间 |
|
is_ordered |
是否已经下单 |
|
order_time |
下单时间 |
|
source_type |
来源类型 |
|
source_id |
来源编号 |
1.3.14 评价表(comment_info)
|
字段名 |
字段说明 |
|
id |
编号 |
|
user_id |
用户id |
|
nick_name |
用户昵称 |
|
head_img |
|
|
sku_id |
skuid |
|
spu_id |
商品id |
|
order_id |
订单编号 |
|
appraise |
评价 1 好评 2 中评 3 差评 |
|
comment_txt |
评价内容 |
|
create_time |
创建时间 |
|
operate_time |
修改时间 |
1.3.15 优惠券信息表(coupon_info)
|
字段名 |
字段说明 |
|
id |
购物券编号 |
|
coupon_name |
购物券名称 |
|
coupon_type |
购物券类型 1 现金券 2 折扣券 3 满减券 4 满件打折券 |
|
condition_amount |
满额数(3) |
|
condition_num |
满件数(4) |
|
activity_id |
活动编号 |
|
benefit_amount |
减金额(1 3) |
|
benefit_discount |
折扣(2 4) |
|
create_time |
创建时间 |
|
range_type |
范围类型 1、商品(spuid) 2、品类(三级分类id) 3、品牌 |
|
limit_num |
最多领用次数 |
|
taken_count |
已领用次数 |
|
start_time |
可以领取的开始日期 |
|
end_time |
可以领取的结束日期 |
|
operate_time |
修改时间 |
|
expire_time |
过期时间 |
|
range_desc |
范围描述 |
1.3.16 优惠券优惠范围表(coupon_range)
|
字段名 |
字段说明 |
|
id |
购物券编号 |
|
coupon_id |
优惠券id |
|
range_type |
范围类型 1、商品(spuid) 2、品类(三级分类id) 3、品牌 |
|
range_id |
|
1.3.17 优惠券领用表(coupon_use)
|
字段名 |
字段说明 |
|
id |
编号 |
|
coupon_id |
购物券ID |
|
user_id |
用户ID |
|
order_id |
订单ID |
|
coupon_status |
购物券状态(1:未使用 2:已使用) |
|
get_time |
获取时间 |
|
using_time |
使用时间 |
|
used_time |
支付时间 |
|
expire_time |
过期时间 |
1.3.18 收藏表(favor_info)
|
字段名 |
字段说明 |
|
id |
编号 |
|
user_id |
用户名称 |
|
sku_id |
skuid |
|
spu_id |
商品id |
|
is_cancel |
是否已取消 0 正常 1 已取消 |
|
create_time |
创建时间 |
|
cancel_time |
修改时间 |
1.3.19 订单明细表(order_detail)
|
字段名 |
字段说明 |
|
id |
编号 |
|
order_id |
订单编号 |
|
sku_id |
sku_id |
|
sku_name |
sku名称(冗余) |
|
img_url |
图片名称(冗余) |
|
order_price |
购买价格(下单时sku价格) |
|
sku_num |
购买个数 |
|
create_time |
创建时间 |
|
source_type |
来源类型 |
|
source_id |
来源编号 |
|
split_total_amount |
|
|
split_activity_amount |
|
|
split_coupon_amount |
|
1.3.20 订单明细活动关联表(order_detail_activity)
|
字段名 |
字段说明 |
|
id |
编号 |
|
order_id |
订单id |
|
order_detail_id |
订单明细id |
|
activity_id |
活动ID |
|
activity_rule_id |
活动规则 |
|
sku_id |
skuID |
|
create_time |
获取时间 |
1.3.21 订单明细优惠券关联表(order_detail_coupon)
|
字段名 |
字段说明 |
|
id |
编号 |
|
order_id |
订单id |
|
order_detail_id |
订单明细id |
|
coupon_id |
购物券ID |
|
coupon_use_id |
购物券领用id |
|
sku_id |
skuID |
|
create_time |
获取时间 |
1.3.22 订单表(order_info)
|
字段名 |
字段说明 |
|
id |
编号 |
|
consignee |
收货人 |
|
consignee_tel |
收件人电话 |
|
total_amount |
总金额 |
|
order_status |
订单状态 |
|
user_id |
用户id |
|
payment_way |
付款方式 |
|
delivery_address |
送货地址 |
|
order_comment |
订单备注 |
|
out_trade_no |
订单交易编号(第三方支付用) |
|
trade_body |
订单描述(第三方支付用) |
|
create_time |
创建时间 |
|
operate_time |
操作时间 |
|
expire_time |
失效时间 |
|
process_status |
进度状态 |
|
tracking_no |
物流单编号 |
|
parent_order_id |
父订单编号 |
|
img_url |
图片路径 |
|
province_id |
地区 |
|
activity_reduce_amount |
促销金额 |
|
coupon_reduce_amount |
优惠券 |
|
original_total_amount |
原价金额 |
|
feight_fee |
运费 |
|
feight_fee_reduce |
