

集合是java中提供的一种容器,可以用来存储多个数据。
集合和数组既然都是容器,它们有啥区别呢?
-
数组的长度是固定的。集合的长度是可变的。
-
数组中可以存储基本数据类型值,也可以存储对象,而集合中只能存储对象
集合主要分为两大系列:Collection和Map,Collection 表示一组对象,Map表示一组映射关系或键值对。
1 Collection
Collection 层次结构中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的。JDK 不提供此接口的任何直接实现:它提供更具体的子接口(如 Set 和 List、Queue)实现。此接口通常用来传递 collection,并在需要最大普遍性的地方操作这些 collection。
Collection<E>是所有单列集合的父接口,因此在Collection中定义了单列集合(List和Set)通用的一些方法,这些方法可用于操作所有的单列集合。方法如下:
1、添加元素
(1)add(E obj):添加元素对象到当前集合中
(2)addAll(Collection<? extends E> other):添加other集合中的所有元素对象到当前集合中,即this = this ∪ other
2、删除元素
(1) boolean remove(Object obj) :从当前集合中删除第一个找到的与obj对象equals返回true的元素。
(2)boolean removeAll(Collection<?> coll):从当前集合中删除所有与coll集合中相同的元素。即this = this - this ∩ coll
3、判断
(1)boolean isEmpty():判断当前集合是否为空集合。
(2)boolean contains(Object obj):判断当前集合中是否存在一个与obj对象equals返回true的元素。
(3)boolean containsAll(Collection<?> c):判断c集合中的元素是否在当前集合中都存在。即c集合是否是当前集合的“子集”。
4、获取元素个数
(1)int size():获取当前集合中实际存储的元素个数
5、交集
(1)boolean retainAll(Collection<?> coll):当前集合仅保留与c集合中的元素相同的元素,即当前集合中仅保留两个集合的交集,即this = this ∩ coll;
6、转为数组
(1)Object[] toArray():返回包含当前集合中所有元素的数组
方法演示:
import java.util.ArrayList;
import java.util.Collection;
public class Demo1Collection {
public static void main(String[] args) {
// 创建集合对象
// 使用多态形式
Collection<String> coll = new ArrayList<String>();
// 使用方法
// 添加功能 boolean add(String s)
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
System.out.println(coll);
// boolean contains(E e) 判断o是否在集合中存在
System.out.println("判断 扫地僧 是否在集合中"+coll.contains("扫地僧"));
//boolean remove(E e) 删除在集合中的o元素
System.out.println("删除石破天:"+coll.remove("石破天"));
System.out.println("操作之后集合中元素:"+coll);
