Glibc堆利用之house of系列总结
- 1-前言
- 2-house of系列
- 2.1-house of spirit
- 2.2-house of einherjar
- 2.3-house of force
- 2.4-house of lore
- 2.5-house of orange
- 2.6-house of rabbit
- 2.7-house of roman
- 2.8-house of storm
- 2.9-house of corrosion
- 2.10-house of husk
- 2.11-house of atum
- 2.12-house of kauri
- 2.13-house of fun
- 2.14-house of mind
- 2.15-house of muney
- 2.16-house of botcake
- 2.17-house of rust
- 2.18-house of crust
- 2.19-house of io
- 2.20-house of banana
- 2.21-house of kiwi
- 2.22-house of emma
- 2.23-house of pig
- 2.24-house of obstack
- 2.25-house of apple1
- 2.26-house of apple2
- 2.27-house of apple3
- 2.28-house of gods
- 3-总结
- 4-参考
总结一下
glibc堆利用的house of系列利用手法,主要参考了how2heap,同时参考了其他优秀的文章。
可以在Bilibili上观看视频进行学习,或者在Youtube上观看视频进行学习。
1-前言
Glibc的house of系列攻击手法基于都是围绕着堆利用和IO FILE利用。还有很多堆利用手法也非常经典,但是由于其没有被冠以house of xxxx,故没有收录到本文中。如果想学习所有的详细的堆攻击手法,强烈建议follow仓库how2heap进行学习。我相信,只要把how2heap里面的每一个堆利用手法都学懂学透了,glibc堆利用你将尽在掌握。
在开始系列总结之前,我会给出一个表格,表格里面分别是house of xxxx和对应的优秀的解析文章,在此非常感谢各位师傅们的总结。如果你在阅读本文的过程中想完整地查看某一个手法地详细利用过程,那么可以直接回到表格,点击对应的链接进行学习。目前的最新版本为2.37,但是,目前的ubuntu:23.04还没开始用glibc-2.37,使用的仍然是glibc-2.36。
如果还有哪些house of xxxx的利用手法没有收录进来,或你对本文存有一些疑问,或者你发现本文某些内容编写错误,还请留言指正。
需要注意的是,除了关注各种house of利用技巧本身,更重要的是,需要关注该利用技巧背后的思想和原理。如果你能从这一系列的利用手法中提炼出一些通用的攻击向量或者攻击思想,日后在面对其他的场景,你也能更快的找到系统的漏洞点并加以利用。学习glibc堆利用更多的是为了举一反三,为了更好地掌握漏洞挖掘模式、漏洞分析方法,而不仅仅是为了比赛。
house of系列的表格如下,适用版本不考虑低于glibc-2.23的版本。我将在下文中进一步阐述每一个利用手法的原理、使用场景与适用范围。
此外,阅读下文之前需要了解:
- 下面所述的
chunk A,地址A指的是chunk header地址,而不是user data地址。 - 漏洞成因基本上都是堆溢出、
UAF等
2-house of系列
2.1-house of spirit#
漏洞成因#
堆溢出写
适用范围#
2.23——至今
利用原理#
利用堆溢出,修改chunk size,伪造出fake chunk,然后通过堆的释放和排布,控制fake chunk。house of spirit的操作思路有很多,比如可以按如下操作进行利用:
- 申请
chunk A、chunk B、chunk C、chunk D - 对
A写操作的时候溢出,修改B的size域,使其能包括chunk C - 释放
B,然后把B申请回来,再释放C,则可以通过读写B来控制C的内容
相关技巧#
起初house of spirit主要是针对fastbin,后来引入了tcachebin后,也可以使用tcachebin版本的house of spirit。利用方法与fastbin场景下类似,注意好不同版本下的检查条件即可。
利用效果#
- 劫持
fastbin/tcachebin的fd之后,可以任意地址分配、任意地址读写
2.2-house of einherjar#
漏洞成因#
溢出写、off by one、off by null
适用范围#
2.23——至今- 可分配大于处于
unsortedbin的chunk
利用原理#
利用off by null修改掉chunk的size域的P位,绕过unlink检查,在堆的后向合并过程中构造出chunk overlapping。
- 申请
chunk A、chunk B、chunk C、chunk D,chunk D用来做gap,chunk A、chunk C都要处于unsortedbin范围 - 释放
A,进入unsortedbin - 对
B写操作的时候存在off by null,修改了C的P位 - 释放
C的时候,堆后向合并,直接把A、B、C三块内存合并为了一个chunk,并放到了unsortedbin里面 - 读写合并后的大
chunk可以操作chunk B的内容,chunk B的头
相关技巧#
虽然该利用技巧至今仍可以利用,但是需要对unlink绕过的条件随着版本的增加有所变化。
最开始的unlink的代码是:
/* Take a chunk off a bin list */
#define unlink(AV, P, BK, FD) { \
FD = P->fd; \
BK = P->bk; \
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) \
malloc_printerr (check_action, "corrupted double-linked list", P, AV); \
else { \
// ..... \
} \
}
只需要绕过__builtin_expect (FD->bk != P || BK->fd != P, 0)即可,因此,不需要伪造地址处于高位的chunk的presize域。
高版本的unlink的条件是:
/* Take a chunk off a bin list. */
static void
unlink_chunk (mstate av, mchunkptr p)
{
if (chunksize (p) != prev_size (next_chunk (p)))
malloc_printerr ("corrupted size vs. prev_size");
mchunkptr fd = p->fd;
mchunkptr bk = p->bk;
if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
malloc_printerr ("corrupted double-linked list");
// ......