运费减免 |
|
refundable_time |
可退款日期(签收后30天) |
1.3.23 退单表(order_refund_info)
|
字段名 |
字段说明 |
|
id |
编号 |
|
user_id |
用户id |
|
order_id |
订单id |
|
sku_id |
skuid |
|
refund_type |
退款类型 |
|
refund_num |
退货件数 |
|
refund_amount |
退款金额 |
|
refund_reason_type |
原因类型 |
|
refund_reason_txt |
原因内容 |
|
refund_status |
退款状态(0:待审批 1:已退款) |
|
create_time |
创建时间 |
1.3.24 订单状态流水表(order_status_log)
|
字段名 |
字段说明 |
|
id |
|
|
order_id |
|
|
order_status |
|
|
operate_time |
|
1.3.25 支付表(payment_info)
|
字段名 |
字段说明 |
|
id |
编号 |
|
out_trade_no |
对外业务编号 |
|
order_id |
订单编号 |
|
user_id |
|
|
payment_type |
支付类型(微信 支付宝) |
|
trade_no |
交易编号 |
|
total_amount |
支付金额 |
|
subject |
交易内容 |
|
payment_status |
支付状态 |
|
create_time |
创建时间 |
|
callback_time |
回调时间 |
|
callback_content |
回调信息 |
1.3.26 退款表(refund_payment)
|
字段名 |
字段说明 |
|
id |
编号 |
|
out_trade_no |
对外业务编号 |
|
order_id |
订单编号 |
|
sku_id |
|
|
payment_type |
支付类型(微信 支付宝) |
|
trade_no |
交易编号 |
|
total_amount |
退款金额 |
|
subject |
交易内容 |
|
refund_status |
退款状态 |
|
create_time |
创建时间 |
|
callback_time |
回调时间 |
|
callback_content |
回调信息 |
1.3.27 SKU平台属性表(sku_attr_value)
|
字段名 |
字段说明 |
|
id |
编号 |
|
attr_id |
属性id(冗余) |
|
value_id |
属性值id |
|
sku_id |
skuid |
|
attr_name |
属性名称 |
|
value_name |
属性值名称 |
1.3.28 SKU信息表(sku_info)
|
字段名 |
字段说明 |
|
id |
库存id(itemID) |
|
spu_id |
商品id |
|
price |
价格 |
|
sku_name |
sku名称 |
|
sku_desc |
商品规格描述 |
|
weight |
重量 |
|
tm_id |
品牌(冗余) |
|
category3_id |
三级分类id(冗余) |
|
sku_default_img |
默认显示图片(冗余) |
|
is_sale |
是否销售(1:是 0:否) |
|
create_time |
创建时间 |
1.3.29 SKU销售属性表(sku_sale_attr_value)
|
字段名 |
字段说明 |
|
id |
id |
|
sku_id |
库存单元id |
|
spu_id |
spu_id(冗余) |
|
sale_attr_value_id |
销售属性值id |
|
sale_attr_id |
|
|
sale_attr_name |
|
|
sale_attr_value_name |
|
1.3.30 SPU信息表(spu_info)
|
字段名 |
字段说明 |
|
id |
商品id |
|
spu_name |
商品名称 |
|
description |
商品描述(后台简述) |
|
category3_id |
三级分类id |
|
tm_id |
品牌id |
1.3.31 SPU销售属性表(spu_sale_attr)
|
字段名 |
字段说明 |
|
id |
编号(业务中无关联) |
|
spu_id |
商品id |
|
base_sale_attr_id |
销售属性id |
|
sale_attr_name |
销售属性名称(冗余) |
1.3.32 SPU销售属性值表(spu_sale_attr_value)
|
字段名 |
字段说明 |
|
id |
销售属性值编号 |
|
spu_id |
商品id |
|
base_sale_attr_id |
销售属性id |
|
sale_attr_value_name |
销售属性值名称 |
|
sale_attr_name |
销售属性名称(冗余) |
1.3.33 用户地址表(user_address)
|
字段名 |
字段说明 |
|
id |
编号 |
|
user_id |
用户id |
|
province_id |
省份id |
|
user_address |
用户地址 |
|
consignee |
收件人 |
|
phone_num |
联系方式 |
|
is_default |
是否是默认 |
1.3.34 用户信息表(user_info)
|
字段名 |
字段说明 |
|
id |
编号 |
|
login_name |
用户名称 |
|
nick_name |
用户昵称 |
|
passwd |
用户密码 |
|
name |
用户姓名 |
|
phone_num |
手机号 |
|
|
邮箱 |
|
head_img |
头像 |
|
user_level |
用户级别 |
|
birthday |
用户生日 |
|
gender |
性别 M男,F女 |
|
create_time |
创建时间 |
|
operate_time |
修改时间 |
|
status |
状态 |
第2章 业务数据采集模块
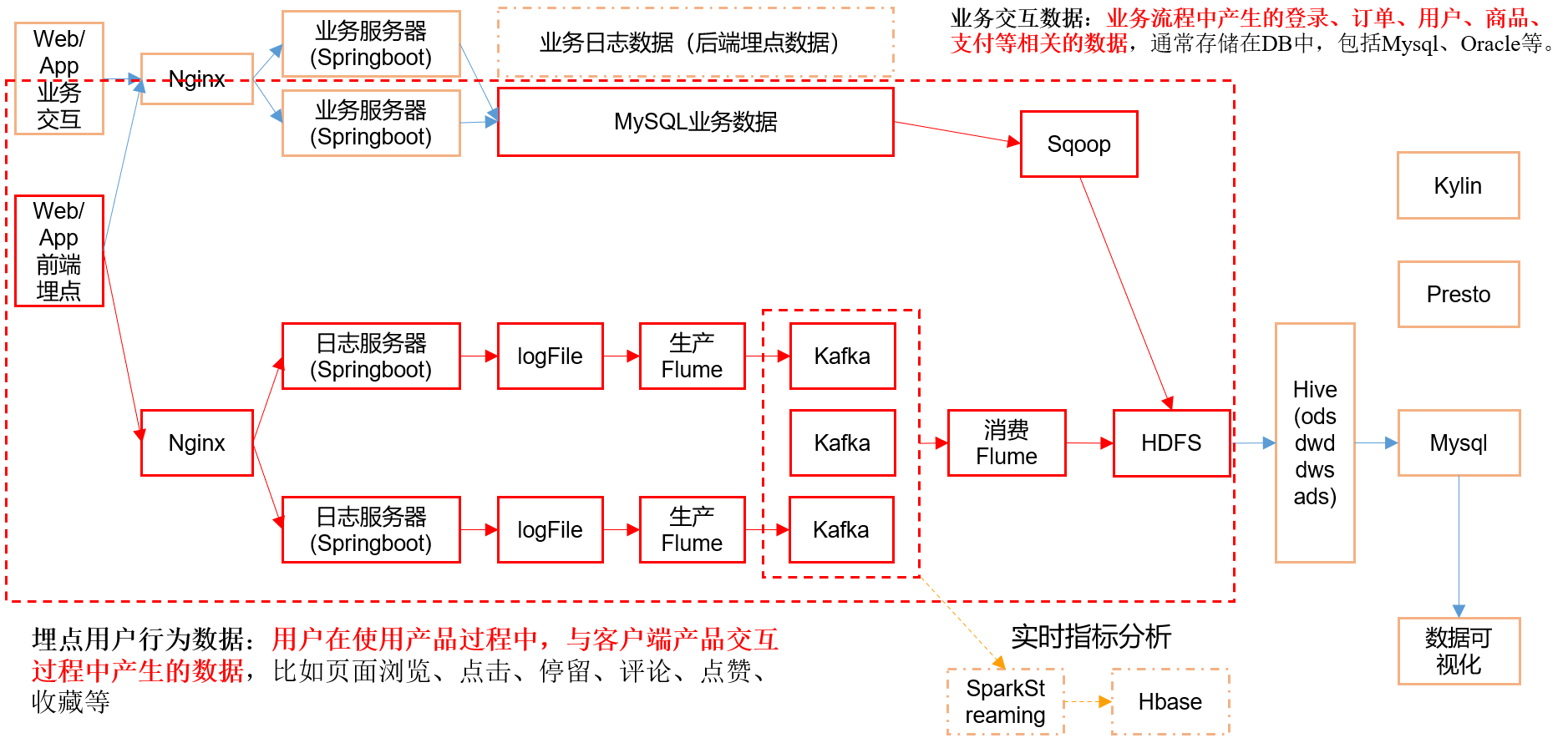
2.1 MySQL安装
2.1.1 安装包准备(下载地址在上篇博客找:https://www.cnblogs.com/LzMingYueShanPao/p/14744738.html)