// size() 集合中有几个元素
System.out.println("集合中有"+coll.size()+"个元素");
// Object[] toArray()转换成一个Object数组
Object[] objects = coll.toArray();
// 遍历数组
for (int i = 0; i < objects.length; i++) {
System.out.println(objects[i]);
}
// void clear() 清空集合
coll.clear();
System.out.println("集合中内容为:"+coll);
// boolean isEmpty() 判断是否为空
System.out.println(coll.isEmpty());
}
}
注意:coll.addAll(other);与coll.add(other);

2 Iterator迭代器
2.1 Iterator接口
在程序开发中,经常需要遍历集合中的所有元素。针对这种需求,JDK专门提供了一个接口java.util.Iterator。Iterator接口也是Java集合中的一员,但它与Collection、Map接口有所不同,Collection接口与Map接口主要用于存储元素,而Iterator主要用于迭代访问(即遍历)Collection中的元素,因此Iterator对象也被称为迭代器。
想要遍历Collection集合,那么就要获取该集合迭代器完成迭代操作,下面介绍一下获取迭代器的方法:
-
public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素的。
下面介绍一下迭代的概念:
-
迭代:即Collection集合元素的通用获取方式。在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续在判断,如果还有就再取出出来。一直把集合中的所有元素全部取出。这种取出方式专业术语称为迭代。
Iterator接口的常用方法如下:
-
public E next():返回迭代的下一个元素。 -
public boolean hasNext():如果仍有元素可以迭代,则返回 true。
接下来我们通过案例学习如何使用Iterator迭代集合中元素:
public class IteratorDemo {
public static void main(String[] args) {
// 使用多态方式 创建对象
Collection<String> coll = new ArrayList<String>();
// 添加元素到集合
coll.add("串串星人");
coll.add("吐槽星人");
coll.add("汪星人");
//遍历
//使用迭代器 遍历 每个集合对象都有自己的迭代器
Iterator<String> it = coll.iterator();
// 泛型指的是 迭代出 元素的数据类型
while(it.hasNext()){ //判断是否有迭代元素
String s = it.next();//获取迭代出的元素
System.out.println(s);
}
}
}
tips::在进行集合元素取出时,如果集合中已经没有元素了,还继续使用迭代器的next方法,将会发生java.util.NoSuchElementException没有集合元素的错误。
2.2 迭代器的实现原理
我们在之前案例已经完成了Iterator遍历集合的整个过程。当遍历集合时,首先通过调用集合的iterator()方法获得迭代器对象,然后使用hashNext()方法判断集合中是否存在下一个元素,如果存在,则调用next()方法将元素取出,否则说明已到达了集合末尾,停止遍历元素。