}
新增了chunksize (p) != prev_size (next_chunk (p)),对chunksize有了检查,伪造的时候需要绕过。
利用效果#
- 构造
chunk overlap后,可以任意地址分配 - 结合其他方法进行任意地址读写
2.3-house of force#
漏洞成因#
堆溢出写top_chunk
适用范围#
2.23——2.29- 可分配任意大小的
chunk - 需要泄露或已知地址
利用原理#
对top_chunk的利用,过程如下:
- 申请
chunk A - 写
A的时候溢出,修改top_chunk的size为很大的数 - 分配很大的
chunk到任意已知地址
相关技巧#
注意,在glibc-2.29后加入了检测,house of force基本失效:

利用效果#
- 任意地址分配
- 任意地址读写
2.4-house of lore#
漏洞成因#
堆溢出、use after free、edit after free
适用范围#
2.23——至今- 需要泄露或已知地址
利用原理#
控制smallbin的bk指针,示例如下:
- 申请
chunk A、chunk B、chunk C,其中chunk B大小位于smallbin - 释放
B,申请更大的chunk D,使得B进入smallbin - 写
A,溢出修改B的bk,指向地址X,这里有fake chunk - 布置
X->fd == &B - 分配两次后即可取出位于
X地址处的fake chunk
相关技巧#
在引入了tcache stash unlink的时候,需要注意绕过:
#if USE_TCACHE
/* While we're here, if we see other chunks of the same size,
stash them in the tcache. */
size_t tc_idx = csize2tidx (nb);
if (tcache && tc_idx < mp_.tcache_bins)
{
mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks over. */
while (tcache->counts[tc_idx] < mp_.tcache_count
&& (tc_victim = last (bin)) != bin)
{
if (tc_victim != 0)
{
bck = tc_victim->bk;
set_inuse_bit_at_offset (tc_victim, nb);
if (av != &main_arena)
set_non_main_arena (tc_victim);
bin->bk = bck;
bck->fd = bin;
tcache_put (tc_victim, tc_idx);
}
}
}
#endif
要么使其满足tc_victim = last (bin)) == bin、要么使其满足:tcache->counts[tc_idx] ≥ mp_.tcache_count。否则可能会因为非法内存访问使得程序down掉。
实际上,这个技巧用得不是很多,因为在同等条件下,更偏向于利用fastbin/tcachebin。
利用效果#
- 任意地址分配
- 任意地址读写
2.5-house of orange#
漏洞成因#
堆溢出写
适用范围#
2.23——2.26- 没有
free - 可以
unsortedbin attack
利用原理#
house of orange可以说是开启了堆与IO组合利用的先河,是非常经典、漂亮、精彩的利用组合技。利用过程还要结合top_chunk的性质,利用过程如下:
stage1
- 申请
chunk A,假设此时的top_chunk的size为0xWXYZ - 写
A,溢出修改top_chunk的size为0xXYZ(需要满足页对齐的检测条件) - 申请一个大于
0xXYZ大小的chunk,此时top_chunk会进行grow,并将原来的old top_chunk释放进入unsortedbin
stage2
- 溢出写
A,修改处于unsortedbin中的old top_chunk,修改其size为0x61,其bk为&_IO_list_all-0x10,同时伪造好IO_FILE结构 - 申请非
0x60大小的chunk的时候,首先触发unsortedbin attack,将_IO_list_all修改为main_arena+88,然后unsortedbin chunk会进入到smallbin,大小为0x60;接着遍历unsortedbin的时候触发了malloc_printerr,然后调用链为:malloc_printerr -> libc_message -> abort -> _IO_flush_all_lockp,调用到伪造的vtable里面的函数指针
相关技巧#
- 在
glibc-2.24后加入了vtable的check,不能任意地址伪造vatble了,但是可以利用IO_str_jumps结构进行利用。 - 在
glibc-2.26后,malloc_printerr不再刷新IO流了,所以该方法失效 - 由于
_mode的正负性是随机的,影响判断条件,大概有1/2的概率会利用失败,多试几次就好
利用效果#
- 任意函数执行
- 任意命令执行
2.6-house of rabbit#
漏洞成因#
堆溢出写、use after free、edit after free
适用范围#
2.23——2.26- 超过
0x400大小的堆分配 - 可以写
fastbin的fd或者size域
利用原理#
该利用技巧的核心是malloc_consolidate函数,当检测到有fastbin的时候,会取出每一个fastbin chunk,将其放置到unsortedbin中,并进行合并。以修改fd为例,利用过程如下:
- 申请
chunk A、chunk B,其中chunk A的大小位于fastbin范围 - 释放
chunk A,使其进入到fastbin - 利用
use after free,修改A->fd指向地址X,需要伪造好fake chunk,使其不执行unlink或者绕过unlink - 分配足够大的
chunk,或者释放0x10000以上的chunk,只要能触发malloc_consolidate即可 - 此时
fake chunk被放到了unsortedbin,或者进入到对应的smallbin/largebin - 取出
fake chunk进行读写即可
相关技巧#
2.26加入了unlink对presize的检查2.27加入了fastbin的检查
抓住重点:house of rabbit是对malloc_consolidate的利用。因此,不一定要按照原作者的思路来,他的思路需要满足的条件太多了。
利用效果#
- 任意地址分配
- 任意地址读写
2.7-house of roman#
漏洞成因#
use after free、堆溢出
适用范围#
2.23——2.29- 可以
use after edit - 不需要泄露地址
- 需要爆破
12 bit,成功的概率1/4096
利用原理#
可以说这个技巧是fastbin attack + unsortedbin attack的组合技,利用思路如下:
- 申请
chunk A、chunk B、chunk C和chunk D,chunk B的大小为0x70 - 释放
chunk B,使其进入到fastbin[0x70] - 溢出写
A,修改chunk B的size,使其大小在unsortedbin范围 - 再次释放
B,B进入unsortedbin中 - 部分写
B的fd,使得fd指向malloc_hook-0x23 - 利用
A的溢出写修正B的size,连续分配两次0x70,即可分配到malloc_hook上方 - 触发
unsortedbin attack,将__malloc_hook写为main_arena+88 - 部分写
__malloc_hook的低三个字节,修改为one_gadget - 再次
malloc即可拿到shell
相关技巧#
- 使用
house of roman的时候,需要采用多线程爆破 - 可以使用其他方法代替,比如先攻击
stdout泄露地址,使得爆破的成本降低
利用效果#
- 执行
one_gadget - 绕过
ASLR
2.8-house of storm#
漏洞成因#
堆溢出、use after free、edit after free
适用范围#
2.23——2.29- 可以进行
unsortedbin attack - 可以进行
largebin attack,修改bk和bk_nextsize - 可以分配
0x50大小的chunk
利用原理#
house of storm也是一款组合技,利用开启了PIE的x64程序的堆地址总是0x55xxxx...或者0x56xxxx...开头这一特性,使用一次largebin attack写两个堆地址,使用一次unsortedbin attack写一次libc地址,可以实现任意地址分配。虽然house of storm最后能达到任意地址分配,但是由于其所需的条件比较多,一般可以用其他更简便的堆利用技术代替。利用思路如下:
- 进行一次
unsortedbin attack,其bk修改为addr - 进行一次
largebin attack,其bk修改为addr+0x10,bk_nextsize修改为addr-0x20+3 - 申请
0x50大小的chunk即可申请到addr处
相关技巧#
需要注意的有:
- 该方法成功的几率是
50%,因为0x55会触发assert断言,0x56才能成功 - 申请
addr处的chunk的时候需要从unsortedbin里面取
利用效果#
- 任意地址分配
2.9-house of corrosion#
漏洞成因#
堆溢出、use after free
适用范围#
2.23——至今- 任意大小分配
- 可以修改
global_max_fast - 不需要泄露地址
利用原理#
一个非常tricky的方法,可以绕过aslr,不需要泄露地址都能达成rce,可以很很多方法结合起来应用。先说利用原理:
- 使用
unsortedbin attack/largebin attack等方法,成功修改global_max_fast的值为很大的值。如果使用unsortedbin attack,不需要泄露地址,爆破1/16即可 - 申请任意大小的
chunk,这些chunk都会被视为fastbin chunk,然后利用这些chunk来进行读和写
此时的计算公式为:
chunk size = (chunk addr - &main_arena.fastbinsY) x 2 + 0x20
读原语:
- 假设对应的地址
X上存储着Y,现在的目的是泄露出Y - 根据偏移计算出来
chunk size,修改chunk A的size为计算出来的值,释放chunk A到地址X处 - 此时,
A->fd就被写入了Y - 通过打印即可泄露出
Y的信息
写原语1:
- 假设对应的地址
X上存储着Y,现在的目的是修改地址X存储的Y为其他值 - 根据偏移计算出来
chunk size,修改chunk A的size为计算出来的值,释放chunk A到地址X处 - 此时,
A->fd就被写入了Y - 修改
A->fd为目标值 - 分配一次
chunk A就可以把地址X存储的值为任意值
写原语2:
- 假设地址
X上存储着Y、地址M上存储着N,现在的目的是把N写到地址X处 - 根据偏移计算
chunk size1,先释放chunk A到地址X处,此时有地址X处存储chunk A地址,chunk A->fd为Y - 根据偏移计算
chunk size2,再次释放chunk A到地址M处,此时有地址M处存储chunk A地址,chunk A->fd为N - 修正
chunk A的大小为chunk size1,分配1次chunk即可使得N转移到地址X处,当然在转移的过程中可以适当的修改N
显然,借助写原语2,即可在不需要泄露地址的前提下将__malloc_hook等写为one_gadget,爆破的概率是1/4096。
相关技巧#
- 虽然至今都能使用
house of corrosion,但是在glibc-2.37版本中,global_max_fast的数据类型被修改为了int8_u,进而导致可控的空间范围大幅度缩小。 house of corrosion也可以拓展到tcachebin上- 适当控制
global_max_fast的大小,把握控制的空间范围 - 可以和
IO_FILE结合起来泄露信息
利用效果#
glibc上的地址泄露- 执行
one_gadget
2.10-house of husk#
漏洞成因#
堆溢出
适用范围#
2.23——至今- 可以修改
__printf_arginfo_table和__printf_function_table - 可触发格式化字符串解析
利用原理#
严格来说,这个漏洞是与堆的关系并不是很大,主要是根据printf的机制进行利用。但是,该技术可以和很多堆利用手法结合起来。
调用处1:
//
/* Use the slow path in case any printf handler is registered. */
if (__glibc_unlikely (__printf_function_table != NULL
|| __printf_modifier_table != NULL
|| __printf_va_arg_table != NULL))
goto do_positional;
// vfprintf-internal.c#1763
nargs += __parse_one_specmb (f, nargs, &specs[nspecs], &max_ref_arg);
// printf-parsemb.c (__parse_one_specmb函数)
/* Get the format specification. */
spec->info.spec = (wchar_t) *format++;
spec->size = -1;
if (__builtin_expect (__printf_function_table == NULL, 1) // 判断是否为空
|| spec->info.spec > UCHAR_MAX
|| __printf_arginfo_table[spec->info.spec] == NULL // 判断是否为空
/* We don't try to get the types for all arguments if the format
uses more than one. The normal case is covered though. If
the call returns -1 we continue with the normal specifiers. */
|| (int) (spec->ndata_args = (*__printf_arginfo_table[spec->info.spec]) // 调用__printf_arginfo_table中的函数指针
(&spec->info, 1, &spec->data_arg_type,
&spec->size)) < 0)
{
// ......
}
利用方式为:
__printf_function_table和__printf_arginfo_table分别写为chunk A和chunk B的地址- 设占位符为
α,此时chunk B的内容应该为p64(0) x ord(α-2) + p64(one_gadget)
调用处2:
// vfprintf-internal.c#1962
if (spec <= UCHAR_MAX
&& __printf_function_table != NULL
&& __printf_function_table[(size_t) spec] != NULL)
{
// ......
/* Call the function. */
function_done = __printf_function_table[(size_t) spec](s, &specs[nspecs_done].info, ptr); // 调用__printf_function_table中的函数指针
if (function_done != -2)
{
/* If an error occurred we don't have information
about # of chars. */
if (function_done < 0)
{
/* Function has set errno. */
done = -1;
goto all_done;
}
done_add (function_done);
break;
}
}
利用方式为:
__printf_function_table和__printf_arginfo_table分别写为chunk A和chunk B的地址- 设占位符为
α,此时chunk A的内容应该为p64(0) x ord(α-2) + p64(one_gadget)
该处调用在高版本被删除。
相关技巧#
- 该技巧一般和
largebin attack结合起来 - 在低于
2.36版本中,__malloc_assert中有格式化字符串的解析 - 还有一个
__printf_va_arg_table也是可以利用的,但是条件比较苛刻
利用效果#
- 执行
one_gadget - 执行
rop控制程序执行流
2.11-house of atum#
漏洞成因#
edit after free
适用范围#
2.26——2.30- 可以修改
tcachebin的next和key
利用原理#
这是一个关于tcachebin的技巧,用于修改chunk presize/size,利用过程如下:
- 申请
chunk A,大小在fastbin范围内 - 释放
A,连续释放8次,此时,A的fd被清0,A也被放置到了fastbin里面 - 申请一个
chunk,将其fd修改为A - 0x10,此时tcache中的counts为6 - 再申请一个
chunk,从fastbin里面取,但是会把fastbin里面剩余的一个chunk链入到tcachebin - 再次分配就会分配到地址
A-0x10处,就可以修改原来A的presize/size等
相关技巧#
-
2.30之后逻辑变了,原来是判断entry[idx]!=NULL,2.31之后判断count[idx] > 0// glibc ≥ 2.30 void * __libc_malloc (size_t bytes) { //...... MAYBE_INIT_TCACHE (); DIAG_PUSH_NEEDS_COMMENT; if (tc_idx < mp_.tcache_bins && tcache && tcache->counts[tc_idx] > 0) { return tcache_get (tc_idx); } } // glibc < 2.30 void * __libc_malloc (size_t bytes) { //...... MAYBE_INIT_TCACHE (); DIAG_PUSH_NEEDS_COMMENT; if (tc_idx < mp_.tcache_bins && tcache && tcache->entries[tc_idx] != NULL) { return tcache_get (tc_idx); } } -