1)卸载自带的Mysql-libs(如果之前安装过mysql,要全都卸载掉)
rpm -qa | grep -i -E mysql\|mariadb | xargs -n1 sudo rpm -e --nodeps
2)将安装包和JDBC驱动上传到/opt/software,共计6个
01_mysql-community-common-5.7.16-1.el7.x86_64.rpm 02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm 03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm 04_mysql-community-client-5.7.16-1.el7.x86_64.rpm 05_mysql-community-server-5.7.16-1.el7.x86_64.rpm mysql-connector-java-5.1.27-bin.jar
2.1.2 安装MySQL
1)安装mysql依赖
sudo yum install -y 01_mysql-community-common-5.7.16-1.el7.x86_64.rpm sudo yum install -y 02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm sudo yum install -y 03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm
2)安装mysql-client
sudo yum install -y 04_mysql-community-client-5.7.16-1.el7.x86_64.rpm
3)安装mysql-server
sudo yum install -y 05_mysql-community-server-5.7.16-1.el7.x86_64.rpm
4)启动mysql并设置开机自启
sudo systemctl start mysqld sudo systemctl enable mysqld
5)查看mysql密码
sudo cat /var/log/mysqld.log | grep password
2.1.3 配置MySQL
配置只要是root用户+密码,在任何主机上都能登录MySQL数据库。
1)用刚刚查到的密码进入mysql
mysql -uroot -p
2)设置复杂密码(由于mysql密码策略,此密码必须足够复杂)
set password=password("Qs23=zs32");
3)更改mysql密码策略
set global validate_password_length=4;
set global validate_password_policy=0;
4)设置简单好记的密码
set password=password("root123");
5)进入msyql库
use mysql
6)查询user表
select user, host from user;
7)修改user表,把Host表内容修改为%
update user set host="%" where user="root";
8)刷新
flush privileges;
9)退出
quit;
2.2 业务数据生成
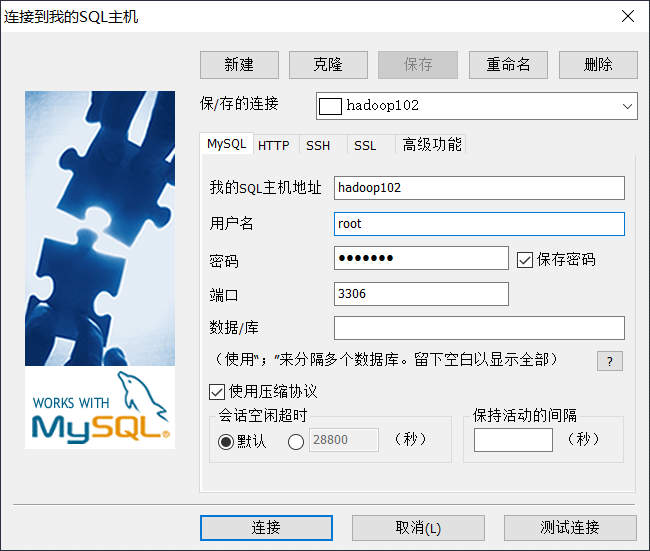
2.2.1 连接MySQL
通过MySQL可视化客户端连接数据库。
2.2.2 建表语句
1)创建数据库,设置数据库名称为gmall,编码为utf-8,排序规则为utf8_general_ci

2)导入数据库结构脚本(gmall.sql),完成后,刷新一下对象浏览器,就可以看见数据库中的表了。
2.2.3 生成业务数据
1)在hadoop102的/opt/module/目录下创建mock文件夹
mkdir /opt/module/mock
2)把gmall2020-mock-db-2021-01-22.jar和application.properties上传到hadoop102的/opt/module/mock路径上。
3)根据需求修改application.properties相关配置(若是第一次生成,则修改mock.clear=1以及mock.clear.user=1)
vim application.properties
logging.level.root=info spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://hadoop102:3306/gmall?characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8 spring.datasource.username=root spring.datasource.password=root123 logging.pattern.console=%m%n mybatis-plus.global-config.db-config.field-strategy=not_null #业务日期 mock.date=2020-06-14 #第一次生成数据,需要将以下两个重置配置设置为1 #是否重置 mock.clear=0 #是否重置用户 mock.clear.user=0 #生成新用户数量 mock.user.count=100 #男性比例 mock.user.male-rate=20 #用户数据变化概率 mock.user.update-rate:20 #收藏取消比例 mock.favor.cancel-rate=10 #收藏数量 mock.favor.count=100 #每个用户添加购物车的概率 mock.cart.user-rate=50 #每次每个用户最多添加多少种商品进购物车 mock.cart.max-sku-count=8 #每个商品最多买几个 mock.cart.max-sku-num=3 #购物车来源 用户查询,商品推广,智能推荐, 促销活动 mock.cart.source-type-rate=60:20:10:10 #用户下单比例 mock.order.user-rate=50 #用户从购物中购买商品比例 mock.order.sku-rate=50 #是否参加活动 mock.order.join-activity=1 #是否使用购物券 mock.order.use-coupon=1 #购物券领取人数 mock.coupon.user-count=100 #支付比例 mock.payment.rate=70 #支付方式 支付宝:微信 :银联 mock.payment.payment-type=30:60:10 #评价比例 好:中:差:自动 mock.comment.appraise-rate=30:10:10:50 #退款原因比例:质量问题 商品描述与实际描述不一致 缺货 号码不合适 拍错 不想买了 其他 mock.refund.reason-rate=30:10:20:5:15:5:5