Iterator迭代器对象在遍历集合时,内部采用指针的方式来跟踪集合中的元素,为了让初学者能更好地理解迭代器的工作原理,接下来通过一个图例来演示Iterator对象迭代元素的过程:
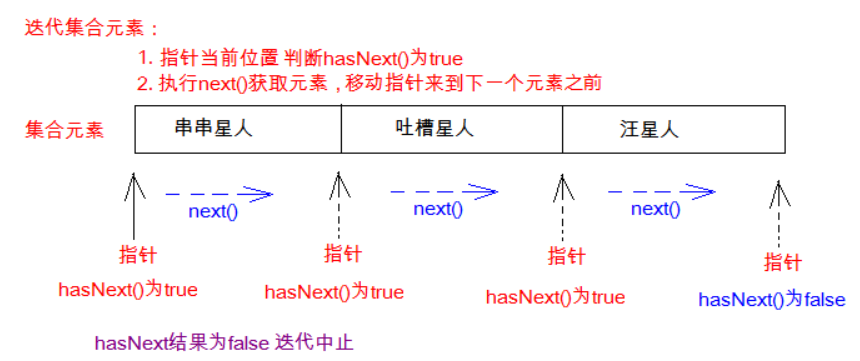
在调用Iterator的next方法之前,迭代器的索引位于第一个元素之前,指向第一个元素,当第一次调用迭代器的next方法时,返回第一个元素,然后迭代器的索引会向后移动一位,指向第二个元素,当再次调用next方法时,返回第二个元素,然后迭代器的索引会再向后移动一位,指向第三个元素,依此类推,直到hasNext方法返回false,表示到达了集合的末尾,终止对元素的遍历。
2.3 使用Iterator迭代器删除元素
java.util.Iterator迭代器中有一个方法:
void remove() ;
那么,既然Collection已经有remove(xx)方法了,为什么Iterator迭代器还要提供删除方法呢?
因为Collection的remove方法,无法根据条件删除。
例如:要删除以下集合元素中的偶数
注意:不要在使用Iterator迭代器进行迭代时,调用Collection的remove(xx)方法,否则会报异常java.util.ConcurrentModificationException,或出现不确定行为。
2.4 增强for
增强for循环(也称for each循环)是JDK1.5以后出来的一个高级for循环,专门用来遍历数组和集合的。
格式:
for(元素的数据类型 变量 : Collection集合or数组){
//写操作代码
}
练习1:遍历数组
通常只进行遍历元素,不要在遍历的过程中对数组元素进行修改。
public class NBForDemo1 {
public static void main(String[] args) {
int[] arr = {3,5,6,87};
//使用增强for遍历数组
for(int a : arr){//a代表数组中的每个元素
System.out.println(a);
}
}
}
练习2:遍历集合
通常只进行遍历元素,不要在遍历的过程中对集合元素进行增加、删除、替换操作。
public class NBFor {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<String>();
coll.add("小河神");
coll.add("老河神");
coll.add("神婆");
//使用增强for遍历
for(String s :coll){//接收变量s代表 代表被遍历到的集合元素
System.out.println(s);
}
}
}
2.5 java.lang.Iterable接口
java.lang.Iterable接口,实现这个接口允许对象成为 "foreach" 语句的目标。
Java 5时Collection接口继承了java.lang.Iterable接口,因此Collection系列的集合就可以直接使用foreach循环遍历。
java.lang.Iterable接口的抽象方法:
-
public Iterator iterator(): 获取对应的迭代器,用来遍历数组或集合中的元素的。
自定义某容器类型,实现java.lang.Iterable接口,发现就可以使用foreach进行迭代。
import java.util.Iterator;
public class TestMyArrayList {
public static void main(String[] args) {
MyArrayList<String> my = new MyArrayList<>();
for(String obj : my) {
System.out.println(obj);
}
}
}