有时候需要绕过
tcache->key的检测
利用效果#
- 修改
chunk size以及chunk presize
2.12-house of kauri#
漏洞成因#
堆溢出
适用范围#
2.26——2.32
利用原理#
利用原理很简单,修改tcachebin的size,然后使其被放到不同大小的tcachebin链表里面去。我感觉这个技巧是很基础的tcachebin技巧,甚至不应该被称之为house of。
相关技巧#
- 无
利用效果#
- 多个
tcachebin链表中存放同一个chunk
2.13-house of fun#
漏洞成因#
堆溢出、use after free
适用范围#
2.23——2.30- 可以申请
largebin范围的chunk
利用原理#
或许这个技巧应该叫做largebin attack。
在这个sourceware.org Git - glibc.git/blobdiff - malloc/malloc.ccommit被检测了:
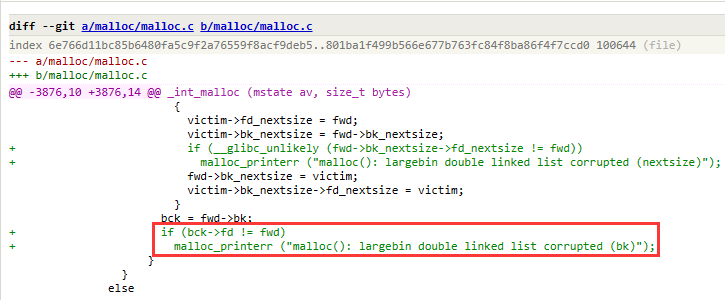
相关技巧#
- 无
利用效果#
- 任意地址写堆地址
2.14-house of mind#
漏洞成因#
堆溢出
适用范围#
2.23——至今- 可以分配任意大小的
chunk
利用原理#
主要利用的是:
#define heap_for_ptr(ptr) \
((heap_info *) ((unsigned long) (ptr) & ~(HEAP_MAX_SIZE - 1)))
#define arena_for_chunk(ptr) \
(chunk_non_main_arena (ptr) ? heap_for_ptr (ptr)->ar_ptr : &main_arena)
如果是non-mainarean的chunk,会根据其地址找到heapinfo,然后找到malloc_state结构体。
因此,利用技巧是:
- 根据要释放的
fastbin chunk A的堆地址,找到对应的heap_for_ptr地址 - 在
heapinfo地址处伪造好相关变量,重点是mstate指针 - 修改
chunk A的non-main标志位,释放到伪造的arena里面,控制好偏移即可
相关技巧#
- 一般来说,可以分配任意大小的
chunk,还能堆溢出,很多技巧都能用 - 这个技巧是希望大家关注对于
arena的攻击 - 甚至可以直接修改
thread_arena这个变量
利用效果#
- 任意地址写堆地址
2.15-house of muney#
漏洞成因#
堆溢出
适用范围#
2.23——至今- 能分配
mmap的chunk - 能修改
mmap的chunk的大小
利用原理#
这个技巧被称之为steal heap from glibc。主要的点有以下几个:
libc.so.6映射的地址空间,前面都是与符号表、哈希表、字符串表等重定位或者解析函数地址有关,前面一段的权限是r--mmap(NULL, ...)是会分配到libc.so.6的上方的
基于这两个知识点,利用过程如下:
- 申请
chunk A,假设为0x40000大小,则会走mmap申请,并且申请到libc.so.6的上方 - 修改
chunk A的大小为0x45000,设置MMAP标志位 - 释放
chunk A,则会把libc.so.6的0x5000的内存也释放掉 - 再次申请
0x45000,就可以控制libc.so.6原来的符号表、哈希表等等 - 触发一次
dl_runtime_resolve等就能控制程序执行任意代码
相关技巧#
- 需要伪造的符号表、哈希表等需要逐步调试
- 可以扩展为
steal heap from everywhere
利用效果#
- 任意代码执行
2.16-house of botcake#
漏洞成因#
double free
适用范围#
2.26——至今- 多次释放
chunk的能力
利用原理#
该技巧可以用于绕过tcache->key的检查,利用过程如下:
- 申请
7个大小相同,大小大于0x80的chunk,再申请三个,分别为chunk A和chunkB和chunk C - 释放前
7个和chunk A,前面7个都会进入到tcachebin里面,chunk A进入到unsortedbin - 释放
chunk B,则chunk B会和chunk A合并 - 从
tcachebin分配走一个 - 再次释放
chunk B,此时B同时存在与unsortedbin和tcachebin
相关技巧#
- 在高版本需要绕过指针保护的检查
利用效果#
- 构造出堆重叠,为后续利用做准备
2.17-house of rust#
漏洞成因#
堆溢出
适用范围#
2.26——至今- 可以进行
tcache stash unlinking攻击 - 可以进行
largebin attack - 不需要泄露地址
利用原理#
原作者的博客写得很复杂,我这里提炼出关键信息。该技巧就是tcachebin stash unlinking+largebin attack的组合技巧。
首先需要知道tcachebin stash unlinking,下面称之为TSU技巧:
tcachebin[A]为空smallbin[A]有8个- 修改第
8个smallbin chunk的bk为addr - 分配
malloc(A)的时候,addr+0x10会被写一个libc地址
还要知道tcachebin stash unlinking+,下面称之为TSU+技巧:
tcachebin[A]为空smallbin[A]有8个- 修改第
7个smallbin chunk的bk为addr,还要保证addr+0x18是一个合法可写的地址 - 分配
malloc(A)的时候,addr会被链入到tcachebin,也就是可以分配到addr处
以0x90大小的chunk为例,此时的tcache_key还是指向tcache_perthread_struct + 0x10的:
- 第一步,把
tcachebin[0x90]填满,把smallbin[0x90]也填满 - 第二步,把最后一个
smallbin 0x90的chunk的size改成0xb0,将其释放到tcachebin[0xb0],这一步主要是为了改变其bk指向tcache_perthread_struct + 0x10,可以部分修改低位的字节,以便下一步分配到目标区域 - 第三步,使用
largebin attack往上一步的bk->bk写一个合法地址,然后耗尽tcachebin[0x90],再分配的时候就会触发TSU+,之后就能分配到tcache_perthread_struct结构体 - 第四步,还是堆风水,但是用
TSU技术,在tcache_perthread_struct上写一个libc地址(比前面一步要简单很多) - 第五步,通过控制
tcache_perthread_struct结构体,部分写上面的libc地址,分配到stdout结构体,泄露信息 - 第六步,通过控制
tcache_perthread_struct结构体分配到任意地址
上面的过程最好的情况下需要爆破1/16,最差1/256。
但是,2.34之后,tcache_key是一个随机数,不是tcache_perthread_struct + 0x10了。
所以,此时可以加上largebin attack,把以上的第二步变为:继续用largebin attack向其bk写一个堆地址,然后还要部分写bk使其落在tcache_perthread_struct区域。其他步骤一样。
或者,在smallbin里面放9个,这样第8个的bk肯定就是一个堆地址。此时就需要爆破1/16的堆,1/16的glibc地址,成功的概率是1/256。
相关技巧#
- 总的来说,就是利用
tcachebin stash unlinking打tcache_perthread_struct - 利用
largebin attack构造合法地址
利用效果#
- 任意地址分配
- 任意函数执行
2.18-house of crust#
漏洞成因#
堆溢出
适用范围#
2.26——2.37- 可以进行
tcache stash unlinking攻击 - 可以进行
largebin attack - 不需要泄露地址
利用原理#
其他步骤和上面的house of rust一样,但是到第五步的时候,去修改global_max_fast
后面的步骤和house of corrosion是一样的,通过写原语打stderr修改one_gadget拿到shell。
相关技巧#
house of crust = house of corrosion + house of rust2.37之后,house of corrosion使用受限
2.19-house of io#
漏洞成因#
堆溢出
适用范围#
2.26——至今
利用原理#
其他博客上对该方法的介绍如下:
The tcache_perthread_object is allocated when the heap is created. Furthermore, it is stored right at the heap's beginning (at a relatively low memory address). The safe-linking mitigation aims to protect the fd/next pointer within the free lists. However, the head of each free-list is not protected. Additionally, freeing a chunk and placing it into the tcachebin also places a non-protected pointer to the appropriate tcache entry in the 2nd qword of a chunks' user data. The House of IO assumes one of three scenarios for the bypass to work. First, any attacker with a controlled linear buffer underflow over a heap buffer, or a relative arbitrary write will be able to corrupt the tcache. Secondly, a UAF bug allowing to read from a freed tcache eligible chunk leaks the tcache and with that, the heap base. Thirdly, a badly ordered set of calls to free(), ultimately passing the address of the tcache itself to free, would link the tcache into the 0x290 sized tcachebin. Allocating it as a new chunk would mean complete control over the tcache's values.
可以看出来,其实就是对tcache_perthread_struct结构体的攻击,想办法将其释放掉,然后再申请回来,申请回来的时候就能控制整个tcache的分配。
相关技巧#
- 围绕
tcache_perthread_struct进行攻击
利用效果#
- 任意地址分配
2.20-house of banana#
漏洞成因#
堆溢出
适用范围#
2.23——至今- 可以进行
largebin attack - 能执行
exit函数
利用原理#
首先是largebin attack在高版本只能从下面这个分支利用:
/* maintain large bins in sorted order */
if (fwd != bck)
{
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
if ((unsigned long) (size)
< (unsigned long) chunksize_nomask (bck->bk))
{
fwd = bck;
bck = bck->bk;
victim->fd_nextsize = fwd->fd;
victim->bk_nextsize = fwd->fd->bk_nextsize;
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
}
else
{
//......
}
//......
}
也就是,双链表里面至少存在一个largebin chunk,且目前要入链的chunk比最小的还小,修改了bk_nextsize之后就会触发。可以造成任意地址写堆地址。
然后是exit调用的时候,会调用到_dl_fini函数,执行每个so中注册的fini函数:
for (i = 0; i < nmaps; ++i)
{
struct link_map *l = maps[i];
if (l->l_init_called)
{
/* Make sure nothing happens if we are called twice. */
l->l_init_called = 0;
/* Is there a destructor function? */
if (l->l_info[DT_FINI_ARRAY] != NULL
|| (ELF_INITFINI && l->l_info[DT_FINI] != NULL))
{
/* When debugging print a message first. */
if (__builtin_expect (GLRO(dl_debug_mask)
& DL_DEBUG_IMPCALLS, 0))
_dl_debug_printf ("\ncalling fini: %s [%lu]\n\n",
DSO_FILENAME (l->l_name),
ns);
/* First see whether an array is given. */
if (l->l_info[DT_FINI_ARRAY] != NULL)
{
ElfW(Addr) *array =
(ElfW(Addr) *) (l->l_addr
+ l->l_info[DT_FINI_ARRAY]->d_un.d_ptr);
unsigned int i = (l->l_info[DT_FINI_ARRAYSZ]->d_un.d_val
/ sizeof (ElfW(Addr)));
while (i-- > 0)
((fini_t) array[i]) (); // 这里call
}
/* Next try the old-style destructor. */
if (ELF_INITFINI && l->l_info[DT_FINI] != NULL)
DL_CALL_DT_FINI
(l, l->l_addr + l->l_info[DT_FINI]->d_un.d_ptr); // 这里call
}
可以触发call的有两个点,第一个点可以call到很多指针,是一个数组;另一个点就只有一个函数。
剩下的工作就是根据代码绕过检测,调用到调用点。
所以,利用的思路有:
- 直接伪造
_rtld_global的_ns_loaded,布局好其他内容,使其调用到fini_array - 伪造
link_map的next指针,布局好其他内容,使其调用到fini_array - 修改
link_map->l_addr,根据偏移使其调用到指定区域的函数
相关技巧#
- 伪造
fini_array数组的时候,是从后往前遍历的 - 有时候远程的
rtld_global的偏移与本地不一样,需要爆破 - 如果不想逐个伪造,可以直接用
gdb从内存里面dump出来,然后基于偏移修改内存即可
利用效果#
- 任意代码执行
2.21-house of kiwi#
漏洞成因#
堆溢出
适用范围#
2.23——2.36- 在
malloc流程中触发assert
利用原理#
主要是提供了一种在程序中调用IO流函数的思路:
#if IS_IN (libc)
#ifndef NDEBUG
# define __assert_fail(assertion, file, line, function) \
__malloc_assert(assertion, file, line, function)
extern const char *__progname;
static void
__malloc_assert (const char *assertion, const char *file, unsigned int line,
const char *function)
{
(void) __fxprintf (NULL, "%s%s%s:%u: %s%sAssertion `%s' failed.\n",
__progname, __progname[0] ? ": " : "",
file, line,
function ? function : "", function ? ": " : "",
assertion);
fflush (stderr);
abort ();
}
#endif
#endif
可以看到,调用到了fxprintf和fflush。
至于原house of kiwi所提到的控制rdx的思路,在很多版本中无法使用,因为IO_jumps_table都是不可写的,故此处不再详述。
相关技巧#
- 在
2.36之后,__malloc_assert被修改为:
_Noreturn static void
__malloc_assert (const char *assertion, const char *file, unsigned int line,
const char *function)
{
__libc_message (do_abort, "\
Fatal glibc error: malloc assertion failure in %s: %s\n",
function, assertion);
__builtin_unreachable ();
}
而在2.37该函数直接被删掉了。
-
如果
stderr在libc上,需要修改调stderr处的指针,也有可能在程序的地址空间上 -
伪造的技巧如下,触发