4)并在该目录下执行,如下命令,生成2021-05-11日期数据:
java -jar gmall2020-mock-db-2021-01-22.jar
5)查看gmall数据库,观察是否有2021-05-11的数据出现
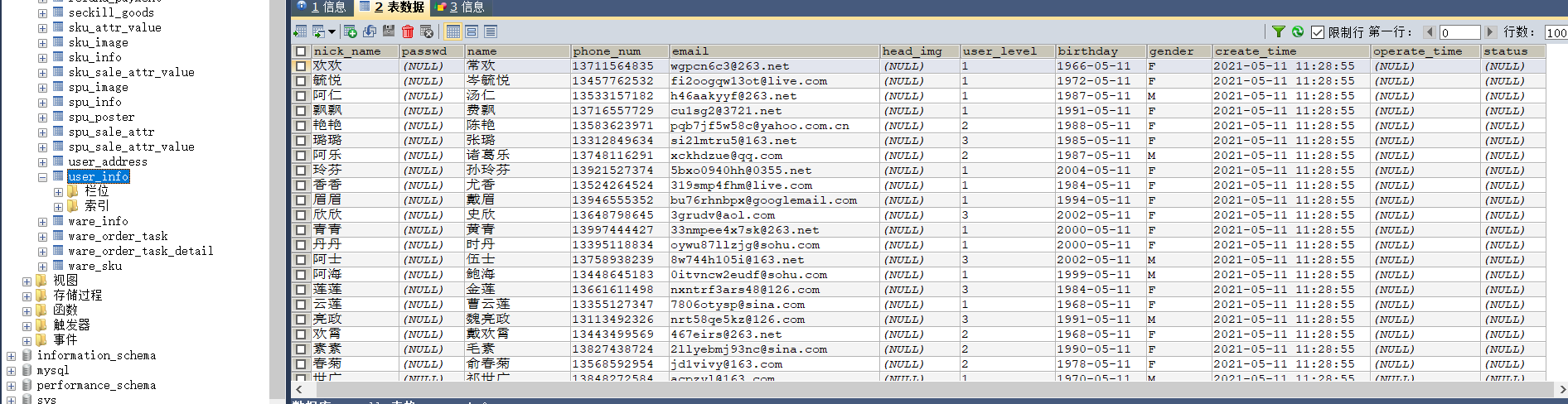
2.2.4 业务数据建模
可借助EZDML这款数据库设计工具,来辅助我们梳理复杂的业务表关系。
1)下载地址:http://www.ezdml.com/download_cn.html
2)使用说明
(1)点击“模型”,选择“新建模型”

(2)命名模型,双击即可

(3)点击图标,选中gmall模型
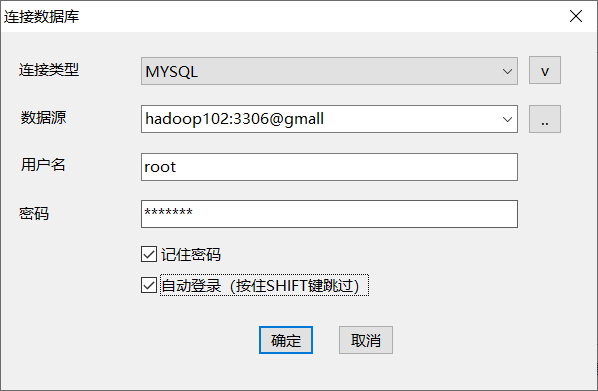
(4)点击“模型”,选择“导入数据库”,配置数据库连接
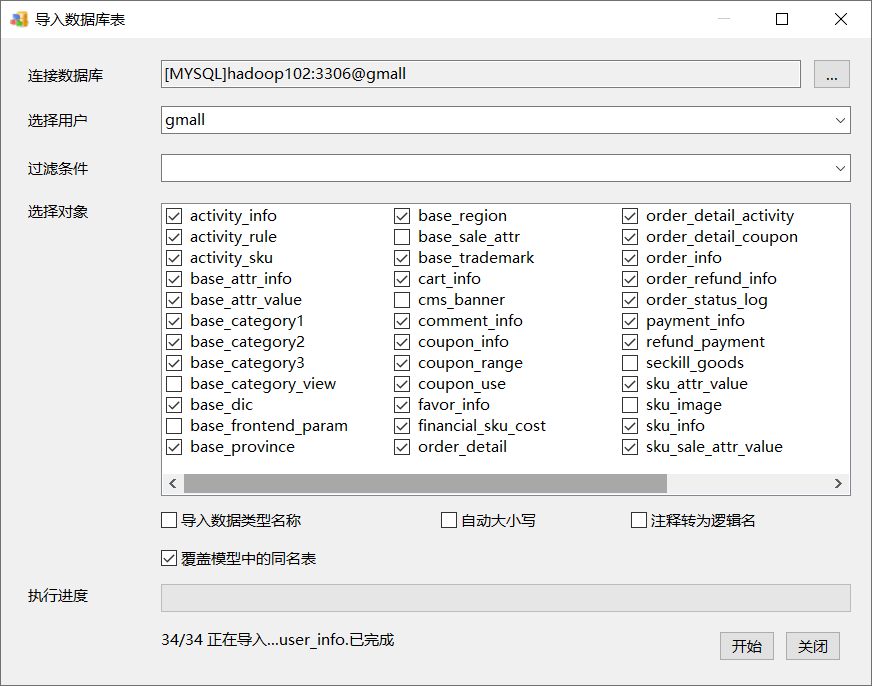
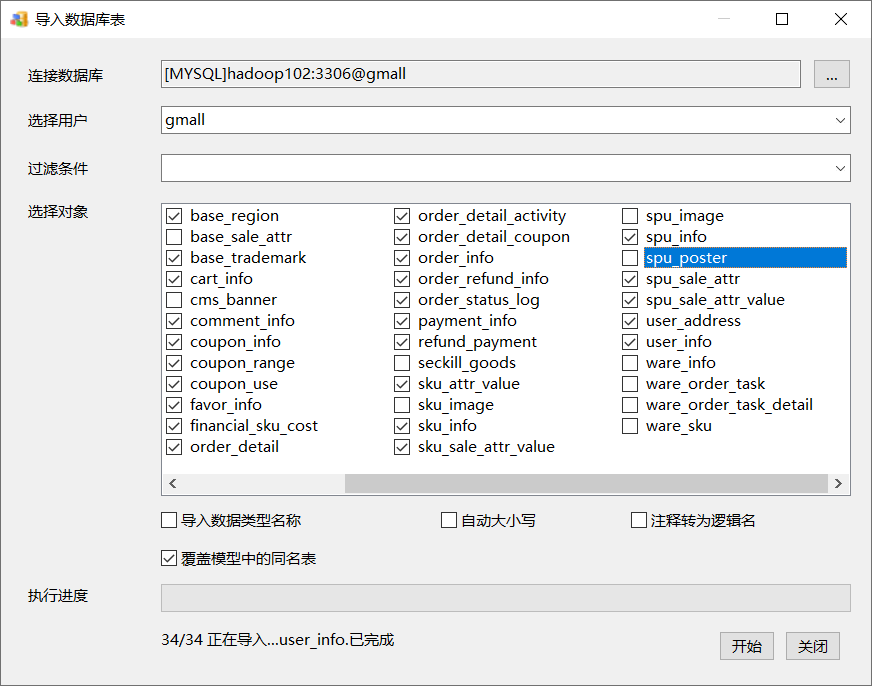
(5)选择导入的表
(7)建立表关系
第一步:点击选中主表(主键所在的表)
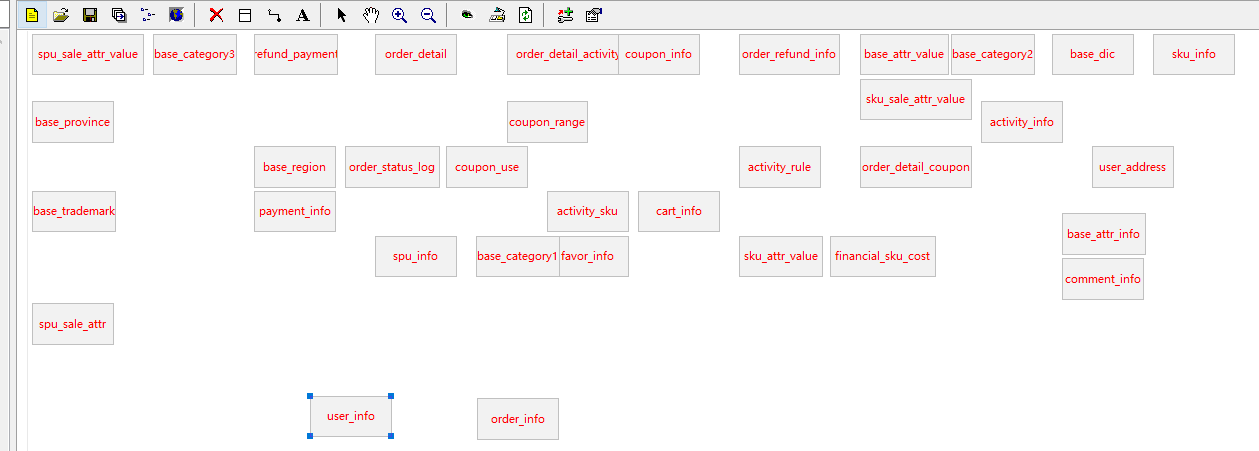
第二步:点击连接按钮

第三步:点击从表,配置连接条件
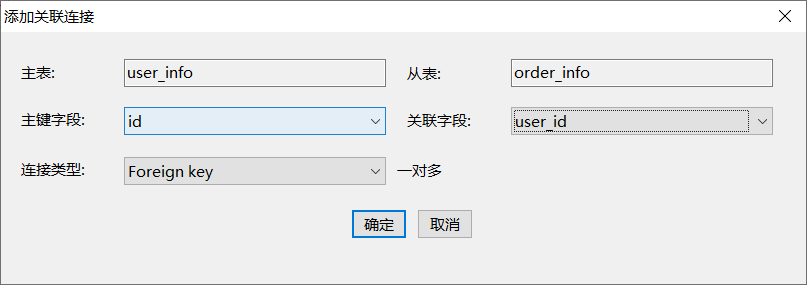
第四步:效果展示
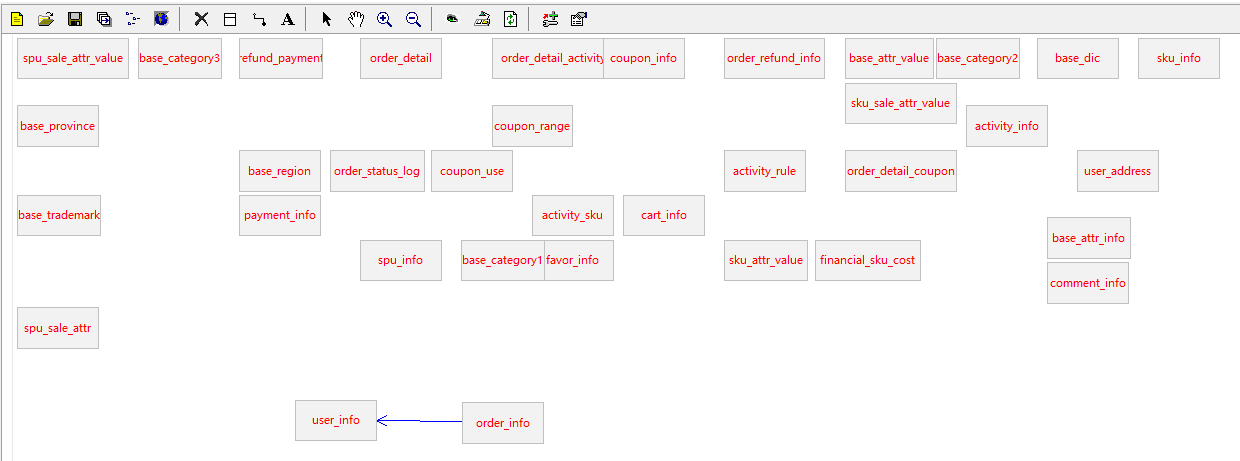
第五步:依次将如下表进行关联
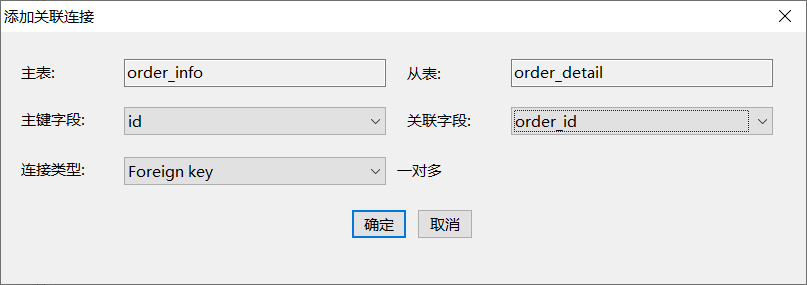
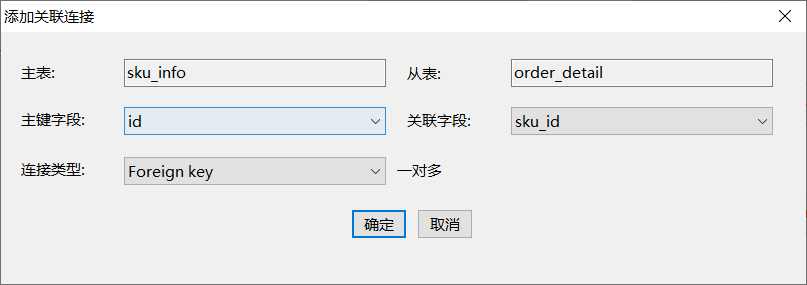
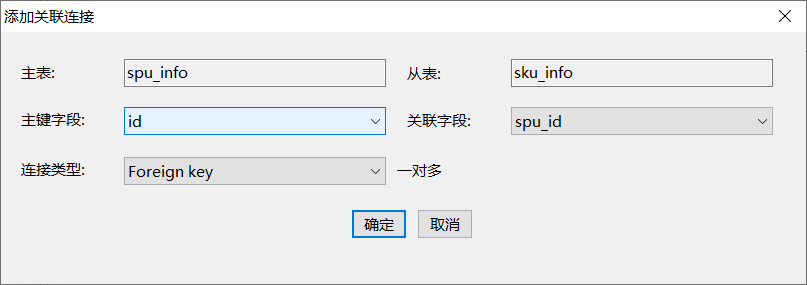
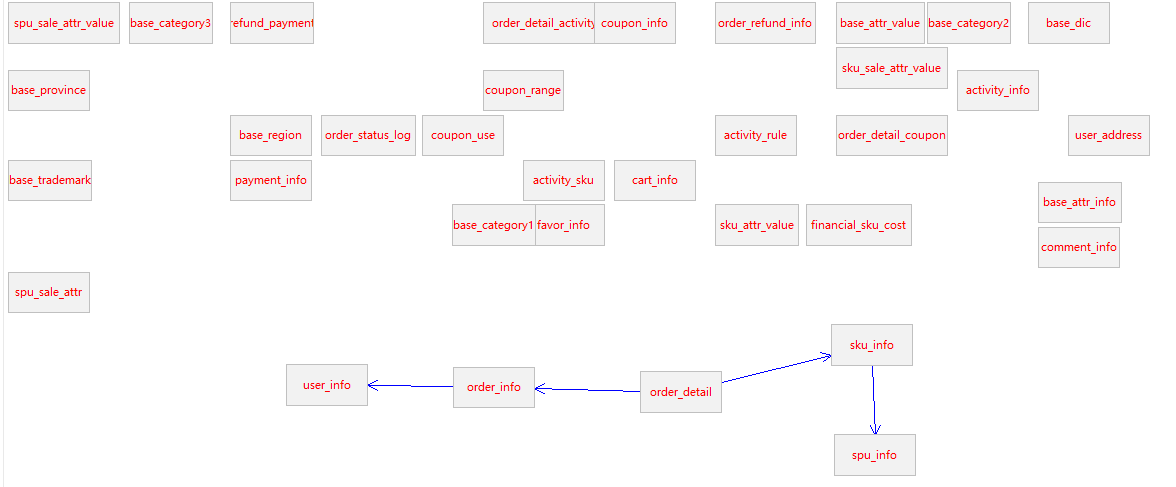
3)使用技巧
(1)缩略图

(2)热键
按住shift键,用鼠标点击表,进行多选,可实现批量移动
按住ctrl键,用鼠标圈选表,也可进行多选,实现批量移动
2.3 Sqoop安装
2.3.1 下载并解压
1)下载地址:http://mirrors.hust.edu.cn/apache/sqoop/1.4.6/
2)上传安装包sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz到hadoop102的/opt/software路径中
3)解压sqoop安装包到指定目录,如:
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/
4)进入/opt/module/目录,重命名sqoop-1.4.6.bin__hadoop-2.0.4-alpha
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop
2.3.2 修改配置文件
1) 进入到/opt/module/sqoop/conf目录,重命名配置文件
mv sqoop-env-template.sh sqoop-env.sh
2) 修改配置文件
vim sqoop-env.sh
#添加如下内容
export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3 export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3 export HIVE_HOME=/opt/module/hive export ZOOKEEPER_HOME=/opt/module/zookeeper export ZOOCFGDIR=/opt/module/zookeeper/conf
2.3.3 拷贝JDBC驱动
拷贝jdbc驱动到sqoop的lib目录下。
cp /opt/software/mysql-connector-java-5.1.27-bin.jar /opt/module/sqoop/lib/
2.3.4 验证Sqoop
我们可以通过某一个command来验证sqoop配置是否正确:
bin/sqoop help
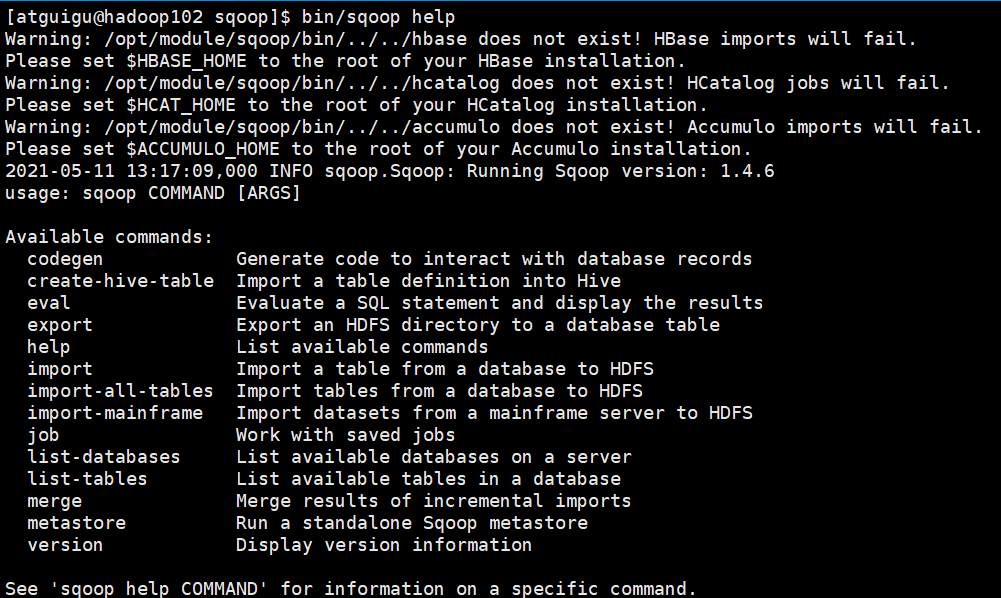
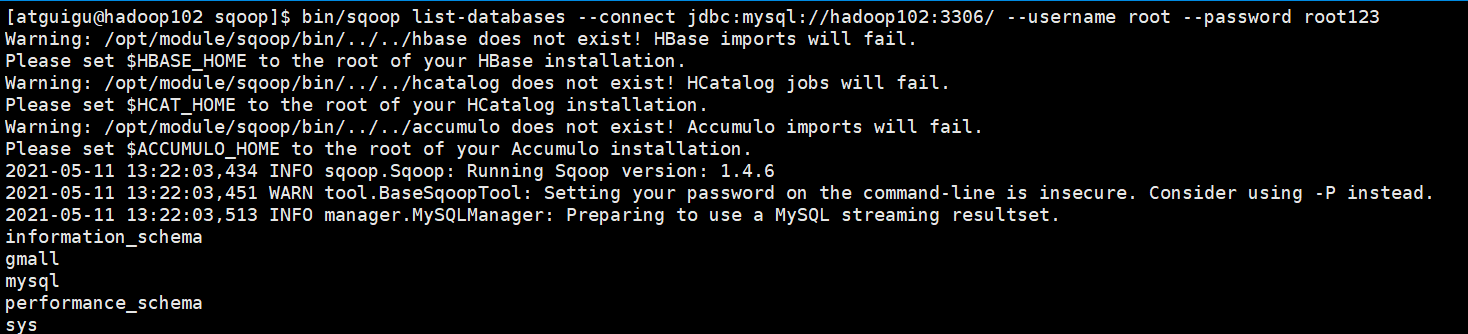
2.3.5 测试Sqoop是否能够成功连接数据库
bin/sqoop list-databases --connect jdbc:mysql://hadoop102:3306/ --username root --password root123
2.4 同步策略
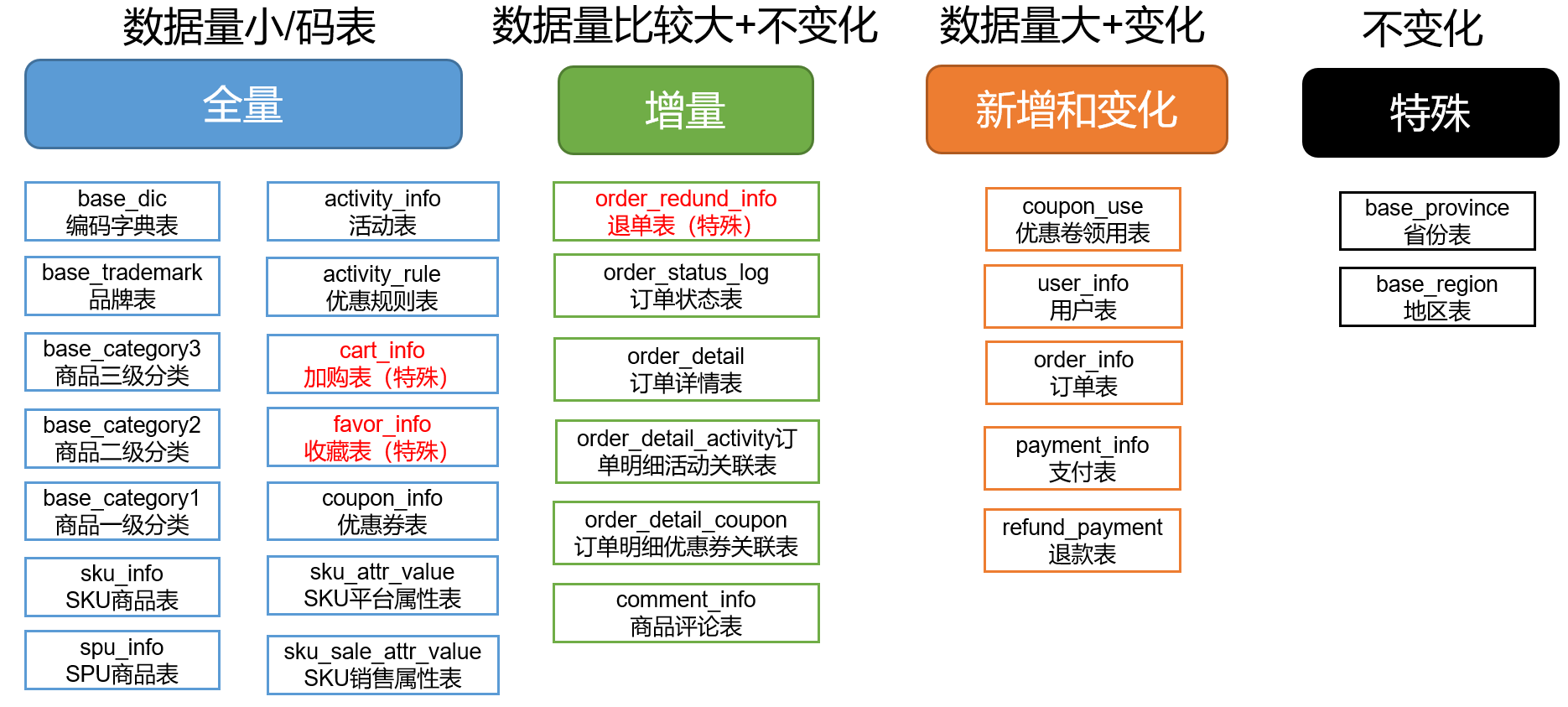
数据同步策略的类型包括:全量同步、增量同步、新增及变化同步、特殊情况
- 全量表:存储完整的数据。
- 增量表:存储新增加的数据。
- 新增及变化表:存储新增加的数据和变化的数据。
- 特殊表:只需要存储一次。
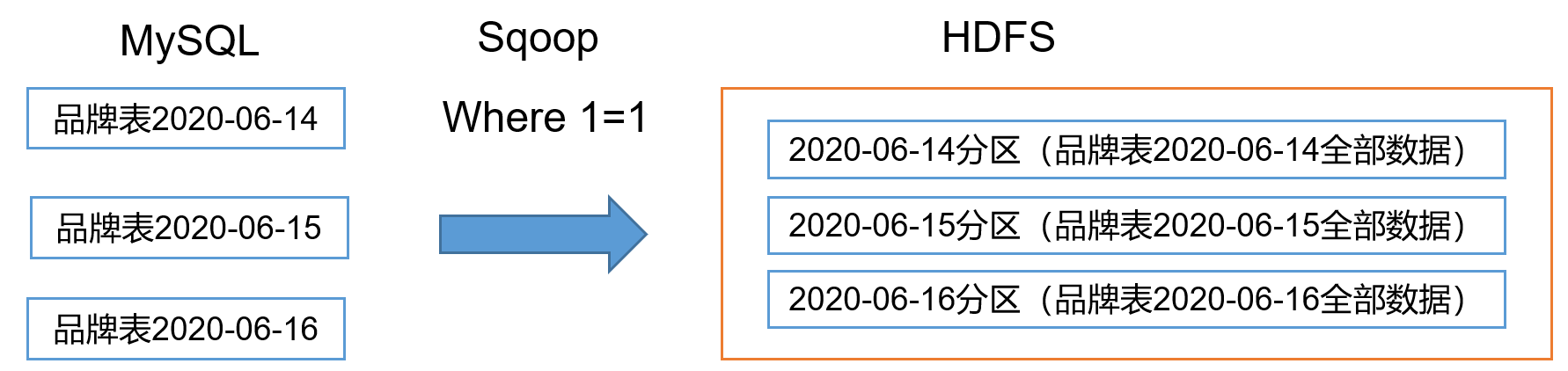
2.4.1 全量同步策略
每日全量,就是每天存储一份完整数据,作为一个分区。适用于表数据量不大,且每天既会有新数据插入,也会有旧数据修改的场景。例如:编码字典表、品牌表、商品三级分类、商品二级分类、商品一级分类、优惠规则表、活动表、活动参与商品表、加购表、商品收藏表、优惠券表、SKU商品表、SPU商品表
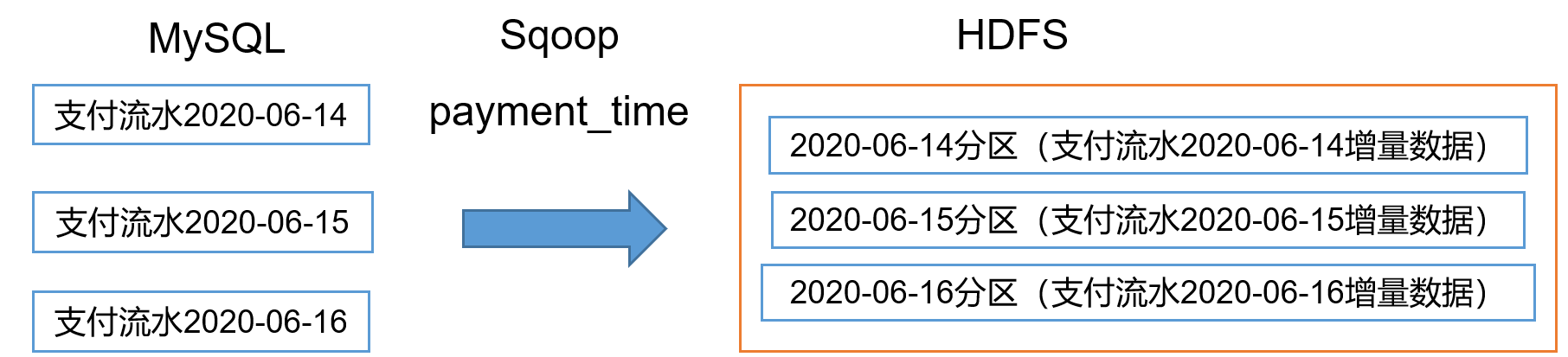
2.4.2 增量同步策略
每日增量,就是每天存储一份增量数据,作为一个分区。适用于表数据量大,且每天只会有新数据插入的场景。例如:退单表、订单状态表、支付流水表、订单详情表、活动与订单关联表、商品评论表。
2.4.3 新增及变化策略
每日新增及变化,就是存储创建时间和操作时间都是今天的数据。适用场景:表的数据量大,既会有新增,又会有变化。例如:用户表、订单表、优惠券领用表