class MyArrayList<T> implements Iterable<T>{
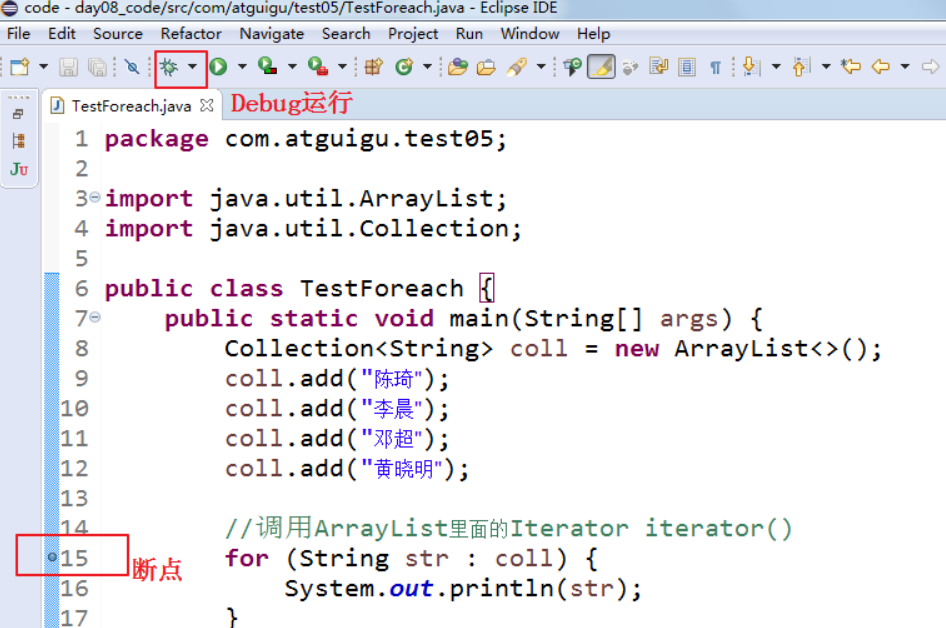
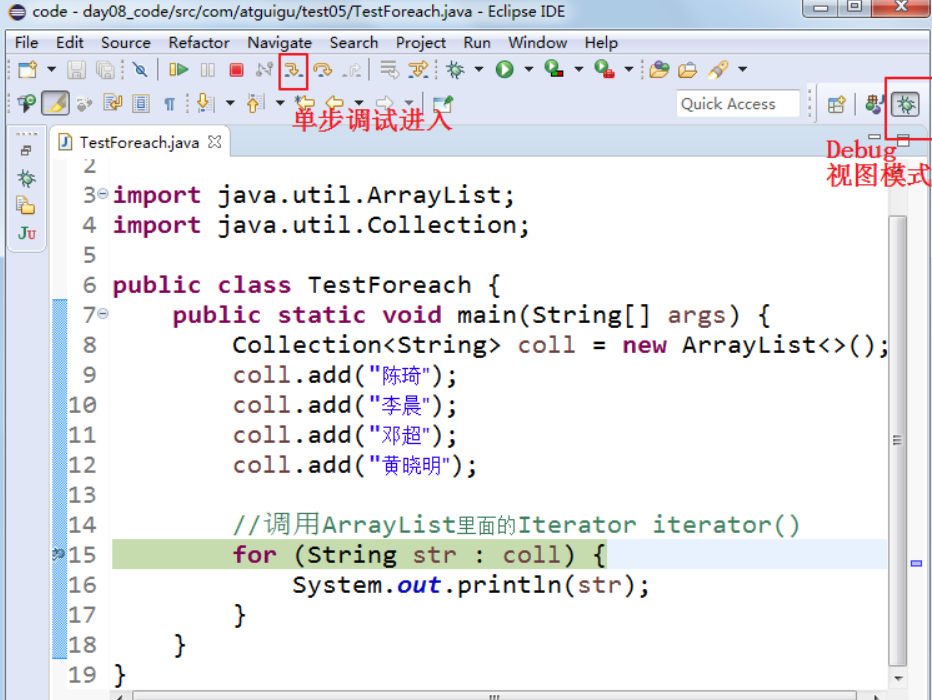
foreach本质上就是使用Iterator迭代器进行遍历的。
我们在如下代码的for(Student student : coll)这行打断点,然后使用单步调试进入源码,发现foreach本质上是调用集合的iterator()方法,返回一个迭代器进行迭代的
import java.util.ArrayList;
import java.util.Collection;
public class TestForeach {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<>();
coll.add("陈琦");
coll.add("李晨");
coll.add("邓超");
coll.add("黄晓明");
//调用ArrayList里面的Iterator iterator()
for (String str : coll) {
System.out.println(str);
}
}
}
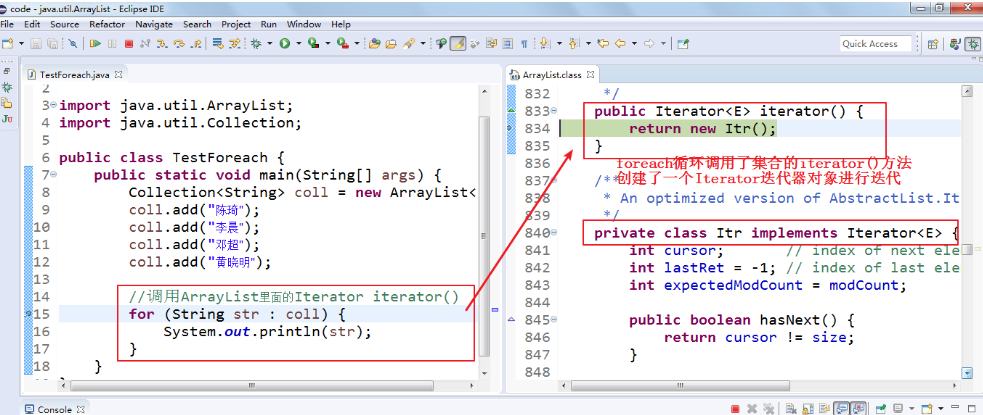
所以也不要在foreach遍历的过程使用Collection的remove()方法。否则,要么报异常java.util.ConcurrentModificationException,要么行为不确定。
2.6 Java中modCount的用法,快速失败(fail-fast)机制
当使用foreach或Iterator迭代器遍历集合时,同时调用迭代器自身以外的方法修改了集合的结构,例如调用集合的add和remove方法时,就会报ConcurrentModificationException。
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class TestForeach {
public static void main(String[] args) {
Collection<String> list = new ArrayList<>();
list.add("hello");
list.add("java");
list.add("atguigu");
list.add("world");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
list.remove(iterator.next());
}
}
}
如果在Iterator、ListIterator迭代器创建后的任意时间从结构上修改了集合(通过迭代器自身的 remove 或 add 方法之外的任何其他方式),则迭代器将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就完全失败,而不是冒着在将来不确定的时间任意发生不确定行为的风险。
这样设计是因为,迭代器代表集合中某个元素的位置,内部会存储某些能够代表该位置的信息。当集合发生改变时,该信息的含义可能会发生变化,这时操作迭代器就可能会造成不可预料的事情。因此,果断抛异常阻止,是最好的方法。这就是Iterator迭代器的快速失败(fail-fast)机制。
注意,迭代器的快速失败行为不能得到保证,一般来说,存在不同步的并发修改时,不可能作出任何坚决的保证。快速失败迭代器尽最大努力抛出 ConcurrentModificationException。因此,编写依赖于此异常的程序的方式是错误的,正确做法是:迭代器的快速失败行为应该仅用于检测 bug。例如:
那么如何实现快速失败(fail-fast)机制的呢?