fxprintf(stderr,......):flags & 0x8000的话,不用伪造_lock flags & ~(0x2 | 0x8) 必须成立,避免走到unbuffered的流程 mode 设置为0 vtable默认调用的是偏移0x38的函数,如果想劫持为_IO_xxx_overflow,需要设置为_IO_xxx_jumps-0x20 flags 可以设置为" sh||",前面有两个空格,此时还需要设置_lock,不想设置_lock的时候,flags可以为"\x20\x80;sh||"
利用效果#
- 触发
IO处理流程,为后续利用做准备
2.22-house of emma#
漏洞成因#
堆溢出
适用范围#
2.23——至今- 可以进行两次
largebin attack - 或者可以进行两次任意地址写堆地址
- 可以触发
IO流操作
利用原理#
在_IO_cookie_jumps中存在一些_IO_cookie_read等函数,如下:
static ssize_t
_IO_cookie_read (FILE *fp, void *buf, ssize_t size)
{
struct _IO_cookie_file *cfile = (struct _IO_cookie_file *) fp;
cookie_read_function_t *read_cb = cfile->__io_functions.read;
#ifdef PTR_DEMANGLE
PTR_DEMANGLE (read_cb);
#endif
if (read_cb == NULL)
return -1;
return read_cb (cfile->__cookie, buf, size);
}
可以看到有函数指针的调用。但是对函数指针使用pointer_guard进行了加密:
# define PTR_MANGLE(var) asm ("xorl %%gs:%c2, %0\n" \
"roll $9, %0" \
: "=r" (var) \
: "0" (var), \
"i" (offsetof (tcbhead_t, \
pointer_guard)))
# define PTR_DEMANGLE(var) asm ("rorl $9, %0\n" \
"xorl %%gs:%c2, %0" \
: "=r" (var) \
: "0" (var), \
"i" (offsetof (tcbhead_t, \
pointer_guard)))
# endif
循环右移后,再异或。
因此,利用思路如下:
- 截至某个
IO_FILE的指针(IO_list_all/stdxxx->chain等都可以)为堆地址 - 堆上伪造
IO_FILE结构,其vtable替换为_IO_cookie_jumps+XX,XX为一个偏移量 - 伪造好函数指针和调用参数,指针需要循环异或和加密
- 调用到
_IO_cookie_read等函数,进而执行任意函数
相关技巧#
-
常用的
gadget有:;栈迁移 mov rbp,QWORD PTR [rdi+0x48] mov rax,QWORD PTR [rbp+0x18] lea r13,[rbp+0x10] mov DWORD PTR [rbp+0x10],0x0 mov rdi,r13 call QWORD PTR [rax+0x28] ; rdi转rdx mov rdx, qword ptr [rdi + 8] mov qword ptr [rsp], rax call qword ptr [rdx + 0x20] -
pointer_guard就在canary下面,偏移可能需要爆破
利用效果#
- 任意函数执行
2.23-house of pig#
漏洞成因#
堆溢出
适用范围#
2.23——至今- 可以进行
largebin attack - 可以触发
IO流操作
利用原理#
在_IO_str_jumps中,存在着_IO_str_overflow函数:
int
_IO_str_overflow (FILE *fp, int c)
{
int flush_only = c == EOF;
size_t pos;
if (fp->_flags & _IO_NO_WRITES)
return flush_only ? 0 : EOF;
if ((fp->_flags & _IO_TIED_PUT_GET) && !(fp->_flags & _IO_CURRENTLY_PUTTING))
{
fp->_flags |= _IO_CURRENTLY_PUTTING;
fp->_IO_write_ptr = fp->_IO_read_ptr;
fp->_IO_read_ptr = fp->_IO_read_end;
}
pos = fp->_IO_write_ptr - fp->_IO_write_base;
if (pos >= (size_t) (_IO_blen (fp) + flush_only))
{
if (fp->_flags & _IO_USER_BUF) /* not allowed to enlarge */
return EOF;
else
{
char *new_buf;
char *old_buf = fp->_IO_buf_base; // 覆盖到这里
size_t old_blen = _IO_blen (fp);
size_t new_size = 2 * old_blen + 100;
if (new_size < old_blen)
return EOF;
new_buf = malloc (new_size); // 调用malloc
if (new_buf == NULL)
{
/* __ferror(fp) = 1; */
return EOF;
}
if (old_buf)
{
memcpy (new_buf, old_buf, old_blen);// 调用memecpy,覆盖
free (old_buf); // 调用free
/* Make sure _IO_setb won't try to delete _IO_buf_base. */
fp->_IO_buf_base = NULL;
}
memset (new_buf + old_blen, '\0', new_size - old_blen);
//......
}
}
从函数中就能看到,利用流程如下:
- 伪造
IO_FILE的_IO_buf_base - 合理控制
_IO_buf_end-_IO_buf_base的值,进而控制分配的chunk的大小,分配到布局好的地址 - 在
memcpy中覆盖地址,如可以覆盖__malloc_hook/__free_hook等
该方法需要结合其他堆利用技术,需要保证malloc分配出来的chunk的地址是可控的。该方法主要提供了对IO系列函数中间接调用mallc/free/memcpy的组合利用。
相关技巧#
- 可以
largebin attack打掉mp_.tcachebins,进而能把很大的chunk也放进入tcache进行管理 - 高版本没有
hook的话,可以利用memcpy@got,通过覆写got来进行rce - 可以多次
house of pig组合调用
利用效果#
- 任意函数执行
ROP控制程序执行流
2.24-house of obstack#
漏洞成因#
堆溢出
适用范围#
2.23——至今- 可以执行一次
largebin attack - 可以触发
IO流操作
利用原理#
一条新的利用链,伪造vtable为_IO_obstack_jumps,然后调用到_IO_obstack_xsputn,紧接着调用obstack_grow,其代码为:
#define obstack_grow(OBSTACK, where, length) \
__extension__ \
({ struct obstack *__o = (OBSTACK); \
int __len = (length); \
if (_o->next_free + __len > __o->chunk_limit) \
_obstack_newchunk (__o, __len); \
memcpy (__o->next_free, where, __len); \
__o->next_free += __len; \
(void) 0; })
然后在_obstack_newchunk调用了CALL_CHUNKFUN这个宏
void
_obstack_newchunk (struct obstack *h, int length)
{
struct _obstack_chunk *old_chunk = h->chunk;
struct _obstack_chunk *new_chunk;
long new_size;
long obj_size = h->next_free - h->object_base;
long i;
long already;
char *object_base;
/* Compute size for new chunk. */
new_size = (obj_size + length) + (obj_size >> 3) + h->alignment_mask + 100;
if (new_size < h->chunk_size)
new_size = h->chunk_size;
/* Allocate and initialize the new chunk. */
new_chunk = CALL_CHUNKFUN (h, new_size);
[...]