2.4.4 特殊策略
某些特殊的表,可不必遵循上述同步策略。
例如没变化的客观世界的数据(比如性别,地区,民族,政治成分,鞋子尺码)可以只存一份。
2.5 业务数据导入HDFS
2.5.1 分析表同步策略
在生产环境,个别小公司,为了简单处理,所有表全量导入。
中大型公司,由于数据量比较大,还是严格按照同步策略导入数据。
2.5.2 业务数据首日同步脚本
1)脚本编写
(1)在/home/atguigu/bin目录下创建
vim /home/atguigu/bin/mysql_sqoop_hdfs_init.sh
#!/bin/bash #mysql_sqoop_hdfs_init.sh all/表名 时间 if [ $# -lt 1 ] then echo "参数个数不正确!!!" exit fi #若输入日期,则使用该日期,否则使用前一天的日期 [ "$2" ] && datestr=$2 || datestr=$(date -d '-1 day' +%Y%m%d) APP=gmall sqoop=/opt/module/sqoop/bin/sqoop import_date(){ $sqoop import \ --connect jdbc:mysql://hadoop102:3306/$APP \
--username root \ --password root123 \ --delete-target-dir \ --num-mappers 1 \ --split-by $2 \--query "$1" \ --target-dir hdfs://hadoop102:8020/$APP/$3/$datestr \
--compress \ --compression-codec lzop \ --null-string '\\N' \ --null-non-string '\\N' \ --fields-terminated-by , #给lzo压缩文件创建索引 hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer hdfs://hadoop102:8020/$APP/$3/$datestr } case $1 in #全表导入 "all") import_date "select * from sku_info where \$CONDITIONS" "id" "sku_info" import_date "select * from comment_info where \$CONDITIONS" "id" "comment_info" import_date "select * from user_info where \$CONDITIONS" "id" "user_info" import_date "select * from base_province where \$CONDITIONS" "id" "base_province" ;; #导入指定表数据 "sku_info") import_date "select * from sku_info where \$CONDITIONS" "id" "sku_info" ;; "comment_info") import_date "select * from comment_info where \$CONDITIONS" "id" "comment_info" ;; "user_info") import_date "select * from user_info where \$CONDITIONS" "id" "user_info" ;; "base_province") import_date "select * from base_province where \$CONDITIONS" "id" "base_province" ;; *) echo "第一个参数输入错误,必须是all或者是表名" ;; esac
说明1:
[ -n 变量值 ] 判断变量的值,是否为空
-- 变量的值,非空,返回true
-- 变量的值,为空,返回false
说明2:
查看date命令的使用
date --help
(2)增加脚本执行权限
chmod +x /home/atguigu/bin/mysql_sqoop_hdfs_init.sh
2)运行脚本
mysql_sqoop_hdfs_init.sh all
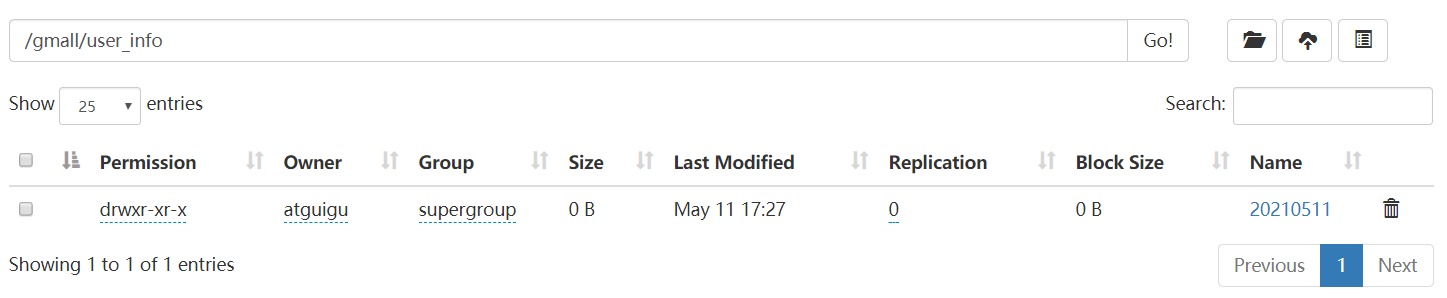
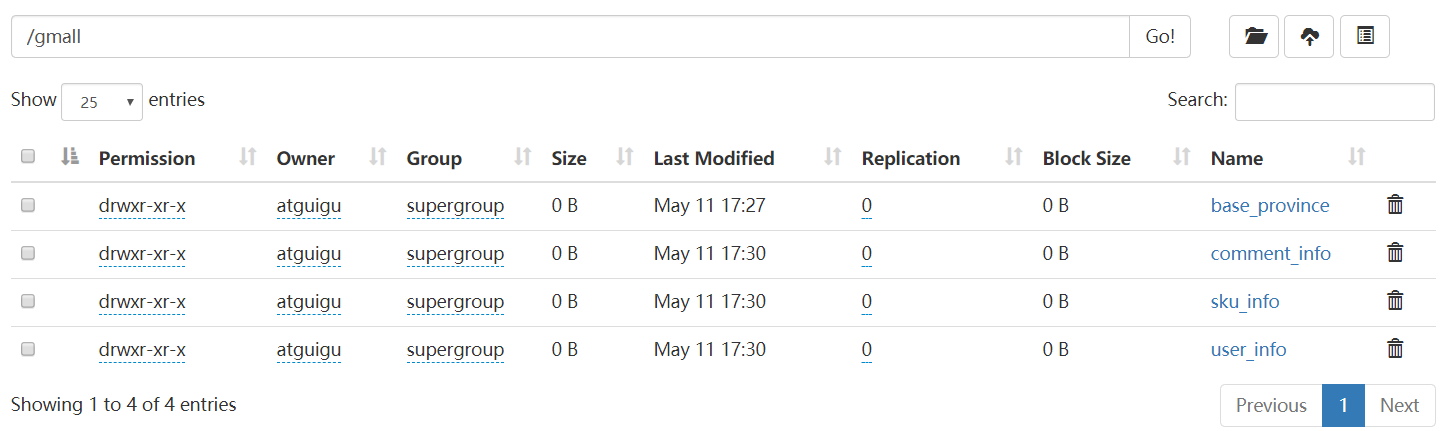
3)查看HDFS中的 /gmall/user_info/ 以及 /gmall/
4)sqoop常用参数说明
bin/sqoop import ------------------------------公有参数----------------------------------- --connect 指定mysql url连接 --username 指定mysql账号 --password 指定mysql的密码 -------------------------------导入HDFS的时候使用--------------------------- --append 追加数据到HDFS --as-textfile 将数据以文本格式保存在HDFS --as-parquetfile 将数据以parquet文件格式保存在HDFS--columns 指定从mysql导出哪些列的数据到HDFS --delete-target-dir 指定导入数据之前先删除目标路径 --num-mappers[-m] 指定maptask的个数,使maptask并行从mysql导数据 --split-by 指定数据切分的依据字段 --query[-e] 通过sql语句指定从mysql导哪些数据 [select 字段,... from 表名 where ...] --where 指定导入mysql指定条件的数据 --table 指定导mysql哪个表的数据 --columns 指定从mysql导出哪些列的数据到HDFS --target-dir 指定数据存储在HDFS的路径 --compress[-z] 指定数据导入HDFS的时候是否压缩 --compression-codec 指定数据保存在HDFS的时候压缩格式 --null-string 指定mysql字符串列值如果为null的时候导入HDFS以哪种格式保存 --null-non-string 指定mysql非字符串列值如果为null的时候导入HDFS以哪种格式保存 --fields-terminated-by 指定数据保存在HDFS的时候列之间的分隔符 --lines-terminated-by 指定数据保存在HDFS的时候行之间的分隔符 -------------------------------------增量导入------------------------------ --check-column 指定通过哪个字段判断数据为新增/修改数据 --incremental append[只导mysql每天新增的数据]/lastmodified[导入新增和修改的数据] --last-value 指定通过哪个值判断数据为新增/修改的数据 ------------------------------------数据导入HIVE-------------------------- --hive-import 指定数据导入HIVE中 --hive-table 指定数据导入hive哪个表 --create-hive-table 如果hive表不存在可以自动创建 --hive-overwrite 指定数据导入hive的时候直接覆盖hive数据 --hive-partition-key 指定数据导入hive分区表的时候分区字段名是什么 --hive-partition-value 指定数据导入hive分区表的时候分区字段的值是什么
5)示例:
bin/sqoop import --connect jdbc:mysql://hadoop102:3306/gmall \ --username root \ --password root123 \ --as-textfile \ --delete-target-dir \ --num-mappers 4 \ --split-by id \ --query "select * from user_info where id<=100 and \$CONDITIONS" \ --target-dir hdfs://hadoop102:8020/user_info \ --null-string '\\N' \ --null-non-string '\\N' \ --fields-terminated-by ,
2.5.3 业务数据每日同步脚本
1)脚本编写
(1)在/home/atguigu/bin目录下创建
vim /home/atguigu/bin/mysql_sqoop_hdfs_everyday.sh
#!/bin/bash #mysql_sqoop_hdfs_everyday.sh all/表名 时间 if [ $# -lt 1 ] then echo "参数个数错误!!!" exit fi [ "$2" ] && datestr=$2 || datestr=$(date -d '-1 day' +%Y%m%d) APP=gmall sqoop=/opt/module/sqoop/bin/sqoop import_date(){ $sqoop import \ --connect jdbc:mysql://hadoop102:3306/$APP \ --username root \ --password root123 \ --delete-target-dir \ --num-mappers 1 \ --split-by $2 \ --query "$1" \ --target-dir hdfs://hadoop102:8020/$APP/$3/$datestr \ --compress \ --compression-codec lzop \ --null-string '\\N' \ --null-non-string '\\N' \ --fields-terminated-by , #给lzo压缩文件创建索引 hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer hdfs://hadoop102:8020/$APP/$3/$datestr } #3、根据参数匹配导入数据 case $1 in #导入所有策略的表 "all") import_date "select * from sku_info where \$CONDITIONS" "id" "sku_info" import_date "select * from comment_info where DATE_FORMAT(create_time,'%Y%m%d')='$datestr' and \$CONDITIONS" "id" "comment_info" import_date "select * from user_info where (DATE_FORMAT(create_time,'%Y%m%d')='$datestr' or DATE_FORMAT(operate_time,'%Y%m%d')='$datestr')and \$CONDITIONS" "id" "user_info" ;; #导入指定表 #导入全量策略的表 "sku_info") import_date "select * from sku_info where \$CONDITIONS" "id" "sku_info" ;; #导入新增策略的表 "comment_info") import_date "select * from comment_info where DATE_FORMAT(create_time,'%Y%m%d')='$datestr' and \$CONDITIONS" "id" "comment_info" ;; #导入新增及修改策略 "user_info") import_date "select * from user_info where (DATE_FORMAT(create_time,'%Y%m%d')='$datestr' or DATE_FORMAT(operate_time,'%Y%m%d')='$datestr')and \$CONDITIONS" "id" "user_info" ;; *) echo "必须输入all或者是表名" ;; esac
(2)增加脚本执行权限
chmod +x /home/atguigu/bin/mysql_sqoop_hdfs_everyday.sh
(3)修改gmall数据库中user_info表下的第一条数据的时间字段为2021-05-10,保存

2)脚本使用