-
在ArrayList等集合类中都有一个modCount变量。它用来记录集合的结构被修改的次数。
-
当我们给集合添加和删除操作时,会导致modCount++。
-
然后当我们用Iterator迭代器遍历集合时,创建集合迭代器的对象时,用一个变量记录当前集合的modCount。例如:
int expectedModCount = modCount;,并且在迭代器每次next()迭代元素时,都要检查expectedModCount != modCount,如果不相等了,那么说明你调用了Iterator迭代器以外的Collection的add,remove等方法,修改了集合的结构,使得modCount++,值变了,就会抛出ConcurrentModificationException。
下面以AbstractList<E>和ArrayList.Itr迭代器为例进行源码分析:
AbstractList<E>类中声明了modCount变量:
/**
* The number of times this list has been <i>structurally modified</i>.
* Structural modifications are those that change the size of the
* list, or otherwise perturb it in such a fashion that iterations in
* progress may yield incorrect results.
*
* <p>This field is used by the iterator and list iterator implementation
* returned by the {@code iterator} and {@code listIterator} methods.
* If the value of this field changes unexpectedly, the iterator (or list
* iterator) will throw a {@code ConcurrentModificationException} in
* response to the {@code next}, {@code remove}, {@code previous},
* {@code set} or {@code add} operations. This provides
* <i>fail-fast</i> behavior, rather than non-deterministic behavior in
* the face of concurrent modification during iteration.
*
* <p><b>Use of this field by subclasses is optional.</b> If a subclass
* wishes to provide fail-fast iterators (and list iterators), then it
* merely has to increment this field in its {@code add(int, E)} and
* {@code remove(int)} methods (and any other methods that it overrides
* that result in structural modifications to the list). A single call to
* {@code add(int, E)} or {@code remove(int)} must add no more than
* one to this field, or the iterators (and list iterators) will throw
* bogus {@code ConcurrentModificationExceptions}. If an implementation
* does not wish to provide fail-fast iterators, this field may be
* ignored.
*/
protected transient int modCount = 0;
modCount是这个list被结构性修改的次数。结构性修改是指:改变list的size大小,或者,以其他方式改变他导致正在进行迭代时出现错误的结果。
这个字段用于迭代器和列表迭代器的实现类中,由迭代器和列表迭代器方法返回。如果这个值被意外改变,这个迭代器将会抛出 ConcurrentModificationException的异常来响应:next,remove,previous,set,add 这些操作。在迭代过程中,他提供了fail-fast行为而不是不确定行为来处理并发修改。
子类使用这个字段是可选的,如果子类希望提供fail-fast迭代器,它仅仅需要在add(int, E),remove(int)方法(或者它重写的其他任何会结构性修改这个列表的方法)中添加这个字段。调用一次add(int,E)或者remove(int)方法时必须且仅仅给这个字段加1,否则迭代器会抛出伪装的ConcurrentModificationExceptions错误。如果一个实现类不希望提供fail-fast迭代器,则可以忽略这个字段。
Arraylist的Itr迭代器:
private class Itr implements Iterator<E> {
int cursor;
int lastRet = -1;
int expectedModCount = modCount;//在创建迭代器时,expectedModCount初始化为当前集合的modCount的值
public boolean hasNext() {
return cursor != size;
}
我们掌握了Collection接口的使用后,再来看看Collection接口中的子接口,他们都具备那些特性呢?