}
这个宏会调用到函数指针:
# define CALL_CHUNKFUN(h, size) \
(((h)->use_extra_arg) \
? (*(h)->chunkfun)((h)->extra_arg, (size)) \
: (*(struct _obstack_chunk *(*)(long))(h)->chunkfun)((size)))
因此,其就是利用该函数指针进行控制程序的执行流。
相关技巧#
伪造的IO_FILE布局如下:
- 利用
largebin attack伪造_IO_FILE,记完成伪造的chunk为A(或者别的手法) chunk A内偏移为0xd8处设为_IO_obstack_jumps+0x20chunk A内偏移为0xe0处设置chunk A的地址作为obstack结构体chunk A内偏移为0x18处设为1(next_free)chunk A内偏移为0x20处设为0(chunk_limit)chunk A内偏移为0x48处设为&/bin/shchunk A内偏移为0x38处设为system函数的地址chunk A内偏移为0x28处设为1(_IO_write_ptr)chunk A内偏移为0x30处设为0(_IO_write_end)chunk A内偏移为0x50处设为1(use_extra_arg)
glibc-2.37开始这个方法的调用链为:__printf_buffer_as_file_overflow -> __printf_buffer_flush -> __printf_buffer_flush_obstack->__obstack_newchunk。
利用效果#
- 任意函数执行
2.25-house of apple1#
漏洞成因#
堆溢出
适用范围#
-
2.23——至今 -
程序从
main函数返回或能调用exit函数 -
能泄露出
heap地址和libc地址 -
能使用一次
largebin attack(一次即可)
利用原理#
利用_IO_wstr_overflow将任意地址存储的值修改已知值:
static wint_t
_IO_wstrn_overflow (FILE *fp, wint_t c)
{
/* When we come to here this means the user supplied buffer is
filled. But since we must return the number of characters which
would have been written in total we must provide a buffer for
further use. We can do this by writing on and on in the overflow
buffer in the _IO_wstrnfile structure. */
_IO_wstrnfile *snf = (_IO_wstrnfile *) fp;
if (fp->_wide_data->_IO_buf_base != snf->overflow_buf)
{
_IO_wsetb (fp, snf->overflow_buf,
snf->overflow_buf + (sizeof (snf->overflow_buf)
/ sizeof (wchar_t)), 0);
fp->_wide_data->_IO_write_base = snf->overflow_buf;
fp->_wide_data->_IO_read_base = snf->overflow_buf;
fp->_wide_data->_IO_read_ptr = snf->overflow_buf;
fp->_wide_data->_IO_read_end = (snf->overflow_buf
+ (sizeof (snf->overflow_buf)
/ sizeof (wchar_t)));
}
fp->_wide_data->_IO_write_ptr = snf->overflow_buf;
fp->_wide_data->_IO_write_end = snf->overflow_buf;
/* Since we are not really interested in storing the characters
which do not fit in the buffer we simply ignore it. */
return c;
}
比如修改tcache变量、mp_结构体、pointer_guard变量等。
修改成功后,再使用其他技术控制程序执行流。
相关技巧#
house of apple1 是对现有一些 IO 流攻击方法的补充,能在一次劫持 IO 流的过程中做到任意地址写已知值,进而构造出其他方法攻击成功的条件。
利用效果#
- 任意地址写已知堆地址
2.26-house of apple2#
漏洞成因#
堆溢出
适用范围#
2.23——至今- 已知
heap地址和glibc地址 - 能控制程序执行
IO操作,包括但不限于:从main函数返回、调用exit函数、通过__malloc_assert触发 - 能控制
_IO_FILE的vtable和_wide_data,一般使用largebin attack去控制
利用原理#
_IO_WIDE_JUMPS没有检查_wide_vtable的合法性:
#define _IO_WOVERFLOW(FP, CH) WJUMP1 (__overflow, FP, CH)
#define WJUMP1(FUNC, THIS, X1) (_IO_WIDE_JUMPS_FUNC(THIS)->FUNC) (THIS, X1)
#define _IO_WIDE_JUMPS_FUNC(THIS) _IO_WIDE_JUMPS(THIS)
#define _IO_WIDE_JUMPS(THIS) \
_IO_CAST_FIELD_ACCESS ((THIS), struct _IO_FILE, _wide_data)->_wide_vtable
所以利用_IO_wfile_jumps等伪造_wide_vtable即可。
相关技巧#
利用_IO_wfile_overflow 函数控制程序执行流时对 fp 的设置如下:
_flags设置为~(2 | 0x8 | 0x800),如果不需要控制rdi,设置为0即可;如果需要获得shell,可设置为sh;,注意前面有两个空格vtable设置为_IO_wfile_jumps/_IO_wfile_jumps_mmap/_IO_wfile_jumps_maybe_mmap地址(加减偏移),使其能成功调用_IO_wfile_overflow即可_wide_data设置为可控堆地址A,即满足*(fp + 0xa0) = A_wide_data->_IO_write_base设置为0,即满足*(A + 0x18) = 0_wide_data->_IO_buf_base设置为0,即满足*(A + 0x30) = 0_wide_data->_wide_vtable设置为可控堆地址B,即满足*(A + 0xe0) = B_wide_data->_wide_vtable->doallocate设置为地址C用于劫持RIP,即满足*(B + 0x68) = C
利用效果#
- 任意函数执行
2.27-house of apple3#
漏洞成因#
堆溢出
适用范围#
2.23——至今- 已知
heap地址和glibc地址 - 能控制程序执行
IO操作,包括但不限于:从main函数返回、调用exit函数、通过__malloc_assert触发 - 能控制
_IO_FILE的vtable和_wide_data,一般使用largebin attack去控制
利用原理#
__libio_codecvt_in等函数,可以设置gs->__shlib_handle == NULL绕过PTR_DEMANGLE对指针的保护,然后通过_IO_wfile_underflow 调用到__libio_codecvt_in来控制函数指针,执行任意代码。
enum __codecvt_result
__libio_codecvt_in (struct _IO_codecvt *codecvt, __mbstate_t *statep,
const char *from_start, const char *from_end,
const char **from_stop,
wchar_t *to_start, wchar_t *to_end, wchar_t **to_stop)
{
enum __codecvt_result result;
// gs 源自第一个参数
struct __gconv_step *gs = codecvt->__cd_in.step;
int status;
size_t dummy;
const unsigned char *from_start_copy = (unsigned char *) from_start;
codecvt->__cd_in.step_data.__outbuf = (unsigned char *) to_start;
codecvt->__cd_in.step_data.__outbufend = (unsigned char *) to_end;
codecvt->__cd_in.step_data.__statep = statep;
__gconv_fct fct = gs->__fct;
#ifdef PTR_DEMANGLE
// 如果gs->__shlib_handle不为空,则会用__pointer_guard去解密
// 这里如果可控,设置为NULL即可绕过解密
if (gs->__shlib_handle != NULL)
PTR_DEMANGLE (fct);
#endif
// 这里有函数指针调用
// 这个宏就是调用fct(gs, ...)