mysql_sqoop_hdfs_everyday.sh all
3)查看HDFS
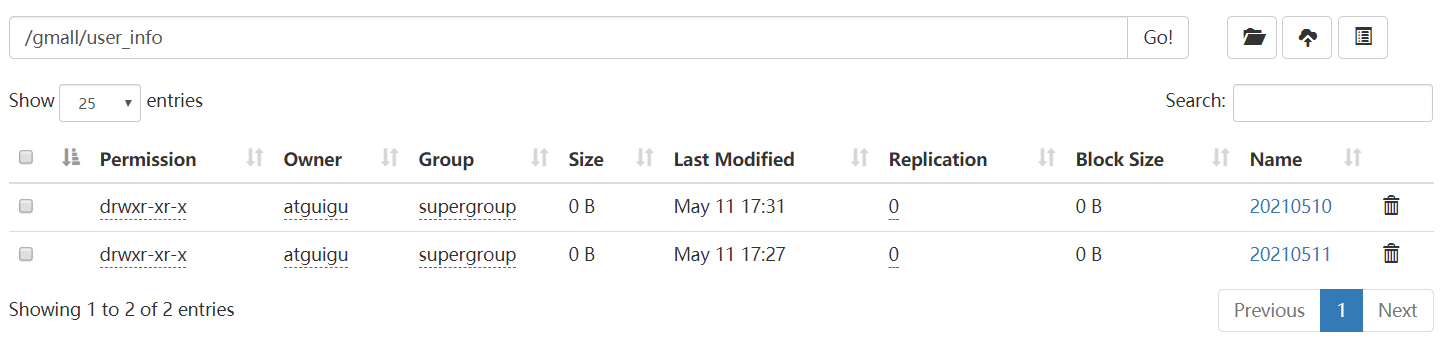
4)sqoop 导出常用参数:
bin/sqoop export ------------------------------公有参数----------------------------------- --connect 指定mysql url连接 --username 指定mysql账号 --password 指定mysql的密码 --columns 指定数据导入到mysql哪些列中 --export-dir 指定HDFS数据路径 --num-mappers[-m] 指定maptask个数 --table 指定数据导入到mysql哪个表 --update-key 指定HDFS导入数据到mysql的时候,通过哪个字段判断HDFS与mysql的数据是同一条数 --update-mode updateonly[如果update-key的数据在mysql中已经存在则更新,不存在则忽略]/allowinsert[如果update-key的数据在mysql中已经存在则更新,不存在则插入] --input-null-string 指定HDFS字符串数据如果为null,保存在mysql的时候以哪种形式保存 --input-null-non-string 指定HDFS非字符串数据如果为null,保存在mysql的时候以哪种形式保存 --input-fields-terminated-by 指定HDFS中数据字段之间的分隔符 --input-lines-terminated-by 指定HDFS中数据行之间的分隔符
5)示例:
bin/sqoop export \ --connect jdbc:mysql://hadoop102:3306/test \ --username root \ --password root123 \ --columns id,name,age \ --export-dir hdfs://hadoop102:8020/input \ --num-mappers 1 \ --table user_info \ --update-key id \ --update-mode allowinsert \ --input-null-string "null" \ --input-null-non-string "null" \ --input-fields-terminated-by ,
2.5.3 项目经验
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用--input-null-string和--input-null-non-string两个参数。导入数据时采用--null-string和--null-non-string。
第3章 数据环境准备
3.1 Hive安装部署
1)把apache-hive-3.1.2-bin.tar.gz上传到linux的/opt/software目录下
2)解压apache-hive-3.1.2-bin.tar.gz到/opt/module/目录下面
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
3)修改apache-hive-3.1.2-bin.tar.gz的名称为hive
mv /opt/module/apache-hive-3.1.2-bin /opt/module/hive
4)修改/etc/profile.d/my_env.sh,添加环境变量
sudo vim /etc/profile.d/my_env.sh
#HIVE_HOME export HIVE_HOME=/opt/module/hive export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile.d/my_env.sh
5)解决日志Jar包冲突,进入/opt/module/hive/lib目录
mv /opt/module/hive/lib/log4j-slf4j-impl-2.10.0.jar /opt/module/hive/lib/log4j-slf4j-impl-2.10.0.jar.bak
3.2 Hive元数据配置到MySQL
3.2.1 拷贝驱动
将MySQL的JDBC驱动拷贝到Hive的lib目录下
cp /opt/software/mysql-connector-java-5.1.27-bin.jar /opt/module/hive/lib/
3.2.2 配置Metastore到MySQL
在$HIVE_HOME/conf目录下新建hive-site.xml文件
vim /opt/module/hive/conf/hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root123</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>hadoop102</value> </property> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> </configuration>
3.3 启动Hive
3.3.1 初始化元数据库
1)登陆MySQL
mysql -uroot -proot123
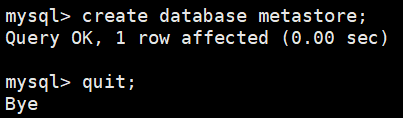
2)新建Hive元数据库
create database metastore;
create database metastore;
3)初始化Hive元数据库
schematool -initSchema -dbType mysql -verbose
3.3.2 启动hive客户端
1)启动Hive客户端
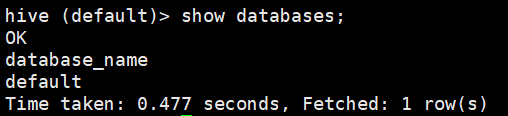
hive
2)查看一下数据库
show databases;
3)在$HIVE_HOME/下创建logs文件夹
mkdir -p /opt/module/hive/logs
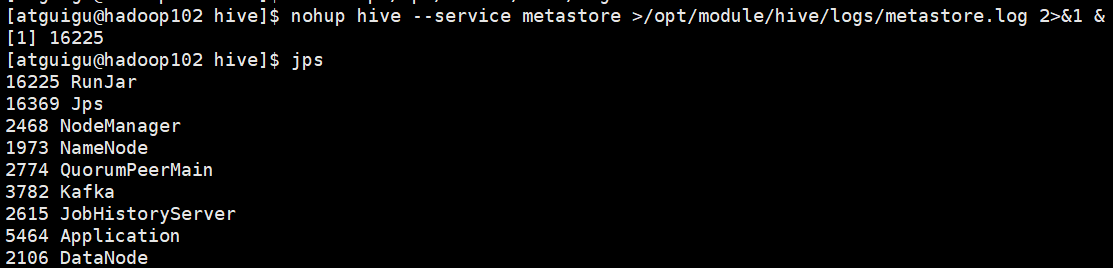
4)启动Metastroe服务,并使用jps查看,发现有RunJar进程
nohup hive --service metastore >/opt/module/hive/logs/metastore.log 2>&1 &