3.1 List接口介绍
java.util.List接口继承自Collection接口,是单列集合的一个重要分支,习惯性地会将实现了List接口的对象称为List集合。
List接口特点:
-
List集合所有的元素是以一种线性方式进行存储的,例如,存元素的顺序是11、22、33。那么集合中,元素的存储就是按照11、22、33的顺序完成的)
-
它是一个元素存取有序的集合。即元素的存入顺序和取出顺序有保证。
-
它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
-
集合中可以有重复的元素,通过元素的equals方法,来比较是否为重复的元素。
List集合类中元素有序、且可重复。这就像银行门口客服,给每一个来办理业务的客户分配序号:第一个来的是“张三”,客服给他分配的是0;第二个来的是“李四”,客服给他分配的1;以此类推,最后一个序号应该是“总人数-1”。

注意:
List集合关心元素是否有序,而不关心是否重复,请大家记住这个原则。例如“张三”可以领取两个号。
3.2 List接口中常用方法
List作为Collection集合的子接口,不但继承了Collection接口中的全部方法,而且还增加了一些根据元素索引来操作集合的特有方法,如下:
List除了从Collection集合继承的方法外,List 集合里添加了一些根据索引来操作集合元素的方法。
1、添加元素
-
void add(int index, E ele)
-
boolean addAll(int index, Collection<? extends E> eles)
2、获取元素
-
E get(int index)
-
List subList(int fromIndex, int toIndex)
3、获取元素索引
-
int indexOf(Object obj)
-
int lastIndexOf(Object obj)
4、删除和替换元素
-
E remove(int index)
-
E set(int index, E ele)
List集合特有的方法都是跟索引相关:
public class ListDemo {
public static void main(String[] args) {
// 创建List集合对象
List<String> list = new ArrayList<String>();
// 往 尾部添加 指定元素
list.add("图图");
list.add("小美");
list.add("不高兴");
System.out.println(list);
// add(int index,String s) 往指定位置添加
list.add(1,"没头脑");
System.out.println(list);
// String remove(int index) 删除指定位置元素 返回被删除元素
// 删除索引位置为2的元素
System.out.println("删除索引位置为2的元素");
System.out.println(list.remove(2));
System.out.println(list);
// String set(int index,String s)
// 在指定位置 进行 元素替代(改)
// 修改指定位置元素
list.set(0, "三毛");
System.out.println(list);
// String get(int index) 获取指定位置元素
// 跟size() 方法一起用 来 遍历的
for(int i = 0;i<list.size();i++){
System.out.println(list.get(i));
}
//还可以使用增强for
for (String string : list) {
System.out.println(string);
}
}
}
在JavaSE中List名称的类型有两个,一个是java.util.List集合接口,一个是java.awt.List图形界面的组件,别导错包了。
3.3 List接口的实现类们
List接口的实现类有很多,常见的有:
ArrayList:动态数组
Vector:动态数组
LinkedList:双向链表
Stack:栈
它们的区别我们在数据结构部分再详细讲解
3.4 ListIterator
List 集合额外提供了一个 listIterator() 方法,该方法返回一个 ListIterator 对象, ListIterator 接口继承了 Iterator 接口,提供了专门操作 List 的方法:
-
void add():通过迭代器添加元素到对应集合
-
void set(Object obj):通过迭代器替换正迭代的元素
-
void remove():通过迭代器删除刚迭代的元素
-
boolean hasPrevious():如果以逆向遍历列表,往前是否还有元素。
-
Object previous():返回列表中的前一个元素。
-
int previousIndex():返回列表中的前一个元素的索引
-
boolean hasNext()
-
Object next()
-
int nextIndex()
public static void main(String[] args) {
List<Student> c = new ArrayList<>();
c.add(new Student(1,"张三"));
c.add(new Student(2,"李四"));
c.add(new Student(3,"王五"));
c.add(new Student(4,"赵六"));
c.add(new Student(5,"钱七"));
//从指定位置往前遍历
ListIterator<Student> listIterator = c.listIterator(c.size());
while(listIterator.hasPrevious()){
Student previous = listIterator.previous();
System.out.println(previous);
}
}
4 Set集合
Set接口是Collection的子接口,set接口没有提供额外的方法。但是比Collection接口更加严格了。
Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个 Set 集合中,则添加操作失败。
Set集合支持的遍历方式和Collection集合一样:foreach和Iterator。
Set的常用实现类有:HashSet、TreeSet、LinkedHashSet。
4.1 HashSet
HashSet 是 Set 接口的典型实现,大多数时候使用 Set 集合时都使用这个实现类。
java.util.HashSet底层的实现其实是一个java.util.HashMap支持,然后HashMap的底层物理实现是一个Hash表。(什么是哈希表,下一节在HashMap小节在细讲,这里先不展开)
HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存取和查找性能。HashSet 集合判断两个元素相等的标准:两个对象通过 hashCode() 方法比较相等,并且两个对象的 equals() 方法返回值也相等。因此,存储到HashSet的元素要重写hashCode和equals方法。
示例代码:定义一个Employee类,该类包含属性:name, birthday,其中 birthday 为 MyDate类的对象;MyDate为自定义类型,包含年、月、日属性。要求 name和birthday一样的视为同一个员工。
public class Employee {
private String name;
private MyDate birthday;
public Employee(String name, MyDate birthday) {
super();
this.name = name;
this.birthday = birthday;
}
public Employee() {
super();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public MyDate getBirthday() {
return birthday;
}
public void setBirthday(MyDate birthday) {
this.birthday = birthday;
}