status = DL_CALL_FCT (fct,
(gs, &codecvt->__cd_in.step_data, &from_start_copy,
(const unsigned char *) from_end, NULL,
&dummy, 0, 0));
// ......
}
相关技巧#
利用_IO_wfile_underflow 函数控制程序执行流时对 fp 的设置如下:
_flags设置为~(4 | 0x10)vtable设置为_IO_wfile_jumps地址(加减偏移),使其能成功调用_IO_wfile_underflow即可fp->_IO_read_ptr < fp->_IO_read_end,即满足*(fp + 8) < *(fp + 0x10)_wide_data保持默认,或者设置为堆地址,假设其地址为A,即满足*(fp + 0xa0) = A_wide_data->_IO_read_ptr >= _wide_data->_IO_read_end,即满足*A >= *(A + 8)_codecvt设置为可控堆地址B,即满足*(fp + 0x98) = Bcodecvt->__cd_in.step设置为可控堆地址C,即满足*B = Ccodecvt->__cd_in.step->__shlib_handle设置为0,即满足*C = 0codecvt->__cd_in.step->__fct设置为地址D, 地址D用于控制rip,即满足*(C + 0x28) = D。当调用到D的时候,此时的rdi为C。如果_wide_data也可控的话,rsi也能控制。
利用效果#
- 任意函数执行
2.28-house of gods#
漏洞成因#
堆溢出
适用范围#
2.23——2.27- 泄露堆地址和
libc地址 - 任意大小分配
利用原理#
这个技巧比较有意思,非常建议把作者的原博客读一下。我会简述一下该技巧的利用过程。
总的来说,该技巧最终的目的是伪造一个fake arena,通过劫持main_arena.next字段完成。
其主要过程为:
- 通过
binmap的赋值,将其当做chunk的size,然后修改unsortedbin链的bk指向binmap,作者选择的是0x90大小的chunk,释放后恰好让binmap称为0x200,然后binmap->bk是main_arena(初始状态下main_arena.next = &main_arena),然后main_arena->bk= fastbin[0x40] - 分配
0x1f0大小的chunk就刚好能分配到binmap - 之后修改掉
main_arena的system_mem为很大的值和next指向fake arena - 然后用
unsortedbin attack打掉narenas,将其改为一个很大的数 - 然后分配两次
malloc(0xffffffffffffffbf + 1),触发arena_get_retry,进而触发两次reused_arena,就能把fake arena给thread_arena变量 - 最后直接伪造
fastbin任意地址分配
相关技巧#
- 仅仅借助
unsortedbin链就能控制main_arena的next和system_mem - 利用
binmap的值构造出合法的size
利用效果#
- 劫持
thread_arena为fake_arena
3-总结
- 总结了
28种house of系列利用手法 - 给出了每种利用手法的影响版本、适用范围、利用原理等
- 所有的利用方法都可以在源码中找到答案,因此强烈建议将源码反复阅读
- 可以根据目前已有的技术提出新的组合技
4-参考
[1] 堆利用系列之house of spirit-安全客 - 安全资讯平台 (anquanke.com)
[2] shellphish/how2heap: A repository for learning various heap exploitation techniques. (github.com)
[3] Overview of GLIBC heap exploitation techniques (0x434b.dev)
[4] [原创] CTF 中 glibc堆利用 及 IO_FILE 总结-Pwn-看雪论坛-安全社区|安全招聘|bbs.pediy.com (kanxue.com)
[5] PWN——House Of Einherjar CTF Wiki例题详解-安全客 - 安全资讯平台 (anquanke.com)
[6] Top chunk劫持:House of force攻击-安全客 - 安全资讯平台 (anquanke.com)
[7] House of Lore - CTF Wiki (ctf-wiki.org)
[8] House of orange-安全客 - 安全资讯平台 (anquanke.com)
[9] house of rabbit
[10] House of Roman - CTF Wiki (ctf-wiki.org)
[11] House of storm 原理及利用-安全客 - 安全资讯平台 (anquanke.com)
[12] House-of-Corrosion 一种新的堆利用技巧 - 先知社区 (aliyun.com)
[13] house-of-husk学习笔记-安全客 - 安全资讯平台 (anquanke.com)
[14] House of Muney 分析-安全客 - 安全资讯平台 (anquanke.com)
[15] 奇安信攻防社区-深入理解 House of Botcake 堆利用手法 (butian.net)
[17] house of banana-安全客 - 安全资讯平台 (anquanke.com)
[18] House OF Kiwi-安全客 - 安全资讯平台 (anquanke.com)
[19] house of emma
[20] house of pig一个新的堆利用详解-安全客 - 安全资讯平台 (anquanke.com)
[21] 一条新的glibc IO_FILE利用链:_IO_obstack_jumps利用分析 - 跳跳糖 (tttang.com)
[22] House of Apple 一种新的glibc中IO攻击方法 (1) - roderick - record and learn! (roderickchan.cn)
[23] House of Apple 一种新的glibc中IO攻击方法 (2) - roderick - record and learn! (roderickchan.cn)
[24] House of Apple 一种新的glibc中IO攻击方法 (3) - roderick - record and learn! (roderickchan.cn)
[25] GlibcHeap-house of muney - roderick - record and learn! (roderickchan.cn)
[26] house-of-gods/HOUSE_OF_GODS.TXT at master · Milo-D/house-of-gods (github.com)
作者:roderick
出处:https://www.cnblogs.com/LynneHuan/p/17822162.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)