5)启动HiveServer2服务,并使用jps查看,发现有RunJar进程
nohup hive --service hiveserver2 >/opt/module/hive/logs/hiveServer2.log 2>&1 &
6)编写hive服务脚本
vim /home/atguigu/bin/hiveservices.sh
#!/bin/bash HIVE_LOG_DIR=$HIVE_HOME/logs mkdir -p $HIVE_LOG_DIR #检查进程是否运行正常,参数1为进程名,参数2为进程端口 function check_process() { pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}') ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1) echo $pid [[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1 } function hive_start() { metapid=$(check_process HiveMetastore 9083) cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &" cmd=$cmd" sleep 4; hdfs dfsadmin -safemode wait >/dev/null 2>&1" [ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动" server2pid=$(check_process HiveServer2 10000) cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &" [ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动" } function hive_stop() { metapid=$(check_process HiveMetastore 9083) [ "$metapid" ] && kill $metapid || echo "Metastore服务未启动" server2pid=$(check_process HiveServer2 10000) [ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动" } case $1 in "start") hive_start ;; "stop") hive_stop ;; "restart") hive_stop sleep 2 hive_start ;; "status") check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常" check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常" ;; *) echo Invalid Args! echo 'Usage: '$(basename $0)' start|stop|restart|status' ;; esac
7)赋予可执行权限
chmod +x /home/atguigu/bin/hiveservices.sh
8)使用beeline连接hive
beeline -u jdbc:hive2://hadoop102:10000 -n atguigu
9)退出
!quit
10)创建school表
create table school( region_name string, school_name string, class_name string, stu_name string ) row format delimited fields terminated by ',';
11)添加数据至HDFS中:创建school.txt,并上传至/user/hive/warehouse/school 目录下
宝安区,宝安中学,法师班,安琪拉
宝安区,宝安中学,法师班,王昭君
宝安区,宝安中学,法师班,诸葛亮
宝安区,宝安中学,法师班,甄姬
宝安区,宝安中学,法师班,貂蝉
宝安区,宝安中学,法师班,司马懿
宝安区,小学,战士班,吕布
宝安区,小学,战士班,程咬金
宝安区,小学,战士班,达摩
宝安区,小学,战士班,刘备
宝安区,小学,战士班,赵云
龙华区,龙华幼儿园,辅助班,瑶
龙华区,龙华幼儿园,辅助班,牛魔
龙华区,龙华幼儿园,辅助班,张飞
龙华区,龙华幼儿园,辅助班,孙斌
福田区,福田大学,射手班,后裔
福田区,福田大学,射手班,鲁班
福田区,福田大学,射手班,虞姬
福田区,福田大学,射手班,狄仁杰
福田区,福田大学,射手班,孙尚香
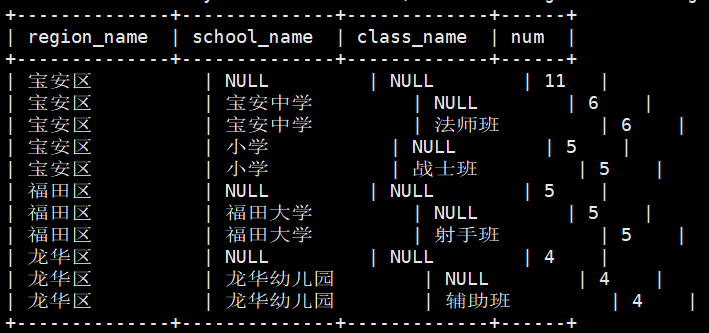
12)需求:统计每个区域的学生人数,每个区域每个学校的学生人数,每个区域每个学校每个班级的学生人数
(1)传统写法,运行之后出现5个Job
select region_name,null school_name,null class_name,count(1) num from school group by region_name union all select region_name,school_name,null class_name,count(1) num from school group by region_name,school_name union all select region_name,school_name,class_name,count(1) num from school group by region_name,school_name,class_name;

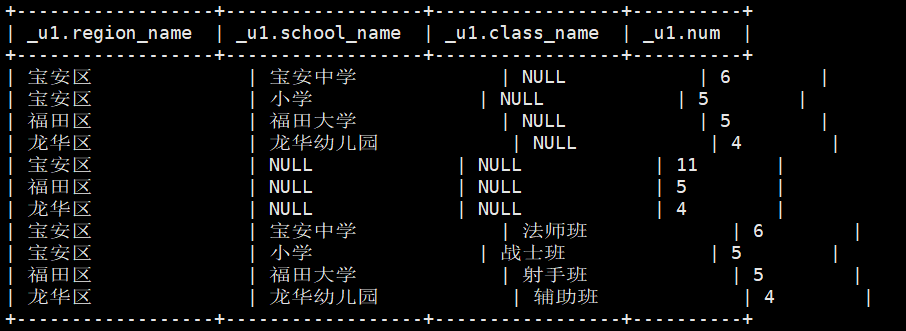
(2)多维聚合(grouping sets),运行之后只有一个Job
select region_name,school_name,class_name,count(1) num from school group by region_name,school_name,class_name grouping sets ( (region_name),(region_name,school_name),(region_name,school_name,class_name) );